Activation vocale
Remarque
Cette rubrique se réfère principalement à nos expériences destinées aux consommateurs, qui sont actuellement disponibles dans Windows 10 (version 1909 et antérieures). Pour plus d’informations, veuillez consulter la section Fin du support pour Cortana dans Windows et Teams.
Cortana, la technologie d’assistant personnel, a été démontrée pour la première fois lors de la conférence Microsoft BUILD Developer en 2013. La plateforme de reconnaissance vocale de Windows est utilisée pour alimenter toutes les expériences de reconnaissance vocale dans Windows 10, telles que Cortana et Dictée. L’activation vocale est une fonctionnalité qui permet aux utilisateurs de déclencher un moteur de reconnaissance vocale à partir de différents états d’alimentation de l’appareil en prononçant une phrase spécifique - « Hey Cortana ». Pour créer du matériel prenant en charge la technologie d’activation vocale, consultez les informations de cette rubrique.
Remarque
La mise en œuvre de l’activation vocale est un projet important et une tâche réalisée par les fournisseurs de SoC. Les OEM peuvent contacter leur fournisseur de SoC pour obtenir des informations sur l’implémentation de l’activation vocale de leur SoC.
Expérience de l’utilisateur final de Cortana
Pour comprendre l’expérience d’interaction vocale disponible dans Windows, consultez ces rubriques.
| Rubrique | Description |
|---|---|
| Qu’est-ce que Cortana ? | Fournit une vue d’ensemble et des instructions d’utilisation pour Cortana. |
Introduction à l’activation vocale « Hey Cortana » et « Apprendre ma voix »
Activation vocale « Hey Cortana »
La fonctionnalité d’activation vocale (VA) « Hey Cortana » permet aux utilisateurs d’engager rapidement l’expérience Cortana en dehors de leur contexte actif (c’est-à-dire, ce qui est actuellement à l’écran) en utilisant leur voix. Les utilisateurs souhaitent souvent pouvoir accéder instantanément à une expérience sans avoir à interagir physiquement avec un appareil. Pour les utilisateurs de téléphone, cela peut être dû à la conduite d’un véhicule et à l’engagement de leur attention et de leurs mains dans la conduite. Pour un utilisateur de Xbox, cela peut être dû à la réticence à chercher et connecter une manette. Pour les utilisateurs de PC, cela peut être dû à l’accès rapide à une expérience sans avoir à effectuer plusieurs actions de souris, de toucher et/ou de clavier, par exemple un ordinateur dans la cuisine.
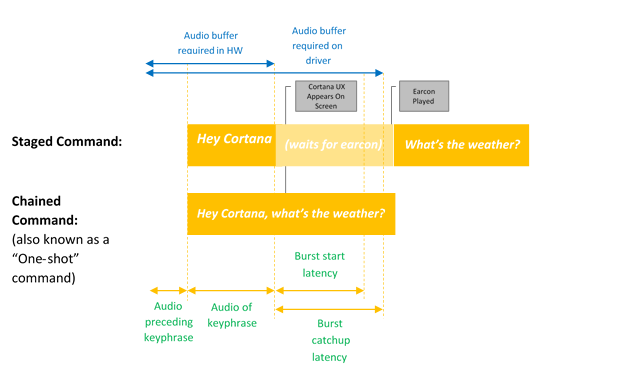
L’activation vocale offre une entrée vocale toujours à l’écoute via des phrases-clés prédéfinies ou des « phrases d’activation ». Les phrases-clés peuvent être prononcées seules (« Hey Cortana ») comme une commande par étapes, ou suivies d’une action vocale, par exemple, « Hey Cortana, où est ma prochaine réunion? », une commande enchaînée.
Le terme Détection de mot-clé décrit la détection du mot-clé par le matériel ou le logiciel.
L’activation Mot-clé seul se produit lorsque seul le mot-clé Cortana est dit, Cortana démarre et joue le son EarCon pour indiquer qu’il est en mode d’écoute.
Une commande enchaînée décrit la capacité de donner une commande immédiatement après le mot-clé (comme « Hey Cortana, appelle John ») et d’avoir Cortana qui démarre (si ce n’est déjà fait) et suit la commande (démarrant un appel téléphonique avec John).
Ce diagramme illustre l’activation enchaînée et l’activation par mot-clé seul.
Microsoft fournit un détecteur de mot-clé par défaut dans l’OS (détecteur de mot-clé logiciel) qui est utilisé pour assurer la qualité des détections de mot-clé matériel et pour offrir l’expérience Hey Cortana dans les cas où la détection de mot-clé matériel est absente ou indisponible.
La fonctionnalité « Apprendre ma voix »
La fonctionnalité « Apprendre ma voix » permet à l’utilisateur d’entraîner Cortana à reconnaître sa voix unique. Cela se fait en sélectionnant Apprenez comment je dis « Hey Cortana » dans l’écran des paramètres de Cortana. L’utilisateur répète alors six phrases soigneusement choisies qui fournissent une variété suffisante de modèles phonétiques pour identifier les attributs uniques de la voix de l’utilisateur.
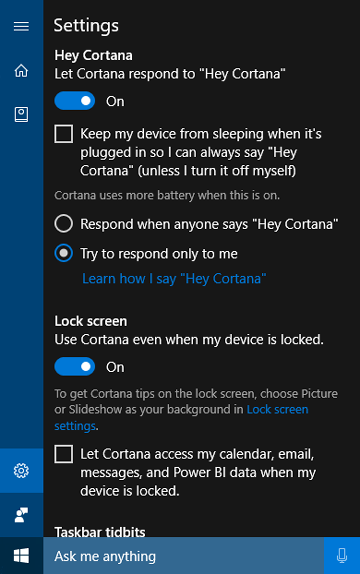
Lorsque l’activation vocale est couplée à « Apprendre ma voix », les deux algorithmes travailleront ensemble pour réduire les activations fausses. Cela est particulièrement précieux pour le scénario de salle de réunion, où une personne dit « Hey Cortana » dans une salle pleine d’appareils. Cette fonctionnalité est disponible uniquement pour Windows 10 version 1903 et les versions antérieures.
L’activation vocale est alimentée par un détecteur de mot-clé (KWS) qui réagit si la phrase-clé est détectée. Si le KWS doit réveiller l’appareil à partir d’un état de faible puissance, la solution est connue sous le nom de Wake on Voice (WoV). Pour plus d’informations, consultez la section Wake on Voice.
Glossaire des termes
Ce glossaire résume les termes liés à l’activation vocale.
| Terme | Exemple/définition |
|---|---|
| Commande par étapes | Exemple : Hey Cortana <pause, attendez l’earcon> Quel temps fait-il? Ceci est parfois appelé « commande en deux étapes » ou « mot-clé seul » |
| Commande enchaînée | Exemple : Hey Cortana quel temps fait-il? Ceci est parfois appelé « commande one-shot » |
| Activation vocale | Scénario de fourniture de détection de mot-clé d’une phrase-clé d’activation prédéfinie. Par exemple, « Hey Cortana » est le scénario d’activation vocale de Microsoft. |
| WoV | Wake-on-Voice : Technologie permettant l’activation vocale d’un état d’écran éteint, de faible puissance, à un état d’écran allumé, de pleine puissance. |
| WoV depuis Modern Standby | Wake-on-Voice d’un état de veille moderne (S0ix) écran éteint à un état de pleine puissance (S0). |
| Veille moderne | Infrastructure de veille à faible consommation d’énergie de Windows - successeur de la veille connectée (CS) dans Windows 10. Le premier état de veille moderne est lorsque l’écran est éteint. L’état de sommeil le plus profond est lorsqu’il est en DRIPS/Résilience. Pour plus d’informations, veuillez consulter la section Modern Standby |
| KWS | Keyword spotter : l’algorithme qui fournit la détection de « Hey Cortana » |
| SW KWS | Détecteur de mot-clé logiciel – une implémentation de KWS qui s’exécute sur l’hôte (CPU). Pour « Hey Cortana », SW KWS est inclus dans Windows. |
| Détecteur de mot-clé déporté sur le matériel – une implémentation de KWS qui s’exécute déportée sur le matériel. | Détecteur de mots-clés déchargé sur le matériel : une implémentation de KWS qui s’exécute déchargée sur le matériel. |
| Burst Buffer (mise en mémoire tampon de paquets) | Un tampon circulaire utilisé pour stocker les données PCM qui peuvent « monter en rafale » en cas de détection KWS, de sorte que tous les audios qui ont déclenché une détection KWS soient inclus. |
| Adaptateur OEM de détecteur de mot-clé | Un shim au niveau du pilote qui permet au matériel compatible WoV de communiquer avec Windows et la pile Cortana. |
| Modèle | Le fichier de données du modèle acoustique utilisé par l’algorithme KWS. Le fichier de données est statique. Les modèles sont localisés, un par localité. |
Intégration d’un détecteur de mot-clé matériel
Pour implémenter un détecteur de mot-clé matériel (HW KWS), les fournisseurs de SoC doivent accomplir les tâches suivantes.
- Créer un détecteur de mot-clé personnalisé basé sur l’échantillon SYSVAD décrit plus loin dans ce sujet. Vous allez implémenter ces méthodes dans une DLL COM, décrite dans Interface d’adaptateur OEM de détecteur de mot-clé.
- Implémenter les améliorations WAVE RT décrites dans Améliorations WAVERT.
- Fournir des entrées de fichier INF pour décrire tous les APO personnalisés utilisés pour la détection de mot-clé.
- PKEY_FX_KeywordDetector_StreamEffectClsid
- PKEY_FX_KeywordDetector_ModeEffectClsid
- PKEY_FX_KeywordDetector_EndpointEffectClsid
- PKEY_SFX_KeywordDetector_ProcessingModes_Supported_For_Streaming
- PKEY_MFX_KeywordDetector_ProcessingModes_Supported_For_Streaming
- PKEY_EFX_KeywordDetector_ProcessingModes_Supported_For_Streaming
- Examinez les recommandations matérielles et les directives de test dans Recommandations pour les appareils audio. Cette rubrique fournit des conseils et des recommandations pour la conception et le développement de dispositifs d’entrée audio destinés à être utilisés avec la plateforme de reconnaissance vocale de Microsoft.
- Supporter à la fois les commandes par étapes et enchaînées.
- Prenez en charge « Hey Cortana » chacun des localités prises en charge par Cortana.
- Les APO (objets de traitement audio) doivent fournir les effets suivants :
- AEC
- AGC
- NS
- Les effets pour le mode de traitement vocal doivent être rapportés par l’APO MFX.
- L’APO peut effectuer la conversion de format en tant que MFX.
- L’APO doit sortir le format suivant :
- 16 kHz, mono, FLOAT.
- Concevez éventuellement des APO personnalisés pour améliorer le processus de capture audio. Pour plus d’informations, veuillez consulter la section Objets de traitement audio Windows.
Exigences WoV pour les détecteurs de mot-clé déportés sur le matériel (HW KWS)
- HW KWS WoV est pris en charge pendant l’état de fonctionnement S0 et l’état de veille S0 également connu sous le nom de veille moderne.
- HW KWS WoV n’est pas pris en charge depuis S3.
Exigences AEC pour HW KWS
Pour Windows Version 1709
- Pour prendre en charge HW KWS WoV pour l’état de veille S0 (veille moderne), l’AEC n’est pas requis.
- HW KWS WoV pour l’état de fonctionnement S0 n’est pas pris en charge dans Windows Version 1709.
Pour Windows Version 1803
- HW KWS WoV pour l’état de fonctionnement S0 est pris en charge.
- Pour activer HW KWS WoV pour l’état de fonctionnement S0, l’APO doit prendre en charge l’AEC.
Aperçu du code d’exemple
Il y a un code d’exemple pour un pilote audio qui implémente l’activation vocale sur GitHub dans le cadre de l’échantillon de l’adaptateur audio virtuel SYSVAD. Il est recommandé d’utiliser ce code comme point de départ. Le code est disponible à cet emplacement.
https://github.com/Microsoft/Windows-driver-samples/tree/main/audio/sysvad/
Pour plus d’informations sur le pilote audio d’exemple SYSVAD, veuillez consulter la rubrique Pilotes audio d’exemple.
Informations sur le système de reconnaissance de mot-clé
Support de la pile audio pour l’activation vocale
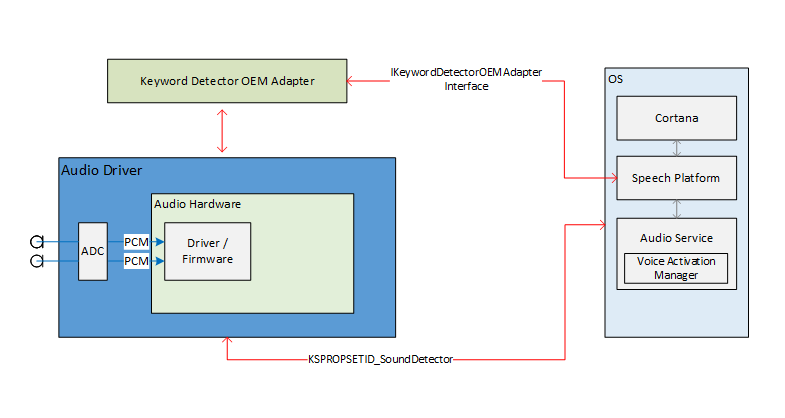
Les interfaces externes de la pile audio pour activer l’activation vocale servent de pipeline de communication pour la plateforme de reconnaissance vocale et les pilotes audio. Les interfaces externes sont divisées en trois parties.
- Interface de pilote de périphérique de détecteur de mot-clé (DDI). L’interface de pilote de périphérique de détecteur de mot-clé est responsable de la configuration et de l’activation du détecteur de mot-clé matériel (KWS). Elle est également utilisée par le pilote pour notifier le système d’un événement de détection.
- DLL d’adaptateur OEM de détecteur de mot-clé Cette DLL implémente une interface COM pour adapter les données opaques spécifiques au pilote pour être utilisées par l’OS pour aider à la détection de mot-clé.
- Améliorations de streaming WaveRT. Les améliorations permettent au pilote audio de diffuser en rafale les données audio mises en tampon à partir de la détection de mot-clé.
Propriétés du point de terminaison audio
La construction du graphe de point de terminaison audio se fait normalement. Le graphe est préparé pour gérer la capture plus rapide que le temps réel. Les horodatages sur les tampons capturés restent vrais. Plus précisément, les horodatages refléteront correctement les données capturées dans le passé et mises en tampon, et qui sont maintenant « en rafale ».
Théorie du streaming audio en contournant le Bluetooth
Le pilote expose un filtre KS pour son périphérique de capture comme d’habitude. Ce filtre prend en charge plusieurs propriétés KS et un événement KS pour configurer, activer et signaler un événement de détection. Le filtre comprend également une usine de broches supplémentaire identifiée comme une broche de détecteur de mot-clé (KWS). Cette broche est utilisée pour diffuser l’audio à partir du détecteur de mot-clé.
Les propriétés sont les suivantes :
- Types de mots-clés pris en charge : KSPROPERTY_SOUNDDETECTOR_PATTERNS. Cette propriété est définie par le système d’exploitation pour configurer les mots-clés à détecter.
- Liste des GUID des modèles de mots-clés : KSPROPERTY_SOUNDDETECTOR_SUPPORTEDPATTERNS. Cette propriété est utilisée pour obtenir une liste de GUID qui identifient les types de modèles pris en charge.
- Armé : KSPROPERTY_SOUNDDETECTOR_ARMED. Cette propriété de lecture/écriture est un simple statut booléen indiquant si le détecteur est armé. L’OS définit cela pour engager le détecteur de mot-clé. L’OS peut l’effacer pour désactiver. Le pilote efface automatiquement cela lorsque les modèles de mots-clés sont définis et également après qu’un mot-clé a été détecté. (L’OS doit réarmer).
- Résultat de correspondance : KSPROPERTY_SOUNDDETECTOR_MATCHRESULT. Cette propriété de lecture contient les données de résultat après qu’une détection a eu lieu.
L’événement qui est déclenché lorsqu’un mot-clé est détecté est un événement KSEVENT_SOUNDDETECTOR_MATCHDETECTED.
Séquence d’opérations
Démarrage du système
- L’OS lit les types de mots-clés pris en charge pour vérifier qu’il a des mots-clés dans ce format.
- L’OS s’enregistre pour l’événement de changement de statut du détecteur.
- L’OS définit les modèles de mots-clés.
- L’OS arme le détecteur.
À la réception de l’événement KS
- Le pilote désarme le détecteur.
- L’OS lit le statut du détecteur de mot-clé, analyse les données retournées et détermine quel modèle a été détecté.
- L’OS réarme le détecteur.
Opération interne du pilote et du matériel
Pendant que le détecteur est armé, le matériel peut capturer et mettre en tampon en continu les données audio dans un petit tampon FIFO. (La taille de ce tampon FIFO est déterminée par des exigences en dehors de ce document, mais peut généralement être de quelques centaines de millisecondes à plusieurs secondes.) L’algorithme de détection fonctionne sur les données circulant dans ce tampon. La conception du pilote et du matériel est telle que, lorsqu’il est armé, il n’y a aucune interaction entre le pilote et le matériel et aucune interruption des processeurs « application » jusqu’à ce qu’un mot clé soit détecté. Cela permet au système d’atteindre un état de basse consommation s’il n’y a pas d’autre activité.
Lorsque le matériel détecte un mot-clé, il génère une interruption. En attendant que le pilote traite l’interruption, le matériel continue de capturer l’audio dans le tampon, garantissant ainsi qu’aucune donnée après le mot-clé ne soit perdue, dans les limites du tampon.
Horodatages des mots-clés
Après avoir détecté un mot-clé, toutes les solutions d’activation vocale doivent mettre en tampon tout le mot-clé prononcé, y compris 250 ms avant le début du mot-clé. Le pilote audio doit fournir des horodatages identifiant le début et la fin de la phrase clé dans le flux.
Pour prendre en charge les horodatages de début/fin des mots-clés, le logiciel DSP peut avoir besoin d’horodater les événements en interne en fonction d’une horloge DSP. Une fois qu’un mot-clé est détecté, le logiciel DSP interagit avec le pilote pour préparer un événement KS. Le pilote et le logiciel DSP devront mapper les horodatages DSP à une valeur de compteur de performance Windows. La méthode pour ce faire est spécifique à la conception matérielle. Une solution possible est que le pilote lise le compteur de performance actuel, interroge l’horodatage DSP actuel, lise à nouveau le compteur de performance actuel, puis estime une corrélation entre le compteur de performance et le temps DSP. Ensuite, étant donné la corrélation, le pilote peut mapper les horodatages DSP des mots-clés aux horodatages des compteurs de performance Windows.
Interface de l’adaptateur OEM du détecteur de mots-clés
L’OEM fournit une implémentation d’objet COM qui agit comme un intermédiaire entre le système d’exploitation et le pilote, aidant à calculer ou à analyser les données opaques qui sont écrites et lues par le pilote audio via les propriétés KSPROPERTY_SOUNDDETECTOR_PATTERNS et KSPROPERTY_SOUNDDETECTOR_MATCHRESULT.
Le CLSID de l’objet COM est un GUID de type de modèle de détecteur renvoyé par la propriété KSPROPERTY_SOUNDDETECTOR_SUPPORTEDPATTERNS. Le système d’exploitation appelle CoCreateInstance en passant le GUID du type de modèle pour instancier l’objet COM approprié compatible avec le type de modèle de mot-clé et appelle des méthodes sur l’interface IKeywordDetectorOemAdapter de l’objet.
Exigences du modèle de threading COM
La mise en œuvre de l’OEM peut choisir n’importe lequel des modèles de threading COM.
IKeywordDetectorOemAdapter
La conception de l’interface tente de maintenir l’implémentation de l’objet sans état. En d’autres termes, l’implémentation ne devrait pas nécessiter de stocker un état entre les appels de méthode. En fait, les classes C++ internes n’ont probablement pas besoin de variables membres au-delà de celles requises pour implémenter un objet COM en général.
Méthodes
Implémentez les méthodes suivantes.
- IKeywordDetectorOemAdapter::BuildArmingPatternData
- IKeywordDetectorOemAdapter::ComputeAndAddUserModelData
- IKeywordDetectorOemAdapter::GetCapabilities
- IKeywordDetectorOemAdapter::ParseDetectionResultData
- IKeywordDetectorOemAdapter::VerifyUserKeyword
KEYWORDID
L’énumération KEYWORDID identifie le texte/la fonction d’une phrase clé et est également utilisée dans les adaptateurs du service biométrique Windows. Pour plus d’informations, veuillez consulter la section Vue d’ensemble du cadre biométrique : Composants de la plate-forme principale.
typedef enum {
KwInvalid = 0,
KwHeyCortana = 1,
KwSelect = 2
} KEYWORDID;
KEYWORDSELECTOR
La structure KEYWORDSELECTOR est un ensemble d’ID qui sélectionnent de manière unique un mot-clé particulier et une langue.
typedef struct
{
KEYWORDID KeywordId;
LANGID LangId;
} KEYWORDSELECTOR;
Gestion des données de modèle
Modèle statique indépendant de l’utilisateur : Le DLL OEM inclurait généralement des données de modèle statiques indépendantes de l’utilisateur intégrées dans le DLL ou dans un fichier de données séparé inclus avec le DLL. L’ensemble des ID de mots-clés pris en charge retournés par la routine GetCapabilities dépendrait de ces données. Par exemple, si la liste des ID de mots-clés pris en charge retournée par GetCapabilities inclut KwHeyCortana, les données de modèle statiques indépendantes de l’utilisateur incluraient des données pour « Hey Cortana » (ou sa traduction) pour toutes les langues prises en charge.
Modèle dynamique dépendant de l’utilisateur : IStream fournit un modèle de stockage à accès aléatoire. Le système d’exploitation passe un pointeur d’interface IStream à plusieurs des méthodes de l’interface IKeywordDetectorOemAdapter. Le système d’exploitation prend en charge l’implémentation IStream avec un stockage approprié pour jusqu’à 1 Mo de données.
Le contenu et la structure des données dans ce stockage sont définis par l’OEM. Le but prévu est le stockage persistant des données de modèle dépendant de l’utilisateur calculées ou récupérées par le DLL OEM.
Le système d’exploitation peut appeler les méthodes d’interface avec un IStream vide, en particulier si l’utilisateur n’a jamais formé un mot-clé. Le système d’exploitation crée un stockage IStream séparé pour chaque utilisateur. En d’autres termes, un IStream donné stocke les données de modèle pour un seul et unique utilisateur.
Le développeur du DLL OEM décide comment gérer les données indépendantes de l’utilisateur et dépendantes de l’utilisateur. Cependant, il ne doit jamais stocker de données utilisateur ailleurs que dans l’IStream. Une conception possible du DLL OEM consisterait à basculer en interne entre l’accès à l’IStream et les données statiques indépendantes de l’utilisateur en fonction des paramètres de la méthode actuelle. Une conception alternative pourrait vérifier l’IStream au début de chaque appel de méthode et ajouter les données statiques indépendantes de l’utilisateur à l’IStream si elles ne sont pas déjà présentes, permettant ainsi au reste de la méthode d’accéder uniquement à l’IStream pour toutes les données de modèle.
Formation et traitement audio opérationnel
Comme décrit précédemment, le flux de l’interface utilisateur de formation se traduit par des phrases riches en phonétique disponibles dans le flux audio. Chaque phrase est individuellement passée à IKeywordDetectorOemAdapter::VerifyUserKeyword pour vérifier qu’elle contient le mot-clé attendu et a une qualité acceptable. Après que toutes les phrases sont rassemblées et vérifiées par l’interface utilisateur, elles sont toutes passées en un seul appel à IKeywordDetectorOemAdapter::ComputeAndAddUserModelData.
L’audio est traité de manière unique pour la formation à l’activation vocale. Le tableau suivant résume les différences entre la formation à l’activation vocale et l’utilisation régulière de la reconnaissance vocale.
|
| Formation vocale | Reconnaissance vocale | |
| Mode | Brut | Brut ou parole |
| Épingler | Normale | KWS |
| Format audio | 32 bits float (Type = Audio, Subtype = IEEE_FLOAT, Taux d’échantillonnage = 16 kHz, bits = 32) | Géré par la pile audio du système d’exploitation |
| Mic | Mic 0 | Tous les micros en array, ou mono |
Aperçu du système de reconnaissance de mots-clés
Ce diagramme fournit un aperçu du système de reconnaissance de mots-clés.
Diagrammes de séquence de reconnaissance de mots-clés
Dans ces diagrammes, le module de runtime de la parole est montré comme la « plate-forme de parole ». Comme mentionné précédemment, la plate-forme de parole Windows est utilisée pour alimenter toutes les expériences vocales dans Windows 10, telles que Cortana et la dictée.
Lors du démarrage, les capacités sont rassemblées à l’aide de IKeywordDetectorOemAdapter::GetCapabilities.
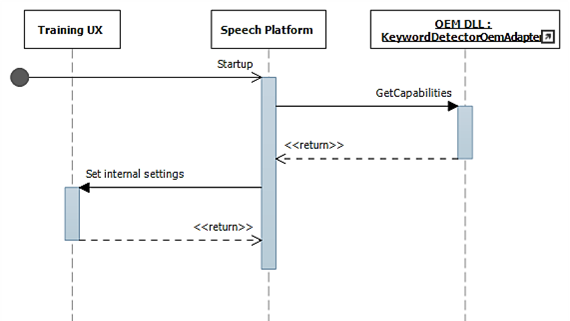
Plus tard, lorsque l’utilisateur choisit « Apprendre ma voix », le flux de formation est invoqué.
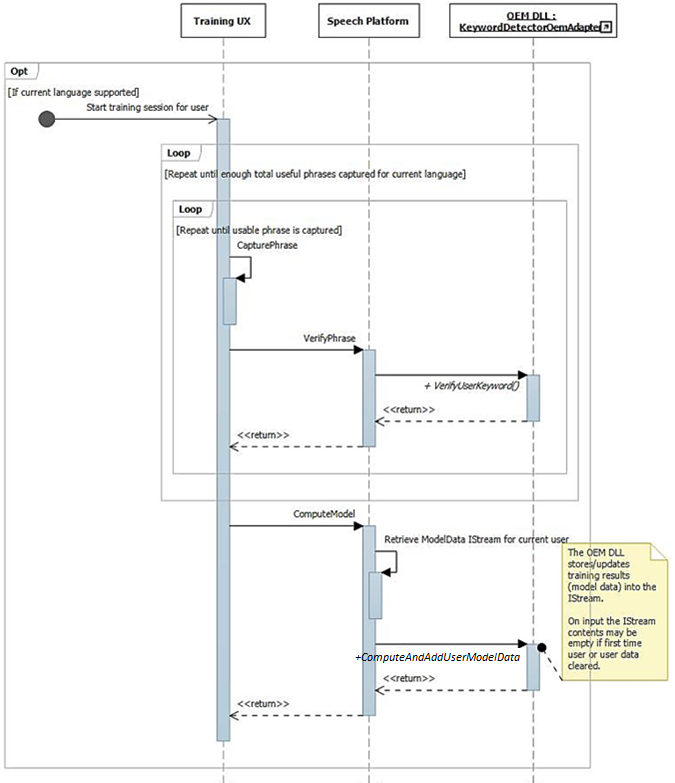
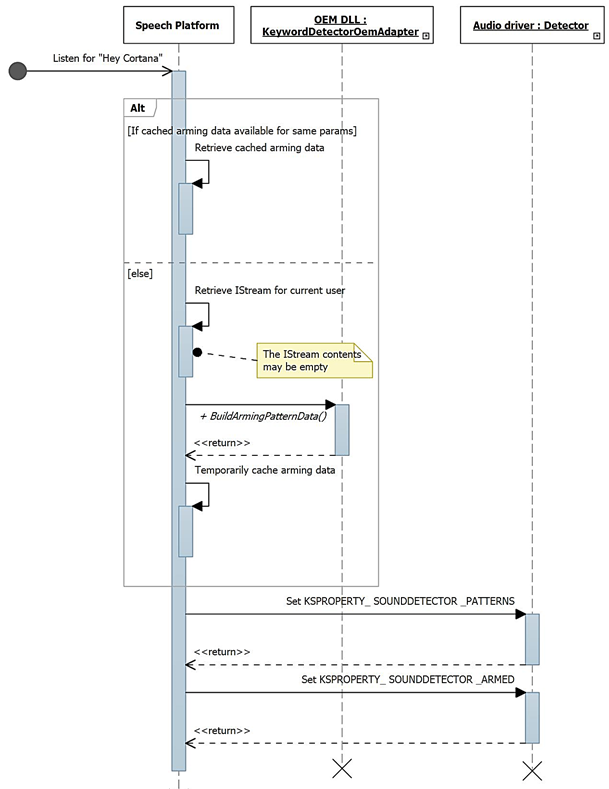
Ce diagramme décrit le processus d’armement pour la détection de mots-clés.
Améliorations WAVERT
Les interfaces miniport sont définies pour être implémentées par les pilotes miniport WaveRT. Ces interfaces fournissent des méthodes pour soit simplifier le pilote audio, améliorer les performances et la fiabilité du pipeline audio du système d’exploitation, soit prendre en charge de nouveaux scénarios. Une nouvelle propriété d’interface de périphérique PnP est définie pour permettre au pilote de fournir des expressions statiques de ses contraintes de taille de tampon au système d’exploitation.
Tailles de tampon
Un pilote fonctionne sous diverses contraintes lorsqu’il déplace des données audio entre le système d’exploitation, le pilote et le matériel. Ces contraintes peuvent être dues au transport matériel physique qui déplace les données entre la mémoire et le matériel, et/ou aux modules de traitement du signal dans le matériel ou le DSP associé.
Les solutions HW-KWS doivent prendre en charge des tailles de capture audio d’au moins 100 ms et jusqu’à 200 ms.
Le pilote exprime les contraintes de taille de tampon en définissant la propriété de périphérique DEVPKEY_KsAudio_PacketSize_Constraints sur l’interface de périphérique PnP KSCATEGORY_AUDIO du filtre KS qui a les broches de streaming KS. Cette propriété doit rester valide et stable tant que l’interface du filtre KS est activée. Le système d’exploitation peut lire cette valeur à tout moment sans avoir à ouvrir un handle vers le pilote et appeler le pilote.
DEVPKEY_KsAudio_PacketSize_Constraints
La valeur de la propriété DEVPKEY_KsAudio_PacketSize_Constraints contient une structure KSAUDIO_PACKETSIZE_CONSTRAINTS décrivant les contraintes matérielles physiques (c’est-à-dire en raison des mécanismes de transfert des données du tampon WaveRT vers le matériel audio). La structure comprend un tableau de 0 ou plus de structures KSAUDIO_PACKETSIZE_PROCESSINGMODE_CONSTRAINT décrivant les contraintes spécifiques à tout mode de traitement du signal. Le pilote définit cette propriété avant d’appeler PcRegisterSubdevice ou d’activer autrement son interface de filtre KS pour ses broches de streaming.
IMiniportWaveRTInputStream
Un pilote implémente cette interface pour une meilleure coordination du flux de données audio du pilote vers le système d’exploitation. Si cette interface est disponible sur un flux de capture, le système d’exploitation utilise les méthodes de cette interface pour accéder aux données dans le tampon WaveRT. Pour plus d’informations, veuillez consulter la section IMiniportWaveRTInputStream::GetReadPacket.
IMiniportWaveRTOutputStream
Un miniport WaveRT implémente facultativement cette interface pour être informé des progrès d’écriture du système d’exploitation et pour retourner la position précise du flux. Pour plus d’informations, consultez IMiniportWaveRTOutputStream::SetWritePacket, IMiniportWaveRTOutputStream::GetOutputStreamPresentationPosition et IMiniportWaveRTOutputStream::GetPacketCount.
Horodatages du compteur de performance
Plusieurs des routines du pilote retournent des horodatages du compteur de performance Windows reflétant l’heure à laquelle les échantillons sont capturés ou présentés par le périphérique.
Dans les appareils qui ont des pipelines DSP complexes et du traitement de signal, calculer un horodatage précis peut être difficile et doit être fait avec soin. Les horodatages ne doivent pas simplement refléter le moment où les échantillons ont été transférés vers ou depuis le système d’exploitation vers le DSP.
- Dans le DSP, suivez les horodatages des échantillons à l’aide d’une horloge interne du DSP.
- Entre le pilote et le DSP, calculez une corrélation entre le compteur de performance Windows et l’horloge murale du DSP. Les procédures pour cela peuvent varier de très simples (mais moins précises) à assez complexes ou novatrices (mais plus précises).
- Tenez compte de tout retard constant dû aux algorithmes de traitement du signal ou au pipeline ou aux transports matériels, à moins que ces retards ne soient autrement pris en compte.
Opération de lecture en mode rafale
Cette section décrit l’interaction entre le système d’exploitation et le pilote pour les lectures en mode rafale. La lecture en rafale peut se produire en dehors du scénario d’activation vocale tant que le pilote prend en charge le modèle de streaming basé sur les paquets WaveRT, y compris la fonction IMiniportWaveRTInputStream::GetReadPacket.
Deux exemples de scénarios de lecture en rafale sont discutés. Dans un scénario, si le miniport prend en charge une broche ayant la catégorie de broche KSNODETYPE_AUDIO_KEYWORDDETECTOR, alors le pilote commencera à capturer et à mettre en tampon des données en interne lorsqu’un mot-clé est détecté. Dans un autre scénario, le pilote peut optionnellement mettre en tampon des données en interne en dehors du tampon WaveRT si le système d’exploitation ne lit pas les données assez rapidement en appelant IMiniportWaveRTInputStream::GetReadPacket.
Pour mettre en rafale les données capturées avant la transition vers KSSTATE_RUN, le pilote doit conserver des informations d’horodatage précises des échantillons ainsi que les données de capture mises en tampon. Les horodatages identifient l’instant d’échantillonnage des échantillons capturés.
Après la transition du flux vers KSSTATE_RUN, le pilote définit immédiatement l’événement de notification de tampon car il a déjà des données disponibles.
À cet événement, le système d’exploitation appelle GetReadPacket() pour obtenir des informations sur les données disponibles.
a. Le pilote renvoie le numéro de paquet des données capturées valides (0 pour le premier paquet après la transition de KSSTATE_STOP à KSSTATE_RUN), à partir duquel le système d’exploitation peut dériver la position du paquet dans le tampon WaveRT ainsi que la position du paquet par rapport au début du flux.
b. Le pilote renvoie également la valeur du compteur de performance qui correspond à l’instant d’échantillonnage du premier échantillon du paquet. Notez que cette valeur du compteur de performance peut être relativement ancienne, en fonction de la quantité de données capturées mises en tampon dans le matériel ou le pilote (en dehors du tampon WaveRT).
c. S’il y a plus de données mises en tampon non lues disponibles, le pilote soit : i. Transfère immédiatement ces données dans l’espace disponible du tampon WaveRT (c’est-à-dire l’espace non utilisé par le paquet retourné par GetReadPacket), retourne true pour MoreData et définit l’événement de notification du tampon avant de retourner de cette routine. Ou, ii. Programme le matériel pour mettre en rafale le paquet suivant dans l’espace disponible du tampon WaveRT, retourne false pour MoreData et définit ultérieurement l’événement de tampon lorsque le transfert est terminé.
Le système d’exploitation lit les données du tampon WaveRT en utilisant les informations retournées par GetReadPacket().
Le système d’exploitation attend le prochain événement de notification de tampon. L’attente peut se terminer immédiatement si le pilote a défini l’événement de tampon à l’étape (2c).
Si le pilote n’a pas immédiatement défini l’événement à l’étape (2c), le pilote définit l’événement après avoir transféré plus de données capturées dans le tampon WaveRT et les a mises à disposition pour que le système d’exploitation les lise.
Revenez à (2). Pour les broches de détecteur de mots-clés KSNODETYPE_AUDIO_KEYWORDDETECTOR, les pilotes doivent allouer suffisamment de tampon interne pour au moins 5000 ms de données audio. Si le système d’exploitation ne parvient pas à créer un flux sur la broche avant que le tampon ne déborde, alors le pilote peut terminer l’activité de mise en tampon interne et libérer les ressources associées.
Wake on Voice
Wake On Voice (WoV) permet à l’utilisateur d’activer et d’interroger un moteur de reconnaissance vocale à partir d’un état d’écran éteint et de basse consommation, à un état d’écran allumé et de pleine puissance en prononçant un certain mot-clé, tel que « Hey Cortana ».
Cette fonctionnalité permet à l’appareil d’être toujours à l’écoute de la voix de l’utilisateur pendant que l’appareil est dans un état de basse consommation, y compris lorsque l’écran est éteint et que l’appareil est inactif. Cela se fait en utilisant un mode d’écoute, qui est de faible consommation par rapport à la consommation beaucoup plus élevée observée pendant l’enregistrement normal du microphone. La reconnaissance vocale à faible consommation permet à un utilisateur de simplement dire une phrase clé prédéfinie comme « Hey Cortana », suivie d’une phrase de commande enchaînée comme « quand est mon prochain rendez-vous » pour invoquer la parole de manière mains libres. Cela fonctionnera que l’appareil soit en cours d’utilisation ou inactif avec l’écran éteint.
La pile audio est responsable de la communication des données de réveil (ID du haut-parleur, déclencheur de mot-clé, niveau de confiance) ainsi que de la notification des clients intéressés que le mot-clé a été détecté.
Validation sur les systèmes Modern Standby
WoV à partir d’un état inactif du système peut être validé sur les systèmes Modern Standby en utilisant les tests Modern Standby Wake on Voice Basic Test on AC-power Source et Modern Standby Wake on Voice Basic Test on DC-power Source dans le HLK. Ces tests vérifient que le système dispose d’un détecteur de mots-clés matériel (HW-KWS), est capable d’entrer dans l’état de plus basse consommation d’exécution (DRIPS) et est capable de se réveiller de Modern Standby sur commande vocale avec une latence de reprise système inférieure ou égale à une seconde.