Mettre à niveau les réplicas de groupe de disponibilité
S'applique à : ![]() SQL Server
SQL Server
Pendant la mise à niveau d’une instance SQL Server hébergeant un groupe de disponibilité Always On vers une nouvelle version de SQL Server, un nouveau Service Pack SQL Server ou une mise à jour cumulative, ou pendant l’installation d’un nouveau Service Pack ou d’une nouvelle mise à jour cumulative Windows, vous pouvez réduire le temps d’arrêt du réplica principal à un seul basculement manuel en effectuant une mise à niveau propagée (ou deux basculements manuels en cas de restauration automatique vers l’instance principale d’origine).
Pendant le processus de mise à niveau, un réplica secondaire n’est pas disponible pour le basculement ni pour des opérations en lecture seule. Après la mise à niveau, le réplica secondaire peut avoir besoin d’un certain temps pour rattraper son retard par rapport au nœud de réplica principal en fonction du volume d’activité sur ce dernier (attendez-vous à un trafic réseau important).
Sachez également qu’après le basculement initial vers un réplica secondaire exécutant une version plus récente de SQL Server, les bases de données de ce groupe de disponibilité s’exécuteront via un processus de mise à niveau vers la version la plus récente. Pendant ce temps, aucun réplica lisible ne sera présent pour aucune de ces bases de données. Le temps d’arrêt après le basculement initial dépend du nombre de bases de données dans le groupe de disponibilité. Si vous prévoyez une restauration automatique sur le réplica principal d’origine, cette étape n’est pas répétée quand vous procédez à la restauration automatique.
Notes
Cet article ne concerne que la mise à niveau de SQL Server lui-même. Il ne couvre pas la mise à niveau du système d’exploitation contenant le cluster de basculement Windows Server (WSFC). La mise à niveau du système d’exploitation Windows qui héberge le cluster de basculement n’est pas prise en charge psr les systèmes d’exploitation antérieurs à Windows Server 2012 R2. Pour mettre à niveau un nœud de cluster s’exécutant sur Windows Server 2012 R2, consultez la rubrique Cluster Operating System Rolling Upgrade (Mise à niveau propagée du système d’exploitation de cluster).
Prérequis
Avant de commencer, passez en revue les informations importantes suivantes :
Mises à niveau des éditions et versions prises en charge : vérifiez que vous pouvez effectuer une mise à niveau vers la dernière version de SQL Server depuis votre version du système d’exploitation Windows et votre version de SQL Server. Par exemple, si vous effectuez une mise à niveau directement à partir d’une instance SQL Server 2005, votre niveau de compatibilité de la base de données sera mis à niveau.
Choisir une méthode de mise à niveau du moteur de base de données : pour effectuer la mise à niveau dans l’ordre correct, sélectionnez la méthode et les étapes de mise à niveau appropriées après avoir passé en revue les mises à niveau des éditions et versions prises en charge, en fonction des autres composants installés dans votre environnement.
Planifier et tester le plan de mise à niveau du moteur de base de données : consultez les notes de publication et les problèmes de mise à niveau connus ainsi que la liste de contrôle préalable à la mise à niveau, puis développez et testez votre plan de mise à niveau.
Exigences matérielle et logicielle pour l’installation de SQL Server : passez en revue les exigences logicielles pour l’installation de SQL Server. Si des logiciels supplémentaires sont nécessaires, installez-les sur chaque nœud avant de commencer le processus de mise à niveau pour réduire les éventuels temps d’arrêt.
Vérifiez si la capture des changements de données ou la réplication est utilisée pour des bases de données de groupe de disponibilité : si une base de données dans le groupe de disponibilité est activée pour la capture des changements de données (CDC), suivez ces instructions.
Notes
Avoir plusieurs versions différentes des instances de SQL Server dans le même groupe de disponibilité n’est pas pris en charge en dehors d’une mise à niveau propagée. En outre, cet état ne devrait pas durer pendant de longues périodes, étant donné que la mise à niveau doit avoir lieu rapidement. L’autre option pour la mise à niveau de SQL Server 2016 (13.x) et versions ultérieures consiste à utiliser un groupe de disponibilité distribué.
Remarque
L’utilisation de la fonctionnalité Mise à jour prenant en charge les clusters Windows pour mettre à jour les groupes de disponibilité Always On n’est pas prise en charge.
Concepts de base de la mise à niveau propagée pour les groupes de disponibilité
Consultez les instructions suivantes pour effectuer la mise à niveau/mise à jour du serveur afin de réduire le temps d’arrêt et la perte de données de vos groupes de disponibilité :
Avant de commencer la mise à niveau propagée :
Procédez à un essai de basculement manuel sur au moins l’une de vos instances de réplica avec validation synchrone.
Protégez vos données en effectuant une sauvegarde complète de chaque base de données de disponibilité.
Exécutez
DBCC CHECKDBsur chaque base de données de disponibilité
Procédez toujours d’abord à la mise à niveau des instances du réplica secondaire distant, puis des instances du réplica secondaire local et enfin de l’instance du réplica principal.
Les sauvegardes ne peuvent pas être exécutées dans une base de données qui est en cours de mise à niveau. Avant de mettre les réplicas secondaires à niveau, configurez la préférence de sauvegarde automatisée pour exécuter les sauvegardes uniquement sur le réplica principal. Pendant une mise à niveau de version, aucun réplica n’est lisible ou disponible pour les sauvegardes. Pendant une mise à niveau sans version, vous pouvez configurer des sauvegardes automatisées s’exécutant sur des réplicas secondaires avant la mise à niveau du réplica principal.
Pendant une mise à niveau de version, les instances de réplica secondaire accessibles en écriture ne peuvent pas être lues après une mise à niveau d’un réplica secondaire et avant que le réplica principal ne soit basculé vers un réplica secondaire mis à niveau ou que le réplica principal ne soit mis à niveau.
Pour éviter les basculements involontaires des groupes de disponibilité pendant le processus de mise à niveau, supprimez le basculement des groupes de disponibilité dans tous les réplicas avec validation synchrone avant de commencer.
Ne mettez à pas à niveau l’instance du réplica principal avant de basculer le groupe de disponibilité sur une instance mise à niveau qui a un réplica secondaire. Sinon, les applications clientes risquent de connaître des temps morts prolongés lors de la mise à niveau sur l’instance de réplica principal.
Basculez toujours le groupe de disponibilité sur une instance de réplica secondaire avec validation synchrone. Si vous basculez le groupe de disponibilité sur une instance de réplica secondaire en validation asynchrone, les bases de données sont exposées à une perte de données, et le déplacement des données est automatiquement suspendu jusqu’à ce que vous le repreniez manuellement.
Ne procédez pas à la mise à niveau de l’instance de réplica principal avant la mise à niveau ou à jour des instances nœuds de réplica secondaire. Un réplica principal mis à niveau n’envoie plus les journaux à un réplica secondaire dont l’instance SQL Server n’a pas encore été mise à niveau à la même version. Lorsque le déplacement des données vers un réplica secondaire est suspendu, aucun basculement automatique ne se produit pour ce réplica, et vos bases de données de disponibilité sont vulnérables à une perte de données. Cela s’applique également lors d’une mise à niveau propagée dans laquelle vous basculez manuellement d’un ancien réplica principal vers un nouveau réplica principal. Ainsi, après avoir mis à niveau l’ancien réplica principal, vous pouvez être amené à reprendre la synchronisation.
Avant de basculer un groupe de disponibilité, vérifiez que l’état de synchronisation de la cible de basculement est
SYNCHRONIZED.Avertissement
L’installation d’une nouvelle instance ou d’une nouvelle version de SQL Server sur un serveur sur lequel une version antérieure de SQL Server installée peut provoquer par inadvertance une panne pour tout groupe de disponibilité hébergé par l’ancienne version de SQL Server. En effet, pendant l’installation de l’instance ou de la version de SQL Server, le module de haute disponibilité SQL Server (RHS.EXE) est mis à niveau. Cela occasionne une interruption temporaire de vos groupes de disponibilité existants dans le rôle principal du serveur. Ainsi, il est vivement recommandé d’effectuer l’une des tâches suivantes au moment d’installer une version plus récente de SQL Server sur un système qui héberge déjà une version antérieure de SQL Server avec un groupe de disponibilité :
Installer la nouvelle version de SQL Server dans le cadre d’une fenêtre de maintenance.
Faire basculer le groupe de disponibilité vers le réplica secondaire pour éviter qu’il soit le réplica principal pendant l’installation de la nouvelle instance de SQL Server.
Processus de mise à niveau propagée
Dans la pratique, le processus exact dépend de facteurs comme la topologie de déploiement de vos groupes de disponibilité et du mode de validation de chaque réplica. Cependant, dans le scénario le plus simple, une mise à niveau propagée est un processus en plusieurs étapes impliquant les étapes suivantes :
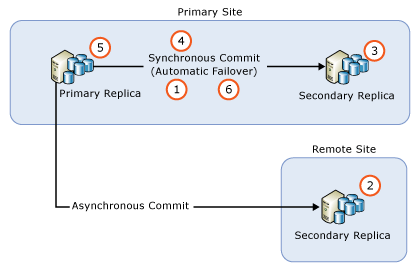
- Supprimer le basculement automatique sur tous les réplicas avec validation synchrone
- Mettre à niveau toutes les instances de réplica secondaire avec validation asynchrone.
- Mettre à niveau toutes les instances de réplica secondaire distant avec validation synchrone.
- Mettre à niveau toutes les instances de réplica secondaire local avec validation synchrone.
- Basculer manuellement le groupe de disponibilité (qui vient d’être mis à niveau) sur un réplica secondaire local avec validation synchrone.
- Mettre à niveau ou mettre à jour l’instance de réplica local qui hébergeait précédemment le réplica principal.
- Configurer le basculement automatique des partenaires de basculement selon les besoins.
Si nécessaire, effectuez un basculement manuel supplémentaire pour rétablir la configuration d’origine du groupe de disponibilité.
Notes
La mise à niveau d’un réplica avec validation synchrone et sa mise hors connexion ne retardent pas les transactions sur le réplica principal. Une fois que le réplica secondaire est déconnecté, les transactions sont validées sur le réplica principal sans attendre les journaux pour renforcer la sécurité sur le réplica secondaire.
Si REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT est défini sur 1 ou 2, le réplica principal peut ne pas être disponible pour les opérations en lecture/écriture quand il n’y a pas le nombre correspondant de réplicas secondaires de synchronisation disponibles pendant le processus de mise à jour.
Notes
Quand vous effectuez une mise à niveau sur place d’un réplica secondaire vers une version plus récente de SQL Server, la base de données dans le groupe de disponibilité reste à l’état Synchronisation/En récupération ou Synchronisé/En récupération jusqu’à ce que le groupe de disponibilité soit basculé manuellement, ce qui termine la récupération et met à niveau la base de données. Un réplica principal mis à niveau ne peut plus envoyer de journaux vers un réplica secondaire de version inférieure et le déplacement des données s’arrête. Aucun basculement automatique ne peut se produire pour ce réplica, et vos bases de données de disponibilité sont vulnérables à la perte de données. Après avoir mis à niveau l’ancien réplica principal, vous pouvez être amené à reprendre la synchronisation. Il est recommandé de mettre à niveau tous les réplicas secondaires avant de basculer vers un réplica avec la nouvelle version. De cette façon, vous avez la possibilité d’effectuer un basculement après la mise à niveau des bases de données vers le nouveau format.
Groupe de disponibilité avec un réplica secondaire distant
Si vous avez déployé un groupe de disponibilité uniquement pour la récupération d’urgence, vous devez peut-être le basculer sur un réplica secondaire avec validation asynchrone. Cette configuration est illustrée dans la figure ci-dessous :
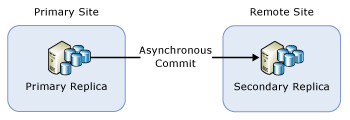
Dans ce cas, vous devez basculer le groupe de disponibilité sur le réplica secondaire avec validation asynchrone pendant la mise à niveau propagée. Pour éviter la perte de données, changez le mode de validation en validation synchrone et patientez jusqu’à ce que le réplica secondaire soit synchronisé avant de basculer le groupe de disponibilité. Par conséquent, le processus de mise à niveau à jour peut ressembler à ce qui suit :
- Mise à niveau l’instance de réplica secondaire sur le site distant
- Changer le mode de validation en validation synchrone
- Patienter jusqu’à ce que l’état de synchronisation soit
SYNCHRONIZED - Basculer le groupe de disponibilité sur le réplica secondaire du site distant
- Mettre à niveau ou mettre à jour l’instance de réplica local (site principal)
- Rebasculer le groupe de disponibilité sur le site principal
- Changer le mode de validation en validation asynchrone
Étant donné que le mode de validation synchrone n’est pas recommandé pour la synchronisation des données sur un site distant, les applications clientes peuvent remarquer une augmentation immédiate de la latence de la base de données après la modification du paramètre. Par ailleurs, avec le basculement, tous les messages du journal sans accusé de réception sont ignorés. Le nombre de messages de journal ignorés peut être important en raison de la latence réseau élevée entre les deux sites, à l’origine d’un grand nombre d’échecs de transactions des clients. Vous pouvez réduire l’impact sur les applications clientes en procédant comme suit :
Sélectionnez avec précaution une fenêtre de maintenance lorsque le trafic est faible sur le client
Lors de la mise à niveau ou mise à jour sur le site principal SQL Server , revenez au mode de disponibilité validation asynchrone, puis rétablissez la validation synchrone lorsque vous êtes prêt à effectuer le basculement sur le site principal
Groupe de disponibilité avec des nœuds d’instance de cluster de basculement
Si un groupe de disponibilité contient des nœuds d’instance de cluster de basculement, mettez à niveau les nœuds inactifs avant de mettre à niveau les nœuds actifs. La figure suivante illustre un scénario courant de groupe de disponibilité avec des instances de cluster de basculement pour une haute disponibilité locale et avec une validation asynchrone entre instances de cluster de basculement pour la récupération d’urgence, ainsi que la séquence de mise à niveau.
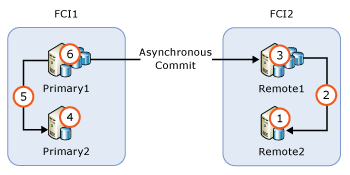
- Mettre à niveau ou à jour
REMOTE2 - Basculer FCI2 sur
REMOTE2 - Mettre à niveau ou à jour
REMOTE1 - Mettre à niveau ou à jour
PRIMARY2 - Basculer FCI1 sur
PRIMARY2 - Mettre à niveau ou à jour
PRIMARY1
Mettre à niveau ou à jour des instances SQL Server avec plusieurs groupes de disponibilité
Si vous exécutez plusieurs groupes de disponibilité avec des réplicas principaux sur des nœuds de serveur distincts (configuration active/active), le chemin de mise à niveau implique des étapes de basculement supplémentaires pour assurer la haute disponibilité dans le processus. Supposons que vous exécutez trois groupes de disponibilité sur trois nœuds de serveur et que tous les réplicas s’exécutent en mode de validation synchrone, comme l’illustre le tableau suivant :
| Groupe de disponibilité | Nœud1 | Nœud2 | Node3 |
|---|---|---|---|
| AG1 | Principal | ||
| AG2 | Principal | ||
| AG3 | Principal |
Il peut s'avérer nécessaire d'effectuer une mise à niveau/ propagée à charge équilibrée dans l'ordre suivant :
- Basculer AG2 sur
Node3(pour libérerNode2) - Mettre à niveau ou à jour
Node2 - Basculer AG1 sur
Node2(pour libérerNode1) - Mettre à niveau ou à jour
Node1 - Basculer AG2 et AG3 sur
Node1(pour libérerNode3) - Mettre à niveau ou à jour
Node3 - Basculer AG3 sur
Node3
Cette séquence de mise à niveau a un temps d’arrêt moyen de moins de deux basculements par groupe de disponibilité. La configuration obtenue est illustrée dans le tableau suivant.
| Groupe de disponibilité | Nœud1 | Nœud2 | Node3 |
|---|---|---|---|
| AG1 | Principal | ||
| AG2 | Principal | ||
| AG3 | Principal |
Le chemin d'accès de la mise à niveau varie selon votre implémentation. Le temps mort que les applications clientes peuvent rencontrer varie également.
Notes
Dans de nombreux cas, une fois la mise à niveau propagée terminée, vous rebasculez sur le réplica principal d’origine.
Mise à niveau propagée d’un groupe de disponibilité distribué
Pour effectuer une mise à niveau propagée d’un groupe de disponibilité distribué, commencez par mettre à niveau tous les réplicas secondaires. Ensuite, basculez vers le redirecteur et mettez à niveau la dernière instance restante du deuxième groupe de disponibilité. Une fois que tous les autres réplicas ont été mis à niveau, basculez vers le réplica principal global et mettez à niveau la dernière instance restante du premier groupe de disponibilité. Vous trouverez ci-dessous un diagramme détaillé avec les étapes.
Le chemin d'accès de la mise à niveau varie selon votre implémentation. Le temps mort que les applications clientes peuvent rencontrer varie également.
Notes
Dans de nombreux cas, une fois la mise à niveau propagée terminée, vous rebasculez sur les réplicas principaux d’origine.
Étapes générales pour mettre à niveau un groupe de disponibilité distribué
- Sauvegardez toutes les bases de données, notamment les bases de données système et celles qui font partie du groupe de disponibilité.
- Mettez à niveau et redémarrez tous les réplicas secondaires du deuxième groupe de disponibilité (aval).
- Mettez à niveau et redémarrez tous les réplicas secondaires du premier groupe de disponibilité (amont).
- Basculez le réplica principal redirecteur vers un réplica secondaire mis à niveau du groupe de disponibilité secondaire.
- Attendez la synchronisation des données. Les bases de données doivent apparaître synchronisées sur tous les réplicas en validation synchrone, tandis que le réplica principal global doit être synchronisé avec le redirecteur.
- Mettez à niveau et redémarrez la dernière instance restante du groupe de disponibilité secondaire.
- Basculez le réplica principal global vers un réplica secondaire mis à niveau du premier groupe de disponibilité.
- Mettez à niveau la dernière instance restante du groupe de disponibilité principal.
- Redémarrez le serveur qui vient d’être mis à niveau.
- (facultatif) Rebasculez les deux groupes de disponibilité vers leurs réplicas principaux d’origine.
Important
Vérifiez la synchronisation entre chaque étape. Avant de passer à l’étape suivante, vérifiez que vos réplicas en validation synchrone sont synchronisés dans le groupe de disponibilité, et que votre réplica principal global est synchronisé avec le redirecteur dans le groupe de disponibilité distribué.
Recommandation : chaque fois que vous vérifiez la synchronisation, actualisez le nœud de base de données et le nœud de groupe de disponibilité distribué dans SQL Server Management Studio. Une fois que tout est synchronisé, enregistrez une capture d’écran de l’état de chaque réplica. Elle vous permettra de savoir à quelle étape vous êtes, de fournir la preuve que tout fonctionnait correctement avant l’étape suivante et vous aidera à résoudre les problèmes en cas de défaillance.
Exemple de diagramme d’une mise à niveau propagée d’un groupe de disponibilité distribué
| Groupe de disponibilité | Réplica principal | Réplica secondaire |
|---|---|---|
| AG1 | NODE1\SQLAG |
NODE2\SQLAG |
| AG2 | NODE3\SQLAG |
NODE4\SQLAG |
| Groupe de disponibilité distribué | GD1 (global) | GD2 (redirecteur) |
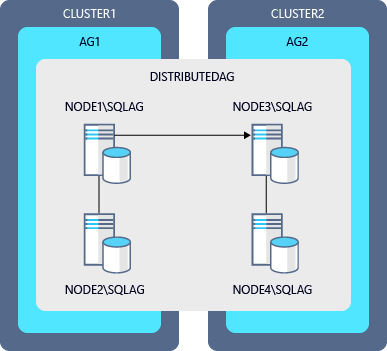
Voici les étapes pour mettre à niveau les instances de ce diagramme :
- Sauvegardez toutes les bases de données, notamment les bases de données système et celles qui font partie du groupe de disponibilité.
- Mettez à niveau
NODE4\SQLAG(secondaire de AG2) et redémarrez le serveur. - Mettez à niveau
NODE2\SQLAG(secondaire de AG1) et redémarrez le serveur. - Basculez AG2 de
NODE3\SQLAGsurNODE4\SQLAG. - Mettez à niveau
NODE3\SQLAGet redémarrez le serveur. - Basculez AG1 de
NODE1\SQLAGsurNODE2\SQLAG. - Mettez à niveau
NODE1\SQLAGet redémarrez le serveur. - (facultatif) Restaurez les réplicas principaux d’origine.
- Rebasculez AG2 de
NODE4\SQLAGsurNODE3\SQLAG. - Rebasculez AG1 de
NODE2\SQLAGsurNODE1\SQLAG.
- Rebasculez AG2 de
Si un troisième réplica existe dans chaque groupe de disponibilité, il est mis à niveau avant NODE3\SQLAG et NODE1\SQLAG.
Important
Vérifiez la synchronisation entre chaque étape. Avant de passer à l’étape suivante, vérifiez que vos réplicas en validation synchrone sont synchronisés dans le groupe de disponibilité, et que votre réplica principal global est synchronisé avec le redirecteur dans le groupe de disponibilité distribué.
Recommandation : chaque fois que vous vérifiez la synchronisation, actualisez à la fois le nœud de la base de données et le nœud du groupe de disponibilité distribué dans SQL Server Management Studio. Une fois que tout est synchronisé, prenez une capture d’écran et enregistrez-la. Elle vous permettra de savoir à quelle étape vous êtes, de fournir la preuve que tout fonctionnait correctement avant l’étape suivante et vous aidera à résoudre les problèmes en cas de défaillance.
Étapes spéciales pour la capture de données modifiées ou la réplication
En fonction de la mise à jour appliquée, des étapes supplémentaires peuvent être nécessaires pour les bases de données de réplica de groupe de disponibilité qui sont activées pour la réplication ou la capture de données modifiées. Consultez les notes de publication de la mise à jour pour déterminer si les étapes suivantes sont nécessaires :
Mettez à niveau chaque réplica secondaire.
Une fois tous les réplicas secondaires mis à niveau, basculez le groupe de disponibilité sur une instance mise à niveau.
Exécutez l’instruction Transact-SQL suivante sur l’instance qui héberge le réplica principal :
EXECUTE [master].[sys].[sp_vupgrade_replication];Notes
L’exécution de cette commande peut durer plusieurs minutes. Ignorez cette étape si vous utilisez SQL Server 2019 CU1 ou version ultérieure. Pour plus d’informations, passez en revue KB4530283
Mettez à niveau l’instance qui était le réplica principal à l’origine.
Pour plus d’informations, consultez Les fonctionnalités de capture de données modifiées peuvent s’interrompre après la mise à niveau vers la dernière version CU.