Istanze e repliche
Questo articolo offre una panoramica del ciclo di vita delle repliche dei servizi con stato e delle istanze dei servizi senza stato.
Istanze di servizi senza stato
Un'istanza di un servizio senza stato è una copia della logica del servizio in esecuzione in uno dei nodi del cluster. Un'istanza all'interno di una partizione viene identificata in modo univoco dal relativo valore InstanceId. Il ciclo di vita di un'istanza è modellato nel diagramma seguente:
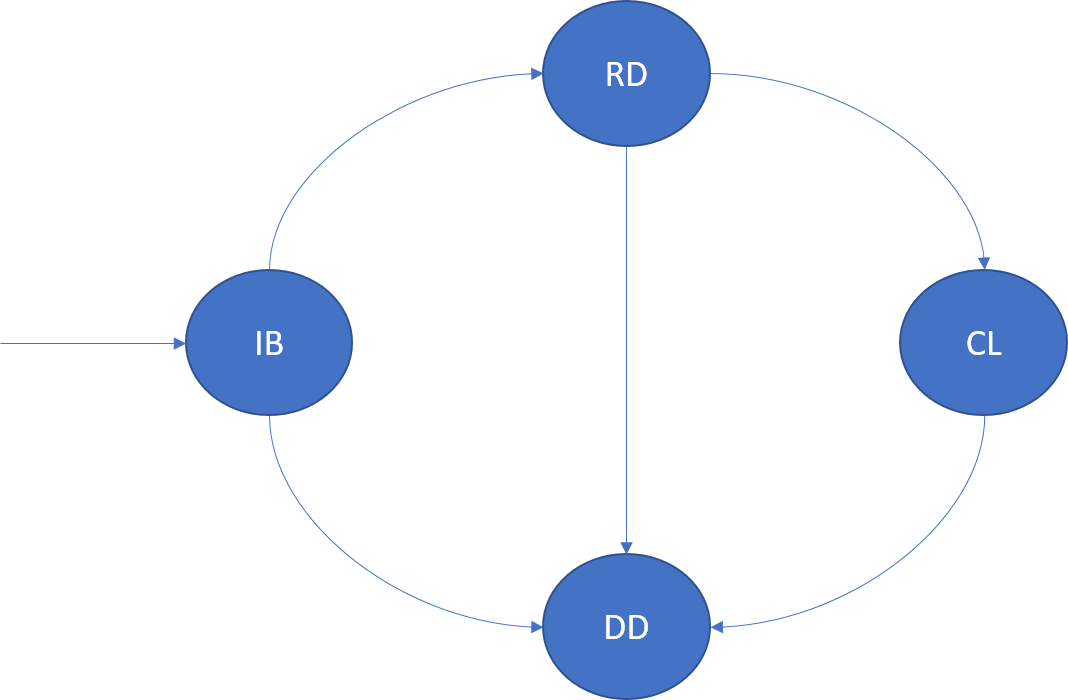
InBuild (IB)
Dopo aver determinato una selezione host per l'istanza, Cluster Resource Manager passa a questo stato del ciclo di vita. L'istanza viene avviata nel nodo. L'host dell'applicazione viene avviato, l'istanza viene creata e quindi aperta. Al termine dell'avvio, l'istanza passa allo stato Ready.
Se si verifica un arresto anomalo dell'host dell'applicazione o del nodo per questa istanza, passa allo stato Dropped (Eliminato).
Ready (RD) (Pronto (RD))
Nello stato Ready (Pronto) l'istanza è attiva nel nodo. Se questa istanza è un servizio Reliable Services, è stato richiamato RunAsync.
Se si verifica un arresto anomalo dell'host dell'applicazione o del nodo per questa istanza, passa allo stato Dropped (Eliminato).
Closing (CL) (Chiusura (CL))
Nello stato Closing Azure Service Fabric esegue l'arresto dell'istanza in questo nodo. Questo arresto può essere dovuto a vari motivi, ad esempio l'aggiornamento di un'applicazione, il bilanciamento del carico o l'eliminazione del servizio. Al termine del processo di arresto, passa allo stato Dropped.
Dropped (DD) (Eliminato (DD))
Nello stato Dropped l'istanza non è più in esecuzione nel nodo. In questa fase Service Fabric gestisce i metadati relativi a questa istanza, che viene comunque eliminata.
Nota
È possibile eseguire la transizione da qualsiasi stato allo stato Dropped usando l'opzione ForceRemove in Remove-ServiceFabricReplica.
Repliche di servizi con stato
Una replica di un servizio con stato è una copia della logica del servizio in esecuzione in uno dei nodi del cluster. La replica gestisce anche una copia dello stato del servizio. Due concetti correlati descrivono il ciclo di vita e il comportamento delle repliche con stato:
- Ciclo di vita della replica
- Ruolo della replica
La discussione seguente illustra i servizi con stato persistente. Per i servizi con stato volatile (o in memoria), gli stati Down e Dropped sono equivalenti.
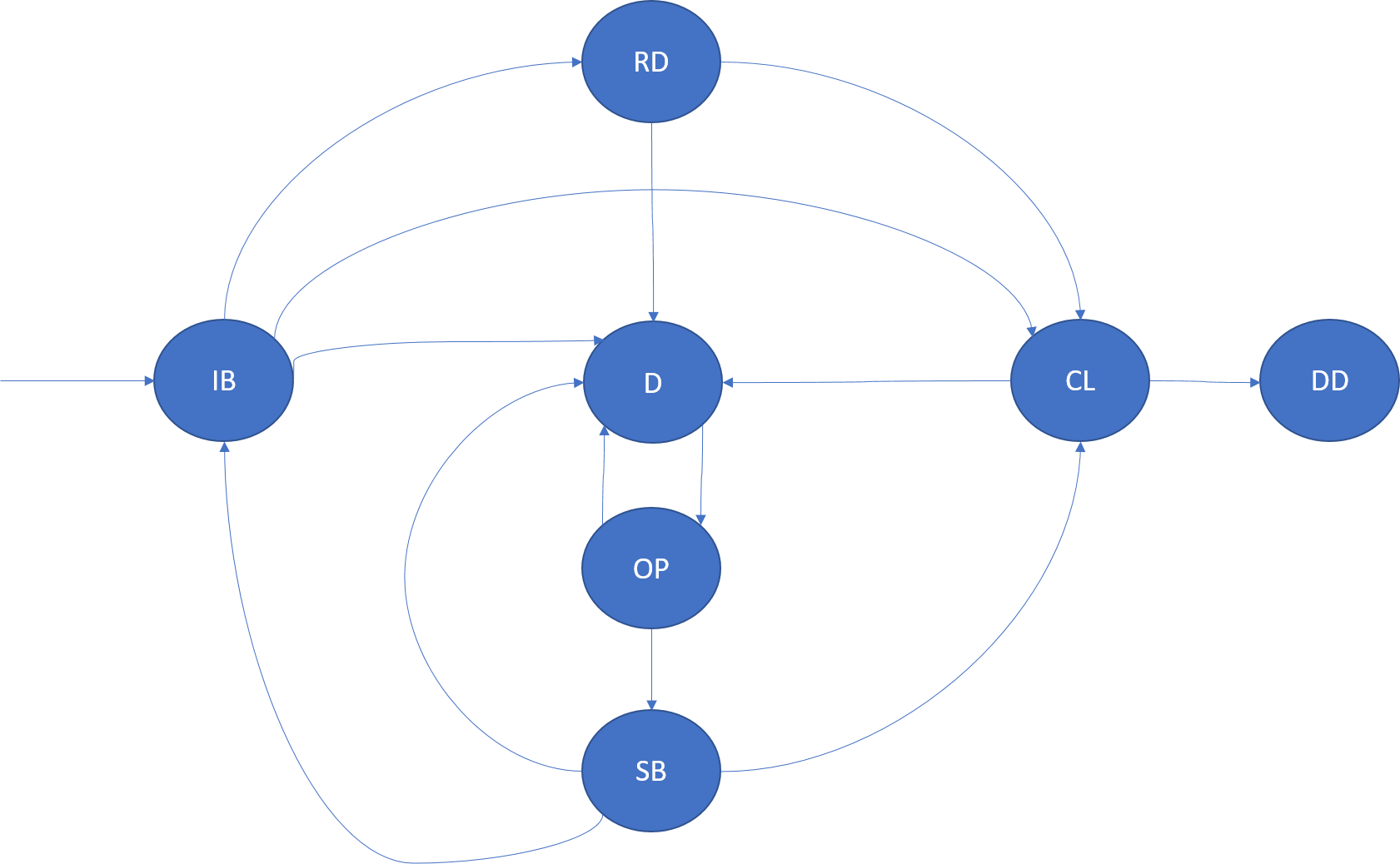
InBuild (IB)
Una replica InBuild è una replica creata o preparata per l'unione con il set di repliche. A seconda del ruolo della replica, IB presenta semantiche diverse.
Se l'host dell'applicazione o il nodo per una replica InBuild si arresta in modo anomalo, passa allo stato Down.
Repliche Primary InBuild: le repliche Primary InBuild sono le prime repliche di una partizione. Questa replica in genere viene eseguita in fase di creazione della partizione. Le repliche Primary InBuild (InBuild primaria) vengono create anche quando tutte le repliche di una partizione vengono riavviate o eliminate.
Repliche IdleSecondary InBuild: si tratta di nuove repliche create da Cluster Resource Manager o di repliche esistenti che sono divenute inaccessibili e devono essere nuovamente aggiunte al set. Queste repliche vengono generate o create dalla primaria prima che possano unirsi al set di repliche come secondarie attive e partecipare al riconoscimento del quorum delle operazioni.
Repliche ActiveSecondary InBuild: questo stato si osserva in alcune query. Si tratta di un'ottimizzazione in cui il set di repliche rimane invariato, ma è necessario creare una replica. La replica stessa segue le transizioni di stato normale del computer (come descritto nella sezione sui ruoli delle repliche).
Ready (RD) (Pronto (RD))
Una replica Ready è una replica che partecipa al processo di replica e al riconoscimento del quorum delle operazioni. Lo stato Ready (Pronto) è applicabile alle repliche primarie e secondarie attive.
Se l'host dell'applicazione o il nodo per una replica Ready si arresta in modo anomalo, passa allo stato Down.
Closing (CL) (Chiusura (CL))
Una replica passa allo stato Closing (Chiusura) negli scenari seguenti:
Arresto del codice per la replica: Service Fabric potrebbe dover arrestare il codice in esecuzione per una replica. Questo arresto può essere dovuto a diversi motivi. Ad esempio, può verificarsi a causa dell'aggiornamento di un'applicazione o di un'infrastruttura oppure a causa di un errore segnalato dalla replica. Al termine della chiusura, la replica passa allo stato Down. Lo stato persistente associato a questa replica archiviata su disco non viene eliminato.
Rimozione della replica dal cluster: Service Fabric potrebbe dover rimuovere lo stato permanente e arrestare il codice in esecuzione per una replica. Questo arresto può essere dovuto a diversi motivi, ad esempio il bilanciamento del carico.
Dropped (DD) (Eliminato (DD))
Nello stato Dropped l'istanza non è più in esecuzione nel nodo. Nel nodo non è presente alcuno stato. In questa fase Service Fabric gestisce i metadati relativi a questa istanza, che viene comunque eliminata.
Down (D) (Inaccessibile (D))
Nello stato Down il codice della replica non è in esecuzione, ma lo stato persistente per la replica è presente su tale nodo. Una replica può essere inaccessibile per diversi motivi, ad esempio in caso di nodo inattivo, di un arresto anomalo nel codice della replica, di un aggiornamento di un'applicazione o di errori nella replica.
Una replica inattiva viene aperta da Service Fabric in base alle esigenze, ad esempio al termine dell'aggiornamento nel nodo.
Il ruolo della replica non è pertinente nello stato Down (Inaccessibile).
Opening (OP) (Apertura (OP))
Una replica Down passa allo stato Opening se Service Fabric deve riattivare la replica. Questo stato può ad esempio verificarsi in seguito a un aggiornamento del codice per l'applicazione in un nodo.
Se l'host dell'applicazione o il nodo per una replica Opening si arresta in modo anomalo, passa allo stato Down.
Il ruolo della replica non è pertinente nello stato Opening (Apertura).
StandBy (SB)
Una replica in stato StandBy è una replica di un servizio persistente che, da inaccessibile, è stata aperta. Questa replica potrebbe essere usata da Service Fabric se deve aggiungere un'altra replica al set di repliche (perché la replica contiene già una parte dello stato e il processo di creazione è più veloce). Alla scadenza di StandByReplicaKeepDuration, la replica StandBy viene rimossa.
Se l'host dell'applicazione o il nodo per una replica StandBy si arresta in modo anomalo, passa allo stato Down.
Il ruolo della replica non è pertinente nello stato StandBy.
Nota
Qualsiasi replica non inattiva o eliminata è considerata attiva.
Nota
È possibile eseguire la transizione da qualsiasi stato allo stato Dropped usando l'opzione ForceRemove in Remove-ServiceFabricReplica.
Ruolo della replica
Il ruolo della replica ne determina la funzione nel set di repliche:
- Primary (P): nel set di repliche è presente una replica primaria responsabile dell'esecuzione di operazioni di lettura e scrittura.
- ActiveSecondary (S): si tratta di repliche che ricevono aggiornamenti di stato dalla replica primaria, li applicano e reinviano riconoscimenti. Sono presenti più repliche secondarie attive nel set di repliche. Il numero di queste repliche secondarie attive determina il numero di errori che il servizio può gestire.
- IdleSecondary (I): queste repliche vengono compilate dalla replica primaria. Ricevono lo stato dalla replica primaria prima di poter essere alzate al livello di repliche secondarie attive.
- None (N): queste repliche non hanno responsabilità nel set di repliche.
- Unknown (U): questo è il ruolo iniziale di una replica prima che riceva una chiamata API ChangeRole da Service Fabric.
Il diagramma seguente illustra le transizioni dei ruoli di replica e alcuni scenari di esempio in cui possono verificarsi:
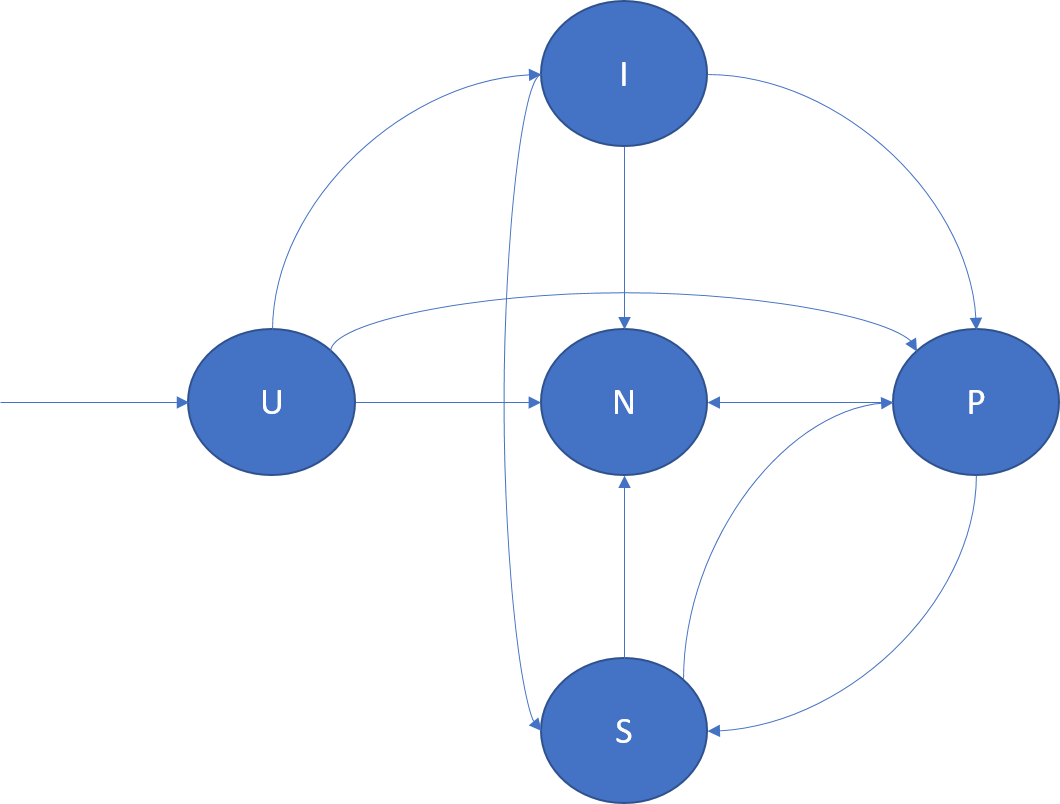
- U -> P: Creazione di una nuova replica primaria.
- U -> I: Creazione di una nuova replica inattiva.
- U -> N: eliminazione di una replica di standby.
- I -> S: Promozione del secondario inattivo al secondario attivo in modo che i riconoscimenti contribuiscano al quorum.
- I -> P: Promozione del secondario inattivo a primario. Ciò può verificarsi in presenza di riconfigurazioni speciali, quando la replica secondaria inattiva è il candidato ideale per diventare primaria.
- I -> N: Eliminazione della replica secondaria inattiva.
- S -> P: Innalzamento di livello del database secondario attivo a primario. Ciò può essere dovuto a un failover della replica primaria o a uno spostamento della replica primaria avviato da Cluster Resource Manager, ad esempio in risposta a un aggiornamento di un'applicazione o al bilanciamento del carico.
- S -> N: eliminazione della replica secondaria attiva.
- P -> S: abbassamento di livello della replica primaria. Ciò può essere causato da uno spostamento della replica primaria avviato da Cluster Resource Manager, ad esempio in risposta a un aggiornamento di un'applicazione o al bilanciamento del carico.
- P -> N: eliminazione della replica primaria.
Nota
Modelli di programmazione di livello superiore, ad esempio Reliable Actors e Reliable Services, nascondono il concetto di ruolo di replica allo sviluppatore. In Actors la nozione di ruolo non è necessaria. In Services è ampiamente semplificata per la maggior parte degli scenari.
Passaggi successivi
Per altre informazioni sui concetti relativi a Service Fabric, vedere l'articolo seguente: