Come distribuire Sincronizzazione file di Azure
Usare Sincronizzazione file di Azure per centralizzare le condivisioni file dell'organizzazione in File di Azure senza rinunciare alla flessibilità, alle prestazioni e alla compatibilità di un file server locale. Il servizio Sincronizzazione file di Azure trasforma Windows Server in una cache rapida della condivisione file di Azure. Per accedere ai dati in locale, è possibile usare qualsiasi protocollo disponibile in Windows Server, inclusi SMB, NFS (Network File System) e FTPS (File Transfer Protocol Service). Si può usare qualsiasi numero di cache necessario in tutto il mondo.
È consigliabile leggere Pianificazione per la distribuzione di File di Azure e Pianificazione per la distribuzione di Sincronizzazione file di Azure prima di completare i passaggi descritti in questo articolo.
Prerequisiti
Una condivisione file di Azure nella stessa area in cui si desidera distribuire Sincronizzazione file di Azure. Per altre informazioni, vedere:
- Aree di disponibilità per Sincronizzazione file di Azure.
- Creare una condivisione file per una descrizione dettagliata della procedura per la creazione di una condivisione file.
Per consentire l'accesso di Sincronizzazione file di Azure all'account di archiviazione, è necessario abilitare le impostazioni dell'account di archiviazione seguenti:
- Le impostazioni di sicurezza SMB devono consentire la versione del protocollo SMB 3.1.1, l'autenticazione NTLM v2 e la crittografia AES-128-GCM. Per controllare le impostazioni di sicurezza SMB nell'account di archiviazione, consultare le impostazioni di sicurezza SMB.
- Consenti accesso con chiave all'account di archiviazione deve essere Abilitato. Per controllare questa impostazione, passare all'account di archiviazione e selezionare Configurazione nella sezione Impostazioni.
Almeno un'istanza supportata di Windows Server da sincronizzare con Sincronizzazione file di Azure. Per altre informazioni sulle versioni supportate di Windows Server e sulle risorse di sistema consigliate, vedere Considerazioni relative al file server Windows.
Gli aggiornamenti di Windows seguenti devono essere installati nel Windows Server:
Facoltativo: se si intende usare Sincronizzazione file di Azure con un cluster di failover di Windows Server, è necessario configurare il ruolo File server per uso generale prima di installare l'agente di Sincronizzazione file di Azure in ogni nodo del cluster. Per altre informazioni su come configurare il ruolo File server per uso generale in un cluster di failover, vedere Distribuzione di un file server in cluster a due nodi.
Nota
L'unico scenario supportato da Sincronizzazione file di Azure è il cluster di failover di Windows Server con dischi in cluster. Vedere Clustering di failover per Sincronizzazione file di Azure.
Anche se la gestione cloud può essere eseguita con il portale di Azure, la funzionalità avanzata del server registrato è fornita tramite i cmdlet di PowerShell che devono essere eseguiti in locale in PowerShell 5.1 o PowerShell 6+. In Windows Server 2012 R2 è possibile verificare se è in esecuzione almeno PowerShell 5.1. esaminando il valore della proprietà PSVersion dell'oggetto $PSVersionTable:
$PSVersionTable.PSVersionSe il valore PSVersion è minore di 5.1.*, è necessario eseguire l'aggiornamento scaricando e installando Windows Management Framework (WMF) 5.1. Il pacchetto appropriato da scaricare e installare per Windows Server 2012 R2 è Win8.1AndW2K12R2-KB*******-x64.msu.
PowerShell 6+ può essere usato con qualsiasi sistema supportato e può essere scaricato tramite la relativa pagina di GitHub.
Preparare Windows Server per l'uso con Sincronizzazione file di Azure
Per ogni server da usare con Sincronizzazione file di Azure, incluso ogni nodo server in un cluster di failover, disabilitare Sicurezza avanzata di Internet Explorer. Questa operazione è necessaria solo per la registrazione iniziale del server e l'opzione può essere riabilitata dopo che il server è stato registrato.
Nota
È possibile ignorare questo passaggio se si distribuisce Sincronizzazione file di Azure in Windows Server Core.
- Aprire Gestione server.
- Fare clic su Server locale:
- Ne riquadro secondario Proprietà selezionare il collegamento per Configurazione sicurezza avanzata IE.
- Nella finestra di dialogo Configurazione sicurezza avanzata IE selezionare Disattivato per Amministratori e Utenti:

Distribuire il servizio di sincronizzazione archiviazione
La distribuzione di Sincronizzazione file di Azure inizia con l'inserimento di una risorsa servizio di sincronizzazione archiviazione in un gruppo di risorse della sottoscrizione selezionata. È consigliabile effettuare il provisioning di alcune di queste risorse in base alle esigenze. Si creerà una relazione di trust tra i server e questa risorsa. Un server può essere registrato in un solo servizio di sincronizzazione archiviazione. Di conseguenza, è consigliabile distribuire tutti i servizi di sincronizzazione archiviazione necessari per separare i gruppi di server. Tenere presente che non è possibile sincronizzare tra di loro i server di servizi di sincronizzazione archiviazione diversi.
Nota
Il servizio di sincronizzazione archiviazione eredita le autorizzazioni di accesso dalla sottoscrizione e dal gruppo di risorse in cui è stato distribuito. È consigliabile controllare attentamente chi dispone di accesso. Le entità con accesso in scrittura possono avviare la sincronizzazione di nuovi set di file dai server registrati in questo servizio di sincronizzazione archiviazione, causando il flusso dei dati in un archivio di Azure a loro accessibile.
Per distribuire un servizio di sincronizzazione archiviazione, accedere al portale di Azure, selezionare Crea una risorsa e cercare Sincronizzazione file di Azure. Nei risultati della ricerca selezionare Sincronizzazione file di Azure e quindi selezionare Crea per aprire la scheda Distribuisci sincronizzazione archiviazione.
Nel pannello che viene visualizzato immettere le informazioni seguenti:
- Nome: un nome univoco (per ogni area) per il servizio di sincronizzazione archiviazione.
- Sottoscrizione: la sottoscrizione in cui creare il servizio di sincronizzazione archiviazione. A seconda della strategia di configurazione dell'organizzazione, è possibile accedere a una o più sottoscrizioni. Una sottoscrizione di Azure è il contenitore di base per la fatturazione di ogni servizio cloud, ad esempio File di Azure.
- Gruppo di risorse: un gruppo di risorse è un gruppo logico di risorse di Azure, ad esempio un account di archiviazione o un servizio di sincronizzazione archiviazione. Per Sincronizzazione file di Azure è possibile selezionare un gruppo di risorse esistente o crearne uno nuovo. È consigliabile usare i gruppi di risorse come contenitori per isolare le risorse in modo logico per l'organizzazione, ad esempio si possono raggruppare le risorse delle Risorse Umane o per un progetto specifico.
- Percorso: l'area in cui si vuole distribuire Sincronizzazione file di Azure. In questo elenco sono disponibili solo le aree supportate.
Al termine, selezionare Crea per distribuire il servizio di sincronizzazione di archiviazione.
Installare l'agente di Sincronizzazione file di Azure
L'agente Sincronizzazione file di Azure è un pacchetto scaricabile che consente di sincronizzare Windows Server con una condivisione file di Azure.
È possibile scaricare l'agente dall'Area download Microsoft. Al termine del download, fare doppio clic sul pacchetto MSI per avviare l'installazione dell'agente sincronizzazione file di Azure o per installare automaticamente l'agente, vedere Come eseguire un'installazione invisibile all'utente per una nuova installazione dell'agente sincronizzazione file di Azure.
Importante
Se si usa Sincronizzazione file di Azure con un cluster di failover, l'agente di Sincronizzazione file di Azure deve essere installato in ogni nodo del cluster. Ogni nodo del cluster deve registrato affinché usi Sincronizzazione file di Azure.
È consigliabile eseguire queste operazioni:
- Lasciare il percorso di installazione predefinito (c:\Programmi\Microsoft Files\Azure\StorageSyncAgent), per semplificare la risoluzione dei problemi e la manutenzione del server.
- Abilitare Microsoft Update per mantenere sempre aggiornato Sincronizzazione file di Azure. Tutti gli aggiornamenti per l'agente Sincronizzazione file di Azure, inclusi gli aggiornamenti delle funzionalità e gli hotfix, vengono eseguiti tramite Microsoft Update. È consigliabile installare l'aggiornamento più recente di Sincronizzazione file di Azure. Per altre informazioni, vedere Criteri di aggiornamento dell'agente Sincronizzazione file di Azure.
Al termine dell'installazione dell'agente Sincronizzazione file di Azure, viene avviata automaticamente l'interfaccia utente di Registrazione server. È necessario disporre di un servizio di sincronizzazione archiviazione prima di eseguire la registrazione. Per creare un servizio di sincronizzazione archiviazione, vedere la sezione successiva.
Registrare Windows Server con il servizio di sincronizzazione archiviazione
La registrazione di Windows Server con un servizio di sincronizzazione archiviazione consente di stabilire una relazione di trust tra il server, o il cluster, in uso e il servizio di sincronizzazione archiviazione. Un server può essere registrato solo in un servizio di sincronizzazione archiviazione e può eseguire la sincronizzazione con altri server e condivisioni file di Azure associati allo stesso servizio di sincronizzazione archiviazione.
Nota
La registrazione del server usa le credenziali di Azure per creare una relazione di trust tra il servizio di sincronizzazione archiviazione e Windows Server. Successivamente, il server crea e usa la propria identità valida finché il server rimane registrato e il token di firma di accesso condiviso corrente è valido. Non è possibile rilasciare un nuovo token di firma di accesso condiviso per il server dopo l'annullamento della registrazione del server, quindi il server non può più accedere alle condivisioni file di Azure con il conseguente arresto di ogni attività di sincronizzazione.
L'amministratore che registra il server deve essere un membro dei ruoli di gestione Proprietario o Collaboratore per il servizio di sincronizzazione archiviazione specificato. Questa impostazione può essere configurata in Controllo di accesso (IAM) nel portale di Azure per il servizio di sincronizzazione archiviazione.
È anche possibile distinguere gli amministratori in grado di registrare i server da quelli autorizzati anche a configurare la sincronizzazione in un servizio di sincronizzazione archiviazione. A tale scopo, è necessario creare un ruolo personalizzato in cui vengono elencati gli amministratori autorizzati solo a registrare i server e ad assegnare al ruolo personalizzato le autorizzazioni seguenti:
- "Microsoft.StorageSync/storageSyncServices/registeredServers/write"
- "Microsoft.StorageSync/storageSyncServices/read"
- "Microsoft.StorageSync/storageSyncServices/workflows/read"
- "Microsoft.StorageSync/storageSyncServices/workflows/operations/read"
L'interfaccia utente di Registrazione Server viene visualizzata automaticamente al termine dell'installazione dell'agente Sincronizzazione file di Azure. In caso contrario, è possibile aprirla manualmente dal percorso file: C:\Program Files\Azure\StorageSyncAgent\ServerRegistration.exe. Dopo avere aperto l'interfaccia utente di Registrazione server fare clic su Accesso per iniziare.
Eseguito l'accesso, viene richiesto di specificare le informazioni seguenti:
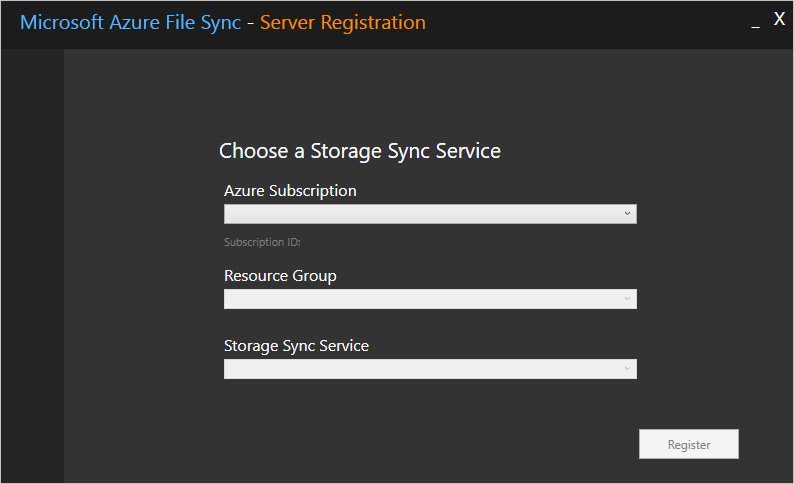
- Sottoscrizione di Azure: la sottoscrizione che contiene il servizio di sincronizzazione archiviazione (vedere Distribuire il servizio di sincronizzazione archiviazione).
- Gruppo di risorse: il gruppo di risorse che contiene il servizio di sincronizzazione archiviazione.
- Servizio di sincronizzazione archiviazione: il nome del servizio di sincronizzazione archiviazione con cui si effettua la registrazione.
Dopo avere selezionato le informazioni appropriate, selezionare Registra per completare la registrazione del server. Come parte del processo di registrazione, viene richiesto un accesso aggiuntivo.
Creare un gruppo di sincronizzazione e un endpoint cloud
Un gruppo di sincronizzazione definisce la topologia di sincronizzazione per un set di file. Gli endpoint all'interno di un gruppo di sincronizzazione vengono mantenuti sincronizzati tra loro. Un gruppo di sincronizzazione deve contenere un endpoint cloud, che rappresenta una condivisione file di Azure, e uno o più endpoint server. Un endpoint server rappresenta un percorso in un server registrato. Un server può avere endpoint server in più gruppi di sincronizzazione. È possibile creare tutti i gruppi di sincronizzazione necessari per descrivere in modo appropriato la topologia di sincronizzazione desiderata.
Un endpoint cloud è un puntatore a una condivisione file di Azure. Tutti gli endpoint server vengono sincronizzati con un endpoint cloud, che diventa quindi l'hub. L'account di archiviazione per la condivisione file di Azure deve trovarsi nella stessa area del servizio di sincronizzazione archiviazione. Viene sincronizzata l'intera condivisione file di Azure con un'unica eccezione: viene effettuato il provisioning di una cartella speciale, paragonabile alla cartella di informazioni sul volume di sistema nascosta, in un volume NTFS. Tale directory è denominata ".SystemShareInformation". Contiene metadati di sincronizzazione importanti che non vengono sincronizzati negli altri endpoint. Non usarlo o eliminarlo!
Importante
È possibile apportare modifiche a qualsiasi endpoint cloud o endpoint server nel gruppo di sincronizzazione e fare in modo che i file vengano sincronizzati con gli altri endpoint del gruppo di sincronizzazione. Se si apporta direttamente una modifica all'endpoint cloud (condivisione file di Azure), le modifiche apportate devono essere prima di tutto individuate da un processo di rilevamento delle modifiche di Sincronizzazione file di Azure, che per un endpoint cloud viene avviato una sola volta ogni 24 ore. Per altre informazioni, vedere Domande frequenti su File di Azure.
L'amministratore che crea l'endpoint cloud deve essere membro del ruolo di gestione Proprietario per l'account di archiviazione che contiene la condivisione file di Azure a cui punta l'endpoint cloud. Configurare questa impostazione in Controllo di accesso (IAM) nel portale di Azure per l'account di archiviazione.
Per creare un gruppo di sincronizzazione, accedere al portale di Azure, passare al servizio di sincronizzazione archiviazione e quindi selezionare + Gruppo di sincronizzazione:
Nel riquadro che viene visualizzato immettere le informazioni seguenti per creare un gruppo di sincronizzazione con un endpoint cloud:
- Nome gruppo di sincronizzazione: il nome del gruppo di sincronizzazione da creare. Questo nome deve essere univoco all'interno del servizio di sincronizzazione archiviazione, ma può essere qualsiasi nome logico per l'utente.
- Sottoscrizione: la sottoscrizione in cui è stato distribuito il servizio di sincronizzazione archiviazione in Distribuire il servizio di sincronizzazione archiviazione.
- Account di archiviazione: se si seleziona Selezionare l'account di archiviazione, viene visualizzato un altro riquadro in cui è possibile selezionare l'account di archiviazione che contiene la condivisione file di Azure con cui si vuole eseguire la sincronizzazione.
- Condivisione file di Azure: il nome della condivisione file di Azure con cui si vuole eseguire la sincronizzazione.
Creare un endpoint server
Un endpoint server rappresenta una posizione specifica in un server registrato, ad esempio una cartella in un volume del server. Un endpoint server è soggetto alle condizioni seguenti:
- Un endpoint server deve essere un percorso in un server registrato (anziché una condivisione montata). L'archiviazione NAS (Network Attached Storage) non è supportata.
- Anche se l'endpoint server può trovarsi nel volume di sistema, gli endpoint server nel volume di sistema potrebbero non usare il cloud a livelli.
- La modifica del percorso o della lettera di unità dopo aver stabilito un endpoint server in un volume non è supportata. Assicurarsi di usare un percorso finale nel server registrato.
- Un server registrato può supportare più endpoint server. Tuttavia, un gruppo di sincronizzazione può avere un solo endpoint server per ogni server registrato in qualsiasi momento. Altri endpoint server all'interno del gruppo di sincronizzazione devono trovarsi in server registrati diversi.
Per aggiungere un endpoint server, passare al gruppo di sincronizzazione appena creato. In Endpoint server selezionare +Aggiungi endpoint server. Verrà visualizzato il pannello Aggiungi endpoint server. Per creare un nuovo endpoint server, immettere le informazioni seguenti:
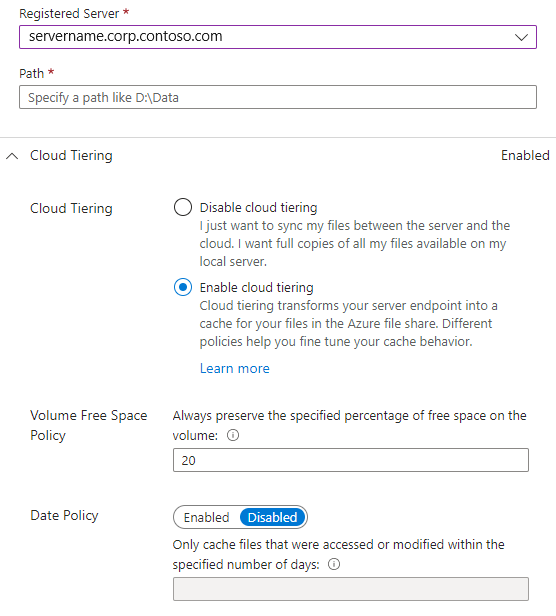
- Server registrato: il nome del server o del cluster in cui viene creato l'endpoint server.
- Percorso: percorso in Windows Server da sincronizzare con la condivisione file di Azure. Il percorso può essere una cartella (ad esempio, D:\Dati), una radice del volume (ad esempio, D:\) o un punto di montaggio del volume (ad esempio, D:\Montaggio).
- Suddivisione in livelli cloud: l'opzione che abilita o disabilita la suddivisione in livelli cloud, che consente di archiviare a livelli in File di Azure i file che si usano o a cui si accede raramente. Quando si abilita il cloud a livelli, è possibile impostare due criteri per comunicare a Sincronizzazione file di Azure quando eseguire l'archiviazione a livelli dei file ad accesso sporadico: Criterio spazio disponibile volume e Criteri data.
- Spazio disponibile nel volume: la quantità di spazio disponibile da riservare nel volume in cui si trova l'endpoint server. Se ad esempio lo spazio disponibile nel volume è impostato su 50% per un volume con un singolo endpoint server, circa la metà dei dati viene archiviata a livelli in File di Azure. A prescindere dall'abilitazione o meno della suddivisione in livelli nel cloud, per la condivisione file di Azure è sempre disponibile una copia completa dei dati nel gruppo di sincronizzazione.
- Criteri data: i file vengono archiviati a livelli nel cloud se l'utente non vi ha eseguito l'accesso (ovvero operazioni di lettura e scrittura) per il numero di giorni specificato. Ad esempio, se si è notato che i file che a cui non è eseguito l'accesso per più di 15 giorni sono in genere file di archiviazione, è consigliabile impostare i criteri data su 15 giorni.
- Sincronizzazione iniziale: la sezione Sincronizzazione iniziale è disponibile solo per il primo endpoint server in un gruppo di sincronizzazione (la sezione diventa in Download iniziale quando si creano più endpoint server in un gruppo di sincronizzazione). Nella sezione Sincronizzazione iniziale è possibile selezionare il comportamento di caricamento iniziale e download iniziale.
Caricamento iniziale: è possibile selezionare il modo in cui il server carica inizialmente i dati nella condivisione file di Azure:
- Opzione 1: unire il contenuto di questo percorso del server con il contenuto nella condivisione file di Azure. I file con lo stesso nome e percorso causeranno conflitti se il contenuto è diverso. Le due versioni di tali file verranno archiviate l'una accanto all'altra. Se il percorso del server o la condivisione file di Azure sono vuoti, scegliere sempre questa opzione.
- Opzione 2: sovrascrivere in modo autorevole file e cartelle nella condivisione file di Azure con il contenuto di questo percorso del server. Tale opzione consente di evitare conflitti di file.
Per altre informazioni, vedere Sincronizzazione iniziale.
Download iniziale: è possibile selezionare il modo in cui il server scarica inizialmente i dati della condivisione file di Azure. Questa impostazione è importante quando il server si connette a una condivisione file di Azure e contiene già alcuni file. "Spazio dei nomi" indica la struttura di file e cartelle senza il contenuto dei file. Il contenuto dei file di "file a livelli" viene richiamato dal cloud al server in base all'accesso o ai criteri locali.
- Opzione n. 1: scaricare prima lo spazio dei nomi e quindi richiamare il contenuto dei file, in un quantitativo adatto al disco locale.
- Opzione 2: scaricare solo lo spazio dei nomi. Il contenuto dei file verrà richiamato all'accesso.
- Opzione 3: evitare file a livelli. I file verranno visualizzati nel server solo dopo il download completo.
Per altre informazioni, vedere Download iniziale.
Per aggiungere l'endpoint server, selezionare Crea. I file vengono ora mantenuti sincronizzati tra la condivisione file di Azure e Windows Server.
Nota
Sincronizzazione file di Azure crea uno snapshot della condivisione file di Azure come backup prima di creare l'endpoint server. Questo snapshot può essere usato per ripristinare lo stato della condivisione prima della creazione dell'endpoint server. Lo snapshot non viene rimosso automaticamente dopo la creazione dell'endpoint server, quindi è possibile eliminarlo manualmente se non è necessario. È possibile trovare gli snapshot creati da Sincronizzazione file di Azure esaminando gli snapshot per la condivisione file di Azure e controllando AzureFileSync nella colonna Iniziatore.
Facoltativo: Configurare le impostazioni del firewall e della rete virtuale
Portale
Se si vuole configurare Sincronizzazione file di Azure per l'uso con le impostazioni di firewall e rete virtuale, procedere come segue:
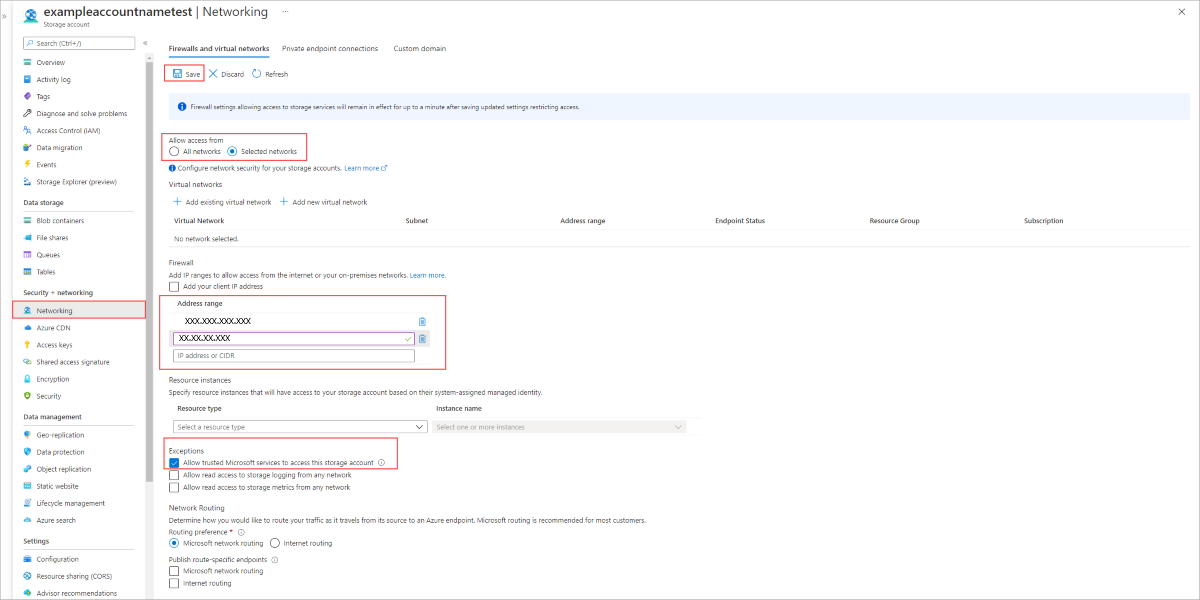
Nel portale di Azure passare all'account di archiviazione da proteggere.
Nel menu a sinistra selezionare Rete.
Selezionare Reti selezionate in Consenti l'accesso da.
Verificare che l'indirizzo IP dei server o l'indirizzo della rete virtuale sia elencato nella sezione appropriata Intervallo di indirizzi.
Assicurarsi che l'opzione Consenti ai servizi Microsoft attendibili di accedere a questo account di archiviazione sia selezionata.
Per salvare le impostazioni, fare clic su Save (Salva).
Facoltativo: ripristino self-service tramite Versioni precedenti e Servizio Copia Shadow del volume
Versioni precedenti è una funzionalità di Windows che consente di usare snapshot del Servizio Copia Shadow del volume lato server di un volume per presentare le versioni ripristinabili di un file in un client SMB. Ciò consente uno scenario avanzato, comunemente definito ripristino self-service, direttamente per gli information worker anziché dipendere dal ripristino eseguito da un amministratore IT.
Gli snapshot del Servizio Copia Shadow del volume e Versioni precedenti funzionano indipendentemente da Sincronizzazione file di Azure. Tuttavia, il cloud a livelli deve essere impostato su una modalità compatibile. Nello stesso volume possono esistere più endpoint server di Sincronizzazione file di Azure. È necessario effettuare la chiamata di PowerShell seguente per ogni volume che abbia anche un solo endpoint server in cui si prevede o si usa il cloud a livelli.
Import-Module '<SyncAgentInstallPath>\StorageSync.Management.ServerCmdlets.dll'
Enable-StorageSyncSelfServiceRestore [-DriveLetter] <string> [[-Force]]
Gli snapshot del Servizio Copia Shadow del volume vengono acquisiti da un intero volume. Per impostazione predefinita, per un determinato volume possono esistere fino a 64 snapshot, purché ci sia spazio sufficiente per archiviare gli snapshot. Servizio Copia Shadow del volume gestisce automaticamente questa operazione. La pianificazione degli snapshot predefinita acquisisce due snapshot al giorno, dal lunedì al venerdì. Tale pianificazione è configurabile tramite un'attività pianificata di Windows. Il cmdlet di PowerShell precedente esegue due operazioni:
- Configura il cloud a livelli di Sincronizzazione file di Azure nel volume specificato in modo che sia compatibile con le versioni precedenti e garantisce che un file possa essere ripristinato da una versione precedente, anche se è stato archiviato a livelli nel cloud del server.
- Abilita la pianificazione predefinita del Servizio Copia Shadow del volume. È quindi possibile decidere di modificarla in un secondo momento.
Nota
Esistono due aspetti importanti da notare:
- Se si usa il parametro -Force, e Servizio Copia Shadow del volume è attualmente abilitato, il parametro sovrascrive la pianificazione degli snapshot di Servizio Copia Shadow del volume corrente e la sostituisce con la pianificazione predefinita. Assicurarsi di salvare la configurazione personalizzata prima di eseguire il cmdlet.
- Se si usa questo cmdlet in un nodo del cluster, è necessario eseguirlo anche in tutti gli altri nodi del cluster.
Per verificare se la compatibilità del ripristino self-service è abilitata, è possibile eseguire il cmdlet seguente:
Get-StorageSyncSelfServiceRestore [[-Driveletter] <string>]
Verranno elencati tutti i volumi nel server e il numero di giorni compatibili per il cloud a livelli per ognuno di essi. Questo numero viene calcolato automaticamente in base al numero massimo possibile di snapshot per volume e alla pianificazione degli snapshot predefinita. Per impostazione predefinita, quindi, tutte le versioni precedenti presentate a un information worker possono quindi essere usate per eseguirne il ripristino. Lo stesso vale se si modifica la pianificazione predefinita per acquisire più snapshot. Tuttavia, se si modifica la pianificazione in modo che generi uno snapshot disponibile nel volume che sia precedente al valore di giorni compatibili, gli utenti non potranno usare questo snapshot precedente (versione precedente) per eseguire il ripristino.
Nota
L'abilitazione del ripristino self-service può influire sull'utilizzo e sulla fatturazione dell'archiviazione di Azure. Questo impatto è limitato ai file attualmente suddivisi a livelli nel server. L'abilitazione di questa funzionalità garantisce che nel cloud sia disponibile una versione del file a cui è possibile fare riferimento tramite una voce (snapshot del Servizio Copia Shadow del volume) delle versioni precedenti.
Se si disabilita questa funzionalità, l'utilizzo dell'archiviazione di Azure diminuisce lentamente fino a quando non viene superata la finestra dei giorni compatibili. Non c'è modo di velocizzare questa operazione.
Il numero massimo predefinito di snapshot del Servizio Copia Shadow del volume per ogni volume (64) e la pianificazione predefinita per acquisirli comportano un massimo di 45 giorni di versioni precedenti da cui un information worker può eseguire il ripristino, a seconda del numero di snapshot del Servizio Copia Shadow del volume che è possibile archiviare nel volume.
Se un massimo di 64 snapshot del Servizio Copia Shadow del volume per ogni volume non è l'impostazione corretta per l'utente, modificare tale valore tramite una chiave del Registro di sistema. Per rendere effettivo il nuovo limite, è necessario eseguire nuovamente il cmdlet per abilitare la compatibilità delle versioni precedenti in ogni volume abilitato in precedenza. Il flag -Force deve prendere in considerazione il nuovo numero massimo di snapshot del Servizio Copia Shadow del volume per ogni volume. In questo modo verrà restituito un nuovo valore calcolato per il numero di giorni compatibili. Questa modifica avrà effetto solo sui nuovi file suddivisi a livelli e sovrascriverà le personalizzazioni nella pianificazione del Servizio Copia Shadow del volume impostate dall'utente.
Gli snapshot del Servizio Copia Shadow del volume per impostazione predefinita possono utilizzare fino al 10% dello spazio del volume. Per regolare la quantità di spazio di archiviazione che può essere usato per gli snapshot del Servizio Copia Shadow del volume, usare il comando vssadmin resize shadowstorage.
Facoltativo: richiamare in modo proattivo i file nuovi e modificati da una condivisione file di Azure
Sincronizzazione file di Azure ha una modalità che consente alle aziende distribuite a livello globale di prepopolare la cache del server in un'area remota anche prima che gli utenti locali accedano ai file. Se abilitata in un endpoint server, questa modalità farà in modo che il server richiami i file creati o modificati nella condivisione file di Azure.
Scenario
Un'azienda distribuita a livello globale ha succursali negli Stati Uniti e in India. Al mattino (ora USA) gli information worker creano una nuova cartella e nuovi file per un nuovo progetto e lavorano tutto il giorno su di esso. Sincronizzazione file di Azure sincronizza la cartelle e i file nella condivisione file di Azure (endpoint cloud). Gli information worker in India continueranno a lavorare al progetto con il proprio fuso orario. Al mattino, in India, nel server abilitato per Sincronizzazione file di Azure locale questi nuovi file devono essere disponibili in locale, in modo che il team indiano possa lavorare in modo efficiente da una cache locale. L'abilitazione di questa modalità impedisce che l'accesso iniziale ai file sia più lento a causa del richiamo su richiesta e consente al server di richiamare in modo proattivo i file non appena vengono modificati o creati nella condivisione file di Azure.
Importante
Il rilevamento delle modifiche nella condivisione file di Azure vicina al server può aumentare il traffico in uscita e l'importo della fattura di Azure. Se i file richiamati al server non sono effettivamente necessari in locale, non è consigliabile richiamare il server. Usare solo questa modalità quando si è sicuri che la possibilità di prepolorare la cache in un server con modifiche recenti nel cloud avrà un effetto positivo sugli utenti o sulle applicazioni che usano i file in tale server.
Abilitare un endpoint server per richiamare in modo proattivo le modifiche apportate in una condivisione file di Azure
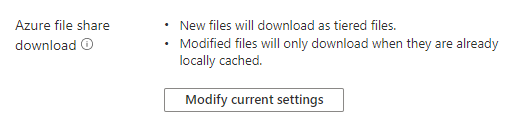
- Nel portale di Azure passare al servizio di sincronizzazione archiviazione, selezionare il gruppo di sincronizzazione corretto e quindi identificare l'endpoint server per cui si desidera tenere traccia attentamente delle modifiche nella condivisione file di Azure (endpoint cloud).
- Nella sezione relativa al cloud a livelli individuare l'argomento Download della condivisione file di Azure. Verrà visualizzata la modalità attualmente selezionata ed è possibile modificarla per tenere traccia delle modifiche apportate alla condivisione file di Azure in modo più attento e richiamarle in modo proattivo nel server.
Facoltativo: SMB su QUIC in un endpoint server
Sebbene la condivisione file di Azure (endpoint cloud) sia un endpoint SMB completo in grado di accedere direttamente dal cloud o in locale, i clienti che desiderano accedere ai dati della condivisione file sul lato cloud spesso distribuiscono un endpoint server di Sincronizzazione file di Azure in un'istanza di Windows Server ospitata in una macchina virtuale di Azure. Il motivo più comune per avere un endpoint server aggiuntivo anziché accedere direttamente alla condivisione file di Azure è che le modifiche apportate direttamente nella condivisione file di Azure possono richiedere fino a 24 ore o più per essere individuate da Sincronizzazione file di Azure, mentre le modifiche apportate a un endpoint server vengono individuate quasi immediatamente e sincronizzate con tutti gli altri endpoint server e cloud.
Questa configurazione è estremamente comune negli ambienti in cui una parte sostanziale degli utenti è remota. Tradizionalmente, l'accesso a una condivisione file con SMB tramite la rete Internet pubblica, incluse sia le condivisioni file ospitate in File server Windows o direttamente in File di Azure, può essere molto complicato poiché molte organizzazioni e degli ISP blocca la porta 445. È possibile ovviare a questa limitazione con gli endpoint privati e le VPN, tuttavia Windows Server 2022 Azure Edition offre una strategia di accesso aggiuntiva: SMB sul protocollo di trasporto QUIC.
SMB su QUIC comunica sulla porta 443, che la maggior parte delle organizzazioni e degli ISP hanno aperto per supportare il traffico HTTPS. L'uso di SMB su QUIC semplifica notevolmente la rete necessaria per accedere a una condivisione file ospitata in un endpoint server di Sincronizzazione file di Azure per i client che usano Windows 11 o una versione successiva. Per altre informazioni su come configurare e impostare SMB su QUIC in Windows Server Azure Edition, vedere SMB su QUIC per File Server Windows.
Onboarding con Sincronizzazione file di Azure
Le procedure consigliate per l'esecuzione dell'onboarding in Sincronizzazione file di Azure per la prima volta senza alcun tempo di inattività e mantenendo intatta la fedeltà dei file e l'elenco di controllo di accesso (ACL) sono le seguenti:
- Distribuire un servizio di sincronizzazione archiviazione.
- Creare un gruppo di sincronizzazione.
- Installare l'agente di Sincronizzazione file di Azure nel server con il set di dati completo.
- Registrare il server e creare un endpoint del server nella condivisione.
- Consentire alla sincronizzazione di eseguire il caricamento completo in condivisione file di Azure (endpoint cloud).
- Al termine del caricamento iniziale, installare l'agente di Sincronizzazione file di Azure in ognuno dei server rimanenti.
- Creare nuove condivisioni file in ognuno dei server rimanenti.
- Creare endpoint server nelle nuove condivisioni file con i criteri di suddivisione in livelli nel cloud, se lo si desidera. Per questo passaggio sono necessarie altre risorse di archiviazione disponibili per l'installazione iniziale.
- Consentire all'agente di Sincronizzazione file di Azure di eseguire un rapido ripristino dello spazio dei nomi completo senza il trasferimento effettivo dei dati. Dopo la sincronizzazione completa dello spazio dei nomi, il motore di sincronizzazione riempirà lo spazio su disco locale in base ai criteri suddivisione in livelli nel cloud per l'endpoint server.
- Verificare che la sincronizzazione sia stata completata e testare la topologia in base alle esigenze.
- Reindirizzare gli utenti e le applicazioni a questa nuova condivisione.
- Facoltativamente, è possibile eliminare le condivisioni duplicate nei server.
Se non si dispone di spazio di archiviazione aggiuntivo per l'onboarding iniziale e si vuole eseguire un collegamento alle condivisioni esistenti, è possibile effettuare il pre-seeding dei dati nelle condivisioni file di Azure usando un altro strumento di trasferimento dati anziché usare il servizio di sincronizzazione archiviazione per caricare i dati. L'approccio basato sul pre-seeding è consigliato solo se è possibile accettare il tempo di inattività e garantire che non avvenga alcuna modifica nelle condivisioni dei server durante il processo di onboarding iniziale.
- Assicurarsi che i dati nei server non vengano modificati durante il processo di onboarding.
- Effettuare il pre-seeding delle condivisioni file di Azure con i dati del server usando un qualsiasi strumento di trasferimento di dati su SMB, ad esempio Robocopy o AzCopy su REST. Se si usa Robocopy, assicurarsi di montare le condivisioni file di Azure usando la chiave di accesso dell'account di archiviazione, non usare un'identità di dominio. Se si usa AzCopy, assicurarsi di impostare le opzioni appropriate per mantenere i timestamp e gli attributi ACL.
- Creare una topologia di Sincronizzazione file di Azure con gli endpoint del server desiderati che puntano alle condivisioni esistenti.
- Consentire alla sincronizzazione di completare il processo di riconciliazione in tutti gli endpoint.
- Una volta completata la riconciliazione, è possibile aprire le condivisioni per le modifiche.
Attualmente, il pre-seeding presenta alcune limitazioni:
- Le modifiche ai dati nel server prima che la topologia di sincronizzazione sia completamente operativa e in esecuzione possono causare conflitti negli endpoint server.
- Dopo aver creato l'endpoint cloud, Sincronizzazione file di Azure esegue un processo per rilevare i file nel cloud prima di avviare la sincronizzazione iniziale. Il tempo impiegato per completare il processo varia a seconda dei fattori quali la velocità di rete, la larghezza di banda disponibile e il numero di file e cartelle. Per la stima approssimativa nella versione di anteprima, il processo di rilevamento viene eseguito a una velocità di circa 10 file/sec. Di conseguenza, anche se il pre-seeding viene eseguito velocemente, il tempo complessivo per ottenere un sistema completamente operativo può essere notevolmente più lungo quando viene effettuato il pre-seeding dei dati nel cloud.
Eseguire la migrazione di una distribuzione di Replica DFS (DFS-R) in Sincronizzazione file di Azure
Per eseguire la migrazione di una distribuzione di DFS-R in Sincronizzazione file di Azure:
- Creare un gruppo di sincronizzazione per rappresentare la topologia di DFS-R che si sta sostituendo.
- Avviare il server contenente il set completo di dati in una topologia DFS-R di cui eseguire la migrazione. Installare Sincronizzazione file di Azure su tale server.
- Registrare il server e creare un endpoint server per il primo server di cui eseguire la migrazione. Non abilitare il cloud a livelli.
- Consentire la sincronizzazione di tutti i dati in Condivisione file di Azure (endpoint cloud).
- Installare e registrare l'agente Sincronizzazione file di Azure in ogni server DFS-R rimanente.
- Disabilitare DFS-R.
- Creare un endpoint server in ogni server DFS-R. Non abilitare il cloud a livelli.
- Verificare che la sincronizzazione sia stata completata e testare la topologia in base alle esigenze.
- Disattivare DFS-R.
- È ora possibile abilitare la suddivisione in livelli cloud in qualsiasi endpoint server in base alle esigenze.
Per altre informazioni, vedere Interoperabilità di Sincronizzazione file di Azure con il file system distribuito.