Esercitazione: Copiare dati da un database di SQL Server ad Archiviazione BLOB di Azure
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
In questa esercitazione si usa Azure PowerShell per creare una pipeline di data factory che copia i dati da un database di SQL Server all'archiviazione BLOB di Azure. Si crea e si usa un runtime di integrazione self-hosted, che sposta i dati tra gli archivi dati locali e cloud.
Nota
Questo articolo non offre una presentazione dettagliata del servizio Data Factory. Per altre informazioni, vedere l'introduzione ad Azure Data Factory.
In questa esercitazione si segue questa procedura:
- Creare una data factory.
- Creare un runtime di integrazione self-hosted.
- Creare servizi collegati per SQL Server e Archiviazione di Azure.
- Creare set di dati per SQL Server e BLOB di Azure.
- Creare una pipeline con attività di copia per trasferire i dati.
- Avviare un'esecuzione della pipeline.
- Monitorare l'esecuzione della pipeline.
Prerequisiti
Sottoscrizione di Azure
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Ruoli di Azure
Per creare istanze di Data Factory, all'account utente usato per accedere ad Azure deve essere assegnato un ruolo collaboratore o proprietario oppure l'account utente deve essere un amministratore della sottoscrizione di Azure.
Per visualizzare le autorizzazioni disponibili nella sottoscrizione, passare al portale di Azure, selezionare il nome utente nell'angolo in alto a destra e quindi Autorizzazioni. Se si accede a più sottoscrizioni, selezionare quella appropriata. Per istruzioni di esempio sull'aggiunta di un utente a un ruolo, vedere l'articolo Assegnare ruoli di Azure usando il portale di Azure.
SQL Server 2014, 2016 e 2017
In questa esercitazione si usa un database di SQL Server come archivio dati di origine. La pipeline nella data factory creata in questa esercitazione copia i dati da questo database di SQL Server (origine) all'archiviazione BLOB di Azure (sink). Si crea quindi una tabella denominata emp nel database di SQL Server e inserire una coppia di voci di esempio nella tabella.
Avvia SQL Server Management Studio. Se non è già installato nel computer, passare a Scaricare SQL Server Management Studio.
Connettersi all'istanza di SQL Server usando le credenziali.
Creare un database di esempio. Nella visualizzazione struttura ad albero fare clic con il pulsante destro del mouse su Database e scegliere Nuovo database.
Nella finestra Nuovo database immettere un nome per il database e fare clic su OK.
Per creare la tabella emp e inserirvi alcuni dati di esempio, eseguire questo script di query sul database. Nella visualizzazione struttura ad albero fare clic con il pulsante destro del mouse sul database creato e scegliere Nuova query.
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO INSERT INTO emp (FirstName, LastName) VALUES ('John', 'Doe') INSERT INTO emp (FirstName, LastName) VALUES ('Jane', 'Doe') GO
account di archiviazione di Azure
In questa esercitazione si usa un account di archiviazione di Azure per utilizzo generico (specificamente, un archivio BLOB) come archivio dati di destinazione/sink. Se non si ha un account di archiviazione di Azure per utilizzo generico, vedere Creare un account di archiviazione. La pipeline nella data factory creata in questa esercitazione copia i dati dal database di SQL Server (origine) all'archiviazione BLOB di Azure (sink).
Recuperare il nome e la chiave dell'account di archiviazione
In questa esercitazione si usano il nome e la chiave dell'account di archiviazione di Azure. Recuperare il nome e la chiave dell'account di archiviazione nel modo seguente:
Accedere al portale di Azure con nome utente e password.
Nel riquadro a sinistra selezionare Altri servizi, usare la parola chiave Archiviazione come filtro e selezionare Account di archiviazione.
Nell'elenco degli account di archiviazione filtrare, se necessario, e quindi selezionare il proprio account di archiviazione.
Nella finestra Account di archiviazione selezionare Chiavi di accesso.
Nelle caselle Nome account di archiviazione e key1 copiare i valori e incollarli nel Blocco note o in un altro editor per usarli in seguito nell'esercitazione.
Creare il contenitore adftutorial
In questa sezione si crea un contenitore BLOB denominato adftutorial nell'archivio BLOB di Azure.
Nella finestra Account di archiviazione passare a Panoramica e quindi selezionare BLOB.

Nella finestra Servizio BLOB selezionare Contenitore.
Nella finestra di dialogo Nuovo contenitore immettere adftutorial nella casella Nome e fare clic su OK.
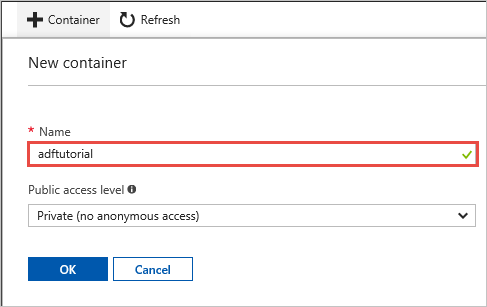
Selezionare adftutorial nell'elenco di contenitori.
Tenere aperta la finestra Contenitore per adftutorial perché verrà usata per verificare l'output alla fine di questa esercitazione. Data Factory crea automaticamente la cartella di output in questo contenitore, quindi non è necessario crearne uno.
Windows PowerShell
Installare Azure PowerShell
Nota
È consigliabile usare il modulo Azure Az PowerShell per interagire con Azure. Per iniziare, vedere Installare Azure PowerShell. Per informazioni su come eseguire la migrazione al modulo AZ PowerShell, vedere Eseguire la migrazione di Azure PowerShell da AzureRM ad Az.
Installare la versione più recente di Azure PowerShell, se non è già presente nel computer. Per istruzioni dettagliate, vedere Come installare e configurare Azure PowerShell.
Accedere a PowerShell
Avviare PowerShell nel computer in uso e tenerlo aperto fino al completamento di questa esercitazione introduttiva. Se si chiude e si riapre, sarà necessario eseguire di nuovo questi comandi.
Eseguire questo comando e immettere il nome utente e la password di Azure usati per accedere al portale di Azure:
Connect-AzAccountSe si hanno più sottoscrizioni di Azure, eseguire questo comando per selezionare la sottoscrizione che si vuole usare. Sostituire SubscriptionId con l'ID della sottoscrizione di Azure:
Select-AzSubscription -SubscriptionId "<SubscriptionId>"
Creare una data factory
Definire una variabile per il nome del gruppo di risorse usato in seguito nei comandi di PowerShell. Copiare il comando seguente in PowerShell, specificare un nome per il gruppo di risorse di Azure tra virgolette doppie (ad esempio
"adfrg") e quindi eseguire il comando.$resourceGroupName = "ADFTutorialResourceGroup"Per creare il gruppo di risorse di Azure, eseguire questo comando:
New-AzResourceGroup $resourceGroupName -location 'East US'Se il gruppo di risorse esiste già, potrebbe essere preferibile non sovrascriverlo. Assegnare un valore diverso alla variabile
$resourceGroupNameed eseguire di nuovo il comando.Definire una variabile per il nome della data factory utilizzabile in seguito nei comandi di PowerShell. Il nome deve iniziare con una lettera o un numero e può contenere solo lettere, numeri e il carattere trattino (-).
Importante
Aggiornare il nome della data factory in modo che sia univoco a livello globale, ad esempio ADFTutorialFactorySP1127.
$dataFactoryName = "ADFTutorialFactory"Definire una variabile per la località della data factory:
$location = "East US"Per creare la data factory, eseguire il cmdlet
Set-AzDataFactoryV2seguente:Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Nota
- Il nome della data factory deve essere univoco a livello globale. Se viene visualizzato l'errore seguente, modificare il nome e riprovare.
The specified data factory name 'ADFv2TutorialDataFactory' is already in use. Data factory names must be globally unique. - Per creare istanze di Data Factory, all'account utente usato per accedere ad Azure deve essere assegnato un ruolo collaboratore o proprietario oppure l'account deve essere un amministratore della sottoscrizione di Azure.
- Per un elenco di aree di Azure in cui Data Factory è attualmente disponibile, selezionare le aree di interesse nella pagina seguente, quindi espandere Analytics per individuare Data Factory: Prodotti disponibili in base all'area. Gli archivi dati (Archiviazione di Azure, database SQL di Azure e così via) e le risorse di calcolo (Azure HDInsight e così via) usati dalla data factory possono trovarsi in altre aree.
Creare un runtime di integrazione self-hosted
In questa sezione si crea un runtime di integrazione self-hosted e lo si associa a un computer locale con il database di SQL Server. Il runtime di integrazione self-hosted è il componente che copia i dati dal database SQL Server presente nel computer all'archivio BLOB di Azure.
Creare una variabile per il nome del runtime di integrazione. Usare un nome univoco e annotarlo perché sarà usato più avanti in questa esercitazione.
$integrationRuntimeName = "ADFTutorialIR"Creare un runtime di integrazione self-hosted.
Set-AzDataFactoryV2IntegrationRuntime -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $integrationRuntimeName -Type SelfHosted -Description "selfhosted IR description"Di seguito è riportato l'output di esempio:
Name : ADFTutorialIR Type : SelfHosted ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Description : selfhosted IR description Id : /subscriptions/<subscription ID>/resourceGroups/<resourceGroupName>/providers/Microsoft.DataFactory/factories/<dataFactoryName>/integrationruntimes/<integrationRuntimeName>Eseguire questo comando per recuperare lo stato del runtime di integrazione creato:
Get-AzDataFactoryV2IntegrationRuntime -name $integrationRuntimeName -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -StatusDi seguito è riportato l'output di esempio:
State : NeedRegistration Version : CreateTime : 9/10/2019 3:24:09 AM AutoUpdate : On ScheduledUpdateDate : UpdateDelayOffset : LocalTimeZoneOffset : InternalChannelEncryption : Capabilities : {} ServiceUrls : {eu.frontend.clouddatahub.net} Nodes : {} Links : {} Name : <Integration Runtime name> Type : SelfHosted ResourceGroupName : <resourceGroup name> DataFactoryName : <dataFactory name> Description : selfhosted IR description Id : /subscriptions/<subscription ID>/resourceGroups/<resourceGroupName>/providers/Microsoft.DataFactory/factories/<dataFactoryName>/integrationruntimes/<integrationRuntimeName>Eseguire questo comando per recuperare le chiavi di autenticazione per la registrazione del runtime di integrazione self-hosted nel servizio Data Factory nel cloud. Copiare una delle chiavi (escluse le virgolette) per la registrazione del runtime di integrazione self-hosted che si installerà nel computer nel passaggio successivo.
Get-AzDataFactoryV2IntegrationRuntimeKey -Name $integrationRuntimeName -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName | ConvertTo-JsonDi seguito è riportato l'output di esempio:
{ "AuthKey1": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx=", "AuthKey2": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy=" }
Installare il runtime di integrazione
Scaricare Azure Data Factory Integration Runtime in un computer Windows locale, quindi eseguire l'installazione.
Nella pagina iniziale dell'installazione guidata di Microsoft Integration Runtime fare clic su Avanti.
Nella finestra Contratto di licenza con l'utente finale accettare le condizioni e fare clic su Avanti.
Nella finestra Cartella di destinazione fare clic su Avanti.
Nella pagina Pronto per l'installazione fare clic su Installa.
Nella pagina Installazione di Microsoft Integration Runtime completata fare clic su Fine.
Nella finestra Registra Runtime di integrazione (self-hosted) incollare la chiave salvata nella sezione precedente e fare clic su Registra.

Nella finestra Nuovo nodo di Runtime di integrazione (self-hosted) fare clic su Fine.

Al termine della registrazione del runtime di integrazione self-hosted viene visualizzato il messaggio seguente:
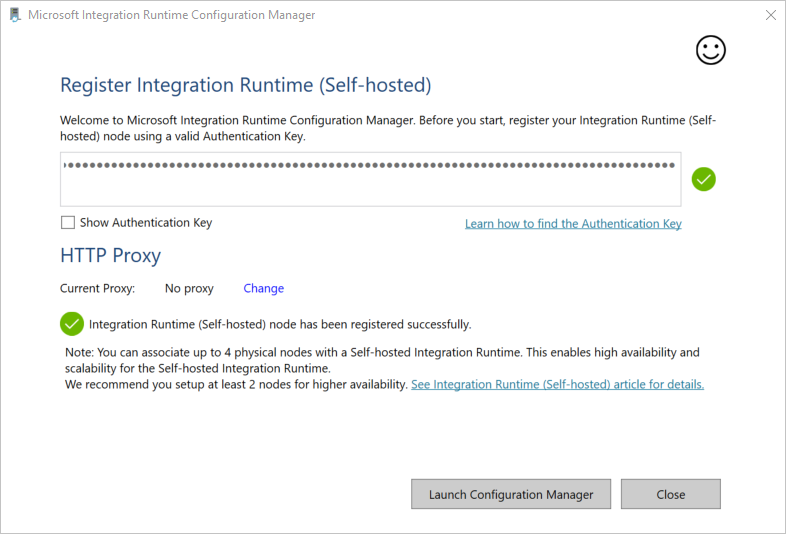
Nella finestra Registra Runtime di integrazione (self-hosted) fare clic su Avvia Configuration Manager.
Quando il nodo viene connesso al servizio cloud, viene visualizzato il messaggio seguente:
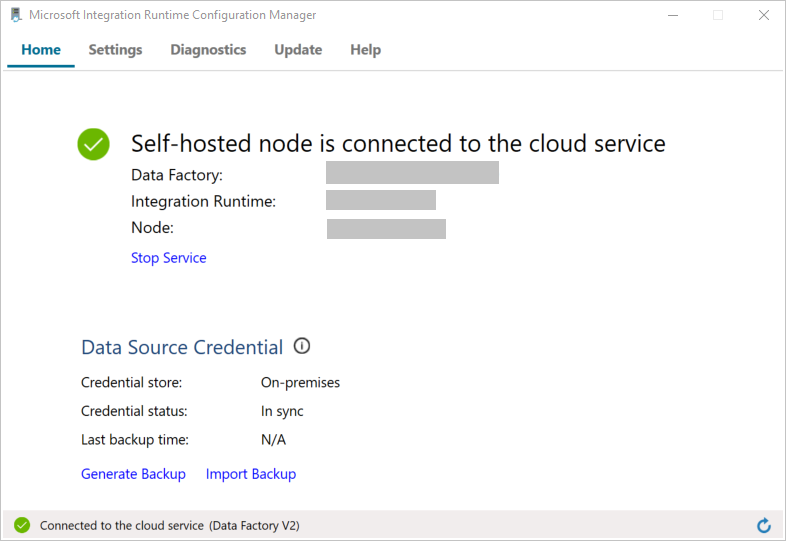
Testare la connettività al database di SQL Server nel modo seguente:
a. Nella finestra Configuration Manager passare alla scheda Diagnostica.
b. Selezionare SqlServer in Tipo di origine dati.
c. Immettere il nome del server.
d. Immettere il nome del database.
e. Selezionare la modalità di autenticazione.
f. Immettere il nome utente.
g. Immettere la password associata al nome utente.
h. Fare clic su Test per verificare che il runtime di integrazione possa connettersi a SQL Server.
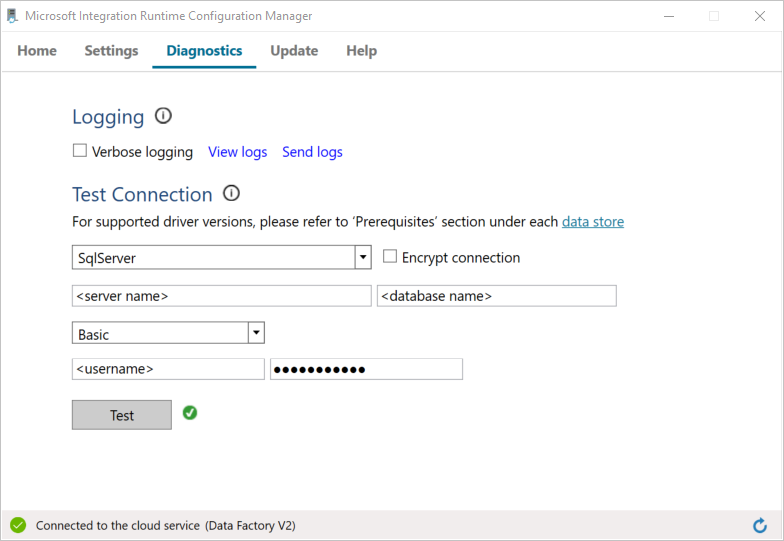
Se la connessione ha esito positivo, viene visualizzato un segno di spunta verde. In caso contrario, viene visualizzato un messaggio associato all'errore. Risolvere eventuali problemi e assicurarsi che il runtime di integrazione possa connettersi all'istanza di SQL Server.
Annotare tutti i valori precedenti per usarli più avanti in questa esercitazione.
Creare servizi collegati
Creare servizi collegati nella data factory per collegare gli archivi dati e i servizi di calcolo alla data factory. In questa esercitazione si collegano l'account di archiviazione di Azure e l'istanza di SQL Server all'archivio dati. I servizi collegati hanno le informazioni di connessione usate dal servizio Data Factory in fase di esecuzione per la connessione.
Creare un servizio collegato Archiviazione di Azure (destinazione/sink)
In questo passaggio, l'account di archiviazione di Azure viene collegato alla data factory.
Creare un file JSON denominato AzureStorageLinkedService.json nella cartella C:\ADFv2Tutorial con il codice seguente. Creare la cartella ADFv2Tutorial, se non esiste già.
Importante
Prima di salvare il file, sostituire <accountName> e <accountKey> con il nome e la chiave dell'account di archiviazione di Azure. Questi valori sono stati annotati nella sezione Prerequisiti.
{ "name": "AzureStorageLinkedService", "properties": { "annotations": [], "type": "AzureBlobStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>;EndpointSuffix=core.windows.net" } } }In PowerShell passare alla cartella C:\ADFv2Tutorial.
Set-Location 'C:\ADFv2Tutorial'Eseguire il cmdlet
Set-AzDataFactoryV2LinkedServiceseguente per creare il servizio collegato denominato AzureStorageLinkedService:Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -Name "AzureStorageLinkedService" -File ".\AzureStorageLinkedService.json"Di seguito è riportato un output di esempio:
LinkedServiceName : AzureStorageLinkedService ResourceGroupName : <resourceGroup name> DataFactoryName : <dataFactory name> Properties : Microsoft.Azure.Management.DataFactory.Models.AzureBlobStorageLinkedServiceSe viene visualizzato un errore di tipo "File non trovato", verificare che il file esista eseguendo il comando
dir. Se il nome del file ha estensione txt, ad esempio AzureStorageLinkedService.json.txt, rimuovere l'estensione ed eseguire di nuovo il comando di PowerShell.
Creare e crittografare un servizio collegato SQL Server (origine)
In questo passaggio si collega l'istanza di SQL Server alla data factory.
Creare un file JSON denominato SqlServerLinkedService.json nella cartella C:\ADFv2Tutorial usando il codice seguente:
Importante
Selezionare la sezione in base all'autenticazione usata per connettersi a SQL Server.
Uso dell'autenticazione SQL (sa):
{ "name":"SqlServerLinkedService", "type":"Microsoft.DataFactory/factories/linkedservices", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=False;data source=<serverName>;initial catalog=<databaseName>;user id=<userName>;password=<password>" }, "connectVia":{ "referenceName":"<integration runtime name> ", "type":"IntegrationRuntimeReference" } } }Con l'autenticazione di Windows:
{ "name":"SqlServerLinkedService", "type":"Microsoft.DataFactory/factories/linkedservices", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=True;data source=<serverName>;initial catalog=<databaseName>", "userName":"<username> or <domain>\\<username>", "password":{ "type":"SecureString", "value":"<password>" } }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Importante
- Selezionare la sezione in base all'autenticazione usata per connettersi all'istanza di SQL Server.
- Sostituire <il nome> del runtime di integrazione con il nome del runtime di integrazione.
- Prima di salvare il file, sostituire <servername, <databasename>>, <username> e <password> con i valori dell'istanza di SQL Server.
- Se è necessario usare una barra rovesciata (\) nell'account utente o nel nome del server, anteporre il carattere di escape (\). Ad esempio, usare mydomain\\myuser.
Per crittografare i dati sensibili (nome utente, password e così via), eseguire il cmdlet
New-AzDataFactoryV2LinkedServiceEncryptedCredential.
Con questa crittografia, le credenziali vengono crittografate con Data Protection API (DPAPI). Le credenziali crittografate vengono archiviate in locale (computer locale) nel nodo del runtime di integrazione self-hosted. Il payload di output può essere reindirizzato a un altro file JSON (in questo caso encryptedLinkedService.json) che contiene le credenziali crittografate.New-AzDataFactoryV2LinkedServiceEncryptedCredential -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -IntegrationRuntimeName $integrationRuntimeName -File ".\SQLServerLinkedService.json" > encryptedSQLServerLinkedService.jsonEseguire questo comando, che crea EncryptedSqlServerLinkedService:
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -Name "EncryptedSqlServerLinkedService" -File ".\encryptedSqlServerLinkedService.json"
Creare i set di dati
In questo passaggio vengono creati set di dati di input e di output, che rappresentano i dati di input e di output per l'operazione di copia dal database di SQL Server all'archiviazione BLOB di Azure.
Creare un set di dati per il database SQL Server di origine
In questo passaggio si definisce un set di dati che rappresenta i dati nell'istanza di database di SQL Server. Il set di dati è di tipo SqlServerTable. Fa riferimento al servizio collegato SQL Server creato nel passaggio precedente. Il servizio collegato ha le informazioni di connessione usate dal servizio Data Factory per connettersi all'istanza di SQL Server in fase di esecuzione. Questo set di dati specifica la tabella SQL nel database che contiene i dati. In questa esercitazione, la tabella emp contiene i dati di origine.
Creare un file JSON denominato SqlServerDataset.json nella cartella C:\ADFv2Tutorial con il codice seguente:
{ "name":"SqlServerDataset", "properties":{ "linkedServiceName":{ "referenceName":"EncryptedSqlServerLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"SqlServerTable", "schema":[ ], "typeProperties":{ "schema":"dbo", "table":"emp" } } }Per creare il set di dati SqlServerDataset, eseguire il cmdlet
Set-AzDataFactoryV2Dataset.Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SqlServerDataset" -File ".\SqlServerDataset.json"Di seguito è riportato l'output di esempio:
DatasetName : SqlServerDataset ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerTableDataset
Creare un set di dati per l'archivio BLOB di Azure (sink)
In questo passaggio si definisce un set di dati che rappresenta i dati da copiare nell'archivio BLOB di Azure. Il set di dati è di tipo AzureBlob. Fa riferimento al servizio collegato Archiviazione di Azure creato in precedenza in questa esercitazione.
Il servizio collegato ha le informazioni di connessione usate da Data Factory in fase di esecuzione per la connessione all'account di archiviazione di Azure. Questo set di dati specifica la cartella nella risorsa di archiviazione di Azure in cui vengono copiati i dati dal database di SQL Server. In questa esercitazione la cartella è adftutorial/fromonprem dove adftutorial è il contenitore BLOB e fromonprem è la cartella.
Creare un file JSON denominato AzureBlobDataset.json nella cartella C:\ADFv2Tutorial con il codice seguente:
{ "name":"AzureBlobDataset", "properties":{ "linkedServiceName":{ "referenceName":"AzureStorageLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"DelimitedText", "typeProperties":{ "location":{ "type":"AzureBlobStorageLocation", "folderPath":"fromonprem", "container":"adftutorial" }, "columnDelimiter":",", "escapeChar":"\\", "quoteChar":"\"" }, "schema":[ ] }, "type":"Microsoft.DataFactory/factories/datasets" }Per creare il set di dati AzureBlobDataset, eseguire il cmdlet
Set-AzDataFactoryV2Dataset.Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureBlobDataset" -File ".\AzureBlobDataset.json"Di seguito è riportato l'output di esempio:
DatasetName : AzureBlobDataset ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.DelimitedTextDataset
Creare una pipeline
In questa esercitazione viene creata una pipeline con un'attività di copia. L'attività di copia usa SqlServerDataset come set di dati di input e AzureBlobDataset come set di dati di output. Il tipo di origine è impostato su SqlSource e il tipo di sink è impostato su BlobSink.
Creare un file JSON denominato SqlServerToBlobPipeline.json nella cartella C:\ADFv2Tutorial con il codice seguente:
{ "name":"SqlServerToBlobPipeline", "properties":{ "activities":[ { "name":"CopySqlServerToAzureBlobActivity", "type":"Copy", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource" }, "sink":{ "type":"DelimitedTextSink", "storeSettings":{ "type":"AzureBlobStorageWriteSettings" }, "formatSettings":{ "type":"DelimitedTextWriteSettings", "quoteAllText":true, "fileExtension":".txt" } }, "enableStaging":false }, "inputs":[ { "referenceName":"SqlServerDataset", "type":"DatasetReference" } ], "outputs":[ { "referenceName":"AzureBlobDataset", "type":"DatasetReference" } ] } ], "annotations":[ ] } }Eseguire il cmdlet
Set-AzDataFactoryV2Pipelineper creare la pipeline SQLServerToBlobPipeline.Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SQLServerToBlobPipeline" -File ".\SQLServerToBlobPipeline.json"Di seguito è riportato l'output di esempio:
PipelineName : SQLServerToBlobPipeline ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Activities : {CopySqlServerToAzureBlobActivity} Parameters :
Creare un'esecuzione della pipeline
Avviare un'esecuzione della pipeline SQLServerToBlobPipeline e acquisire l'ID di esecuzione della pipeline per il monitoraggio futuro.
$runId = Invoke-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineName 'SQLServerToBlobPipeline'
Monitorare l'esecuzione della pipeline
Eseguire questo script in PowerShell per verificare continuamente lo stato di esecuzione della pipeline SQLServerToBlobPipeline e visualizzare il risultato finale:
while ($True) { $result = Get-AzDataFactoryV2ActivityRun -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineRunId $runId -RunStartedAfter (Get-Date).AddMinutes(-30) -RunStartedBefore (Get-Date).AddMinutes(30) if (($result | Where-Object { $_.Status -eq "InProgress" } | Measure-Object).count -ne 0) { Write-Host "Pipeline run status: In Progress" -foregroundcolor "Yellow" Start-Sleep -Seconds 30 } else { Write-Host "Pipeline 'SQLServerToBlobPipeline' run finished. Result:" -foregroundcolor "Yellow" $result break } }Ecco l'output dell'esecuzione di esempio:
ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> ActivityRunId : 24af7cf6-efca-4a95-931d-067c5c921c25 ActivityName : CopySqlServerToAzureBlobActivity ActivityType : Copy PipelineRunId : 7b538846-fd4e-409c-99ef-2475329f5729 PipelineName : SQLServerToBlobPipeline Input : {source, sink, enableStaging} Output : {dataRead, dataWritten, filesWritten, sourcePeakConnections...} LinkedServiceName : ActivityRunStart : 9/11/2019 7:10:37 AM ActivityRunEnd : 9/11/2019 7:10:58 AM DurationInMs : 21094 Status : Succeeded Error : {errorCode, message, failureType, target} AdditionalProperties : {[retryAttempt, ], [iterationHash, ], [userProperties, {}], [recoveryStatus, None]...}È possibile ottenere l'ID di esecuzione della pipeline SQLServerToBlobPipeline e verificare il risultato dettagliato dell'esecuzione dell'attività usando il comando seguente:
Write-Host "Pipeline 'SQLServerToBlobPipeline' run result:" -foregroundcolor "Yellow" ($result | Where-Object {$_.ActivityName -eq "CopySqlServerToAzureBlobActivity"}).Output.ToString()Ecco l'output dell'esecuzione di esempio:
{ "dataRead":36, "dataWritten":32, "filesWritten":1, "sourcePeakConnections":1, "sinkPeakConnections":1, "rowsRead":2, "rowsCopied":2, "copyDuration":18, "throughput":0.01, "errors":[ ], "effectiveIntegrationRuntime":"ADFTutorialIR", "usedParallelCopies":1, "executionDetails":[ { "source":{ "type":"SqlServer" }, "sink":{ "type":"AzureBlobStorage", "region":"CentralUS" }, "status":"Succeeded", "start":"2019-09-11T07:10:38.2342905Z", "duration":18, "usedParallelCopies":1, "detailedDurations":{ "queuingDuration":6, "timeToFirstByte":0, "transferDuration":5 } } ] }
Verificare l'output
La pipeline crea automaticamente la cartella di output denominata fromonprem nel contenitore BLOB adftutorial. Assicurarsi che nella cartella di output sia presente il file dbo.emp.txt.
Nella finestra del contenitore adftutorial del portale di Azure fare clic su Aggiorna per visualizzare la cartella di output.
Selezionare
fromonpremnell'elenco di cartelle.Verificare che venga visualizzato un file denominato
dbo.emp.txt.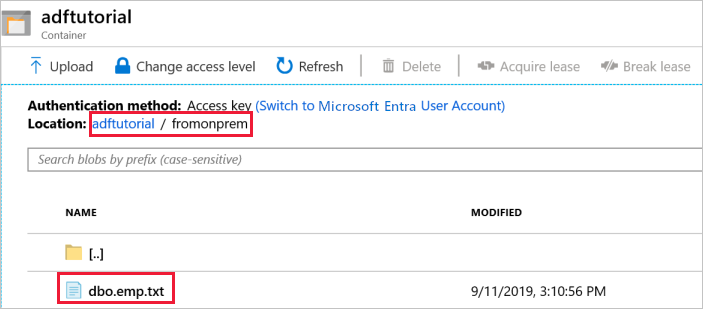
Contenuto correlato
La pipeline in questo esempio copia i dati da una posizione a un'altra in un archivio BLOB di Azure. Contenuto del modulo:
- Creare una data factory.
- Creare un runtime di integrazione self-hosted.
- Creare servizi collegati per SQL Server e Archiviazione di Azure.
- Creare set di dati per SQL Server e BLOB di Azure.
- Creare una pipeline con attività di copia per trasferire i dati.
- Avviare un'esecuzione della pipeline.
- Monitorare l'esecuzione della pipeline.
Per un elenco degli archivi dati supportati da Data Factory, vedere gli archivi dati supportati.
Passare all'esercitazione successiva per ottenere informazioni sulla copia di dati in blocco da un'origine a una destinazione: