Interpretare e migliorare i punteggi di accuratezza dei modelli e di attendibilità dell'analisi
Un punteggio di attendibilità indica la probabilità misurando il grado di certezza statistica che il risultato estratto è rilevato correttamente. L'accuratezza stimata viene calcolata eseguendo alcune combinazioni diverse dei dati di training per prevedere i valori etichettati. Questo articolo illustra come interpretare i punteggi di accuratezza e attendibilità e propone le procedure consigliate per l'uso di tali punteggi per migliorare i risultati.
Punteggi di attendibilità
Nota
- L'attendibilità del livello di campo sta ottenendo l'aggiornamento per tenere conto del punteggio di attendibilità delle parole a partire dalla versione dell'API 2024-07-31-preview per i modelli personalizzati.
- I punteggi di attendibilità per tabelle, righe di tabella e celle di tabella sono disponibili a partire dalla versione API 2024-07-31-preview per i modelli personalizzati.
I risultati dell'analisi di Document Intelligence restituiscono un'attendibilità stimata per parole previste, coppie chiave-valore, segni di selezione, aree e firme. Attualmente, non tutti i campi del documento restituiscono un punteggio di attendibilità.
L'attendibilità dei campi indica una probabilità stimata compresa tra 0 e 1 che la previsione sia corretta. Ad esempio, un valore di attendibilità 0,95 (95%) indica che la previsione è probabilmente corretta 19 volte su 20. Per gli scenari in cui l'accuratezza è critica, è possibile usare l'attendibilità per determinare se accettare automaticamente la stima o contrassegnarla per la revisione umana.
Modello di fattura predefinito analizzato di
Document Intelligence Studio
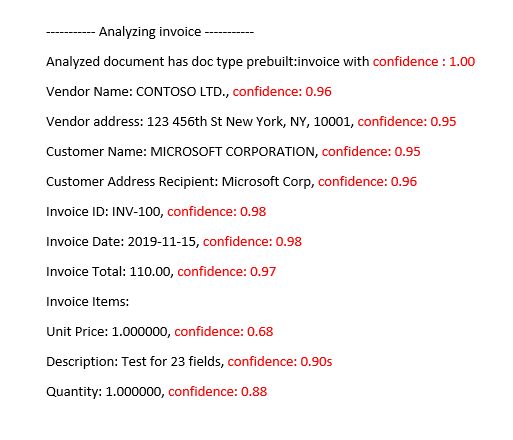
Migliorare i punteggi di attendibilità
Dopo un'operazione di analisi, esaminare l'output JSON. Esaminare i valori di confidence per ogni risultato di chiave-valore nel nodo pageResults. È inoltre consigliabile esaminare il punteggio di attendibilità nel nodo readResults, che corrisponde all'operazione di lettura del testo. L'attendibilità dei risultati della lettura non influisce su quella dei risultati dell'estrazione di coppie chiave-valore, quindi è necessario controllare entrambi. Di seguito sono riportati alcuni suggerimenti:
Se il punteggio di attendibilità per l'oggetto
readResultsè basso, migliorare la qualità dei documenti di input.Se il punteggio di attendibilità per l'oggetto
pageResultsè basso, assicurarsi che i documenti analizzati siano dello stesso tipo.Prendere in considerazione l'incorporazione della revisione umana nei flussi di lavoro.
Usare moduli con valori diversi in ogni campo.
Per i modelli personalizzati, usare un set più ampio di documenti di training. Un set di training più grande insegna al modello di riconoscere i campi con maggiore accuratezza.
Punteggi di accuratezza per i modelli personalizzati
Nota
- I modelli neurali e generativi personalizzati non forniscono punteggi di accuratezza durante il training.
L'output di un'operazione di un modello personalizzato build (v3.0 e successive) o train (v2.1) include il punteggio di accuratezza stimato. Questo punteggio rappresenta la capacità del modello di prevedere accuratamente il valore etichettato in un documento visivamente simile. L'accuratezza viene misurata entro un intervallo di valori percentuale compreso tra 0% (basso) e 100% (alto). È consigliabile mirare a un punteggio dell'80% o superiore. Per casi più sensibili, ad esempio i resoconti finanziari o cartelle cliniche, è consigliabile un punteggio vicino al 100%. È anche possibile aggiungere una fase di revisione umana per convalidare i flussi di lavoro di automazione più critici.
Document Intelligence Studio
Modello personalizzato sottoposto a training (fattura)
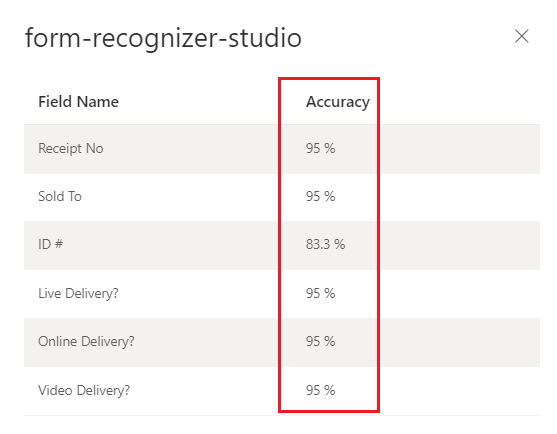
Interpretare i punteggi di accuratezza e attendibilità per i modelli personalizzati
I modelli di modello personalizzato generano un punteggio di accuratezza stimato al momento del training. I documenti analizzati con un modello personalizzato producono un punteggio di attendibilità per i campi estratti. Quando si interpreta il punteggio di attendibilità da un modello personalizzato, è necessario prendere in considerazione tutti i punteggi di attendibilità restituiti dal modello. Iniziamo con un elenco di tutti i punteggi di attendibilità.
- Punteggio di attendibilità del tipo di documento: l'attendibilità del tipo di documento è un indicatore della somiglianza del documento analizzato ai documenti nel set di dati di training. Quando l'attendibilità del tipo di documento è bassa, è indicativa di variazioni di modello o strutturali nel documento analizzato. Per migliorare l'attendibilità del tipo di documento, etichettare un documento con tale variante specifica e aggiungerlo al set di dati di training. Dopo la ripetizione del training del modello, dovrebbe essere meglio equipaggiato per gestire tale classe di varianti.
- Livello di attendibilità del campo: ogni campo etichettato estratto ha un punteggio di attendibilità associato. Questo punteggio riflette l'attendibilità del modello sulla posizione del valore estratto. Durante la valutazione dei punteggi di attendibilità, è consigliabile esaminare anche l'attendibilità dell'estrazione sottostante per generare un'attendibilità completa per il risultato estratto. Valutare i risultati
OCRper l'estrazione del testo o i segni di selezione a seconda del tipo di campo per generare un punteggio di attendibilità composito per il campo. - punteggio di attendibilità di Word Ogni parola estratta all'interno del documento ha un punteggio di attendibilità associato. Il punteggio rappresenta l'attendibilità della trascrizione. La matrice di pagine contiene una matrice di parole e ogni parola ha un punteggio di intervallo e attendibilità associato. Si estende dal campo personalizzato i valori estratti corrispondono agli intervalli delle parole estratte.
- punteggio di attendibilità degli indicatori di selezione: la matrice di pagine contiene anche una matrice degli indicatori di selezione. Ogni indicatore di selezione ha un punteggio di attendibilità che rappresenta l'attendibilità dell'indicatore di selezione e del rilevamento dello stato di selezione. Quando un campo etichettato ha un indicatore di selezione, la selezione del campo personalizzato combinata con l'affidabilità dell'indicatore di selezione è una rappresentazione precisa dell'accuratezza complessiva dell'affidabilità.
La tabella seguente illustra come interpretare i punteggi di accuratezza e attendibilità per misurare le prestazioni di un modello personalizzato.
| Accuratezza | Attendibilità | Risultato |
|---|---|---|
| Elevato | Alta | • Il modello funziona bene con le chiavi etichettate e i formati di documento. • Si dispone di un set di dati di training bilanciato. |
| Alto | Basso | • Il documento analizzato è diverso dal set di dati di training. • Il modello trae vantaggio dalla ripetizione del training con almeno cinque documenti etichettati. • Questi risultati possono anche indicare una variazione di formato tra il set di dati di training e il documento analizzato. È consigliabile aggiungere un nuovo modello. |
| Ridotto | Elevato | • Questo risultato è molto improbabile. • Per i punteggi di accuratezza bassi, aggiungere altri dati etichettati o dividere documenti visivamente distinti in più modelli. |
| Basso | Basso | • Aggiungere altri dati etichettati. • Dividere documenti visivamente distinti in più modelli. |
Garantire un'accuratezza elevata del modello per i modelli personalizzati
Le varianze nella struttura visiva dei documenti influiscono sull'accuratezza del modello. I punteggi di accuratezza segnalati possono non essere coerenti quando i documenti analizzati differiscono dai documenti usati nel training. Tenere presente che un set di documenti può avere un aspetto simile quando viene visualizzato dalle persone, ma sembrare diverso per un modello di intelligenza artificiale. Di seguito è riportato un elenco di procedure consigliate per il training dei modelli con il livello massimo di accuratezza. Seguendo queste linee guida, si dovrebbe produrre un modello con punteggi di accuratezza e attendibilità più alti durante l'analisi, oltre a ridurre il numero di documenti contrassegnati per la revisione umana.
Assicurarsi che tutte le varianti di un documento siano incluse nel set di dati di training. Le varianti includono formati diversi, ad esempio PDF digitali e PDF digitalizzati.
Aggiungere almeno cinque esempi di ogni tipo al set di dati di training se si prevede che il modello analizzi entrambi i tipi di documenti PDF.
Separare tipi di documento visivamente distinti per eseguire il training di modelli diversi per modelli personalizzati e modelli neurali.
- Come regola generale, se si rimuovono tutti i valori immessi dall'utente e i documenti sono simili, è necessario aggiungere altri dati di training al modello esistente.
- Se i documenti sono diversi, dividere i dati di training in cartelle diverse ed eseguire il training di un modello per ogni variante. È quindi possibile comporre le diverse varianti in un unico modello.
Assicurarsi di non avere etichette estranee.
Assicurarsi che l'etichettatura della firma e dell'area non includa il testo circostante.
Attendibilità tra tabelle, righe e celle
Considerata l'aggiunta dell'attendibilità di tabella, riga e cella con l'API 2024-02-29-preview e successive, ecco alcune domande comuni che dovrebbero aiutare a interpretare i punteggi di tabella, riga e cella:
D: è possibile visualizzare un punteggio di attendibilità elevato per le celle, ma un punteggio di attendibilità basso per la riga?
R: Sì. I diversi livelli di attendibilità delle tabelle (cella, riga e tabella) hanno lo scopo di acquisire la correttezza di una stima a quel livello specifico. Una cella stimata correttamente che appartiene a una riga con altri possibili mancati riscontri avrebbe un'elevata attendibilità delle celle, ma l'attendibilità della riga dovrebbe essere bassa. Analogamente, una riga corretta in una tabella con problemi con altre righe avrebbe un'elevata attendibilità di riga, mentre l'attendibilità complessiva della tabella sarebbe bassa.
D: qual è il punteggio di attendibilità previsto quando le celle vengono unite? Poiché un'unione determina il numero di colonne identificate da modificare, come vengono influenzati i punteggi?
R: indipendentemente dal tipo di tabella, l'aspettativa per le celle unite è che debbano avere valori di attendibilità inferiori. Inoltre, la cella mancante (perché è stata fusa con una cella adiacente) dovrebbe avere anche un valore NULL con minore attendibilità. Quanto bassi questi valori possano essere dipende dal set di dati di training e dalla tendenza generale delle celle unite e mancanti con punteggi bassi che deve contenere.
D: qual è il punteggio di attendibilità quando un valore è facoltativo? È consigliabile prevedere una cella con un valore NULL e un punteggio di attendibilità elevato se il valore è mancante?
R: se il set di dati di training è rappresentativo della facoltatività delle celle, consente al modello di conoscere la frequenza con cui un valore tende a essere visualizzato nel set di training e quindi cosa aspettarsi durante l'inferenza. Questa funzionalità viene usata quando si calcola l'attendibilità di una stima o di non eseguire alcuna stima (NULL). È consigliabile prevedere un campo vuoto con attendibilità elevata per i valori mancanti che sono per lo più vuoti anche nel set di training.
D: come influiscono i punteggi di attendibilità se un campo è facoltativo e non è presente o manca? Ci si deve aspettare che il punteggio di attendibilità risponda a tale domanda?
R: quando manca un valore da una riga, alla cella viene assegnato un valore NULL e l'attendibilità. Un punteggio di attendibilità elevato in questo caso dovrebbe significare che la stima del modello (di non avere un valore) è più probabile che sia corretta. Al contrario, un punteggio basso dovrebbe segnalare una maggiore incertezza dal modello (e quindi la possibilità di un errore, come la mancanza del valore).
D: quali dovrebbero essere le aspettative per l'attendibilità delle celle e l'attendibilità delle righe durante l'estrazione di una tabella a più pagine con una riga divisa tra le pagine?
R: aspettarsi che l'attendibilità delle celle sia elevata e che l'attendibilità di riga sia potenzialmente inferiore rispetto alle righe non sono divise. La percentuale di righe suddivise nel set di dati di training può influire sul punteggio di attendibilità. In generale, una riga divisa ha un aspetto diverso rispetto alle altre righe della tabella (quindi, il modello è meno sicuro della sua correttezza).
D: per le tabelle tra pagine con righe che terminano e iniziano in modo pulito nei limiti della pagina, è corretto presupporre che i punteggi di attendibilità siano coerenti tra le pagine?
R: Sì. Poiché le righe hanno un aspetto simile nella forma e nel contenuto, indipendentemente dalla posizione nel documento (o nella pagina), i rispettivi punteggi di attendibilità devono essere coerenti.
D: qual è il modo migliore per usare i nuovi punteggi di attendibilità?
R: esaminare tutti i livelli di confidenza delle tabelle a partire da un approccio dall'alto verso il basso: iniziare controllando l'attendibilità di una tabella nel suo complesso, quindi eseguire il drill-down al livello di riga e esaminare le singole righe, infine esaminare le attendibilità a livello di cella. A seconda del tipo di tabella, è necessario tenere presente alcuni aspetti:
Per le tabelle fisse, l'attendibilità a livello di cella acquisisce già un po' di informazioni sulla correttezza delle cose. Ciò significa che semplicemente passare su ogni cella ed esaminare la sua attendibilità può essere sufficiente per determinare la qualità della stima. Per le tabelle dinamiche, i livelli sono pensati per essere creati l'uno sopra l'altro, quindi l'approccio dall'alto verso il basso è più importante.