Création d’histogrammes en Python
S’applique à : ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Cet article explique comment représenter des données sous forme graphique à l’aide du package Python Pandas hist(). Une base de données SQL est la source utilisée pour visualiser les intervalles de données d’histogramme dont les valeurs sont consécutives et ne se chevauchent pas.
Prérequis
SQL Server Management Studio pour restaurer l’exemple de base de données sur Azure SQL Managed Instance.
Azure Data Studio. Pour l’installer, consultez Azure Data Studio.
Exemple de restauration de base de données DW pour obtenir les exemples de données utilisés dans cet article.
Vérification de la base de données restaurée
Vous pouvez vérifier que la base de données restaurée existe en interrogeant la table Person.CountryRegion :
USE AdventureWorksDW;
SELECT * FROM Person.CountryRegion;
Installer des packages Python
Téléchargez et installez Azure Data Studio.
Installez les packages Python suivants :
pyodbcpandassqlalchemymatplotlib
Pour installer ces packages :
- Dans votre notebook Azure Data Studio, sélectionnez Gérer les packages.
- Dans le volet Gérer les packages, sélectionnez l’onglet Ajouter nouveau.
- Pour chacun des packages suivants, entrez le nom du package, sélectionnez Rechercher, puis Installer.
Création de l’histogramme
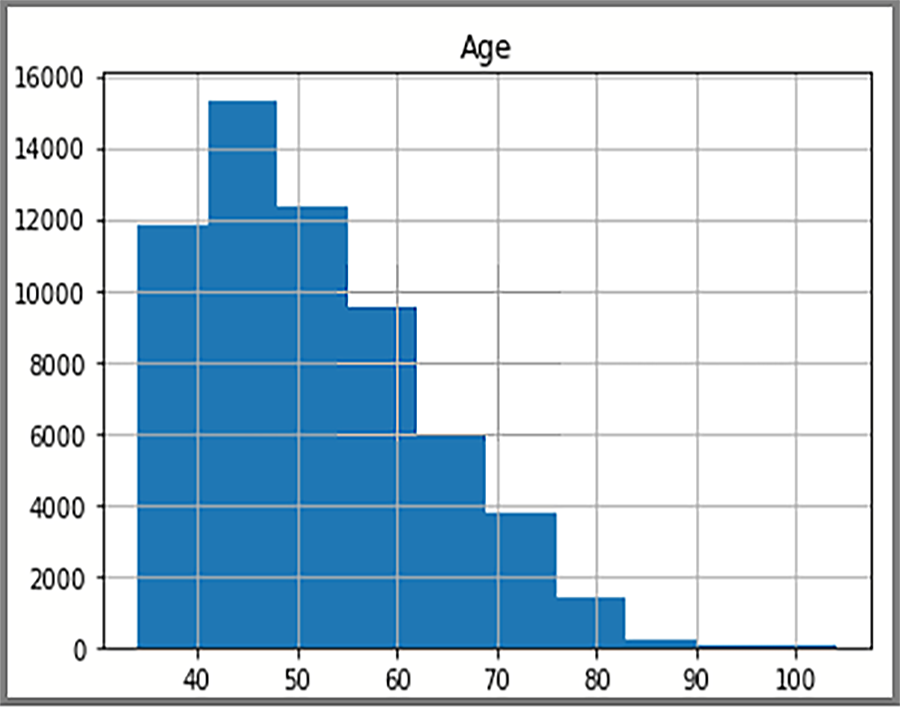
Les données distribuées affichées dans l’histogramme s’appuient sur une requête SQL de AdventureWorksDW2022. L’histogramme permet de visualiser les données et la fréquence des valeurs de données.
Modifiez les variables de chaîne de connexion « server », « database », « username » et « password » pour vous connecter à la base de données SQL Server.
Pour créer un bloc-notes :
- Dans Azure Data Studio, sélectionnez Fichier, puis Nouveau notebook.
- Dans le notebook, sélectionnez le noyau Python3, puis +code.
- Collez le code dans le notebook, puis sélectionnez Tout exécuter.
import pyodbc
import pandas as pd
import matplotlib
import sqlalchemy
from sqlalchemy import create_engine
matplotlib.use('TkAgg', force=True)
from matplotlib import pyplot as plt
# Some other example server values are
# server = 'localhost\sqlexpress' # for a named instance
# server = 'myserver,port' # to specify an alternate port
server = 'servername'
database = 'AdventureWorksDW2022'
username = 'yourusername'
password = 'databasename'
url = 'mssql+pyodbc://{user}:{passwd}@{host}:{port}/{db}?driver=SQL+Server'.format(user=username, passwd=password, host=server, port=port, db=database)
engine = create_engine(url)
sql = "SELECT DATEDIFF(year, c.BirthDate, GETDATE()) AS Age FROM [dbo].[FactInternetSales] s INNER JOIN dbo.DimCustomer c ON s.CustomerKey = c.CustomerKey"
df = pd.read_sql(sql, engine)
df.hist(bins=50)
plt.show()
L’affichage présente la distribution de l’âge des clients dans la table FactInternetSales.