Modelli personalizzati di Informazioni sui documenti
Importante
- Le versioni di anteprima pubblica di Informazioni sui documenti consentono l'accesso anticipato alle funzionalità in fase di sviluppo attivo. Le funzionalità, gli approcci e i processi possono cambiare prima della disponibilità generale, a seconda del feedback degli utenti.
- Per impostazione predefinita, la versione di anteprima pubblica delle librerie client di Intelligence dei documenti è la versione dell'API REST 2024-07-31-preview.
- La versione di anteprima pubblica 2024-07-31-preview è al momento disponibile solo nelle aree di Azure seguenti. Si noti che il modello di generazione personalizzata (estrazione di campi di documento) in Studio AI è disponibile solo nell'area Stati Uniti centro-settentrionali:
- Stati Uniti orientali
- Stati Uniti occidentali 2
- Europa occidentale
- Stati Uniti centro-settentrionali
Questo contenuto si applica a: ![]() v4.0 (anteprima) | Versioni precedenti:
v4.0 (anteprima) | Versioni precedenti: ![]() v3.1 (disponibilità generale)
v3.1 (disponibilità generale) ![]() v3.0 (disponibilità generale)
v3.0 (disponibilità generale) ![]() v2.1 (disponibilità generale)
v2.1 (disponibilità generale)
Questo contenuto si applica a: ![]() v3.1 (disponibilità generale) | Versione più recente:
v3.1 (disponibilità generale) | Versione più recente: ![]() v4.0 (anteprima) | Versioni precedenti:
v4.0 (anteprima) | Versioni precedenti: ![]() v3.0
v3.0 ![]() v2.1
v2.1
Questo contenuto si applica a: ![]() v3.0 (disponibilità generale) | Versioni più recenti:
v3.0 (disponibilità generale) | Versioni più recenti: ![]() v4.0 (anteprima)
v4.0 (anteprima) ![]() v3.1 | Versione precedente:
v3.1 | Versione precedente: ![]() v2.1
v2.1
Questo contenuto si applica a: ![]() v2.1 | Versione più recente:
v2.1 | Versione più recente: ![]() v4.0 (anteprima)
v4.0 (anteprima)
Informazioni sui documenti usa una tecnologia avanzata di apprendimento automatico per identificare i documenti, rilevare ed estrarre informazioni da moduli e documenti e restituire i dati estratti in un output JSON strutturato. Con Informazioni sui documenti è possibile usare modelli di analisi dei documenti, predefiniti e già sottoposti a training, oppure i propri modelli personalizzati autonomi e sottoposti a training.
I modelli personalizzati includono ora modelli di classificazione personalizzati per gli scenari in cui è necessario identificare il tipo di documento prima di richiamare il modello di estrazione. I modelli di classificatore sono disponibili a partire dall'API 2023-07-31 (GA). Un modello di classificazione può essere associato a un modello di estrazione personalizzato per analizzare ed estrarre campi da moduli e documenti specifici dell'azienda. I modelli di estrazione personalizzati autonomi possono essere combinati per creare modelli composti.
Tipi di modelli di documento personalizzati
I modelli di documento personalizzati possono essere uno di due tipi: modello personalizzato o modulo personalizzato e modelli neurali personalizzati o modelli di documento personalizzati. Il processo di etichettatura e training per entrambi i modelli è identico, ma i modelli differiscono come segue:
Modelli di estrazione personalizzati
Per creare un modello di estrazione personalizzato, etichettare un set di dati di documenti con i valori da estrarre ed eseguire il training del modello sul set di dati etichettato. Per iniziare, sono necessari solo cinque esempi dello stesso tipo di modulo o documento.
Modello neurale personalizzato
Importante
A partire dall'API versione 4.0, ovvero 2024-02-29-preview, i modelli neurali personalizzati supportano ora campi sovrapposti e attendibilità a livello di tabella, riga e cella.
Il modello neurale personalizzato (documento personalizzato) usa modelli di Deep Learning e il modello di base sottoposto a training su un'ampia raccolta di documenti. Questo modello viene quindi ottimizzato o adattato ai dati quando viene sottoposto a training con un set di dati etichettati. I modelli neurali personalizzati supportano l'estrazione di campi di dati chiave da documenti strutturati, semistrutturati e non strutturati. Per scegliere tra i due tipi di modello, iniziare con un modello neurale per determinare se supporta le proprie esigenze funzionali. Per altre informazioni sui modelli di documento personalizzati, vedere modelli neurali.
Modello personalizzato
Il modello personalizzato o modello di modulo personalizzato si basa su un modello visivo coerente per estrarre i dati etichettati. Le varianze nella struttura visiva dei documenti influiscono sull'accuratezza del modello. I moduli strutturati, come questionari o richieste, sono esempi di modelli visivi coerenti.
Il set di training è costituito da documenti strutturati in cui la formattazione e il layout sono statici e costanti da un'istanza del documento alla successiva. I modelli personalizzati supportano coppie chiave-valore, segni di selezione, tabelle, campi di firma e aree. I modelli possono essere sottoposti a training su documenti in qualsiasi lingua supportata. Per altre informazioni, vedere Modelli personalizzati.
Se il linguaggio dei documenti e degli scenari di estrazione supporta modelli neurali personalizzati, è consigliabile usare modelli neurali personalizzati rispetto ai modelli per un'accuratezza più elevata.
Suggerimento
Per verificare che i documenti di training presentino un modello visivo coerente, rimuovere tutti i dati immessi dall'utente da ogni modulo del set. Se i moduli vuoti sono identici nell'aspetto, rappresentano un modello visivo coerente.
Per altre informazioni, vedere Interpretare e migliorare l'accuratezza e l'attendibilità dei modelli personalizzati.
Requisiti di input
Per risultati ottimali, fornire una foto chiara o una scansione di alta qualità per ogni documento.
Formati di file supportati:
Modello PDF Immagine: jpeg/jpg,png,bmp,tiff,heifMicrosoft Office:
Word (docx), Excel (xlsx), PowerPoint (pptx)Lettura ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview e versioni successive) Documento generale ✔ ✔ Predefinito ✔ ✔ Estrazione personalizzata ✔ ✔ Classificazione personalizzata ✔ ✔ ✔ ✱ i file di Microsoft Office non sono attualmente supportati per altri modelli o versioni.
Per i formati PDF e TIFF, possono essere elaborate fino a 2.000 pagine (con una sottoscrizione di livello gratuito vengono elaborate solo le prime due pagine).
La dimensione del file per l'analisi dei documenti è di 500 MB per il livello a pagamento (S0) e 4 MB per il livello gratuito (F0).
Per le immagini, le dimensioni devono essere comprese tra 50 x 50 pixel e 10.000 x 10.000 pixel.
Se i file PDF sono bloccati da password, è necessario rimuovere il blocco prima dell'invio.
L'altezza minima del testo da estrarre è di 12 pixel per un'immagine 1024 x 768 pixel. Queste dimensioni corrispondono approssimativamente a un testo con dimensioni di
8punti e 150 punti per pollice.Per il training di modelli personalizzati, il numero massimo di pagine per i dati di training è 500 per il modello personalizzato e 50.000 per il modello neurale personalizzato.
Per il training di modelli di estrazione personalizzati, le dimensioni totali dei dati di training sono di 50 MB per il modello e 1G MB per il modello neurale.
Per il training del modello di classificazione personalizzato, le dimensioni totali dei dati di training sono
1GBcon un massimo di 10.000 pagine.
Dati di training ottimali
I dati di input di training sono la base di qualsiasi modello di Machine Learning. Determina la qualità, l'accuratezza e le prestazioni del modello. Di conseguenza, è fondamentale creare i dati di input di training migliori possibili per il progetto di Intelligence sui documenti. Quando si usa il modello personalizzato di Informazioni sui documenti, si forniscono dati di training personalizzati. Ecco alcuni suggerimenti per eseguire in modo efficace il training dei modelli:
Usare file PDF basati su testo anziché basati su immagini, quando possibile. Un modo per identificare un PDF basato su immagini consiste nel provare a selezionare testo specifico nel documento. Se è possibile selezionare solo l'intera immagine del testo, il documento è basato su immagini, non basato su testo.
Organizzare i documenti di training usando una sottocartella per ogni formato (JPEG/JPG, PNG, BMP, PDF o TIFF).
Usare moduli con tutti i campi disponibili completati.
Usare moduli con valori diversi in ogni campo.
Se le immagini sono di bassa qualità, usare un set di dati più grande, ovvero più di cinque documenti di training.
Determinare se è necessario usare un singolo modello o più modelli composti in un singolo modello.
Pianificare la segmentazione del set di dati in cartelle, in cui ogni cartella corrisponde a un modello univoco. Eseguire il training di un modello per cartella e comporre i modelli risultanti in un singolo endpoint. L'accuratezza del modello può diminuire quando vengono analizzati formati diversi con un singolo modello.
Se il modulo presenta variazioni con formati e interruzioni di pagina, valutare la possibilità di segmentare il set di dati per eseguire il training di più modelli. I moduli personalizzati si basano su un modello di oggetto visivo coerente.
Assicurarsi di avere un set di dati bilanciato tenendo conto di formati, tipi di documento e struttura.
Modalità compilazione
L'operazione build custom model aggiunge il supporto per i modelli personalizzati di tipo modello e neurale. Le versioni precedenti dell'API REST e delle librerie client supportano solo una singola modalità di compilazione ora nota come modalità modello.
I modelli accettano solo documenti con la stessa struttura di pagina di base, con un aspetto visivo uniforme, oppure con lo stesso posizionamento di elementi all'interno.
I modelli neurali supportano documenti con le stesse informazioni, ma con strutture di pagina diverse. Gli esempi di questi documenti includono moduli W2 degli Stati Uniti, che condividono le stesse informazioni, ma variano a livello di aspetto tra le aziende.
Questa tabella fornisce collegamenti ai riferimenti e agli esempi di codice dell'SDK del linguaggio di programmazione in modalità di compilazione in GitHub:
| Linguaggio di programmazione | Informazioni di riferimento sugli SDK | Esempio di codice |
|---|---|---|
| C#/.NET | DocumentBuildMode Struct | Sample_BuildCustomModelAsync.cs |
| Java | DocumentBuildMode Class | BuildModel.java |
| JavaScript | DocumentBuildMode type | buildModel.js |
| Python | DocumentBuildMode Enum | sample_build_model.py |
Confronto tra le funzionalità dei modelli
La tabella seguente contiene un confronto tra le funzionalità dei modelli personalizzati e dei modelli neurali personalizzati:
| Funzionalità | Modello personalizzato (modulo) | Modello neurale personalizzato (documento) |
|---|---|---|
| Struttura del documento | Modello, modulo e strutturato | Strutturato, semistrutturato e non strutturato |
| Tempo di addestramento | 1-5 minuti | 20 minuti-1 ora |
| Estrazione dei dati | Coppie chiave-valore, tabelle, segni di selezione, coordinate e firme | Coppie chiave-valore, segni di selezione e tabelle |
| Campi sovrapposti | Non supportato | Supportato |
| Varianti di documenti | Richiede un modello per ogni variante | Usa un singolo modello per tutte le varianti |
| Supporto di versioni in lingue diverse | Modello personalizzato supporto per la lingua | Sistema neurale personalizzato supporto per la lingua |
Modello di classificazione personalizzato
La classificazione dei documenti è un nuovo scenario supportato da Informazioni sui documenti con l'API 2023-07-31 (v3.1 disponibilità generale). L'API del classificatore di documenti supporta scenari di classificazione e divisione. Eseguire il training di un modello di classificazione per identificare i diversi tipi di documenti supportati dall'applicazione. Il file di input per il modello di classificazione può contenere più documenti e classifica ogni documento all'interno di un intervallo di pagine associato. Per altre informazioni, vedere modelli di classificazione personalizzati.
Nota
A partire dalla versione dell'API 2024-02-29-preview, la classificazione di documenti supporta ora i tipi di documento di Office per la classificazione. Questa versione dell'API introduce anche il training incrementale per il modello di classificazione.
Strumenti per modelli personalizzati
I modelli di Informazioni sui documenti v3.1 e versioni successive supportano gli strumenti, le applicazioni e le librerie, i programmi e le librerie seguenti:
| Funzionalità | Risorse | Model ID |
|---|---|---|
| Modello personalizzato | • Document Intelligence Studio • API REST • C# SDK • Python SDK |
custom-model-id |
Ciclo di vita del modello personalizzato
Il ciclo di vita di un modello personalizzato dipende dalla versione dell'API usata per eseguirne il training. Se la versione dell'API è una versione disponibile a livello generale, il modello personalizzato ha lo stesso ciclo di vita di tale versione. Quando la versione dell'API viene deprecata, il modello non è più disponibile per l'inferenza. Se la versione dell'API è una versione disponibile di anteprima, il modello personalizzato ha lo stesso ciclo di vita della versione di anteprima dell’API.
Informazioni sui documenti v2.1 supporta gli strumenti, le applicazioni e le librerie seguenti:
Nota
I tipi di modello personalizzati, neurale personalizzato e modello personalizzato, sono disponibili con le API di Informazioni sui documenti versione 3.1 e v3.0.
| Funzionalità | Risorse |
|---|---|
| Modello personalizzato | • Strumento di etichettatura di Informazioni sui documenti • API REST • SDK della libreria client • Contenitore Docker di Informazioni sui documenti |
Creare un modello personalizzato
Estrarre dati da documenti specifici o univoci usando modelli personalizzati. Sono necessarie le risorse seguenti:
Una sottoscrizione di Azure. È possibile crearne uno gratuitamente.
Un'istanza di Informazioni sui documenti nel portale di Azure. Per provare il servizio, è possibile usare il piano tariffario gratuito (
F0). Dopo la distribuzione della risorsa, selezionare Vai alla risorsa per recuperare la chiave e l'endpoint.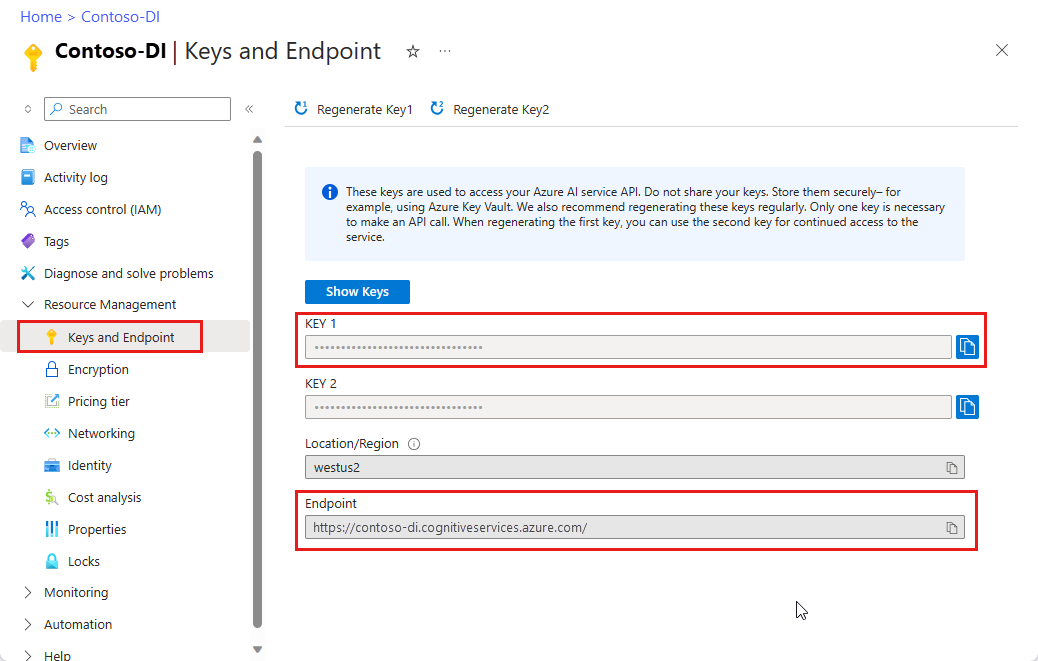
Strumento di etichettatura di esempio
Suggerimento
- Per un'esperienza e una qualità avanzate del modello, provare Document Intelligence v3.0 Studio.
- Studio v3.0 supporta qualsiasi modello sottoposto a training con dati con etichette v2.1.
- Per informazioni dettagliate sulla migrazione da v2.1 a v3.0, vedere la Guida alla migrazione delle API.
- Vedere l'API REST o C#, Java, JavaScript o Python SDK. /quickstarts per iniziare a usare la versione 3.0.
Lo Strumento di etichettatura campioni di Informazioni sui documenti è uno strumento open source che consente di testare le funzionalità più recenti di Informazioni sui documenti e riconoscimento ottico dei caratteri (OCR).
Per iniziare a creare e usare modelli personalizzati, seguire la guida di avvio rapido dello strumento di etichettatura di esempio.
Document Intelligence Studio
Nota
Document Intelligence Studio è disponibile con le API v3.1 e v3.0.
Nella home page di Document Intelligence Studio selezionare Modelli di estrazione personalizzati.
In Progetti personali selezionare Crea un progetto.
Completare i campi dei dettagli del progetto.
Configurare la risorsa del servizio aggiungendo i valori per Account di archiviazione e Contenitore BLOB per connettere l'origine dati di training.
Rivedere e creare il progetto.
Aggiungere i documenti di esempio per etichettare, compilare e testare il modello personalizzato.
Per una procedura dettagliata su come creare il primo modello di estrazione personalizzato, vedere Come creare un modello di estrazione personalizzato.
Riepilogo dell'estrazione di modelli personalizzati
Questa tabella contiene un confronto tra le aree di estrazione di dati supportate:
| Modello | Campi del modulo | Opzioni di selezione | Campi strutturati (tabelle) | Firma | Etichettatura di aree | Campi sovrapposti |
|---|---|---|---|---|---|---|
| Modello personalizzato | ✔ | ✔ | ✔ | ✔ | ✔ | n/d |
| Neurale personalizzato | ✔ | ✔ | ✔ | n/d | * | ✔ (2024-02-29-preview) |
Simboli di tabella:
✔ - Supportato
**n/d - Attualmente non disponibile.
* - Si comporta in modo diverso a seconda del modello. Con i modelli i dati sintetici vengono generati in fase di training. Con i modelli neurali viene selezionato il testo in uscita riconosciuto nell'area.
Suggerimento
Per scegliere tra i due tipi di modello, iniziare con un modello neurale personalizzato per determinare se supporta le proprie esigenze funzionali. Per altre informazioni, vedere Modelli neurali personalizzati.
Opzioni di sviluppo di modelli personalizzati
La tabella seguente descrive le funzionalità disponibili con le librerie client e gli strumenti associati. Come procedura consigliata, assicurarsi di usare gli strumenti compatibili elencati qui.
| Tipo di documento | REST API | SDK | Etichettare e testare i modelli |
|---|---|---|---|
| Modello personalizzato v 4.0 v3.1 v3.0 | Informazioni sui documenti 3.1 | SDK di Informazioni sui documenti | Document Intelligence Studio |
| Neurale personalizzato v4.0 v3.1 v3.0 | Informazioni sui documenti 3.1 | SDK di Informazioni sui documenti | Document Intelligence Studio |
| Modulo personalizzato v2.1 | API di Informazioni sui documenti 2.1 (disponibilità generale) | SDK di Informazioni sui documenti | Strumento di etichettatura campioni |
Nota
I modelli personalizzati sottoposti a training con l'API 3.0 presentano alcuni miglioramenti rispetto all'API 2.1 derivanti dai miglioramenti apportati al motore OCR. I set di dati usati per il training di un modello personalizzato usando l'API 2.1 possono comunque essere usati per il training di un nuovo modello usando l'API 3.0.
Per risultati ottimali, fornire una foto chiara o una scansione di alta qualità per ogni documento.
I formati di file supportati sono JPEG/JPG, PNG, BMP, TIFF e PDF (testo incorporato o digitalizzato). I documenti PDF con testo incorporato sono i più adatti per evitare ogni possibilità di errore nell'estrazione e individuazione dei caratteri.
Per i file PDF e TIFF, è possibile elaborare fino a 2.000 pagine. Con una sottoscrizione del livello gratuito vengono elaborate solo le prime due pagine.
Le dimensioni del file devono essere inferiori a 500 MB per il livello a pagamento (S0) e 4 MB per il livello gratuito (F0).
Per le immagini, le dimensioni devono essere comprese tra 50 x 50 pixel e 10.000 x 10.000 pixel.
Le dimensioni dei file PDF possono essere al massimo di 17 x 17 pollici, corrispondenti a formati di carta Legal o A3 o inferiori.
Le dimensioni totali dei dati di training non devono superare le 500 pagine.
Se i file PDF sono bloccati da password, è necessario rimuovere il blocco prima dell'invio.
Suggerimento
Dati di training:
- Se possibile, utilizza documenti PDF basati su testo anziché documenti basati su immagini. I PDF sottoposti a scansione vengono gestiti come immagini.
- Specificare solo una singola istanza del modulo per ogni documento.
- Per i moduli compilati, usare esempi con tutti i campi compilati.
- Usa moduli con valori diversi in ogni campo.
- Se le immagini del modulo sono di qualità inferiore, usare un set di dati più grande, ad esempio, usare 10-15 immagini.
Lingue e impostazioni locali supportate
Vedere la pagina Lingue supportate - Modelli personalizzati per un elenco completo delle lingue supportate.
Passaggi successivi
Provare a elaborare moduli e documenti personalizzati con lo Strumento di etichettatura campioni di Informazioni sui documenti.
Completare un avvio rapido di Informazioni sui documenti e iniziare a creare un'app per l'elaborazione di documenti nel linguaggio di sviluppo preferito.
Provare a elaborare moduli e documenti personalizzati con Document Intelligence Studio.
Completare l'avvio rapido di Informazioni sui documenti e iniziare a creare un'app per l'elaborazione documenti nel linguaggio di sviluppo preferito.