Configurer un client de science des données pour le développement Python sur SQL Server Machine Learning Services
S’applique à : ![]() SQL Server 2016 (13.x),
SQL Server 2016 (13.x), ![]() SQL Server 2017 (14.x) et
SQL Server 2017 (14.x) et ![]() SQL Server 2019 (15.x),
SQL Server 2019 (15.x), ![]() SQL Server 2019 (15.x) - Linux
SQL Server 2019 (15.x) - Linux
L’intégration de Python est disponible dans SQL Server 2017 (et versions ultérieures) quand vous incluez l’option python dans une installation Machine Learning Services (en base de données).
Notes
Cet article s’applique à SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) et SQL Server 2019 (15.x) pour Linux uniquement.
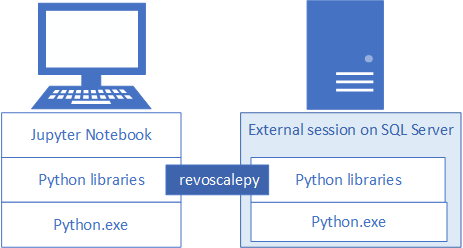
Pour développer et déployer des solutions Python pour SQL Server, installez la bibliothèque revoscalepy de Microsoft et les autres bibliothèques Python sur votre station de travail de développement. La bibliothèque revoscalepy, qui se trouve également sur l’instance SQL Server distante, coordonne les demandes de traitement entre les deux systèmes.
Cet article explique comment configurer une station de travail de développement Python pour interagir avec une instance SQL Server distante activée pour le machine learning et l’intégration de Python. Après avoir effectué les étapes décrites dans cet article, vous aurez les mêmes bibliothèques Python que celles disponibles sur SQL Server. Vous saurez également comment envoyer (push) les calculs d’une session Python locale vers une session Python à distance sur SQL Server.
Pour valider l’installation, vous pouvez utiliser les notebooks Jupyter intégrés comme décrit dans cet article ou lier les bibliothèques à PyCharm ou à tout autre IDE que vous utilisez généralement.
Conseil
Pour voir une démonstration vidéo de ces exercices, consultez Exécuter R et Python à distance dans SQL Server à partir de notebooks Jupyter.
Outils couramment utilisés
Que vous soyez un développeur Python qui débute avec SQL ou un développeur SQL qui découvre Python et l’analytique en base de données, vous aurez besoin d’un outil de développement Python et d’un éditeur de requête T-SQL comme SQL Server Management Studio (SSMS) pour exploiter toutes les fonctionnalités de l’analytique en base de données.
Pour le développement Python, vous pouvez utiliser des notebooks Jupyter, fournis dans la distribution Anaconda installée par SQL Server. Cet article explique comment démarrer les notebooks Jupyter pour exécuter du code Python localement et à distance sur SQL Server.
Disponible en téléchargement distinct, SSMS permet de créer et d’exécuter des procédures stockées sur SQL Server, y compris celles contenant du code Python. Presque tout le code Python que vous écrivez dans des notebooks Jupyter peut être incorporé à une procédure stockée. Vous pouvez consulter d’autres guides de démarrage rapide pour en savoir plus sur SSMS et le code Python incorporé.
1 - Installer des packages Python
Les stations de travail locales doivent avoir les mêmes versions de package Python que celles de SQL Server, y compris Anaconda 4.2.0 (package de base) avec la distribution Python 3.5.2 et les packages spécifiques à Microsoft.
Un script d’installation ajoute trois bibliothèques spécifiques à Microsoft au client Python. Le script installe :
- revoscalepy est utilisé pour définir des objets sources de données et le contexte de calcul.
- microsoftml, qui fournit des algorithmes de machine learning.
- azureml s’applique aux tâches d’opérationnalisation associées à un contexte de serveur autonome, et son utilité peut être limitée pour l’analytique en base de données.
Téléchargez un script d’installation. Sur la page GitHub appropriée qui suit, sélectionnez Télécharger le fichier brut.
https://aka.ms/mls-py installe la version 9.2.1 des packages Microsoft Python. Cette version correspond à une instance SQL Server par défaut.
https://aka.ms/mls93-py installe la version 9.3 des packages Microsoft Python.
Ouvrez une fenêtre PowerShell avec des autorisations d’administrateur élevées (cliquez avec le bouton droit sur Exécuter en tant qu’administrateur).
Accédez au dossier dans lequel vous avez téléchargé le programme d’installation et exécutez le script. Ajoutez l’argument de ligne de commande
-InstallFolderpour spécifier un emplacement de dossier pour les bibliothèques. Par exemple :cd {{download-directory}} .\Install-PyForMLS.ps1 -InstallFolder "C:\path-to-python-for-mls"
Si vous omettez le dossier d’installation, l’emplacement par défaut est %ProgramFiles%\Microsoft\PyForMLS.
L’installation prend un certain temps. Vous pouvez en suivre la progression dans la fenêtre PowerShell. Une fois l’installation terminée, vous disposez d’un ensemble de packages complet.
Conseil
Nous vous recommandons de consulter Questions fréquentes (FAQ) sur Python pour Windows pour obtenir des informations générales sur l’exécution de programmes Python sur Windows.
2 - Localiser les exécutables
Toujours dans PowerShell, listez le contenu du dossier d’installation pour vérifier que Python.exe, les scripts et les autres packages sont installés.
Entrez
cd \pour accéder au lecteur racine, puis entrez le chemin que vous avez spécifié pour-InstallFolderà l’étape précédente. Si vous avez omis ce paramètre au cours de l’installation, la valeur par défaut estcd %ProgramFiles%\Microsoft\PyForMLS.Entrez
dir *.exepour lister les exécutables. Vous devez voir python.exe, pythonw.exe et uninstall-anaconda.exe.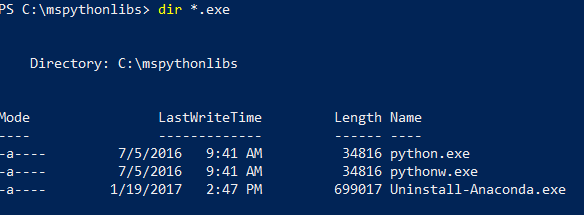
Sur les systèmes dotés de plusieurs versions de Python, n’oubliez pas d’utiliser ce fichier Python.exe en particulier si vous souhaitez charger revoscalepy et d’autres packages Microsoft.
Notes
Le script d’installation ne modifie pas la variable d’environnement PATH sur votre ordinateur. Le nouvel interpréteur Python et les nouveaux modules que vous venez d’installer ne sont donc pas automatiquement disponibles pour les autres outils que vous possédez. Pour obtenir de l’aide sur la liaison de l’interpréteur et des bibliothèques Python aux outils, consultez Installer un IDE.
3 - Ouvrir des notebooks Jupyter
Anaconda inclut Jupyter Notebook. Vous allez à présent créer un notebook et exécuter du code Python contenant les bibliothèques que vous venez d’installer.
À l’invite PowerShell, toujours dans le répertoire
%ProgramFiles%\Microsoft\PyForMLS, ouvrez les notebooks Jupyter à partir du dossier Scripts :.\Scripts\jupyter-notebookUn notebook doit s’ouvrir dans votre navigateur par défaut à l’adresse
https://localhost:8889/tree.Pour commencer, vous pouvez également double-cliquer sur jupyter-notebook.exe.
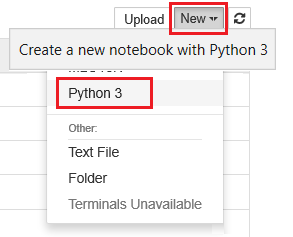
Sélectionnez Nouveau, puis Python 3.
Entrez
import revoscalepyet exécutez la commande pour charger l’une des bibliothèques spécifiques à Microsoft.Entrez et exécutez
print(revoscalepy.__version__)pour retourner les informations de version. Vous devez normalement voir 9.2.1 ou 9.3.0. Vous pouvez utiliser l’une de ces versions avec revoscalepy sur le serveur.Entrez une série d’instructions plus complexe. Dans cet exemple, des statistiques récapitulatives sont générées avec rx_summary sur un jeu de données local. Les autres fonctions récupèrent l’emplacement des exemples de données et créent un objet source de données pour un fichier .xdf local.
import os from revoscalepy import rx_summary from revoscalepy import RxXdfData from revoscalepy import RxOptions sample_data_path = RxOptions.get_option("sampleDataDir") print(sample_data_path) ds = RxXdfData(os.path.join(sample_data_path, "AirlineDemoSmall.xdf")) summary = rx_summary("ArrDelay+DayOfWeek", ds) print(summary)
La capture d’écran suivante montre l’entrée et une partie de la sortie, tronquée par souci de concision.

4 - Obtenir les autorisations SQL
Pour vous connecter à une instance de SQL Server afin d’exécuter des scripts et de charger des données, vous devez disposer d’un compte de connexion valide sur le serveur de base de données. Vous pouvez utiliser un compte de connexion SQL ou l’authentification Windows intégrée. Nous recommandons généralement d’utiliser l’authentification Windows intégrée. Il est cependant plus simple d’utiliser une connexion SQL dans certains scénarios, en particulier quand votre script contient des chaînes de connexion à des données externes.
Le compte utilisé pour exécuter le code doit disposer au minimum d’une autorisation de lecture à partir des bases de données avec lesquelles vous travaillez et de l’autorisation spéciale EXECUTE ANY EXTERNAL SCRIPT. La plupart des développeurs ont également besoin des autorisations permettant de créer des procédures stockées et d’écrire des données dans des tables contenant des données d’entraînement ou des données notées.
Demandez à l’administrateur de base de données de configurer les autorisations suivantes pour votre compte dans la base de données dans laquelle vous utilisez Python :
- EXECUTE ANY EXTERNAL SCRIPT pour exécuter Python sur le serveur.
- Privilèges db_datareader pour exécuter les requêtes utilisées pour l’entraînement du modèle.
- db_datawriter pour écrire les données d’entraînement ou les données notées.
- db_owner pour créer des objets tels que des procédures stockées, des tables et des fonctions. Vous avez également besoin de db_owner pour créer des exemples de base de données et des bases de données de test.
Si votre code nécessite des packages qui ne sont pas installés par défaut avec SQL Server, demandez à l’administrateur de base de données de prévoir l’installation des packages avec l’instance. SQL Server est un environnement sécurisé, qui impose des restrictions quant à l’emplacement d’installation des packages. L’installation ad hoc des packages dans le cadre de votre code n’est pas recommandée, même si vous disposez des droits nécessaires. Par ailleurs, observez toujours attentivement les implications en matière de sécurité avant d’installer de nouveaux packages dans la bibliothèque du serveur.
5 - Créer des données de test
Si vous disposez des autorisations nécessaires pour créer une base de données sur le serveur distant, vous pouvez exécuter le code suivant pour créer la base de données de démonstration Iris utilisée pour les prochaines étapes de cet article.
5-1 - Créer la base de données irissql à distance
import pyodbc
# creating a new db to load Iris sample in
new_db_name = "irissql"
connection_string = "Driver=SQL Server;Server=localhost;Database={0};Trusted_Connection=Yes;"
# you can also swap Trusted_Connection for UID={your username};PWD={your password}
cnxn = pyodbc.connect(connection_string.format("master"), autocommit=True)
cnxn.cursor().execute("IF EXISTS(SELECT * FROM sys.databases WHERE [name] = '{0}') DROP DATABASE {0}".format(new_db_name))
cnxn.cursor().execute("CREATE DATABASE " + new_db_name)
cnxn.close()
print("Database created")
5-2 - Importer l’exemple Iris à partir de SkLearn
from sklearn import datasets
import pandas as pd
# SkLearn has the Iris sample dataset built in to the package
iris = datasets.load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
5-3 - Utiliser les API Revoscalepy pour créer une table et charger les données Iris
from revoscalepy import RxSqlServerData, rx_data_step
# Example of using RX APIs to load data into SQL table. You can also do this with pyodbc
table_ref = RxSqlServerData(connection_string=connection_string.format(new_db_name), table="iris_data")
rx_data_step(input_data = df, output_file = table_ref, overwrite = True)
print("New Table Created: Iris")
print("Sklearn Iris sample loaded into Iris table")
6 - Tester la connexion à distance
Avant d’effectuer cette nouvelle étape, assurez-vous que vous disposez des autorisations sur l’instance SQL Server et d’une chaîne de connexion à l’exemple de base de données Iris. Si la base de données n’existe pas et que vous disposez des autorisations suffisantes, vous pouvez créer une base de données à l’aide de ces instructions inlined.
Remplacez la chaîne de connexion par des valeurs valides. L’exemple de code utilise "Driver=SQL Server;Server=localhost;Database=irissql;Trusted_Connection=Yes;", mais votre code doit spécifier un serveur distant avec, éventuellement, un nom d’instance et une option d’informations d’identification correspondant à une connexion de base de données.
6-1 Définir une fonction
Le code suivant définit une fonction que vous enverrez à SQL Server lors d’une prochaine étape. Quand il est exécuté, il utilise les données et les bibliothèques (revoscalepy, pandas et matplotlib) sur le serveur distant pour créer des nuages de points à partir du jeu de données Iris. Il retourne le flux d’octets du fichier .png aux notebooks Jupyter pour effectuer l’affichage dans le navigateur.
def send_this_func_to_sql():
from revoscalepy import RxSqlServerData, rx_import
from pandas.tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
import io
# remember the scope of the variables in this func are within our SQL Server Python Runtime
connection_string = "Driver=SQL Server;Server=localhost;Database=irissql;Trusted_Connection=Yes;"
# specify a query and load into pandas dataframe df
sql_query = RxSqlServerData(connection_string=connection_string, sql_query = "select * from iris_data")
df = rx_import(sql_query)
scatter_matrix(df)
# return bytestream of image created by scatter_matrix
buf = io.BytesIO()
plt.savefig(buf, format="png")
buf.seek(0)
return buf.getvalue()
6-2 Envoyer la fonction à SQL Server
Dans cet exemple, vous créez le contexte de calcul distant, puis vous transférez l’exécution de la fonction à SQL Server avec rx_exec. La fonction rx_exec est utile, car elle accepte un contexte de calcul comme argument. Toute fonction que vous souhaitez exécuter à distance doit avoir un argument de contexte de calcul. Certaines fonctions telles que rx_lin_mod prennent en charge cet argument directement. Pour les opérations n’assurant pas cette prise en charge directe, vous pouvez utiliser rx_exec pour placer votre code dans un contexte de calcul distant.
Dans cet exemple, aucune donnée brute n’a dû être transférée de SQL Server au notebook Jupyter. Tous les calculs sont effectués dans la base de données Iris et seul le fichier image est retourné au client.
from IPython import display
import matplotlib.pyplot as plt
from revoscalepy import RxInSqlServer, rx_exec
# create a remote compute context with connection to SQL Server
sql_compute_context = RxInSqlServer(connection_string=connection_string.format(new_db_name))
# use rx_exec to send the function execution to SQL Server
image = rx_exec(send_this_func_to_sql, compute_context=sql_compute_context)[0]
# only an image was returned to my jupyter client. All data remained secure and was manipulated in my db.
display.Image(data=image)
La capture d’écran suivante montre l’entrée et le nuage de points en sortie.

7 - Démarrer Python à partir d’outils
Comme les développeurs travaillent souvent avec plusieurs versions de Python, le programme d’installation n’ajoute pas Python à votre variable PATH. Pour utiliser les bibliothèques et l’exécutable Python installés par le programme d’installation, liez votre IDE à Python.exe, au chemin contenant également revoscalepy et microsoftml.
Ligne de commande
Quand vous exécutez Python.exe à partir de %ProgramFiles%\Microsoft\PyForMLS (ou de tout autre emplacement spécifié pour l’installation des bibliothèques de client Python), vous avez accès à la distribution Anaconda complète et aux modules Microsoft Python revoscalepy et microsoftml.
- Accédez à
%ProgramFiles%\Microsoft\PyForMLSet exécutez Python.exe. - Ouvrez l’aide interactive :
help(). - Tapez le nom d’un module à l’invite de l’aide :
help> revoscalepy. L’aide retourne le nom, le contenu du package, la version et l’emplacement du fichier. - Renvoyez la version et les informations relatives au package à l’invite help> :
revoscalepy. Appuyez sur Entrée plusieurs fois pour quitter l’aide. - Importez un module :
import revoscalepy.
Notebooks Jupyter
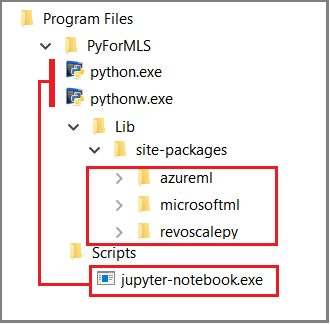
Dans cet article, nous utilisons des notebooks Jupyter intégrés pour illustrer les appels de fonction à revoscalepy. Si vous débutez avec cet outil, reportez-vous à la capture d’écran suivante, qui montre comment s’imbriquent les différents éléments et comment l’ensemble fonctionne.
Le dossier parent %ProgramFiles%\Microsoft\PyForMLS contient Anaconda et les packages Microsoft. Jupyter Notebook est inclus dans Anaconda, sous le dossier Scripts, et les exécutables Python sont inscrits automatiquement auprès de Jupyter Notebook. Les packages disponibles sous le dossier site-packages peuvent être importés dans un notebook, y compris les trois packages Microsoft utilisés pour la science des données et le machine learning.
Si vous utilisez un autre IDE, vous devez lier les bibliothèques de fonctions et fichiers exécutables Python à votre outil. Les sections suivantes fournissent des instructions relatives aux outils couramment utilisés.
Visual Studio
Si vous travaillez avec Python dans Visual Studio, utilisez les options de configuration suivantes pour créer un environnement Python qui comprend les packages Microsoft Python.
| Paramètre de configuration | valeur |
|---|---|
| Chemin de préfixe | %ProgramFiles%\Microsoft\PyForMLS |
| Chemin de l’interpréteur | %ProgramFiles%\Microsoft\PyForMLS\python.exe |
| Interpréteur en mode fenêtre | %ProgramFiles%\Microsoft\PyForMLS\pythonw.exe |
Pour obtenir de l’aide sur la configuration d’un environnement Python, consultez Gestion des environnements Python dans Visual Studio.
PyCharm
Dans PyCharm, définissez l’interpréteur sur l’exécutable Python installé.
Dans un nouveau projet, sous Paramètres, sélectionnez Add Local.
Entrez
%ProgramFiles%\Microsoft\PyForMLS\.
Vous pouvez maintenant importer les modules revoscalepy, microsoftml ou azureml. Vous pouvez également choisir Tools>Python Console pour ouvrir une fenêtre interactive.