Istruzioni di avvio rapido: creare un rilevatore di oggetti con il sito Web di Visione personalizzata
Questo argomento di avvio rapido descrive come usare il sito Web di Visione personalizzata per creare un modello di rilevamento oggetti. Dopo aver compilato un modello, è possibile testarlo con nuove immagini e integrarlo nell'app di riconoscimento delle immagini.
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
- Un set di immagini con cui eseguire il training del modello di rilevatore. È possibile usare il set di immagini di esempio in GitHub. In alternativa, è possibile scegliere immagini personalizzate usando i suggerimenti seguenti.
- Un Web browser supportato
Creare risorse di Visione personalizzata
Per usare il servizio Visione personalizzata, è necessario creare le risorse Training visione personalizzata e Previsioni visione personalizzata in Azure. A questo scopo, nel portale di Azure completare la finestra di dialogo nella pagina Create Custom Vision (Crea visione personalizzata) per creare una risorsa di training e di previsione.
Crea un nuovo progetto
Nel Web browser passare alla pagina web Visione personalizzata e selezionare Accedi. Accedere con lo stesso account usato per il portale di Azure.
Per creare il primo progetto, selezionare New Project (Nuovo progetto). Viene visualizzata la finestra di dialogo Crea nuovo progetto.
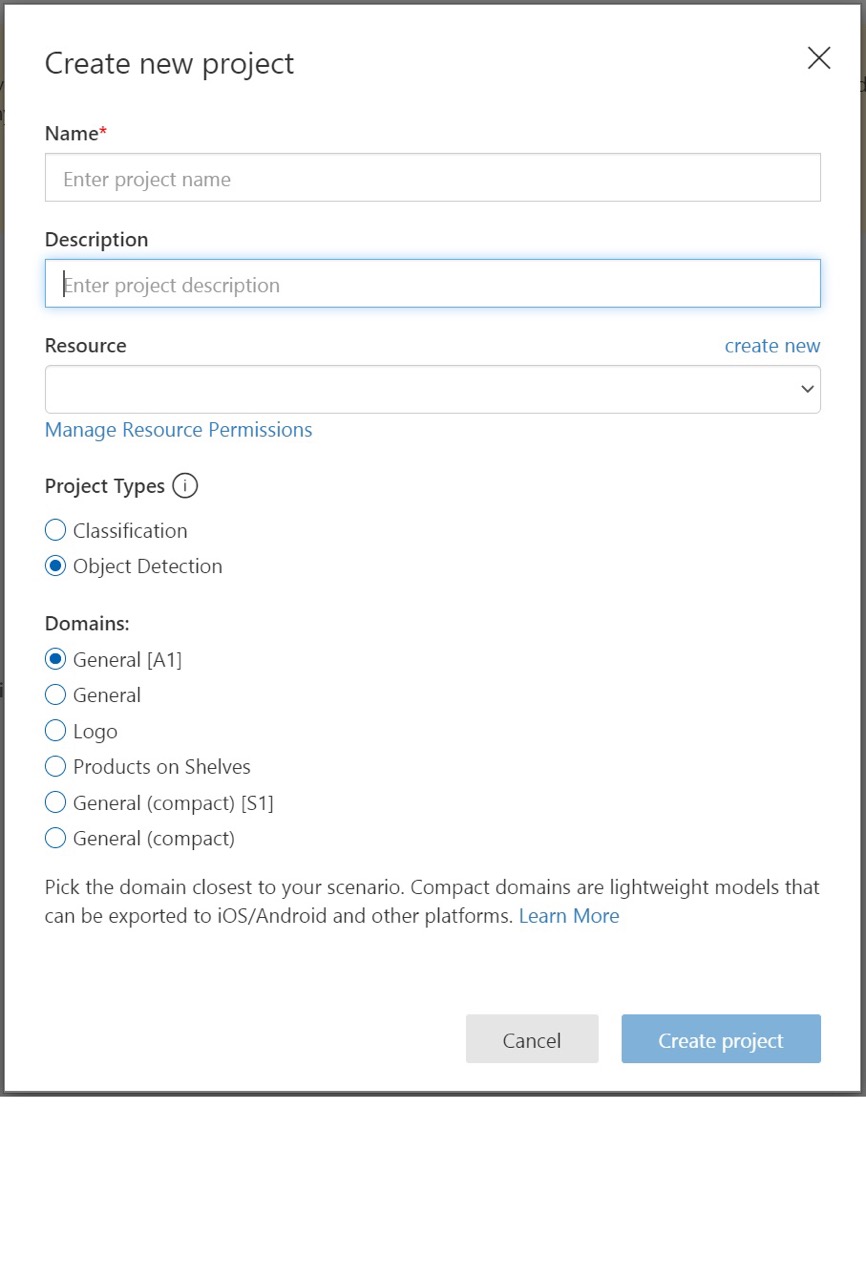
Immettere un nome e una descrizione per il progetto. Selezionare quindi la risorsa di training di Visione personalizzata. Se l'account connesso è associato a un account Azure, l'elenco a discesa Risorsa visualizza tutte le risorse Azure compatibili.
Nota
Se non sono disponibili risorse, verificare di aver eseguito l'accesso a customvision.ai con lo stesso account usato per il portale di Azure. Verificare inoltre di aver selezionato nel sito Web di Visione personalizzata la stessa "Directory" corrispondente alla directory del portale di Azure in cui si trovano le risorse di Visione personalizzata. In entrambi i siti è possibile selezionare la directory nel menu a discesa dell'account nell'angolo superiore destro dello schermo.
Sotto
In Tipi di progetto selezionare Rilevamento oggetti.
Selezionare quindi uno dei domini disponibili. Ogni dominio ottimizza il rilevatore per tipi specifici di immagini, come descritto nella tabella seguente. Se lo si desidera, è possibile modificare il dominio in un secondo momento.
Domain Scopo Generali Ottimizzato per un'ampia gamma di attività di rilevamento oggetti. Se nessuno degli altri domini risulta appropriato o si è in dubbio sul dominio da scegliere, selezionare il dominio Generale. Logo Ottimizzato per il rilevamento di logo dei marchi nelle immagini. Prodotti sugli scaffali Ottimizzato per il rilevamento e la classificazione dei prodotti sugli scaffali. Domini compatti Ottimizzati per i vincoli di rilevamento in tempo reale su dispositivi mobili. I modelli generati da domini compatti possono essere esportati per l'esecuzione in locale. Selezionare infine Crea progetto.
Scegliere le immagini di training
Come minimo, è consigliabile usare almeno 30 immagini per ogni tag nel set di training iniziale. È anche opportuno raccogliere alcune immagini aggiuntive per testare il modello dopo il training.
Per eseguire il training del modello in modo efficace, usare le immagini con diversi oggetti visivi. Selezionare immagini diverse per:
- angolazione
- illuminazione
- background
- stile visivo
- soggetti singoli/raggruppati
- size
- type
Assicurarsi anche che tutte le immagini di training soddisfino i criteri seguenti:
- formato JPG, PNG, BMP o GIF
- dimensioni massime pari a 6 MB (4 MB per le immagini per la previsione)
- almeno 256 pixel sul bordo più corto. Le immagini più piccole verranno automaticamente ingrandite dal Servizio visione artificiale personalizzato
Caricare e contrassegnare le immagini
In questa sezione si caricano e si aggiungono manualmente i tag alle immagini per eseguire il training del rilevatore.
Per aggiungere immagini, selezionare Aggiungi immagini seguito da Esplora file locali. Selezionare Apri per caricare le immagini.
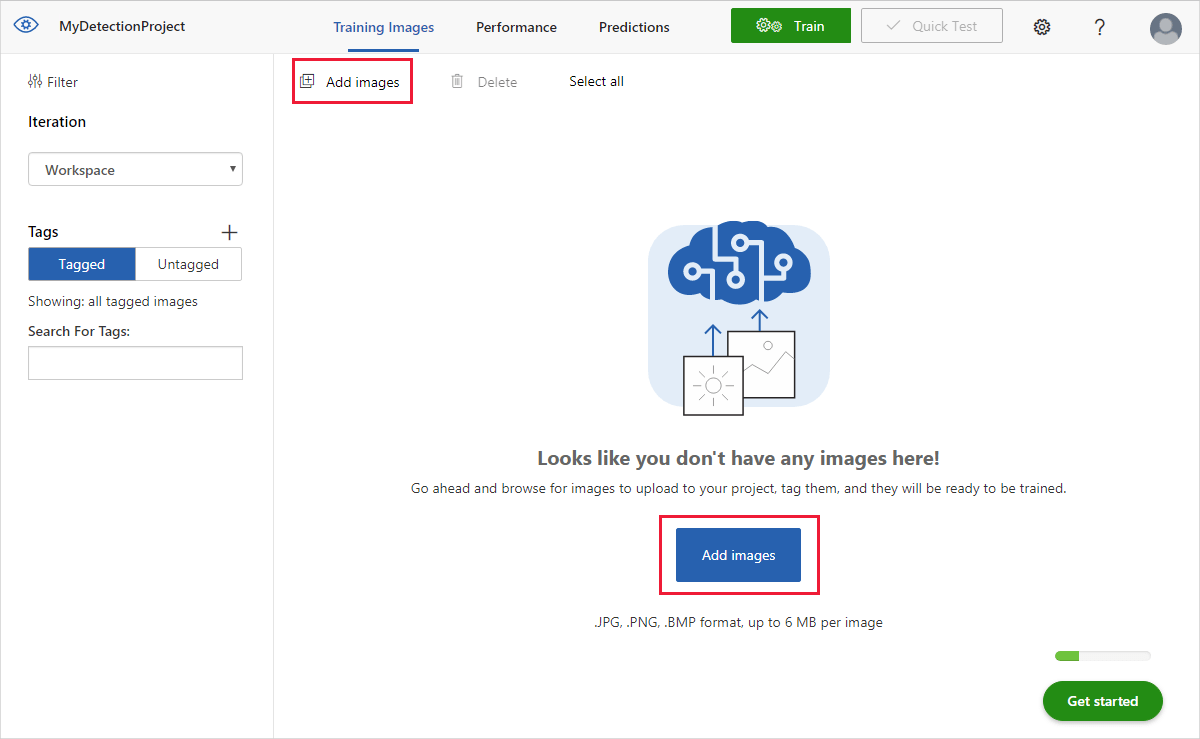
Le immagini caricate verranno visualizzate nella sezione Senza tag dell'interfaccia utente. Il passaggio successivo prevede l'aggiunta manuale dei tag agli oggetti che il rilevatore dovrà riconoscere. Selezionare la prima immagine per aprire la finestra di dialogo per l'aggiunta dei tag.
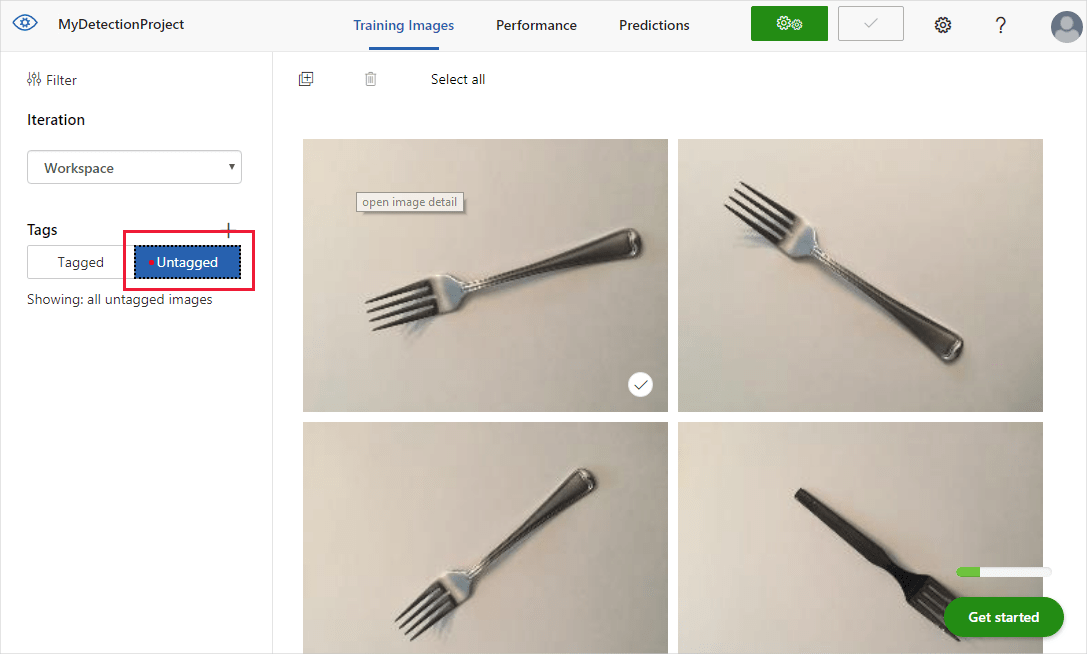
Selezionare e trascinare un rettangolo intorno all'oggetto nell'immagine. Immettere quindi un nuovo nome di tag con il pulsante + oppure selezionare un tag esistente dall'elenco a discesa. È importante aggiungere i tag a ogni istanza degli oggetti che si desidera rilevare, perché il rilevatore usa l'area di sfondo senza tag come esempio negativo durante il training. Dopo aver aggiunto i tag, selezionare la freccia a destra per salvarli e per passare all'immagine successiva.
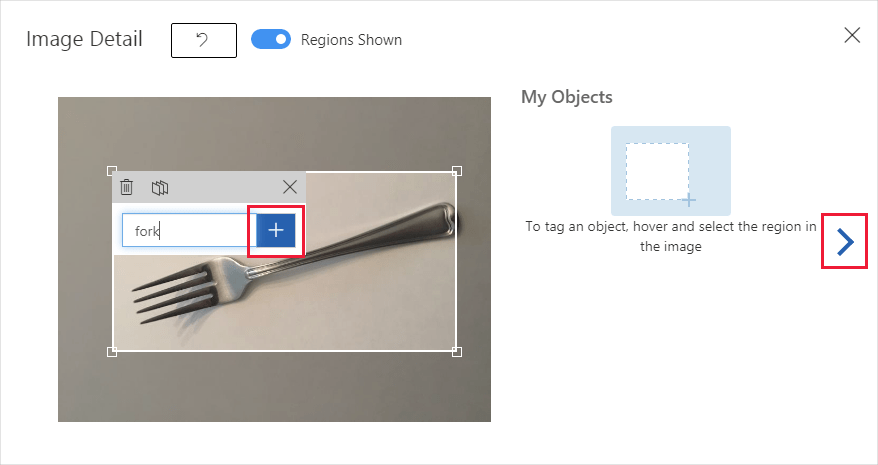
Per caricare un altro set di immagini, tornare all'inizio di questa sezione e ripetere i passaggi.
Eseguire il training del rilevatore
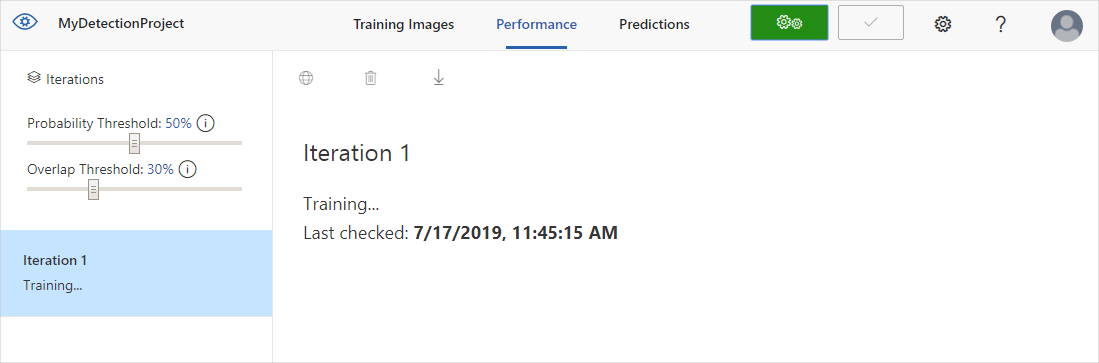
Per eseguire il training del modello di rilevatore, selezionare il pulsante Esegui il training. Il rilevatore usa tutte le immagini correnti e i relativi tag per creare un modello in grado di identificare ogni oggetto con tag. Questo processo può richiedere alcuni minuti.

Il processo di training dovrebbe richiedere solo alcuni minuti. Durante questo periodo, vengono visualizzate informazioni sul processo di training nella scheda Prestazioni.
Valutare il rilevatore
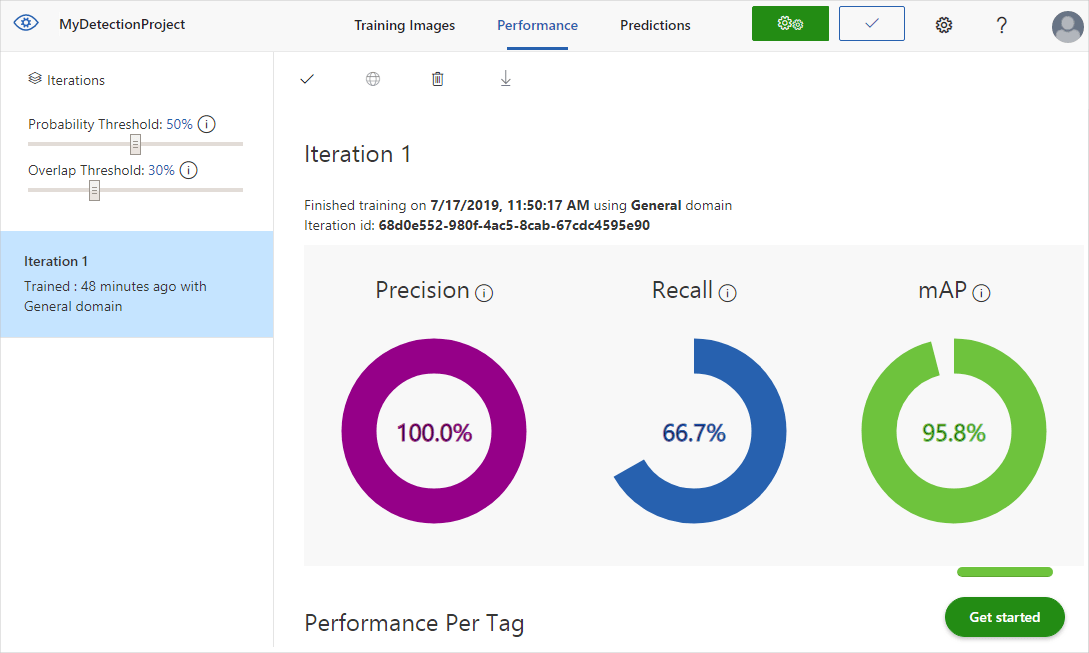
Al termine del training, le prestazioni del modello vengono calcolate e visualizzate. Il servizio Visione personalizzata usa le immagini inviate per il training per calcolare precisione e recupero e precisione media. Precisione e recupero sono due misure diverse dell'efficacia di un rilevatore:
- La precisione indica la frazione delle classificazioni identificate corrette. Se ad esempio il modello identificasse 100 immagini come cani e 99 di essi fossero effettivamente cani, la precisione sarebbe del 99%.
- Il recupero indica la frazione delle classificazioni effettive identificate correttamente. Se ad esempio fossero effettivamente presenti 100 immagini di mele e il modello ne identificasse 80 come mele, il recupero sarebbe dell'80%.
- Mean Average Precision corrisponde al valore medio della precisione media. La precisione media è l'area sotto la curva di precisione/richiamo (precisione tracciata rispetto al richiamo per ogni previsione eseguita).
Soglia di probabilità
Si noti il dispositivo di scorrimento Probability Threshold (Soglia probabilità) nel riquadro sinistro della scheda Prestazioni. Questo è il livello di confidenza che una stima deve avere per essere considerata corretta (ai fini del calcolo della precisione e del richiamo).
Quando si interpretano le chiamate di stima con una soglia di probabilità alta, i risultati restituiti tendono ad avere una precisione elevata a scapito del richiamo, ossia le classificazioni rilevate sono corrette, ma molte rimangono non rilevate. Con una soglia di probabilità bassa avviene l'opposto, ossia viene rilevata la maggior parte delle classificazioni, ma all'interno del set sono presenti più falsi positivi. Tenendo presente questo aspetto, è consigliabile impostare la soglia di probabilità in base alle esigenze specifiche del progetto. In seguito, quando si ricevono i risultati della stima sul lato client, è consigliabile usare lo stesso valore di soglia di probabilità usato qui.
Soglia di sovrapposizione
Il dispositivo di scorrimento della soglia di sovrapposizione gestisce il livello di accuratezza che la previsione di un oggetto deve raggiungere per essere considerata "corretta" nel training. Imposta la sovrapposizione minima consentita tra il rettangolo delimitatore dell'oggetto previsto e il rettangolo delimitatore effettivo immesso dall'utente. Se i rettangoli delimitatori non si sovrappongono a questo livello, la previsione non verrà considerata corretta.
Gestire le iterazioni di training
Ogni volta che si esegue il training del rilevatore, si crea una nuova iterazione con le relative metriche delle prestazioni aggiornate. È possibile visualizzare tutte le iterazioni nel riquadro sinistro della scheda Prestazioni . Nel riquadro sinistro troverai anche il pulsante Elimina , che puoi usare per eliminare un'iterazione se è obsoleta. Quando si elimina un'iterazione, vengono eliminate anche tutte le immagini associate in modo univoco a tale iterazione.
Per informazioni su come accedere ai modelli sottoposti a training a livello di codice, vedere Usare il modello con l'API Previsioni.
Passaggi successivi
In questa esercitazione dell'avvio rapido si è appreso a creare ed eseguire il training di un modello di rilevamento oggetti tramite il sito Web di Visione personalizzata. È ora possibile ottenere altre informazioni sul processo iterativo per migliorare il modello.