Funzionalità di ottimizzazione delle prestazioni dell'attività Copy
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questo articolo illustra le funzionalità di ottimizzazione delle prestazioni dell'attività Copy che è possibile sfruttare nelle pipeline di Azure Data Factory e Synapse.
Configurazione delle funzionalità delle prestazioni con l'interfaccia utente
Quando si seleziona un'attività Copy nell'area di disegno dell'editor della pipeline e si sceglie la scheda Impostazioni nell'area di configurazione dell'attività sotto l'area di disegno, verranno visualizzate le opzioni per configurare tutte le funzionalità delle prestazioni descritte di seguito.
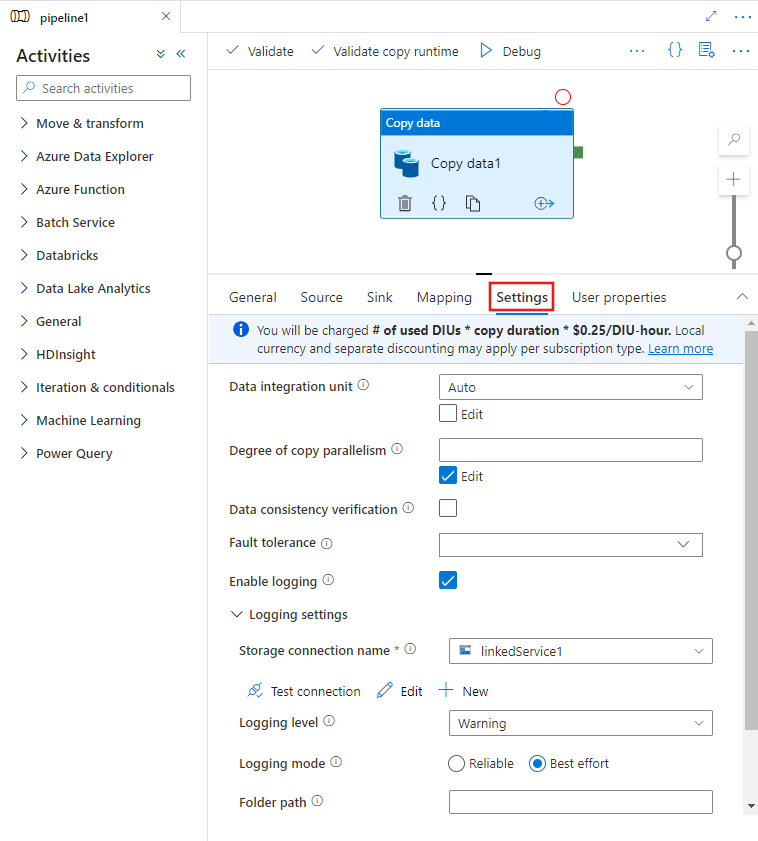
Unità di integrazione dati
Un'unità di integrazione dei dati è un'unità di misura che rappresenta la potenza, ossia la combinazione tra CPU, memoria e allocazione di risorse di rete, di una singola unità nel servizio. L'unità di integrazione dati si applica solo ad Azure Integration Runtime ma non al runtime di integrazione self-hosted.
Le DIU consentite per abilitare l'esecuzione di un'attività di copia sono tra 4 e 256. Se non specificato o se si sceglie "Auto" nell'interfaccia utente, il servizio applica in modo dinamico l'impostazione di DIU ottimale in base alla coppia di sink di origine e al modello di dati. La tabella seguente elenca gli intervalli DIU supportati e il comportamento predefinito in scenari di copia diversi:
| Scenario di copia | Intervallo DIU supportato | Numero di unità di integrazione dati predefinite determinato dal servizio |
|---|---|---|
| Tra archivi file | - Copia da o verso un singolo file: 4 - Copia da e verso più file: 4-256 a seconda del numero e delle dimensioni dei file Ad esempio, se si copiano dati da una cartella con 4 file di grandi dimensioni e si sceglie di mantenere la gerarchia, il numero massimo effettivo di unità di distribuzione è 16; quando si sceglie di unire il file, il numero massimo effettivo di DIU è 4. |
Tra 4 e 32 in base al numero e alle dimensioni dei file |
| Dall'archivio file all'archivio non file | - Copia da un singolo file: 4 - Copia da più file: 4-256 a seconda del numero e delle dimensioni dei file Ad esempio, se si copiano dati da una cartella con 4 file di grandi dimensioni, il numero massimo effettivo di unità di distribuzione è 16. |
- Copiare nel database SQL di Azure o in Azure Cosmos DB: tra 4 e 16 a seconda del livello sink (DTU/UR) e del modello di file di origine - Copiare in Azure Synapse Analytics usando PolyBase o l'istruzione COPY: 2 - Altro scenario: 4 |
| Dall'archivio non file all'archivio file | - Copiare da archivi dati abilitati per l'opzione di partizione (inclusi Database di Azure per PostgreSQL, Database SQL di Azure, Istanza gestita di SQL di Azure, Azure Synapse Analytics, Oracle, Netezza, SQL Servere Teradata): 4-256 durante la scrittura in una cartella e 4 durante la scrittura in un singolo file. Si noti che la partizione dati di origine può usare fino a 4 unità di distribuzione. - Altri scenari: 4 |
- Copia da REST o HTTP: 1 - Copia da Amazon Redshift usando UNLOAD: 4 - Altro scenario: 4 |
| Tra archivi non di file | - Copiare da archivi dati abilitati per l'opzione di partizione (inclusi Database di Azure per PostgreSQL, Database SQL di Azure, Istanza gestita di SQL di Azure, Azure Synapse Analytics, Oracle, Netezza, SQL Servere Teradata): 4-256 durante la scrittura in una cartella e 4 durante la scrittura in un singolo file. Si noti che la partizione dati di origine può usare fino a 4 unità di distribuzione. - Altri scenari: 4 |
- Copia da REST o HTTP: 1 - Altro scenario: 4 |
È possibile visualizzare le DIU usate per ogni esecuzione di copia nella visualizzazione di monitoraggio dell'attività di copia o nell'output dell'attività. Per altre informazioni, vedere Monitoraggio dell'attività Copy. Per ignorare l'impostazione predefinita, è possibile specificare un valore per la proprietà dataIntegrationUnits procedendo come segue. Il numero effettivo di unità di integrazione dati usate dall'operazione di copia in fase di esecuzione è minore o uguale al valore configurato, a seconda del modello di dati.
L'addebito sarà pari a numero di unità di distribuzione usate * durata copia * prezzo unitario/DIU-ora. Vedere i prezzi correnti qui. Per ogni tipo di sottoscrizione possono essere applicati valute locali e sconti separati.
Esempio:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"dataIntegrationUnits": 128
}
}
]
Scalabilità del runtime di integrazione self-hosted
Se si vuole ottenere una velocità effettiva più elevata, è possibile aumentare le prestazioni del runtime di integrazione self-hosted:
- Se la CPU e la memoria disponibili nel nodo del runtime di integrazione self-hosted non vengono usate completamente, ma l'esecuzione di processi simultanei raggiunge il limite, è necessario aumentare il numero di processi simultanei che possono essere eseguiti in un nodo. Per istruzioni vedere qui.
- Se invece l'utilizzo della CPU è elevato nel nodo del runtime di integrazione self-hosted o la memoria disponibile è insufficiente, è possibile aggiungere un nuovo nodo per distribuire il carico tra più nodi. Per istruzioni vedere qui.
Si noti che negli scenari seguenti l'esecuzione di un'attività Copy singola può sfruttare più nodi del runtime di integrazione self-hosted:
- Copiare i dati dagli archivi basati su file, a seconda del numero e delle dimensioni dei file.
- Copiare dati dall'archivio dati abilitato per l'opzione di partizione (inclusi Database SQL di Azure, Istanza gestita di SQL di Azure, Azure Synapse Analytics, Oracle, Netezza, SAP HANA, SAP Open Hub, Tabella SAP, SQL Server e Teradata), a seconda del numero di partizioni di dati.
Copia parallela
È possibile impostare la copia parallela (proprietà parallelCopies nella definizione JSON dell'attività Copy o impostazione Degree of parallelism nella scheda Impostazioni delle proprietà dell'attività Copy nell'interfaccia utente) per indicare al parallelismo che si vuole usare l'attività di copia. Questa proprietà può essere considerata come il numero massimo di thread all'interno dell'attività Copy che possono leggere dall'origine o scrivere negli archivi dati sink in parallelo.
La copia parallela è ortogonale per unità di integrazione dati o nodi del runtime di integrazione self-hosted. Viene conteggiato in tutti i nodi DIU o runtime di integrazione self-hosted.
Per ogni esecuzione dell'attività Copy, per impostazione predefinita il servizio applica dinamicamente l'impostazione di copia parallela ottimale in base alla coppia di sink di origine e al modello di dati.
Suggerimento
Il comportamento predefinito della copia parallela offre in genere la velocità effettiva migliore, determinata automaticamente dal servizio in base alla coppia sink di origine, al modello di dati e al numero di unità di distribuzione o al numero di CPU/memoria/nodo del runtime di integrazione self-hosted. Fare riferimento a Risolvere i problemi di prestazioni dell'attività di copia su quando ottimizzare la copia parallela.
La tabella seguente elenca il comportamento di copia parallela:
| Scenario di copia | Comportamento della copia parallela |
|---|---|
| Tra archivi file | parallelCopies determina il parallelismo a livello di file. La suddivisione in blocchi all'interno di ogni file avviene automaticamente e in modo trasparente. È progettato per usare le dimensioni del blocco più adatte per un determinato tipo di archivio dati per caricare i dati in parallelo. Il numero effettivo di attività Copy parallele usate in fase di esecuzione non è maggiore del numero di file disponibili. Se il comportamento di copia è mergeFile nel sink di file, l'attività Copy non può usare il parallelismo a livello di file. |
| Dall'archivio file all'archivio non file | - Quando si copiano dati nel database SQL di Azure o in Azure Cosmos DB, la copia parallela predefinita dipende anche dal livello sink (numero di DTU/UR). - Quando si copiano dati in tabella di Azure, la copia parallela predefinita è 4. |
| Dall'archivio non file all'archivio file | - Quando si copiano dati da un archivio dati abilitato per l'opzione di partizione (inclusi database SQL di Azure, Istanza gestita di SQL di Azure, Azure Synapse Analytics, Oracle, Amazon RDS per Oracle, Netezza, SAP HANA, SAP Open Hub, Tabella SAP, SQL Server, Amazon RDS per SQL Server e Teradata), la copia parallela predefinita è 4. Il numero effettivo di attività Copy parallele usate in fase di esecuzione non è maggiore del numero di partizioni dati disponibili. Quando si usa il runtime di integrazione self-hosted e si copia in BLOB di Azure/ADLS Gen2, si noti che la copia parallela massima effettiva è 4 o 5 per nodo del runtime di integrazione. - Per altri scenari, la copia parallela non ha effetto. Anche se viene specificato, il parallelismo non viene applicato. |
| Tra archivi non di file | - Quando si copiano dati nel database SQL di Azure o in Azure Cosmos DB, la copia parallela predefinita dipende anche dal livello sink (numero di DTU/UR). - Quando si copiano dati da un archivio dati abilitato per l'opzione di partizione (inclusi database SQL di Azure, Istanza gestita di SQL di Azure, Azure Synapse Analytics, Oracle, Amazon RDS per Oracle, Netezza, SAP HANA, SAP Open Hub, Tabella SAP, SQL Server, Amazon RDS per SQL Server e Teradata), la copia parallela predefinita è 4. - Quando si copiano dati in tabella di Azure, la copia parallela predefinita è 4. |
Per controllare il carico sui computer che ospitano gli archivi dati o per ottimizzare le prestazioni di copia, è possibile ignorare il valore predefinito e specificare un valore per la proprietà parallelCopies. Il valore deve essere un numero intero maggiore o uguale a 1. Per garantire prestazioni ottimali in fase di esecuzione, l'attività Copy usa un valore minore o uguale al valore configurato.
Quando si specifica un valore per la proprietà parallelCopies, prendere in considerazione l'aumento del carico negli archivi dati di origine e sink. Prendere in considerazione anche l'aumento del carico al runtime di integrazione self-hosted se l'attività Copy lo usa. Questo aumento del carico avviene soprattutto quando ci sono più attività o esecuzioni simultanee delle stesse attività che vengono eseguite con lo stesso archivio dati. Se si nota che l'archivio dati o il runtime di integrazione self-hosted è sovraccarico, ridurre il valore parallelCopies per alleviarlo.
Esempio:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"parallelCopies": 32
}
}
]
copia di staging
Quando si copiano dati da un archivio dati di origine a un archivio dati sink, è possibile scegliere di usare un archivio BLOB di Azure o Azure Data Lake Storage Gen2 come archivio di gestione temporanea. La funzionalità di staging è particolarmente utile nei casi seguenti:
- Si vogliono inserire dati da vari archivi dati in Azure Synapse Analytics tramite PolyBase, copiare dati da/a Snowflake o inserire dati da Amazon Redshift/HDFS con prestazioni elevate. Per altre informazioni, vedere:
- Non si vuole aprire porte diverse dalla porta 80 e dalla porta 443 nel firewall, a causa dei criteri IT aziendali. Ad esempio, quando si copiano dati da un archivio dati locale a un database SQL di Azure o Azure Synapse Analytics, è necessario attivare le comunicazioni TCP in uscita sulla porta 1433 per Windows Firewall e per il firewall aziendale. In questo scenario, la copia a fasi può sfruttare il runtime di integrazione self-hosted per copiare prima i dati in un archivio di gestione temporanea tramite HTTP o HTTPS sulla porta 443, quindi caricare i dati dalla gestione temporanea nel database SQL o in Azure Synapse Analytics. In questo flusso non è necessario abilitare la porta 1433.
- A volte occorre tempo per eseguire uno spostamento dati ibrido, ovvero la copia da un archivio dati locale a un archivio dati cloud, su una connessione di rete lenta. Per migliorare le prestazioni, è possibile usare la copia di gestione temporanea comprimere i dati in locale in modo che sia necessario meno tempo per spostare i dati nell'archivio dati di staging nel cloud. È quindi possibile decomprimere i dati nell'archivio di staging prima di caricarli nell'archivio dati di destinazione.
Come funziona la copia di staging
Quando si attiva la funzionalità di staging, i dati vengono prima copiati dall'archivio dati di origine nell'archivio di gestione temporanea (con il proprio archivio BLOB di Azure o Data Lake Storage Gen2). Successivamente, vengono copiati dalla gestione temporanea nell'archivio dati sink. L'attività Copy gestisce automaticamente il flusso a due fasi e pulisce anche i dati temporanei dall'archiviazione di gestione temporanea dopo il completamento dello spostamento dei dati.

È necessario concedere l'autorizzazione di eliminazione ad Azure Data Factory nell'archiviazione di gestione temporanea, in modo che i dati temporanei possano essere puliti dopo l'esecuzione dell'attività Copy.
Quando si attiva lo spostamento dei dati usando un archivio di staging, è possibile specificare se i dati devono essere compressi prima dello spostamento dall'archivio dati di origine all'archivio di gestione temporanea e poi decompressi prima dello spostamento dall'archivio dati provvisorio o di staging all'archivio dati sink.
Attualmente, non è possibile copiare dati tra due archivi dati connessi tramite runtime di integrazione self-hosted diversi, con o senza copia di gestione temporanea. Per questo scenario, è possibile configurare due attività di copia concatenate in modo esplicito per la copia dall'origine alla gestione temporanea e quindi dalla gestione temporanea al sink.
Impostazione
Configurare l'impostazione enableStaging nell'attività Copy per specificare se i dati devono essere inseriti in un archivio di gestione temporanea prima del caricamento in un archivio dati di destinazione. Se si imposta enableStaging su TRUE, specificare le proprietà aggiuntive elencate nella tabella seguente.
| Proprietà | Descrizione | Default value | Richiesto |
|---|---|---|---|
| enableStaging | Specificare se si vuole copiare i dati tramite un archivio di staging provvisorio. | Falso | No |
| linkedServiceName | Specificare il nome di un'archiviazione BLOB di Azure o servizio collegato Azure Data Lake Storage Gen2, che fa riferimento all'istanza di Archiviazione usata come archivio di gestione temporanea. | N/D | Sì, quando enableStaging è impostato su TRUE |
| path | Specificare il percorso in cui si desidera mantenere i dati di gestione temporanea. Se non si specifica un percorso, il servizio crea un contenitore in cui archiviare i dati temporanei. | N/D | No (Sì quando storageIntegration è specificato nel connettore Snowflake) |
| enableCompression | Specifica se è necessario comprimere i dati prima di copiarli nella destinazione. Questa impostazione ridurre il volume dei dati da trasferire. | Falso | No |
Nota
Se si usa la copia di staging con compressione abilitata, l'entità servizio o l'autenticazione MSI per lo staging del servizio collegato BLOB non è supportato.
Di seguito è riportata una definizione di esempio di attività Copy con le proprietà descritte nella tabella precedente:
"activities":[
{
"name": "CopyActivityWithStaging",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "OracleSource",
},
"sink": {
"type": "SqlDWSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "stagingcontainer/path"
}
}
}
]
Impatto della copia di staging sulla fatturazione
I costi addebitati si basano su due passaggi: durata della copia e tipo di copia.
- Quando si usa la funzionalità di staging durante una copia nel cloud, ovvero la copia di dati da un archivio dati cloud a un altro archivio dati cloud con l'ottimizzazione del runtime di integrazione di Azure, il costo addebitato sarà [somma della durata della copia per i passaggi 1 e 2] x [prezzo unitario della copia nel cloud].
- Quando si usa la funzionalità di staging durante una copia ibrida, ovvero la copia di dati da un archivio dati locale a un archivio dati cloud e solo uno beneficia dell'ottimizzazione del runtime di integrazione di Azure, il costo addebitato sarà [durata della copia ibrida] x [prezzo unitario della copia ibrida] + [durata della copia nel cloud] x [prezzo unitario della copia nel cloud].
Contenuto correlato
Vedere gli altri articoli relativi all'attività di copia:
- Panoramica dell'attività di copia
- Guida a prestazioni e scalabilità dell'attività di copia
- Risolvere i problemi di prestazioni dell'attività Copy
- Usare Azure Data Factory per eseguire la migrazione dei dati dal data lake o dal data warehouse ad Azure
- Eseguire la migrazione dei dati da un archivio dati Amazon S3 ad Archiviazione di Azure