Usare Azure Data Factory per eseguire la migrazione dei dati da un server Netezza locale ad Azure
SI APPLICA A:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Azure Data Factory offre un meccanismo efficiente, affidabile e conveniente per eseguire la migrazione dei dati su larga scala da un server Netezza locale all'account di archiviazione di Azure o al database di Azure Synapse Analytics.
In questo articolo vengono fornite le seguenti informazioni per i data engineer e gli sviluppatori:
- Prestazione
- Resilienza della copia
- Sicurezza di rete
- Architettura di alto livello della soluzione
- Procedure consigliate dell'implementazione
Prestazioni
Azure Data Factory offre un'architettura serverless che consente il parallelismo a vari livelli. Se si è uno sviluppatore, questo significa che è possibile creare pipeline per usare completamente la larghezza di banda di rete e di database per ottimizzare la velocità effettiva di spostamento dei dati per l'ambiente.

Il diagramma precedente può essere interpretato come segue:
Una singola attività Copy può sfruttare risorse di calcolo scalabili. Quando si usa Azure Integration Runtime, è possibile specificare fino a 256 DIU per ogni attività di copia in modo serverless. Con un runtime di integrazione self-hosted (runtime di integrazione self-hosted), è possibile aumentare manualmente il numero di istanze del computer o aumentare il numero di istanze in più computer (fino a quattro nodi) e una singola attività di copia distribuisce la partizione in tutti i nodi.
Una singola attività di copia legge e scrive nell'archivio dati usando più thread.
Il flusso di controllo di Azure Data Factory può avviare più attività di copia in parallelo. Ad esempio, può avviarli usando un ciclo For Each.
Per altre informazioni, vedere la Guida alle prestazioni e alla scalabilità dell'attività Copy.
Resilienza
All'interno di una singola esecuzione dell'attività di copia, Azure Data Factory ha un meccanismo di ripetizione dei tentativi predefinito, che consente di gestire un determinato livello di errori temporanei negli archivi dati o nella rete sottostante.
Con l'attività di copia di Azure Data Factory, quando si copiano dati tra archivi dati di origine e sink, è possibile gestire le righe incompatibili in due modi. È possibile interrompere e interrompere l'attività di copia o continuare a copiare il resto dei dati ignorando le righe di dati incompatibili. Per informazioni sulla causa dell'errore, è anche possibile registrare le righe incompatibili in Archiviazione BLOB di Azure o Azure Data Lake Store, correggere i dati nell'origine dati e ripetere l'attività di copia.
Sicurezza di rete
Per impostazione predefinita, Azure Data Factory trasferisce i dati dal server Netezza locale a un account di archiviazione di Azure o a un database di Azure Synapse Analytics usando una connessione crittografata tramite PROTOCOLLO HTTPS (Hypertext Transfer Protocol Secure). Il protocollo HTTPS offre la crittografia dei dati in transito e impedisce l'intercettazione e gli attacchi man-in-the-middle.
In alternativa, se non si vuole trasferire i dati tramite La rete Internet pubblica, è possibile ottenere una maggiore sicurezza trasferendo i dati tramite un collegamento di peering privato tramite Azure ExpressRoute.
La sezione successiva illustra come ottenere una maggiore sicurezza.
Architettura della soluzione
Questa sezione illustra due modi per eseguire la migrazione dei dati.
Eseguire la migrazione dei dati tramite Internet pubblico

Il diagramma precedente può essere interpretato come segue:
In questa architettura i dati vengono trasferiti in modo sicuro usando HTTPS tramite la rete Internet pubblica.
Per ottenere questa architettura, è necessario installare il runtime di integrazione di Azure Data Factory (self-hosted) in un computer Windows protetto da un firewall aziendale. Assicurarsi che questo runtime di integrazione possa accedere direttamente al server Netezza. Per usare completamente la larghezza di banda della rete e degli archivi dati per copiare i dati, è possibile aumentare manualmente le prestazioni del computer o aumentare il numero di istanze in più computer.
Usando questa architettura, è possibile eseguire la migrazione sia dei dati di snapshot iniziali che dei dati differenziali.
Eseguire la migrazione dei dati in una rete privata
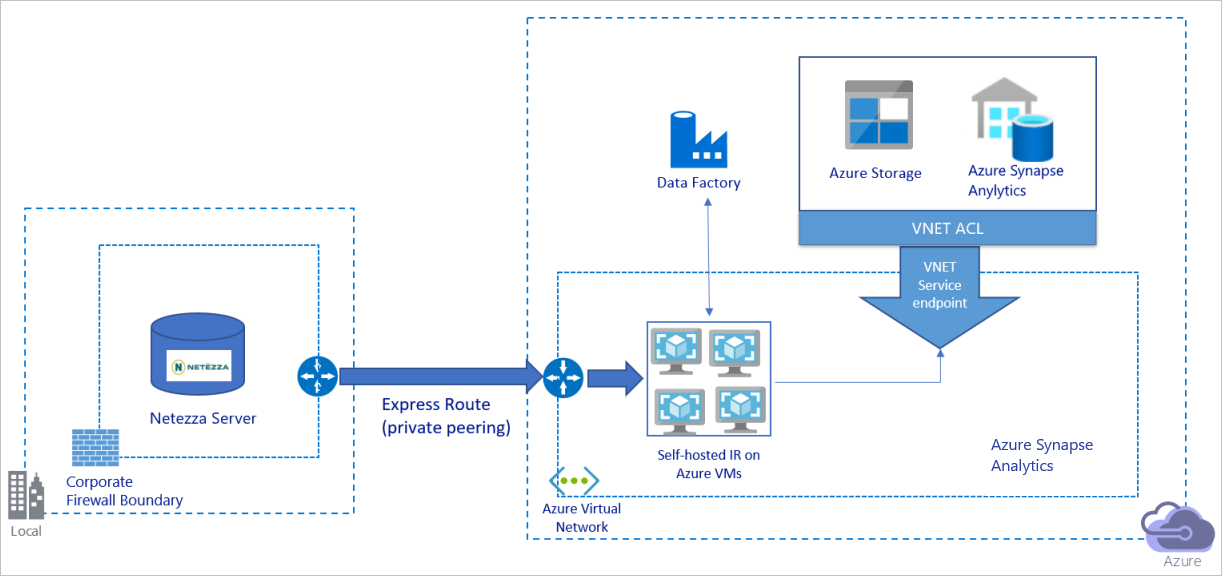
Il diagramma precedente può essere interpretato come segue:
In questa architettura si esegue la migrazione dei dati tramite un collegamento di peering privato tramite Azure ExpressRoute e i dati non attraversano mai la rete Internet pubblica.
Per ottenere questa architettura, è necessario installare il runtime di integrazione di Azure Data Factory (self-hosted) in una macchina virtuale Windows all'interno della rete virtuale di Azure. Per usare completamente la larghezza di banda della rete e degli archivi dati per copiare i dati, è possibile aumentare manualmente la macchina virtuale o aumentare il numero di istanze in più macchine virtuali.
Usando questa architettura, è possibile eseguire la migrazione sia dei dati di snapshot iniziali che dei dati differenziali.
Procedure consigliate per l'implementazione
Gestire l'autenticazione e le credenziali
Per eseguire l'autenticazione in Netezza, è possibile usare l'autenticazione ODBC tramite stringa di connessione.
Per eseguire l'autenticazione in Archiviazione BLOB di Azure:
È consigliabile usare le identità gestite per le risorse di Azure. Basato su un'identità di Azure Data Factory gestita automaticamente in Microsoft Entra ID, le identità gestite consentono di configurare le pipeline senza dover fornire le credenziali nella definizione del servizio collegato.
In alternativa, è possibile eseguire l'autenticazione nell'archivio BLOB di Azure usando un'entità servizio, una firma di accesso condiviso o una chiave dell'account di archiviazione.
Per eseguire l'autenticazione in Azure Data Lake Storage Gen2:
È consigliabile usare le identità gestite per le risorse di Azure.
È anche possibile usare un'entità servizio o una chiave dell'account di archiviazione.
Per eseguire l'autenticazione ad Azure Synapse Analytics:
È consigliabile usare le identità gestite per le risorse di Azure.
È anche possibile usare l'entità servizio o l'autenticazione SQL.
Quando non si usano identità gestite per le risorse di Azure, è consigliabile archiviare le credenziali in Azure Key Vault per semplificare la gestione centralizzata e la rotazione delle chiavi senza dover modificare i servizi collegati di Azure Data Factory. Questa è anche una delle procedure consigliate per CI/CD.
Eseguire la migrazione dei dati dello snapshot iniziale
Per le tabelle di piccole dimensioni( ovvero le tabelle con un volume inferiore a 100 GB o che è possibile eseguire la migrazione ad Azure entro due ore), è possibile rendere ogni processo di copia caricare i dati per ogni tabella. Per una maggiore velocità effettiva, è possibile eseguire più processi di copia di Azure Data Factory per caricare tabelle separate contemporaneamente.
All'interno di ogni processo di copia, per eseguire query parallele e copiare i dati in base alle partizioni, è anche possibile raggiungere un certo livello di parallelismo usando l'impostazione della parallelCopies proprietà con una delle opzioni di partizione dati seguenti:
Per ottenere una maggiore efficienza, è consigliabile iniziare da una sezione di dati. Assicurarsi che il valore nell'impostazione
parallelCopiessia minore del numero totale di partizioni di sezioni di dati nella tabella nel server Netezza.Se il volume di ogni partizione della sezione di dati è ancora grande (ad esempio, 10 GB o superiore), è consigliabile passare a una partizione di intervallo dinamico. Questa opzione offre maggiore flessibilità per definire il numero di partizioni e il volume di ogni partizione per colonna di partizione, limite superiore e limite inferiore.
Per le tabelle di dimensioni maggiori( ovvero le tabelle con un volume di 100 GB o versione successiva o successiva o che non possono essere migrate in Azure entro due ore), è consigliabile partizionare i dati in base alla query personalizzata e quindi creare una copia di ogni processo di copia una partizione alla volta. Per una migliore velocità effettiva, è possibile eseguire più processi di copia di Azure Data Factory contemporaneamente. Per ogni destinazione del processo di copia del caricamento di una partizione tramite query personalizzata, è possibile aumentare la velocità effettiva abilitando il parallelismo tramite sezione di dati o intervallo dinamico.
Se un processo di copia ha esito negativo a causa di un problema temporaneo di rete o archivio dati, è possibile eseguire di nuovo il processo di copia non riuscito per ricaricare tale partizione specifica dalla tabella. Altri processi di copia che caricano altre partizioni non sono interessati.
Quando si caricano dati in un database di Azure Synapse Analytics, è consigliabile abilitare PolyBase all'interno del processo di copia con l'archiviazione BLOB di Azure come staging.
Eseguire la migrazione dei dati differenziali
Per identificare le righe nuove o aggiornate dalla tabella, usare una colonna timestamp o una chiave di incremento all'interno dello schema. È quindi possibile archiviare il valore più recente come limite massimo in una tabella esterna e quindi usarlo per filtrare i dati differenziali al successivo caricamento dei dati.
Ogni tabella può usare una colonna filigrana diversa per identificare le righe nuove o aggiornate. È consigliabile creare una tabella di controllo esterna. Nella tabella ogni riga rappresenta una tabella nel server Netezza con il nome di colonna limite specifico e il valore limite elevato.
Configurare un runtime di integrazione self-hosted
Se si esegue la migrazione dei dati dal server Netezza ad Azure, indipendentemente dal fatto che il server si trovi in locale dietro il firewall aziendale o all'interno di un ambiente di rete virtuale, è necessario installare un runtime di integrazione self-hosted in un computer Windows o in una macchina virtuale, ovvero il motore usato per spostare i dati. Durante l'installazione del runtime di integrazione self-hosted, è consigliabile adottare l'approccio seguente:
Per ogni computer o macchina virtuale Windows, iniziare con una configurazione di 32 vCPU e 128 GB di memoria. È possibile mantenere il monitoraggio dell'utilizzo della CPU e della memoria del computer di integrazione durante la migrazione dei dati per verificare se è necessario aumentare ulteriormente il numero di istanze del computer per ottenere prestazioni migliori o ridurre le prestazioni del computer per risparmiare sui costi.
È anche possibile aumentare il numero di istanze associando fino a quattro nodi a un singolo runtime di integrazione self-hosted. Un singolo processo di copia in esecuzione su un runtime di integrazione self-hosted applica automaticamente tutti i nodi della macchina virtuale per copiare i dati in parallelo. Per la disponibilità elevata, iniziare con quattro nodi della macchina virtuale per evitare un singolo punto di errore durante la migrazione dei dati.
Limitare le partizioni
Come procedura consigliata, eseguire un modello di verifica delle prestazioni con un set di dati di esempio rappresentativo, in modo da poter determinare una dimensione di partizione appropriata per ogni attività di copia. È consigliabile caricare ogni partizione in Azure entro due ore.
Per copiare una tabella, iniziare con una singola attività di copia con un singolo computer del runtime di integrazione self-hosted. Aumentare gradualmente l'impostazione parallelCopies in base al numero di partizioni di sezioni di dati nella tabella. Verificare se l'intera tabella può essere caricata in Azure entro due ore, in base alla velocità effettiva risultante dal processo di copia.
Se non può essere caricato in Azure entro due ore e la capacità del nodo del runtime di integrazione self-hosted e l'archivio dati non vengono usati completamente, aumentare gradualmente il numero di attività di copia simultanee fino a raggiungere il limite della rete o il limite di larghezza di banda degli archivi dati.
Mantenere il monitoraggio dell'utilizzo della CPU e della memoria nel computer del runtime di integrazione self-hosted ed essere pronti per aumentare le prestazioni del computer o aumentare il numero di istanze in più computer quando si noterà che la CPU e la memoria vengono usate completamente.
Quando si verificano errori di limitazione, come segnalato dall'attività di copia di Azure Data Factory, ridurre la concorrenza o parallelCopies l'impostazione in Azure Data Factory oppure valutare la possibilità di aumentare i limiti di larghezza di banda o operazioni di I/O al secondo (IOPS) della rete e degli archivi dati.
Stimare i prezzi
Si consideri la pipeline seguente, costruita per eseguire la migrazione dei dati dal server Netezza locale a un database di Azure Synapse Analytics:
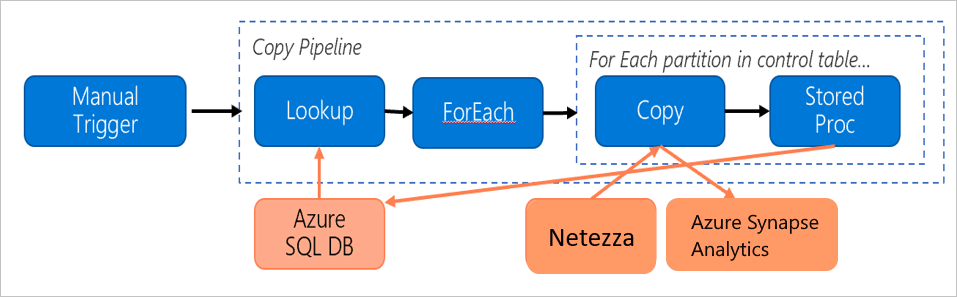
Si supponga che le istruzioni seguenti siano vere:
Il volume totale di dati è di 50 terabyte (TB).
Si sta eseguendo la migrazione dei dati usando l'architettura first-solution (il server Netezza è locale, dietro il firewall).
Il volume da 50 TB è suddiviso in 500 partizioni e ogni attività di copia sposta una partizione.
Ogni attività di copia è configurata con un runtime di integrazione self-hosted su quattro computer e ottiene una velocità effettiva di 20 megabyte al secondo (MBps). L'attività
parallelCopiesdi copia è impostata su 4 e ogni thread per caricare i dati dalla tabella ottiene una velocità effettiva di 5 MBps.La concorrenza ForEach è impostata su 3 e la velocità effettiva aggregata è di 60 MBps.
In totale, sono necessarie 243 ore per completare la migrazione.
In base ai presupposti precedenti, ecco il prezzo stimato:
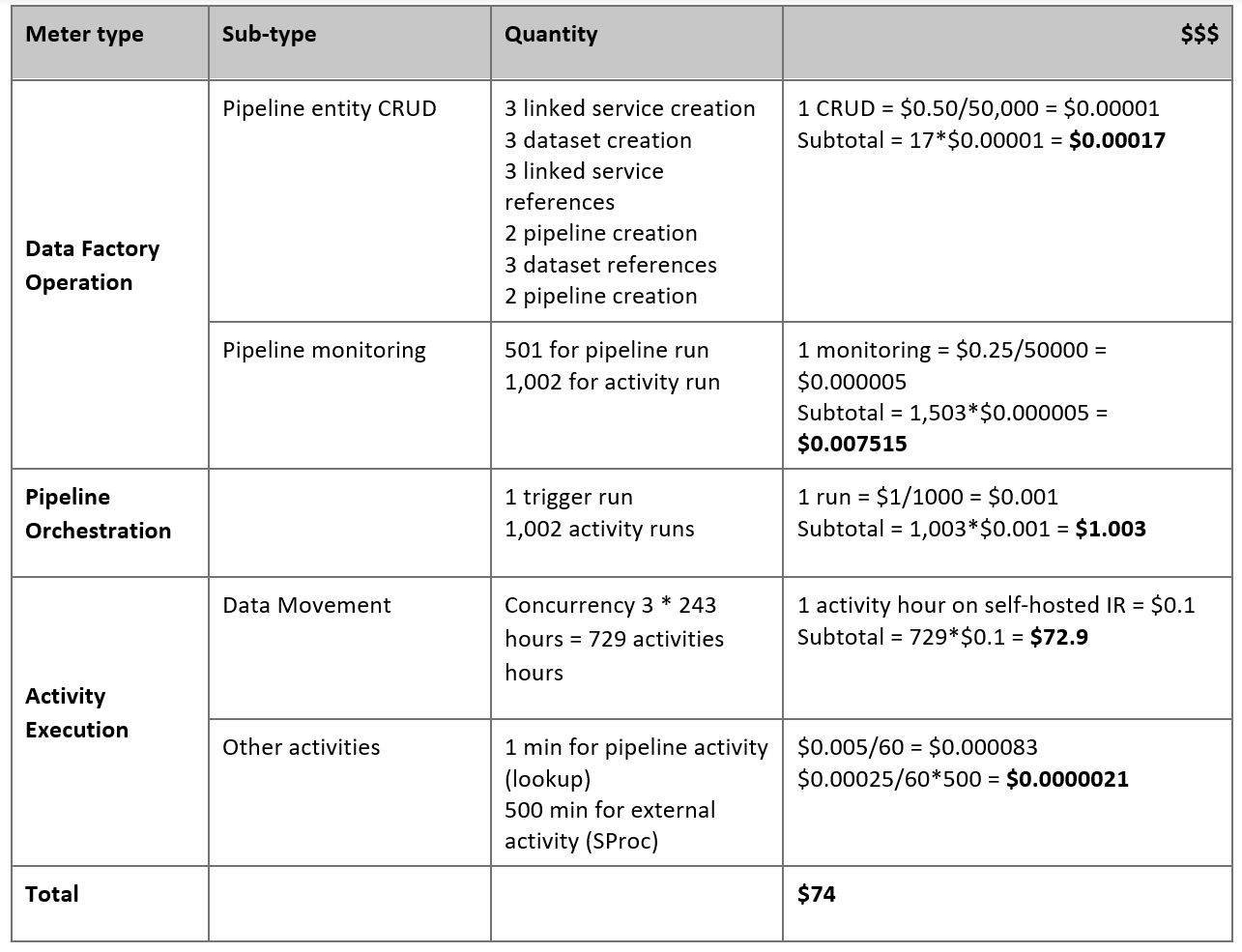
Nota
I prezzi indicati nella tabella precedente sono ipotetici. I prezzi effettivi variano in base alla velocità effettiva dell'ambiente. Il prezzo per il computer Windows (con il runtime di integrazione self-hosted installato) non è incluso.
Altri riferimenti
Per altre informazioni, vedere gli articoli e le guide seguenti:
- Connettore Netezza
- Connettore ODBC
- Connettore di Archiviazione BLOB di Azure
- Connettore di Azure Data Lake Storage Gen2
- Connettore Azure Synapse Analytics
- Guida alle prestazioni delle attività di copia e all'ottimizzazione
- Creare e configurare un runtime di integrazione self-hosted
- Disponibilità elevata e scalabilità del runtime di integrazione self-hosted
- Considerazioni relative alla sicurezza per lo spostamento dei dati
- Archiviare le credenziali in Azure Key Vault
- Copiare i dati in modo incrementale da una tabella
- Copiare i dati in modo incrementale da più tabelle
- Pagina dei prezzi di Azure Data Factory