Résolution des problèmes de délai d’attente de connexion intermittents entre les réplicas de groupe de disponibilité
Cet article vous aide à diagnostiquer les délais d’attente de connexion intermittents signalés entre les réplicas de groupe de disponibilité.
Symptômes et effets d’un groupe de disponibilité intermittent réplica des délais d’attente de connexion
L’interrogation des réplicas principaux et secondaires retourne des résultats différents
Les charges de travail en lecture seule qui interrogent des réplicas secondaires peuvent interroger des données obsolètes. Si des délais de connexion réplica intermittents se produisent, les modifications apportées aux données de la base de données réplica primaire ne sont pas encore reflétées dans la base de données secondaire lorsque vous interrogez les mêmes données. Pour plus d’informations, consultez la section Latence des données sur les réplica secondaires.
Groupe de disponibilité de rapport de diagnostic non synchronisé
Le tableau de bord Always On dans SQL Server Management Studio peut signaler un groupe de disponibilité non sain dont les réplicas sont dans un état non synchronisant. Vous pouvez également observer que les réplicas de rapport du tableau de bord Always On sont dans l’état Non synchronisation.

Lorsque vous passez en revue les journaux d’erreurs SQL Server de ces réplicas, vous pouvez observer des messages tels que les suivants qui indiquent qu’il y avait un délai d’attente de connexion entre les réplicas dans le groupe de disponibilité :
Journal des erreurs du réplica principal
2023-02-15 07:10:55.500 spid43s Always On availability groups connection with secondary database terminated for primary database 'agdb' on the availability replica 'SQL19AGN2' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
Journal des erreurs du réplica secondaire
2023-02-15 07:11:03.100 spid31s A connection time-out has occurred on a previously established connection to availability replica 'SQL19AGN1' with id [<replicaid>]. Either a networking or a firewall issue exists or the availability replica has transitioned to the resolving role.
2023-02-15 07:11:03.100 spid31s Always On Availability Groups connection with primary database terminated for secondary database 'agdb' on the availability replica 'SQL19AGN1' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
Des problèmes de connexion intermittents peuvent affecter la préparation au basculement d’un réplica secondaire
Si vous configurez le groupe de disponibilité pour le basculement automatique et que le partenaire de basculement à validation synchrone est déconnecté par intermittence du serveur principal, le basculement automatique peut échouer.
Vous pouvez interroger sys.dm_hadr_database_replia_cluster_states pour déterminer si la base de données du groupe de disponibilité est prête pour le basculement à ce moment-là. Voici un exemple des résultats si le point de terminaison de mise en miroir a été arrêté sur le réplica secondaire :
SELECT drcs.database_name, drcs.is_failover_ready, ar.replica_server_name, ars.role_desc, ars.connected_state_desc,
ars.last_connect_error_description, ars.last_connect_error_number, ar.endpoint_url
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.availability_replicas ar ON ars.replica_id=ar.replica_id
JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ar.replica_id=drcs.replica_id
WHERE ars.role_desc='SECONDARY'

Le basculement automatique peut ne pas mettre le groupe de disponibilité en ligne dans le rôle principal sur l’ordinateur partenaire de basculement si le basculement coïncide avec un délai de connexion réplica.
Qu’indiquent les erreurs de délai d’attente de connexion ?
La valeur par défaut est de 10 secondes pour le paramètre de réplica du groupe de disponibilité, SESSION_TIMEOUT. Ce paramètre est configuré pour chaque réplica. Il détermine la durée pendant laquelle le réplica attend de recevoir une réponse de son partenaire réplica avant de signaler un délai d’expiration de connexion. Si un réplica n’obtient aucune réponse du réplica partenaire, il signale un délai de connexion expiré dans le journal des erreurs microsoft SQL Server et le journal des applications Windows. Le réplica qui signale le délai d’attente tente immédiatement de se reconnecter et continue à essayer toutes les cinq secondes.
En règle générale, le délai d’expiration de la connexion est détecté et signalé par un seul réplica. Toutefois, le délai d’expiration de la connexion peut être signalé par les deux réplicas en même temps. Il existe différentes versions de ce message, selon que le délai de connexion s’est produit à l’aide d’une connexion précédemment établie ou d’une nouvelle connexion :
Message 35206 A connection timeout has occurred on a previously established connection to availability replica '<replicaname>' with id [<replicaid>]. Either a networking or a firewall issue exists or the availability replica has transitioned to the resolving role.
Message 35201 A connection timeout has occurred while attempting to establish a connection to availability replica '<replicaname>' with id [<replicaid>]. Either a networking or firewall issue exists, or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance.
Le réplica partenaire peut ne pas détecter un délai d’attente. Si c’est le cas, il peut signaler le message 35201 ou 35206. Si ce n’est pas le cas, il signale une perte de connexion à chacune des bases de données du groupe de disponibilité :
Message 35267 Always On Availability Groups connection with primary/secondary database terminated for primary/secondary database '<databasename>' on the availability replica '<replicaname>' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
Voici un exemple de ce que SQL Server signale au journal des erreurs : si vous arrêtez le point de terminaison de mise en miroir sur le réplica principal, le réplica secondaire détecte un délai d’expiration de connexion et les messages 35206 et 35267 sont signalés dans le journal des erreurs réplica secondaire :
2023-02-15 07:11:03.100 spid31s A connection timeout has occurred on a previously established connection to availability replica 'SQL19AGN1' with id [<replicaid>]. Either a networking or a firewall issue exists or the availability replica has transitioned to the resolving role.
2023-02-15 07:11:03.100 spid31s Always On Availability Groups connection with primary database terminated for secondary database 'agdb' on the availability replica 'SQL19AGN1' with Replica ID:[<replicaid>]. This is an informational message only. No user action is required.
Dans cet exemple, le réplica principal n’a détecté aucun délai de connexion, car il pouvait toujours communiquer avec le serveur secondaire, et il a signalé le message 35267 pour chaque base de données de groupe de disponibilité (dans cet exemple, il n’y a qu’une seule base de données, « agdb ») :
2023-02-15 07:10:55.500 spid43s Always On Availability Groups connection with secondary database terminated for primary database 'agdb' on the availability replica 'SQL19AGN2' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
Causes des délais d’expiration de connexion réplica
Problème d’application
SQL Server peut être occupé pour plusieurs raisons et ne gère pas la connexion de point de terminaison de mise en miroir pendant la période du groupe SESSION_TIMEOUT de disponibilité. Cela entraîne l’expiration du délai de connexion. Voici quelques-unes des raisons suivantes :
SQL Server 100 % d’utilisation du processeur. Cela signifie que SQL Server ou une autre application pilote le processeur pendant quelques secondes à la fois.
SQL Server rencontre des événements de planificateur qui ne produisent pas de rendement. SQL Server threads sont chargés de céder le planificateur (processeur) à d’autres threads pour terminer leur travail si un thread ne cède pas en temps voulu.
SQL Server rencontre un épuisement des threads de travail, des problèmes de mémoire insuffisante ou des problèmes d’application qui affectent sa capacité à traiter la connexion de point de terminaison de mise en miroir.
Problème réseau
Pour cela, vous devez collecter les journaux de trace réseau sur les réplicas principaux et secondaires lorsque l’erreur est déclenchée. Pour ce faire, vous pouvez examiner la latence du réseau et les paquets supprimés.
Comment diagnostiquer réplica délai d’expiration de connexion
Pour le problème des problèmes d’application qui empêchent SQL Server de gérer la connexion avec le réplica partenaire, cette section explique comment analyser les journaux SQL Server. Ces conseils peuvent vous aider à identifier la cause racine des délais d’expiration de connexion réplica. Cette section se termine par des conseils plus avancés sur la collecte des traces réseau lorsque les délais de connexion se produisent afin que vous puissiez case activée le status réseau.
Évaluer le moment et l’emplacement des délais d’expiration de connexion réplica
Passez en revue l’historique, la fréquence et les tendances des délais d’attente de connexion. L’utilisation des messages que vous trouvez dans le journal des erreurs SQL Server est un excellent moyen de le faire. Où les délais de connexion sont-ils signalés ? Sont-ils signalés de manière cohérente sur le réplica principal ou secondaire ? Quand les erreurs se sont-elles produites ? Est-ce qu’elles se sont produites dans une certaine semaine du mois, un jour de la semaine ou une heure de la journée ? Les autres opérations de maintenance planifiée ou de traitement par lots correspondent-elles aux heures auxquelles les délais d’expiration de connexion sont observés ? Cette évaluation peut vous aider à définir l’étendue et à mettre en corrélation les délais d’attente de connexion pour identifier la cause racine.
Passer en revue la session d’événements étendue AlwaysOn_health
La AlwaysOn_health session d’événements étendue a été améliorée pour inclure l’événementucs_connection_setup, qui est déclenché lorsqu’un réplica établit une connexion avec son réplica partenaire. Cela peut être utile lors de la résolution des problèmes de délai d’attente de connexion.
Remarque
L’événement ucs_connection_setup étendu a été ajouté aux dernières mises à jour cumulatives SQL Server. Vous devez exécuter les dernières mises à jour cumulatives pour observer cet événement étendu.
Vues de gestion distribuée Always On de requêtes (DMV)
Vous pouvez interroger Always On DMV pour plus d’informations sur l’état connecté de l’réplica. Cette requête signale uniquement l’état connecté et toutes les erreurs associées au délai d’expiration de la connexion au moment où les problèmes se produisent. Si les problèmes de connexion sont intermittents, la requête risque de ne pas capturer facilement l’état déconnecté.
SELECT ar.replica_server_name, ars.role_desc, ars.connected_state_desc,
ars.last_connect_error_description, ars.last_connect_error_number, ar.endpoint_url
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.availability_replicas ar ON ars.replica_id=ar.replica_id
L’exemple suivant montre un état déconnecté soutenu, car le point de terminaison de mise en miroir sur le réplica principal a été arrêté. En interrogeant le réplica principal, la DMV Always On peut créer un rapport sur le réplica principal et tous les réplicas secondaires (le point de terminaison est désactivé sur le réplica principal).

En interrogeant le réplica secondaire, les vues de gestion dynamique Always On indiquent uniquement les réplica secondaires.

Passer en revue la session d’événements étendue Always On
Connectez-vous à chaque réplica en utilisant SQL Server Management Studio (SSMS) Explorateur d'objets et ouvrez les fichiers d’événements
AlwaysOn_healthétendus.Dans SSMS, accédez à Ouvrir un fichier>, puis sélectionnez Fusionner les fichiers d’événements étendus.
Cliquez sur le bouton Ajouter.
Dans la boîte de dialogue Ouvrir le fichier, accédez aux fichiers dans le répertoire SQL Server \LOG.
Appuyez sur Ctrl, puis sélectionnez les fichiers dont le nom commence par « AlwaysOn_healthxxx.xel ».
Sélectionnez Ouvrir, puis OK.
Vous devez voir une nouvelle fenêtre à onglets dans SSMS qui affiche les événements AlwaysOn.
La capture d’écran suivante montre les
AlwaysOn_healthdonnées du réplica secondaire. La première zone hiérarchique affiche la perte de connexion après l’arrêt du point de terminaison sur le réplica principal. La deuxième zone hiérarchique indique l’échec de connexion qui se produit la prochaine fois que le réplica secondaire tente de se connecter au réplica principal.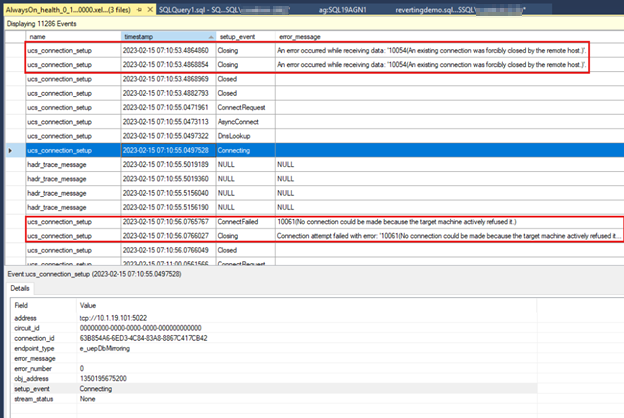

Vérifiez si les événements qui ne produisent pas de rendement entraînent des délais d’attente de connexion
L’une des raisons les plus courantes pour lesquelles un réplica de disponibilité ne peut pas traiter la connexion réplica partenaire est un planificateur sans rendement. Pour plus d’informations sur les planificateurs sans rendement, consultez Résolution des problèmes SQL Server planification et rendement.
SQL Server effectue le suivi des événements du planificateur qui ne produisent pas de rendement qui sont aussi courts que 5 à 10 secondes. Il signale ces événements dans le point de TrackingNonYieldingScheduler données dans la sortie du sp_server_diagnostics query_processing composant.
Pour case activée pour les événements qui ne produisent pas de résultats susceptibles d’entraîner réplica délai d’attente de connexion, procédez comme suit :
Créez un travail SQL Agent qui enregistre
sp_server_diagnosticstoutes les cinq secondes.Planifiez ce travail sur le serveur qui ne signale pas le délai d’expiration de la connexion. Autrement dit, si le serveur A réplica signale l’expiration du délai de connexion réplica dans son journal des erreurs, configurez le travail SQL Agent sur le réplica partenaire, serveur B. Sinon, si vous voyez des délais d’expiration de connexion sur les deux réplicas, créez le travail sur les deux réplicas.
Exécutez le fichier de commandes suivant pour créer un travail qui s’exécute
sp_server_diagnosticstoutes les cinq secondes, ajoute la sortie à un fichier texte, puis démarre le travail. La commande dans l’exemple suivant s’exécutesp_server_diagnostics 5toutes les cinq secondes. Par conséquent, il n’est pas nécessaire de planifier l’exécution de ce travail toutes les cinq secondes, il suffit de démarrer le travail et il s’exécutera jusqu’à ce qu’il s’arrête, toutes les cinq secondes :USE [msdb] GO DECLARE @ReturnCode INT SELECT @ReturnCode = 0 DECLARE @jobId BINARY(16) EXEC @ReturnCode = msdb.dbo.sp_add_job @job_name=N'Run sp_server_diagnostics', @owner_login_name=N'sa', @job_id = @jobId OUTPUT /****** Object: Step [Run SP_SERVER_DIAGNOSTICS] Script Date: 2/15/2023 4:20:41 PM ******/ EXEC @ReturnCode = msdb.dbo.sp_add_jobstep @job_id=@jobId, @step_name=N'Run SP_SERVER_DIAGNOSTICS', @subsystem=N'TSQL', @command=N'sp_server_diagnostics 5', @database_name=N'master', @output_file_name=N'D:\cases\2423\sp_server_diagnostics_output.out', @flags=2 EXEC @ReturnCode = msdb.dbo.sp_add_jobserver @job_id = @jobId, @server_name = N'(local)' EXEC sp_start_job 'Run sp_server_diagnostics'Remarque
Dans ces commandes, remplacez par
@output_file_nameun chemin d’accès valide et fournissez un nom de fichier.
Analyser les résultats
Lorsqu’un délai d’attente de connexion est signalé, notez l’horodatage de l’événement de délai d’attente affiché dans le journal des erreurs SQL Server. Pour les réplicas de l’exemple suivant, SQL19AGN1 a signalé le délai d’attente de connexion réplica. Par conséquent, un travail SQL Agent a été créé sur SQL19AGN2, le partenaire réplica. Ensuite, un délai d’attente de connexion a été signalé dans le SQL19AGN1 journal des erreurs à 07 :24 :31.

Ensuite, la sortie du travail SQL Agent qui s’exécute sp_server_diagnostics est vérifiée à l’heure indiquée, en particulier en examinant le TrackingNonYieldingScheduler point de données dans la sortie du query_processing composant. La sortie indique qu’un planificateur sans rendement a été suivi (sous la forme d’une valeur hexadécimale différente de zéro) sur le serveur SQL19AGN2 (à 07 :24 :33) à l’heure à laquelle le délai d’expiration de connexion réplica a été signalé sur SQL19AGN1 (à 07 :24 :31).
Remarque
La sortie suivante sp_server_diagnostics est concaténée pour afficher à la fois le create_time (horodatage) et les query_processing TrackingNonYieldingScheduler résultats.

Examiner un événement de planificateur sans rendement
Si vous avez vérifié à partir des étapes de diagnostic précédentes qu’un événement ne produisant pas de résultat a provoqué l’expiration du délai de connexion réplica :
Identifiez les charges de travail qui s’exécutent dans SQL Server au moment où les événements sans rendement sont exécutés.
À l’instar des délais d’attente de connexion réplica, recherchez les tendances de ces événements au cours du mois, du jour ou de la semaine où ils se produisent.
Collectez le suivi de l’analyseur de performances sur le système sur lequel l’événement sans rendement a été détecté.
Collectez les compteurs de performances clés pour les ressources système, notamment Processeur ::% Temps processeur, Mémoire ::Mooctets disponibles, Disque logique ::Longueur moyenne de la file d’attente du disque et Disque logique ::Avg Disk sec/Transfer.
Si nécessaire, ouvrez un incident de support SQL Server pour obtenir de l’aide supplémentaire pour trouver la cause racine de ces événements non générés. Partagez les journaux que vous avez collectés pour une analyse plus approfondie.
Collecte de données avancée : collecter la trace réseau pendant l’expiration du délai de connexion
Si le diagnostic précédent de l’application SQL Server n’a pas généré de cause racine, vous devez case activée le réseau. L’analyse réussie du réseau nécessite que vous collectiez une trace réseau qui couvre le temps d’expiration de la connexion.
La procédure suivante démarre un suivi réseau Windows netsh sur les réplicas sur lesquels les délais de connexion sont signalés dans les journaux d’erreurs SQL Server. Une tâche d’événement planifié Windows est déclenchée quand l’une des erreurs de connexion SQL Server est enregistrée dans le journal des applications. La tâche planifiée exécute une commande pour arrêter la netsh trace réseau afin que les données de trace réseau clés ne soient pas remplacées. Ces étapes supposent également un chemin d’accès *F :* pour les journaux de traitement par lots et de suivi. Ajustez ce chemin d’accès à votre environnement.
Démarrez une trace réseau, comme indiqué dans l’extrait de code suivant, sur les deux réplicas sur lesquels le délai d’attente de connexion se produit :
netsh trace start capture=yes persistent=yes overwrite=yes maxsize=500 tracefile=f:\trace.etlCréez des tâches planifiées Windows qui arrêtent la
netshtrace sur les événements 35206 ou 35267. Vous pouvez créer ces tâches à l’aide d’une ligne de commande d’administration :schtasks /Create /tn Event35206Task /tr F:\stoptrace.bat /SC ONEVENT /EC Application /MO *[System/EventID=35206] /f /RL HIGHEST schtasks /Create /tn Event35267Task /tr F:\stoptrace.bat /SC ONEVENT /EC Application /MO *[System/EventID=35267] /f /RL HIGHESTUne fois que l’événement se produit et que les traces réseau sont arrêtées et capturées, vous pouvez supprimer les
ONEVENTtâches :PS C:\Users\sqladmin> Schtasks /Delete /tn Event35206Task /F PS C:\Users\sqladmin> Schtasks /Delete /tn Event35267Task /F
L’analyse de la trace réseau n’est pas dans le cadre de cet utilitaire de résolution des problèmes. Si vous ne pouvez pas interpréter la trace réseau, contactez l’équipe du support technique Microsoft SQL Server et fournissez la trace avec les autres fichiers journaux demandés pour l’analyse de la cause racine.
Que puis-je faire d’autre pour atténuer les délais d’expiration de connexion ?
Le groupe de disponibilité par défaut, SESSION_TIMEOUT, est configuré pendant 10 secondes. Vous pourrez peut-être atténuer les délais d’attente de connexion en ajustant la propriété réplica SESSION_TIMEOUT groupe de disponibilité. Ce paramètre est défini par réplica. Ajustez-le en fonction du réplica principal et de chaque réplica secondaire affecté. Voici un exemple de syntaxe. La valeur par défaut SESSION_TIMEOUT est 10. Par conséquent, vous pouvez utiliser 15 comme valeur suivante.
ALTER AVAILABILITY GROUP ag
MODIFY REPLICA ON 'SQL19AGN1' WITH (SESSION_TIMEOUT = 15);