Vue d’ensemble des Data Flow dans DirectShow
[La fonctionnalité associée à cette page, DirectShow, est une fonctionnalité héritée. Il a été remplacé par MediaPlayer, IMFMediaEngine et Audio/Video Capture in Media Foundation. Ces fonctionnalités ont été optimisées pour Windows 10 et Windows 11. Microsoft recommande vivement que le nouveau code utilise MediaPlayer, IMFMediaEngine et Audio/Video Capture dans Media Foundation au lieu de DirectShow, si possible. Microsoft suggère que le code existant qui utilise les API héritées soit réécrit pour utiliser les nouvelles API si possible.]
Cette section fournit une vue d’ensemble du fonctionnement du flux de données dans DirectShow. Vous trouverez des détails dans d’autres sections de la documentation.
Les données sont conservées dans des mémoires tampons, qui sont simplement des tableaux d’octets. Chaque mémoire tampon est encapsulée par un objet COM appelé exemple de média, qui implémente l’interface IMediaSample . Les exemples sont créés par un autre type d’objet, appelé allocateur, qui implémente l’interface IMemAllocator . Un allocateur est affecté pour chaque connexion de broche, bien que deux connexions de broche ou plus puissent partager le même allocateur. L’image suivante illustre ce processus.
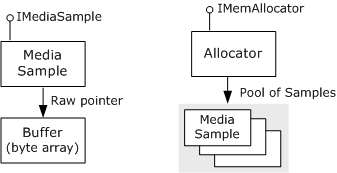
Chaque allocateur crée un pool d’exemples de média et alloue les mémoires tampons pour chaque exemple. Chaque fois qu’un filtre doit remplir une mémoire tampon avec des données, il demande un exemple à partir de l’allocateur en appelant IMemAllocator::GetBuffer. Si l’allocateur contient des exemples qui ne sont pas actuellement utilisés par un autre filtre, la méthode GetBuffer retourne immédiatement avec un pointeur vers l’exemple. Si tous les exemples de l’allocateur sont en cours d’utilisation, la méthode se bloque jusqu’à ce qu’un exemple soit disponible. Lorsque la méthode retourne un exemple, le filtre place les données dans la mémoire tampon, définit les indicateurs appropriés sur l’exemple (généralement avec un horodatage) et remet l’exemple en aval.
Lorsqu’un filtre de convertisseur reçoit un exemple, il vérifie l’horodatage et se conserve sur l’exemple jusqu’à ce que l’horloge de référence du graphe de filtre indique que les données doivent être rendues. Une fois que le filtre a rendu les données, il libère l’exemple. L’exemple ne retourne pas dans le pool d’échantillons de l’allocateur tant que le nombre de références de l’échantillon n’est pas égal à zéro, ce qui signifie que chaque filtre a libéré l’échantillon. L’image suivante illustre ce processus.
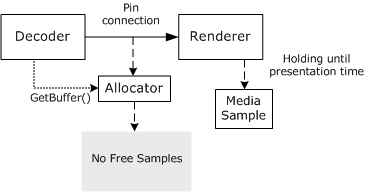
Le filtre amont peut s’exécuter avant le convertisseur, c’est-à-dire qu’il peut remplir les mémoires tampons plus rapidement que le convertisseur ne les consomme. Malgré cela, les exemples ne sont pas rendus plus tôt, car le renderer tient chacun jusqu’à son heure de présentation. En outre, le filtre amont ne remplace pas accidentellement les mémoires tampons, car GetSample retourne uniquement des exemples qui ne sont pas utilisés autrement. La quantité par laquelle le filtre amont peut s’exécuter à l’avance est déterminée par le nombre d’échantillons dans le pool de l’allocateur.
Le diagramme précédent montre un seul allocateur, mais il existe généralement plusieurs allocateurs par flux. Ainsi, lorsque le convertisseur libère un exemple, il peut avoir un effet en cascade. Le diagramme suivant montre une situation dans laquelle un décodeur contient une image vidéo compressée pendant qu’il attend que le convertisseur libère un exemple. Un filtre d’analyseur attend également que le décodeur libère un exemple.
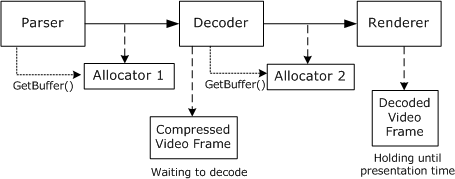
Lorsque le convertisseur libère son exemple, l’appel en attente du décodeur à GetBuffer retourne. Le décodeur peut ensuite décoder l’image vidéo compressée et libérer l’exemple qu’il détenait, débloquant ainsi l’appel GetBuffer en attente de l’analyseur.
Rubriques connexes