Configurer Kubernetes sur plusieurs machines pour les déploiements de cluster Big Data SQL Server
S’applique à : ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Cet article fournit un exemple d’utilisation de kubeadm permettant de configurer Kubernetes sur plusieurs machines pour des déploiements Clusters Big Data SQL Server. Dans cet exemple, plusieurs machines Ubuntu 16.04 ou 18.04 LTS (physiques ou virtuelles) représentent la cible. Si vous effectuez le déploiement sur une autre plateforme Linux, vous devez changer certaines commandes pour qu’elles correspondent à votre système.
Conseil
Pour obtenir des exemples de scripts de configuration de Kubernetes, consultez Créer un cluster Kubernetes à l’aide de Kubeadm sur Ubuntu 20.04 LTS.
Pour obtenir un exemple de script qui automatise le déploiement d’un seul nœud kubeadm sur une machine virtuelle, puis déploie une configuration par défaut du cluster Big Data par-dessus, consultez Déployer un cluster kubeadm à nœud unique.
Prérequis
- Au minimum, trois machines physiques ou machines virtuelles Linux
- Configuration recommandée par machine :
- 8 CPU
- 64 Go de mémoire
- 100 Go de stockage
Important
Avant de démarrer le déploiement du cluster Big Data, vérifiez que les horloges sont synchronisées entre tous les nœuds Kubernetes ciblés par le déploiement. Le cluster Big Data intègre des propriétés d’intégrité temporaires pour différents services et des décalages d’horloge peuvent entraîner un état incorrect.
Préparer les machines
Sur chaque machine, plusieurs prérequis doivent être remplis. Dans un terminal Bash, exécutez les commandes suivantes sur chaque machine :
Ajoutez la machine actuelle au fichier
/etc/hosts:echo $(hostname -i) $(hostname) | sudo tee -a /etc/hostsDésactivez l’échange de mémoire sur tous les appareils.
sudo sed -i "/ swap / s/^/#/" /etc/fstab sudo swapoff -aImportez les clés et inscrivez le dépôt pour Kubernetes.
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo sudo tee /etc/apt/trusted.gpg.d/apt-key.asc echo 'deb http://apt.kubernetes.io/ kubernetes-xenial main' | sudo tee -a /etc/apt/sources.list.d/kubernetes.listConfigurez les prérequis de Docker et Kubernetes sur la machine.
KUBE_DPKG_VERSION=1.15.0-00 #or your other target K8s version, which should be at least 1.13. sudo apt-get update && \ sudo apt-get install -y ebtables ethtool && \ sudo apt-get install -y docker.io && \ sudo apt-get install -y apt-transport-https && \ sudo apt-get install -y kubelet=$KUBE_DPKG_VERSION kubeadm=$KUBE_DPKG_VERSION kubectl=$KUBE_DPKG_VERSION && \ curl https://raw.githubusercontent.com/kubernetes/helm/master/scripts/get | bashDéfinissez
net.bridge.bridge-nf-call-iptables=1. Sur Ubuntu 18.04, les commandes suivantes activent d’abordbr_netfilter.. /etc/os-release if [ "$VERSION_CODENAME" == "bionic" ]; then sudo modprobe br_netfilter; fi sudo sysctl net.bridge.bridge-nf-call-iptables=1
Configurer le maître Kubernetes
Après avoir exécuté les commandes précédentes sur chaque machine, choisissez l’une des machines à utiliser comme maître Kubernetes. Exécutez ensuite les commandes suivantes sur cette machine.
Commencez par créer un fichier rbac.yaml dans votre répertoire actif à l’aide de la commande suivante.
cat <<EOF > rbac.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: default-rbac subjects: - kind: ServiceAccount name: default namespace: default roleRef: kind: ClusterRole name: cluster-admin apiGroup: rbac.authorization.k8s.io EOFInitialisez le maître Kubernetes sur cette machine. L’exemple de script ci-dessous spécifie Kubernetes version
1.15.0. La version que vous utilisez dépend de votre cluster Kubernetes.KUBE_VERSION=1.15.0 sudo kubeadm init --pod-network-cidr=10.244.0.0/16 --kubernetes-version=$KUBE_VERSIONVous devez voir une sortie indiquant que le maître Kubernetes a été initialisé correctement.
Notez la commande
kubeadm joinà utiliser sur les autres serveurs pour rejoindre le cluster Kubernetes. Copiez ceci pour l’utiliser plus tard.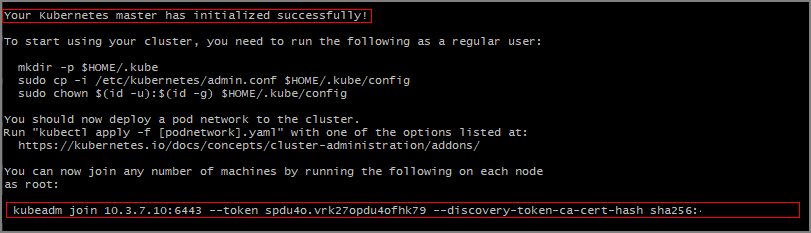
Créez un fichier config Kubernetes dans votre répertoire de base.
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/configConfigurez le cluster et le tableau de bord Kubernetes.
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml helm init kubectl apply -f rbac.yaml kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml kubectl create clusterrolebinding kubernetes-dashboard --clusterrole=cluster-admin --serviceaccount=kube-system:kubernetes-dashboard
Configurer les agents Kubernetes
Les autres machines servent d’agents Kubernetes dans le cluster.
Sur chacune des autres machines, exécutez la commande kubeadm join que vous avez copiée à la section précédente.

Voir l’état du cluster
Pour vérifier la connexion à votre cluster, utilisez la commande kubectl get pour retourner une liste des nœuds du cluster.
kubectl get nodes
Étapes suivantes
Les étapes décrites dans cet article ont permis de configurer un cluster Kubernetes sur plusieurs machines Ubuntu. L’étape suivante consiste à déployer le cluster Big Data SQL Server 2019. Pour obtenir des instructions, consultez l’article suivant :