Tutoriel : Créer un modèle prédictif dans R avec le Machine Learning SQL
S’applique à : ![]() SQL Server 2016 (13.x) et versions ultérieures
SQL Server 2016 (13.x) et versions ultérieures ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Dans la troisième partie de cette série de quatre tutoriels, vous allez effectuer l’apprentissage d’un modèle prédictif en R. Dans la partie suivante de cette série, vous allez déployer ce modèle dans une base de données SQL Server avec Machine Learning Services ou sur des clusters Big Data.
Dans la troisième partie de cette série de quatre tutoriels, vous allez effectuer l’apprentissage d’un modèle prédictif en R. Dans la partie suivante de cette série, vous allez déployer ce modèle dans une base de données SQL Server avec Machine Learning Services.
Dans la troisième partie de cette série de quatre tutoriels, vous allez entraîner un modèle prédictif en R. Dans la partie suivante de cette série, vous allez déployer ce modèle dans une base de données avec SQL Server R Services.
Dans la troisième partie de cette série de quatre tutoriels, vous allez entraîner un modèle prédictif en R. Dans la partie suivante de cette série, vous allez déployer ce modèle dans une base de données Azure SQL Managed Instance avec Machine Learning Services.
Dans cet article, vous allez apprendre à :
- Effectuer l’apprentissage de deux modèles Machine Learning
- Effectuer des prédictions à partir des deux modèles
- Comparer les résultats pour choisir le modèle le plus précis
Dans la première partie, vous avez appris à restaurer l’exemple de base de données.
Dans la deuxième partie, vous avez appris à charger les données d’une base de données dans une trame de données Python et à préparer les données en R.
Dans la quatrième partie, vous allez apprendre à stocker le modèle dans une base de données, puis à créer des procédures stockées à partir des scripts Python que vous avez développés dans les parties 2 et 3. Les procédures stockées sont exécutées sur le serveur pour effectuer des prédictions en fonction de nouvelles données.
Prérequis
La troisième partie de cette série de tutoriels part du principe que vous avez satisfait les prérequis de la première partie et effectué les étapes décrites dans la deuxième partie.
Effectuer l’apprentissage de deux modèles
Pour trouver le meilleur modèle pour des données de location de skis, créez deux modèles différents (régression linéaire et arbre de décision), puis voyez lequel des deux fournit les prédictions les plus précises. Vous allez utiliser le cadre de données rentaldata que vous avez créé dans la première partie de cette série.
#First, split the dataset into two different sets:
# one for training the model and the other for validating it
train_data = rentaldata[rentaldata$Year < 2015,];
test_data = rentaldata[rentaldata$Year == 2015,];
#Use the RentalCount column to check the quality of the prediction against actual values
actual_counts <- test_data$RentalCount;
#Model 1: Use lm to create a linear regression model, trained with the training data set
model_lm <- lm(RentalCount ~ Month + Day + WeekDay + Snow + Holiday, data = train_data);
#Model 2: Use rpart to create a decision tree model, trained with the training data set
library(rpart);
model_rpart <- rpart(RentalCount ~ Month + Day + WeekDay + Snow + Holiday, data = train_data);
Effectuer des prédictions à partir des deux modèles
Utilisez une fonction predict pour prédire le nombre de locations à l’aide de chaque modèle formé.
#Use both models to make predictions using the test data set.
predict_lm <- predict(model_lm, test_data)
predict_lm <- data.frame(RentalCount_Pred = predict_lm, RentalCount = test_data$RentalCount,
Year = test_data$Year, Month = test_data$Month,
Day = test_data$Day, Weekday = test_data$WeekDay,
Snow = test_data$Snow, Holiday = test_data$Holiday)
predict_rpart <- predict(model_rpart, test_data)
predict_rpart <- data.frame(RentalCount_Pred = predict_rpart, RentalCount = test_data$RentalCount,
Year = test_data$Year, Month = test_data$Month,
Day = test_data$Day, Weekday = test_data$WeekDay,
Snow = test_data$Snow, Holiday = test_data$Holiday)
#To verify it worked, look at the top rows of the two prediction data sets.
head(predict_lm);
head(predict_rpart);
RentalCount_Pred RentalCount Month Day WeekDay Snow Holiday
1 27.45858 42 2 11 4 0 0
2 387.29344 360 3 29 1 0 0
3 16.37349 20 4 22 4 0 0
4 31.07058 42 3 6 6 0 0
5 463.97263 405 2 28 7 1 0
6 102.21695 38 1 12 2 1 0
RentalCount_Pred RentalCount Month Day WeekDay Snow Holiday
1 40.0000 42 2 11 4 0 0
2 332.5714 360 3 29 1 0 0
3 27.7500 20 4 22 4 0 0
4 34.2500 42 3 6 6 0 0
5 645.7059 405 2 28 7 1 0
6 40.0000 38 1 12 2 1 0
Comparer les résultats
Vous voulez à présent voir lequel des modèles produit les meilleures prédictions. Un moyen simple et rapide pour ce faire consiste à utiliser une fonction de traçage de base afin de voir la différence entre les valeurs réelles de vos données d’entraînement et les valeurs prédites.
#Use the plotting functionality in R to visualize the results from the predictions
par(mfrow = c(1, 1));
plot(predict_lm$RentalCount_Pred - predict_lm$RentalCount, main = "Difference between actual and predicted. lm")
plot(predict_rpart$RentalCount_Pred - predict_rpart$RentalCount, main = "Difference between actual and predicted. rpart")
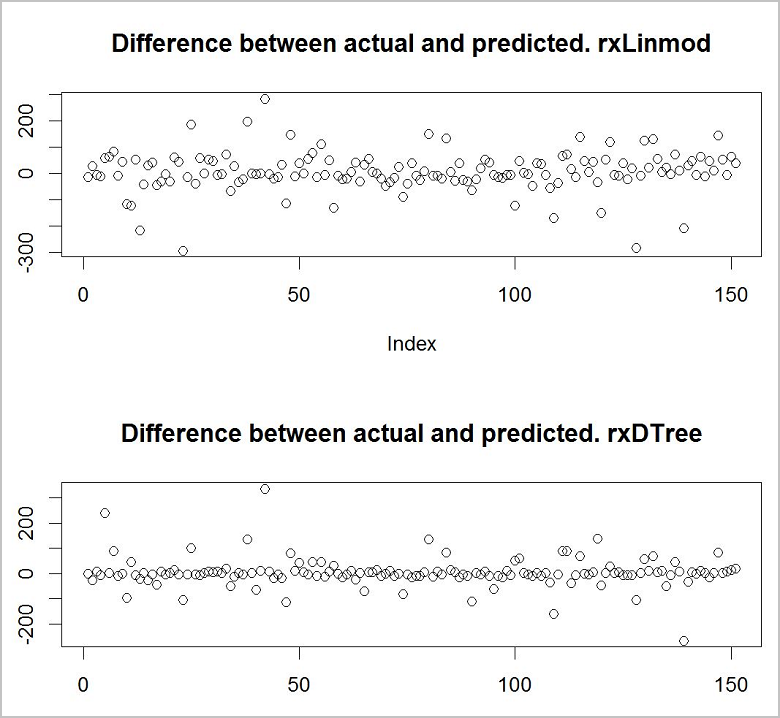
Il semble que le modèle de type arbre de décision est le plus précis des deux.
Nettoyer les ressources
Si vous ne poursuivez pas ce tutoriel, supprimez la base de données TutorialDB.
Étapes suivantes
Dans la troisième partie de cette série de tutoriels, vous avez appris à effectuer les tâches suivantes :
- Effectuer l’apprentissage de deux modèles Machine Learning
- Effectuer des prédictions à partir des deux modèles
- Comparer les résultats pour choisir le modèle le plus précis
Pour déployer le modèle de Machine Learning que vous avez créé, suivez la quatrième partie de cette série de tutoriels :