Procedure consigliate per implementare l'affidabilità a livello di distribuzione e cluster per il servizio Azure Kubernetes
Questo articolo illustra le procedure consigliate per l'affidabilità del cluster implementata sia a livello di distribuzione che di cluster per i carichi di lavoro servizio Azure Kubernetes (AKS). L'articolo è destinato agli operatori dei cluster e agli sviluppatori responsabili della distribuzione e della gestione delle applicazioni nel servizio Azure Kubernetes.
Le procedure consigliate in questo articolo sono organizzate nelle categorie seguenti:
Procedure consigliate a livello di distribuzione
Le procedure consigliate a livello di distribuzione seguenti consentono di garantire una disponibilità e affidabilità elevata per i carichi di lavoro del servizio Azure Kubernetes. Queste procedure consigliate sono configurazioni locali che è possibile implementare nei file YAML per i pod e le distribuzioni.
Nota
Assicurarsi di implementare queste procedure consigliate ogni volta che si distribuisce un aggiornamento nell'applicazione. In caso contrario, è possibile che si verifichino problemi con la disponibilità e l'affidabilità dell'applicazione, ad esempio tempi di inattività involontari dell'applicazione.
Budget per l’interruzione dei pod (PDB)
Indicazioni sulle procedure consigliate
Usare i budget di interruzione dei pod (PDB) per assicurarsi che un numero minimo di pod rimanga disponibile durante le interruzioni volontarie, ad esempio operazioni di aggiornamento o eliminazioni accidentali dei pod.
I budget di interruzione dei pod (PDB) consentono di definire come i set di distribuzioni o repliche rispondono durante le interruzioni involontarie; ad esempio operazioni di aggiornamento o eliminazioni accidentali dei pod. Con i budget di interruzione dei pod è possibile definire un numero minimo o massimo di risorse non disponibili. I budget di interruzione dei pod influiscono solo sull'API di rimozione per le interruzioni volontarie.
Si supponga, ad esempio, di dover eseguire un aggiornamento del cluster e di avere già definito un budget di interruzione dei pod. Prima di eseguire l'aggiornamento del cluster, l'utilità di pianificazione di Kubernetes verifica che il numero minimo di pod definiti nel budget di interruzione dei pod sia disponibile. Se l'aggiornamento può potenzialmente causare ridurre il numero di pod disponibili al di sotto del valore minimo definito nei budget di interruzione dei pod, l'utilità di pianificazione pianifica pod aggiuntivi in altri nodi prima di consentire l'esecuzione dell'aggiornamento. Se non si imposta un budget di interruzione dei pod, l'utilità di pianificazione non dispone di vincoli relativamente al numero di pod che possono non essere disponibili durante l'aggiornamento, il che può causare la carenza di risorse e potenziali interruzioni del cluster.
Nel file di definizione del budget di interruzione dei pod di esempio seguente il campo minAvailable imposta il numero minimo di pod che devono rimanere disponibili durante le interruzioni volontarie. Il valore può essere un numero assoluto (ad esempio, 3) o una percentuale del numero desiderato di pod (ad esempio, 10%).
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: mypdb
spec:
minAvailable: 3 # Minimum number of pods that must remain available during voluntary disruptions
selector:
matchLabels:
app: myapp
Per altre informazioni, vedere Pianificare la disponibilità con i budget di interruzione dei pod e Specificare un budget di interruzione per l'applicazione.
Limiti di CPU e memoria dei pod
Indicazioni sulle procedure consigliate
Impostare i limiti di CPU e memoria dei pod per tutti i pod per assicurarsi che i pod non consumino tutte le risorse in un nodo e per fornire protezione durante le minacce al servizio, ad esempio gli attacchi DDoS.
I limiti di CPU e memoria dei pod definiscono la quantità massima di CPU e memoria utilizzabile da un pod. Quando un pod supera i limiti definiti, viene contrassegnato per la rimozione. Per altre informazioni, vedere Unità di risorse della CPU in Kubernetes e Unità di risorse della memoria in Kubernetes.
L'impostazione dei limiti di CPU e memoria consente di mantenere l'integrità dei nodi e ridurre al minimo l'impatto su altri pod nel nodo. Non impostare un limite pod superiore a quello che i nodi sono in grado di supportare. Ogni nodo servizio Azure Kubernetes riserva una determinata quantità di CPU e memoria per i componenti principali di Kubernetes. Se si imposta un limite di pod superiore a quello che il nodo può supportare, l'applicazione potrebbe provare a usare un numero eccessivo di risorse e avere un impatto negativo su altri pod nel nodo. Gli amministratori dei cluster devono impostare quote di risorse in uno spazio dei nomi che richiede di impostare limiti e richieste di risorse. Per altre informazioni, vedere Applicare le quote di risorse nel servizio Azure Kubernetes.
Nel file di definizione del pod di esempio seguente la sezione resources imposta i limiti di CPU e memoria per il pod:
kind: Pod
apiVersion: v1
metadata:
name: mypod
spec:
containers:
- name: mypod
image: mcr.microsoft.com/oss/nginx/nginx:1.15.5-alpine
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 250m
memory: 256Mi
Suggerimento
È possibile usare il comando kubectl describe node per visualizzare la capacità di CPU e memoria dei nodi, come illustrato nell’esempio seguente:
kubectl describe node <node-name>
# Example output
Capacity:
cpu: 8
ephemeral-storage: 129886128Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32863116Ki
pods: 110
Allocatable:
cpu: 7820m
ephemeral-storage: 119703055367
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 28362636Ki
pods: 110
Per altre informazioni, vedere Assegnare risorse CPU a contenitori e pod e Assegnare risorse di memoria a contenitori e pod.
Hook di pre-arresto
Indicazioni sulle procedure consigliate
Se applicabile, usare gli hook di pre-arresto per garantire la terminazione normale di un contenitore.
Un hook PreStop viene chiamato immediatamente prima della terminazione di un contenitore da una chiamata API o un evento di gestione, ad esempio una precedenza, un conflitto risorse o un errore del probe di attività/avvio. Una chiamata all'hook PreStop ha esito negativo se il contenitore è già in uno stato terminato o completato e l'hook deve essere completato prima dell'invio del segnale TERM per arrestare l'invio del contenitore. Il conto alla rovescia del periodo di tolleranza di terminazione del pod inizia prima dell'esecuzione dell'hook PreStop, quindi il contenitore termina entro il periodo di tolleranza della terminazione.
Il file di definizione di pod di esempio seguente mostra come usare un hook PreStop per garantire la terminazione normale di un contenitore:
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
preStop:
exec:
command: ["/bin/sh","-c","nginx -s quit; while killall -0 nginx; do sleep 1; done"]
Per altre informazioni, vedere Hook del ciclo di vita dei contenitori e Terminazione dei pod.
maxUnavailable
Indicazioni sulle procedure consigliate
Definire il numero massimo di pod che possono non essere disponibili durante un aggiornamento in sequenza usando il campo
maxUnavailablenella distribuzione per garantire che un numero minimo di pod rimanga disponibile durante l'aggiornamento.
Il campo maxUnavailable specifica il numero massimo di pod che possono essere non disponibili durante il processo di aggiornamento. Il valore può essere un numero assoluto (ad esempio, 3) o una percentuale del numero desiderato di pod (ad esempio, 10%). maxUnavailable si riferisce all'API Di eliminazione, usata durante gli aggiornamenti in sequenza.
Il manifesto della distribuzione di esempio seguente usa il campo maxAvailable per impostare il numero massimo di pod che possono essere non disponibili durante il processo di aggiornamento:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1 # Maximum number of pods that can be unavailable during the upgrade
Per altre informazioni, vedere Numero massimo non disponibili.
Vincoli di distribuzione della topologia dei pod
Indicazioni sulle procedure consigliate
Usare i vincoli di distribuzione della topologia dei pod per verificare che i pod vengano distribuiti tra nodi o zone diversi per migliorare la disponibilità e l'affidabilità.
È possibile usare i vincoli di distribuzione della topologia dei pod per controllare la modalità di distribuzione dei pod nel cluster in base alla topologia dei nodi e alla distribuzione di pod in nodi o zone diverse per migliorare la disponibilità e l'affidabilità.
Il file di definizione del pod di esempio seguente mostra come usare il campo topologySpreadConstraints per distribuire i pod in nodi diversi:
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
# Configure a topology spread constraint
topologySpreadConstraints:
- maxSkew: <integer>
minDomains: <integer> # optional
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
matchLabelKeys: <list> # optional
nodeAffinityPolicy: [Honor|Ignore] # optional
nodeTaintsPolicy: [Honor|Ignore] # optional
Per altre informazioni, vedere Vincoli di distribuzione della topologia pod.
Probe di idoneità, attività e avvio
Indicazioni sulle procedure consigliate
Configurare i probe di idoneità, attività e avvio, se applicabile, per migliorare la resilienza dei carichi elevati e dei riavvii dei contenitori inferiori.
Probe di idoneità
In Kubernetes kubelet usa probe di idoneità per sapere quando un contenitore è pronto per iniziare ad accettare il traffico. Un pod viene considerato pronto quando tutti i suoi contenitori sono pronti. Quando un pod non è pronto, viene rimosso dai servizi di bilanciamento del carico. Per altre informazioni, vedere Probe di integrità in Kubernetes.
Il file di definizione del pod di esempio seguente mostra una configurazione di un probe di idoneità:
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
Per altre informazioni, vedere Configurare i probe di integrità.
Probe di attività
In Kubernetes kubelet usa probe di attività per sapere quando riavviare un contenitore. Se un contenitore non supera il probe di attività, il contenitore viene riavviato. Per altre informazioni, vedere Probe di attività in Kubernetes.
Il file di definizione del pod di esempio seguente mostra una configurazione di un probe di attività:
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
Un altro tipo di probe di attività usa una richiesta HTTP GET. Il file di definizione del pod di esempio seguente mostra una configurazione di un probe di attività con una richiesta HTTP GET:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: registry.k8s.io/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
Per altre informazioni, vedere Configurare i probe di attività e Definire una richiesta HTTP di attività.
Probe di avvio
In Kubernetes kubelet usa probe di avvio per sapere quando è stata avviata l'applicazione di un contenitore. Quando si configura un probe di avvio, i probe di idoneità e attività non vengono avviati finché il probe di avvio non ha esito positivo per evitare chi i robe di idoneità e attività non interferiscano con l'avvio dell'applicazione. Per altre informazioni, vedere Probe di avvio in Kubernetes
Il file di definizione del pod di esempio seguente mostra una configurazione di un probe di avvio:
startupProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 30
periodSeconds: 10
Applicazioni con più repliche
Indicazioni sulle procedure consigliate
Distribuire almeno due repliche dell'applicazione per garantire disponibilità elevata e resilienza negli scenari con nodi inattivi.
In Kubernetes è possibile usare il campo replicas nella distribuzione per specificare il numero di pod da eseguire. L’esecuzione di almeno due repliche dell'applicazione permette di garantire disponibilità elevata e resilienza negli scenari con nodi inattivi. Se sono presenti zone di disponibilità abilitate, è possibile usare il campo replicas per specificare il numero di pod da eseguire in più zone di disponibilità.
Il file di definizione del pod di esempio seguente mostra come usare il campo replicas per specificare il numero di pod da eseguire:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Per altre informazioni, vedere Panoramica della soluzione a disponibilità elevata attiva-attiva consigliata per il servizio Azure Kubernetes e Repliche nelle specifiche di distribuzione.
Procedure consigliate a livello di cluster e pool di nodi
Le procedure consigliate seguenti a livello di cluster e di distribuzione consentono di garantire una disponibilità e affidabilità elevata per i cluster del servizio Azure Kubernetes. È possibile implementare queste procedure consigliate al momento della creazione o dell'aggiornamento dei cluster del servizio Azure Kubernetes.
Zone di disponibilità
Indicazioni sulle procedure consigliate
Usare più zone di disponibilità durante la creazione di un cluster del servizio Azure Kubernetes per garantire la disponibilità elevata in scenari con zone inattive. Tenere presente che non è possibile modificare la configurazione delle zone di disponibilità dopo la creazione del cluster.
Le zone di disponibilità sono gruppi separati di data center all'interno di un'area. Queste zone sono abbastanza vicine da poter stabilire connessioni a bassa latenza con altre zone di disponibilità, ma abbastanza lontane da ridurre la possibilità che più di una zone sia interessata da interruzioni locali o meteorologiche. L'uso delle zone di disponibilità consente di mantenere sincronizzati e accessibili i dati negli scenari con una zona inattiva. Per altre informazioni, vedere Esecuzione di più zone.
La scalabilità automatica del cluster
Indicazioni sulle procedure consigliate
Usare il ridimensionamento automatico del cluster per verificare che il cluster possa gestire un carico maggiore e ridurre i costi in presenza di carichi ridotti.
Per restare al passo con le richieste delle applicazioni nel servizio Azure Kubernetes, potrebbe essere necessario modificare il numero di nodi che eseguono i carichi di lavoro. Il componente di scalabilità automatica del cluster può cercare i pod del cluster che non possono essere pianificati a causa di vincoli delle risorse. Quando il ridimensionamento automatico del cluster rileva i problemi, aumenta il numero di nodi nel pool di nodi per soddisfare la richiesta dell'applicazione. Inoltre, controlla regolarmente i nodi per rilevare la mancanza di pod in esecuzione e ridimensiona il numero di nodi in base alle esigenze. Per altre informazioni, vedere Ridimensionamento automatico dei cluster nel servizio Azure Kubernetes.
È possibile usare il parametro --enable-cluster-autoscaler durante la creazione di un cluster del servizio Azure Kubernetes per abilitare il ridimensionamento automatico del cluster, come illustrato nell'esempio seguente:
az aks create \
--resource-group myResourceGroup \
--name myAKSCluster \
--node-count 2 \
--vm-set-type VirtualMachineScaleSets \
--load-balancer-sku standard \
--enable-cluster-autoscaler \
--min-count 1 \
--max-count 3 \
--generate-ssh-keys
È anche possibile abilitare il ridimensionamento automatico del cluster in un pool di nodi esistenti o configurare dettagli più granulari per il ridimensionamento automatico del cluster modificando i valori predefiniti nel profilo di ridimensionamento automatico a livello di cluster.
Per altre informazioni, vedere Usare il ridimensionamento automatico del cluster nel servizio Azure Kubernetes.
Load Balancer standard
Indicazioni sulle procedure consigliate
Usare Load Balancer Standard per offrire maggiore affidabilità e risorse, supporto per più zone di disponibilità, probe HTTP e funzionalità in più data center.
In Azure, lo SKU Load Balancer Standard è progettato per essere idoneo per il bilanciamento del carico del traffico a livello di rete quando sono necessarie prestazioni elevate e bassa latenza. Load Balancer Standard instrada il traffico all'interno e tra aree e alle zone di disponibilità per offrire una resilienza elevata. Lo SKU Standard è lo SKU consigliato e predefinito da usare durante la creazione di un cluster del servizio Azure Kubernetes.
Importante
Il servizio Load Balancer Basic verrà ritirato il 30 settembre 2025. Per altre informazioni, consultare l'annuncio ufficiale. È consigliabile usare Load Balancer Standard per le nuove distribuzioni e aggiornare le distribuzioni esistenti a Load Balancer Standard. Per altre informazioni, vedere Aggiornamento da Load Balancer Basic.
L'esempio seguente mostra un manifesto del servizio LoadBalancer che usa Load Balancer Standard:
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/azure-load-balancer-ipv4 # Service annotation for an IPv4 address
name: azure-load-balancer
spec:
type: LoadBalancer
ports:
- port: 80
selector:
app: azure-load-balancer
Per ulteriori informazioni, vedere Usare Load Balancer Standard nel servizio Azure Kubernetes.
Suggerimento
È anche possibile usare un controller di ingresso o un mesh del servizio per gestire il traffico di rete, con ogni opzione che offre funzionalità e funzionalità diverse.
Pool di nodi di sistema
Usare pool di nodi di sistema dedicati
Indicazioni sulle procedure consigliate
Usare i pool di nodi di sistema per assicurarsi che non vengano eseguite altre applicazioni utente negli stessi nodi, con conseguenti problemi di scarsità di risorse e effetti sui pod di sistema.
Usare i pool di nodi di sistema dedicati per verificare che nessun'altra applicazione utente venga eseguita negli stessi nodi, causando carenza di risorse e potenziali interruzioni del cluster a causa di race condition. Per usare un pool di nodi di sistema dedicato, è possibile usare il taint CriticalAddonsOnly nel pool di nodi di sistema. Per altre informazioni, vedere Usare i pool di nodi di sistema nel servizio Azure Kubernetes.
Ridimensionamento automatico dei pool di nodi di sistema
Indicazioni sulle procedure consigliate
Configurare il ridimensionamento automatico per i pool di nodi di sistema per impostare un limite minimo e massimo di scalabilità per il pool di nodi.
Usare il ridimensionamento automatico dei pool di nodi di sistema per impostare un limite minimo e massimo di scalabilità per il pool di nodi. Il pool di nodi di sistema deve sempre essere in grado di ridimensionarsi per soddisfare le esigenze dei pod di sistema. Se il pool di nodi di sistema non è in grado di ridimensionarsi, il cluster esaurisce le risorse necessarie per gestire la pianificazione, il ridimensionamento e il bilanciamento del carico, il che può impedire a un cluster di rispondere.
Per altre informazioni, vedere Usare il ridimensionamento automatico del cluster nei pool di nodi.
Almeno tre nodi per pool di nodi di sistema
Indicazioni sulle procedure consigliate
Verificare che nei pool di nodi di sistema siano disponibili almeno tre nodi per garantire la resilienza in scenari di blocco/aggiornamento, che possono causare il riavvio o l'arresto dei nodi.
I pool di nodi di sistema vengono usati per eseguire i pod di sistema, ad esempio kube-proxy, coredns e il plug-in di Azure CNI. Microsoft consiglia di verificare che nei pool di nodi di sistema siano disponibili almeno tre nodi per garantire la resilienza in scenari di blocco/aggiornamento, che possono causare il riavvio o l'arresto dei nodi. Per altre informazioni, vedere Gestire i pool di nodi di sistema nel servizio Azure Kubernetes.
Rete accelerata
Indicazioni sulle procedure consigliate
Usare la funzionalità Rete accelerata per ridurre la latenza, l'instabilità e l'utilizzo della CPU nelle macchine virtuali.
La funzionalità Rete accelerata abilita Single Root I/O Virtualization (SR-IOV) nei tipi di macchine virtuali (VM) supportati migliorandone significativamente le prestazioni di rete.
L'immagine seguente mostra le comunicazioni tra due macchine virtuali, con e senza rete accelerata:
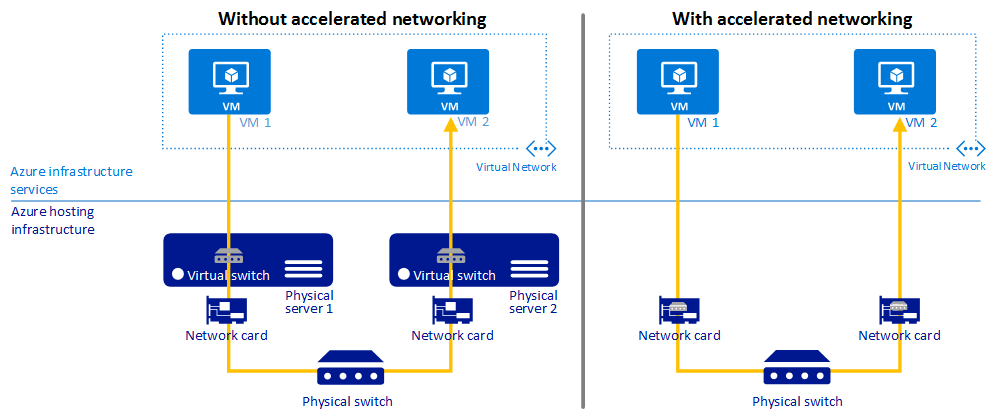
Per altre informazioni, vedere Panoramica della rete accelerata.
Versioni dell'immagine
Indicazioni sulle procedure consigliate
Non è consigliabile usare il tag
latestnelle immagini.
Tag di immagini di contenitori
L'uso del tag latest per le immagini del contenitore può causare un comportamento imprevedibile e rende difficile tenere traccia della versione dell'immagine in esecuzione nel cluster. È possibile ridurre al minimo questi rischi integrando ed eseguendo strumenti di analisi e correzione nei contenitori in fase di compilazione e runtime. Per ulteriori informazioni, vedere Procedure consigliate per la gestione delle immagini dei contenitori nel servizio Azure Kubernetes.
Aggiornamenti delle immagini del nodo
Il servizio Azure Kubernetes fornisce più canali di aggiornamento automatico per gli aggiornamenti delle immagini del sistema operativo dei nodi. È possibile usare questi canali per controllare la tempistica degli aggiornamenti. È consigliabile unire questi canali di aggiornamento automatico per verificare che i nodi eseguano le patch di sicurezza e gli aggiornamenti più recenti. Per altre informazioni, vedere Aggiornare automaticamente le immagini del sistema operativo dei nodi nel servizio Azure Kubernetes.
Livello Standard per i carichi di lavoro di produzione
Indicazioni sulle procedure consigliate
Usare il livello Standard per i carichi di lavoro di produzione per aumentare l’affidabilità e le risorse del cluster e supportare un massimo di 5.000 nodi in un cluster. Per impostazione predefinita, il contratto di servizio per il tempo di attività è abilitato. Se è necessario LTS, valutare la possibilità di usare il livello Premium.
Il livello Standard per il servizio Azure Kubernetes (AKS) offre un contratto di servizio per un tempo di attività del 99,9% supportato finanziariamente per i carichi di lavoro di produzione. Anche il livello Standard offre una maggiore affidabilità e più risorse del cluster e supporta un massimo di 5.000 nodi in un cluster. Per impostazione predefinita, il contratto di servizio per il tempo di attività è abilitato. Per altre informazioni, vedere Piani tariffari per la gestione dei cluster del servizio Azure Kubernetes.
Usare Azure CNI per l'allocazione dinamica degli indirizzi IP
Indicazioni sulle procedure consigliate
Configurare Azure CNI per l'allocazione dinamica degli indirizzi IP allo scopo di ottimizzare l’uso degli indirizzi IP ed evitare l'esaurimento di indirizzi IP per i cluster del servizio Azure Kubernetes.
La nuova funzionalità di allocazione IP dinamica in Azure CNI risolve questo problema allocando gli indirizzi IP ai pod da una subnet separata dalla subnet che ospita il cluster del servizio Azure Kubernetes, oltre a offrire i vantaggi seguenti:
- Migliore utilizzo IP: gli indirizzi IP vengono allocati dinamicamente ai pod del cluster dalla subnet Pod. Ciò comporta un migliore utilizzo degli indirizzi IP nel cluster rispetto alla soluzione CNI tradizionale, che esegue l'allocazione statica degli indirizzi IP per ogni nodo.
- Scalabile e flessibile: le subnet dei nodi e dei pod possono essere scalate in modo indipendente. Una singola subnet pod può essere condivisa tra più pool di nodi di un cluster o tra più cluster del servizio Azure Kubernetes distribuiti nella stessa rete virtuale. È anche possibile configurare una subnet pod separata per un pool di nodi.
- Prestazioni elevate: poiché ai pod vengono assegnati indirizzi IP di rete virtuale, hanno connettività diretta ad altri pod e risorse del cluster nella rete virtuale. La soluzione supporta cluster molto grandi senza alcuna riduzione delle prestazioni.
- Criteri di rete virtuale separati per i pod: poiché i pod hanno una subnet separata, è possibile configurare criteri di rete virtuale separati per essi diversi dai criteri dei nodi. Ciò consente molti scenari utili, ad esempio consentire la connettività Internet solo per i pod e non per i nodi, correggere l'indirizzo IP di origine per il pod in un pool di nodi usando un gateway NAT di Azure e usare gruppi di sicurezza di rete per filtrare il traffico tra pool di nodi.
- Criteri di rete di Kubernetes: la nuova soluzione supporta sia i criteri di rete di Azure che di Calico.
Per altre informazioni, vedere Configurare la rete CNI di Azure per l'allocazione dinamica degli indirizzi IP e il supporto avanzato delle subnet nel servizio Azure Kubernetes.
Macchine virtuali con SKU v5
Indicazioni sulle procedure consigliate
Usare lo SKU di macchine virtuali v5 per migliorare le prestazioni durante e dopo gli aggiornamenti, ridurre l’impatto complessivo e offrire una connessione più affidabile per le applicazioni.
Per i pool di nodi nel servizio Azure Kubernetes, usare macchine virtuali con SKU v5 e dischi temporanei del sistema operativo per fornire risorse di calcolo sufficienti per i pod kube-system. Per altre informazioni, vedere Procedure consigliate per prestazioni e scalabilità per carichi di lavoro di grandi dimensioni nel servizio Azure Kubernetes.
Non usare macchine virtuali serie B
Indicazioni sulle procedure consigliate
Non usare macchine virtuali serie B per i cluster del servizio Azure Kubernetes perché offrono prestazioni ridotte e non funzionano correttamente con il servizio Azure Kubernetes.
Le macchine virtuali serie B offrono prestazioni ridotte e non funzionano correttamente con il servizio Azure Kubernetes. È invece consigliabile usare macchine virtuali con SKU v5.
Dischi Premium
Indicazioni sulle procedure consigliate
Usare dischi Premium per ottenere una disponibilità del 99,9% in una macchina virtuale.
I dischi Premium di Azure offrono una latenza del disco di sottomillisecondo coerente, nonché operazioni di I/O al secondo e velocità effettiva elevate. I dischi Premium sono progettati per offrire bassa latenza, prestazioni elevate e coerenti per le macchine virtuali.
Il manifesto YAML di esempio seguente mostra una definizione di classe di archiviazione per un disco Premium:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: premium2-disk-sc
parameters:
cachingMode: None
skuName: PremiumV2_LRS
DiskIOPSReadWrite: "4000"
DiskMBpsReadWrite: "1000"
provisioner: disk.csi.azure.com
reclaimPolicy: Delete
volumeBindingMode: Immediate
allowVolumeExpansion: true
Per altre informazioni, vedere Usare dischi SSD Premium di Azure v2 nel servizio Azure Kubernetes.
Informazioni dettagliate contenitore
Indicazioni sulle procedure consigliate
Abilitare Informazioni dettagliate contenitore per monitorare e diagnosticare le prestazioni delle applicazioni in contenitori.
Informazioni dettagliate contenitore è una funzionalità di Monitoraggio di Azure che raccoglie e analizza i log dei contenitori dal servizio Azure Kubernetes. È possibile analizzare i dati raccolti con una raccolta di visualizzazioni e cartelle di lavoro predefinite.
È possibile abilitare Informazioni dettagliate contenitore nel cluster del servizio Azure Kubernetes usando metodi diversi. L'esempio seguente mostra come abilitare Informazioni dettagliate contenitore in un cluster esistente tramite l'interfaccia della riga di comando di Azure:
az aks enable-addons -a monitoring --name myAKSCluster --resource-group myResourceGroup
Per altre informazioni, vedere Abilitare il monitoraggio dei cluster di Kubernetes.
Criteri di Azure
Indicazioni sulle procedure consigliate
Applicare e imporre i requisiti di sicurezza e conformità per i cluster del servizio Azure Kubernetes con Criteri di Azure.
È possibile applicare e imporre i criteri di sicurezza predefiniti nei cluster del servizio Azure Kubernetes tramite Criteri di Azure. Criteri di Azure consente di applicare gli standard dell'organizzazione e valutare la conformità su larga scala. Dopo aver installato il componente aggiuntivo di Criteri di Azure per il servizio Azure Kubernetes, è possibile applicare al cluster singole definizioni di criteri o gruppi di definizioni di criteri denominati iniziative.
Per altre informazioni, vedere Proteggere i cluster del servizio Azure Kubernetes con Criteri di Azure.
Passaggi successivi
Questo articolo è incentrato sulle procedure consigliate per implementare l'affidabilità a livello di distribuzione e cluster per i carichi di lavoro del servizio Azure Kubernetes (AKS). Per altre procedure consigliate, vedere gli articoli seguenti:

Azure Kubernetes Service