Résolution des problèmes d’un notebook pyspark
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Cet article explique comment résoudre les problèmes provoquant l’échec d’un notebook pyspark.
Architecture d’un travail PySpark sous Azure Data Studio
Azure Data Studio communique avec le point de terminaison livy sur clusters Big Data SQL Server.
Le point de terminaison livy émet des commandes spark-submit au sein du cluster Big Data. Chaque commande spark-submit possède un paramètre qui spécifie YARN comme Gestionnaire des ressources clusters.
Pour résoudre efficacement les problèmes de votre session PySpark, vous devez collecter et examiner les journaux de chaque couche : Livy, YARN et Spark.
Cette procédure de dépannage comporte plusieurs prérequis :
- Avoir installé Azure Data CLI (
azdata) et défini correctement la configuration sur le cluster. - Savoir exécuter des commandes Linux et posséder quelques compétences en résolution des problèmes liés aux journaux.
Étapes de dépannage
Passez en revue la pile et les messages d’erreur dans
pyspark.Récupérez l’ID de l’application dans la première cellule du notebook. Servez-vous-en pour étudier les journaux
livy, YARN et Spark.SparkContextutilise cet ID d’application YARN.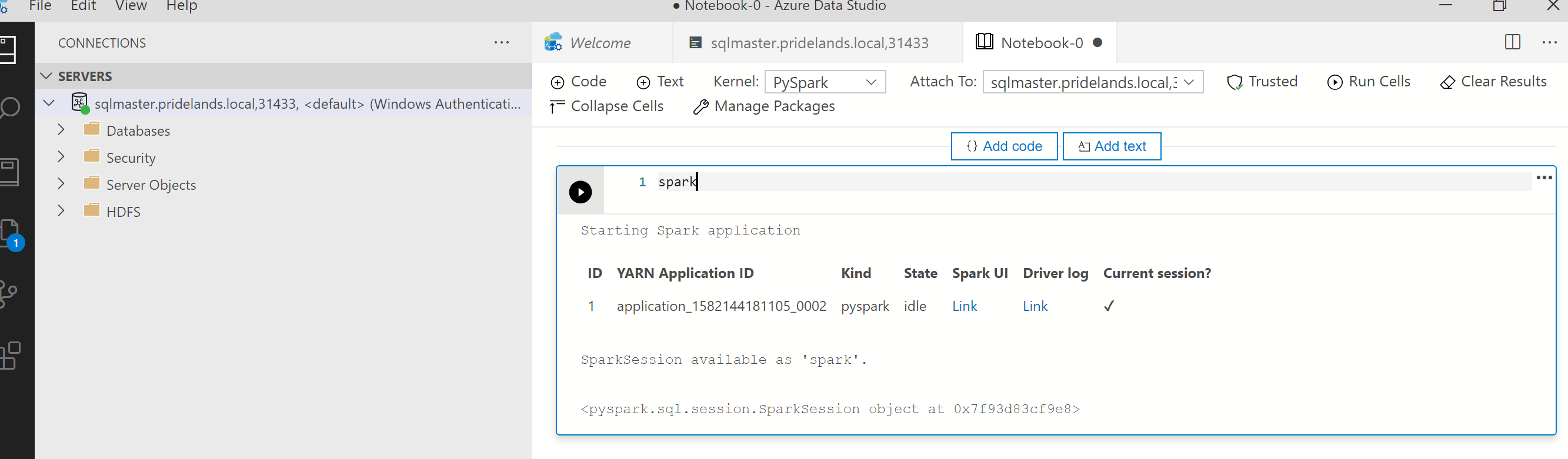
Récupérez les journaux.
Utilisez
azdata bdc debug copy-logspour l’analyse.L’exemple suivant connecte un point de terminaison de cluster Big Data pour copier les journaux. Mettez à jour les valeurs suivantes dans l’exemple avant de l’exécuter.
-
<ip_address>: point de terminaison du cluster Big Data. -
<username>: nom d’utilisateur du cluster Big Data. -
<namespace>: espace de noms Kubernetes du cluster. -
<folder_to_copy_logs>: chemin du dossier local où seront copiés les journaux.
azdata login --auth basic --username <username> --endpoint https://<ip_address>:30080 azdata bdc debug copy-logs -n <namespace> -d <folder_to_copy_logs>Exemple de sortie
<user>@<server>:~$ azdata bdc debug copy-logs -n <namespace> -d copy_logs Collecting the logs for cluster '<namespace>'. Collecting logs for containers... Creating an archive from logs-tmp/<namespace>. Log files are archived in /home/<user>/copy_logs/debuglogs-<namespace>-YYYYMMDD-HHMMSS.tar.gz. Creating an archive from logs-tmp/dumps. Log files are archived in /home/<user>/copy_logs/debuglogs-<namespace>-YYYYMMDD-HHMMSS-dumps.tar.gz. Collecting the logs for cluster 'kube-system'. Collecting logs for containers... Creating an archive from logs-tmp/kube-system. Log files are archived in /home/<user>/copy_logs/debuglogs-kube-system-YYYYMMDD-HHMMSS.tar.gz. Creating an archive from logs-tmp/dumps. Log files are archived in /home/<user>/copy_logs/debuglogs-kube-system-YYYYMMDD-HHMMSS-dumps.tar.gz.-
Examinez les journaux Livy. Ils se trouvent à l’emplacement suivant :
<namespace>\sparkhead-0\hadoop-livy-sparkhistory\supervisor\log.- Recherchez l’ID d’application YARN dans la première cellule du notebook PySpark.
- Recherchez le statut
ERR.
Voici un exemple de journal Livy dont l’état est
YARN ACCEPTED. Livy a soumis l’application YARN.HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO impl.YarnClientImpl: Submitted application application_<application_id> YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO yarn.Client: Application report for application_<application_id> (state: ACCEPTED) YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO yarn.Client: YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: client token: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: diagnostics: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: ApplicationMaster host: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: ApplicationMaster RPC port: -1 YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: queue: default YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: start time: ############ YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: final status: UNDEFINED YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: tracking URL: https://sparkhead-1.fnbm.corp:8090/proxy/application_<application_id>/ YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: user: <account>Examinez l’interface utilisateur YARN.
Récupérez l’URL du point de terminaison YARN sur le tableau de bord de gestion Clusters Big Data Azure Data Studio ou exécutez
azdata bdc endpoint list –o table.Par exemple :
azdata bdc endpoint list -o tableRetours
Description Endpoint Name Protocol ------------------------------------------------------ ---------------------------------------------------------------- -------------------------- ---------- Gateway to access HDFS files, Spark https://knox.<namespace-value>.local:30443 gateway https Spark Jobs Management and Monitoring Dashboard https://knox.<namespace-value>.local:30443/gateway/default/sparkhistory spark-history https Spark Diagnostics and Monitoring Dashboard https://knox.<namespace-value>.local:30443/gateway/default/yarn yarn-ui https Application Proxy https://proxy.<namespace-value>.local:30778 app-proxy https Management Proxy https://bdcmon.<namespace-value>.local:30777 mgmtproxy https Log Search Dashboard https://bdcmon.<namespace-value>.local:30777/kibana logsui https Metrics Dashboard https://bdcmon.<namespace-value>.local:30777/grafana metricsui https Cluster Management Service https://bdcctl.<namespace-value>.local:30080 controller https SQL Server Master Instance Front-End sqlmaster.<namespace-value>.local,31433 sql-server-master tds SQL Server Master Readable Secondary Replicas sqlsecondary.<namespace-value>.local,31436 sql-server-master-readonly tds HDFS File System Proxy https://knox.<namespace-value>.local:30443/gateway/default/webhdfs/v1 webhdfs https Proxy for running Spark statements, jobs, applications https://knox.<namespace-value>.local:30443/gateway/default/livy/v1 livy httpsVérifiez l’ID de l’application et les différents journaux application_master et container.
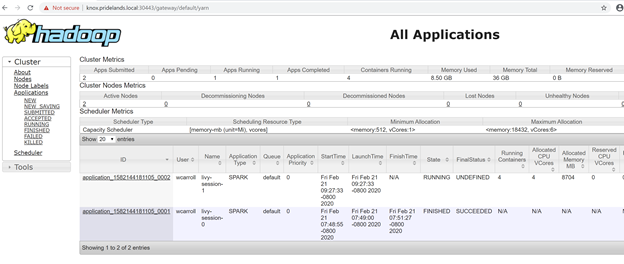
Examinez les journaux des applications YARN.
Récupérez le journal de l’application. Utilisez
kubectlpour vous connecter au podsparkhead-0, par exemple :kubectl exec -it sparkhead-0 -- /bin/bashMaintenant, exécutez cette commande dans ce shell en utilisant le bon
application_id:yarn logs -applicationId application_<application_id>Recherchez des erreurs ou des piles.
Voici un exemple d’erreur d’autorisation vis-à-vis de HDFS. Dans la pile Java, recherchez
Caused by::YYYY-MM-DD HH:MM:SS,MMM ERROR spark.SparkContext: Error initializing SparkContext. org.apache.hadoop.security.AccessControlException: Permission denied: user=<account>, access=WRITE, inode="/system/spark-events":sph:<bdc-admin>:drwxr-xr-x at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:399) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:255) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:193) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1852) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1836) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1795) at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.resolvePathForStartFile(FSDirWriteFileOp.java:324) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInt(FSNamesystem.java:2504) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileChecked(FSNamesystem.java:2448) Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=<account>, access=WRITE, inode="/system/spark-events":sph:<bdc-admin>:drwxr-xr-xExaminez l’interface utilisateur Spark.
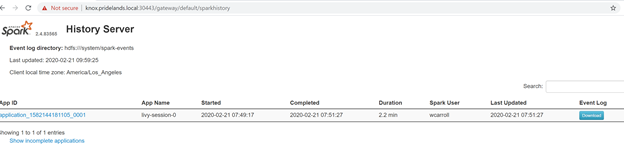
Descendez dans la hiérarchie des étapes pour trouver des erreurs dans les tâches.
Étapes suivantes
Résolution des problèmes d’intégration à Active Directory des clusters Big Data SQL Server