Eseguire il training del modello di comprensione del linguaggio di conversazione
Dopo aver completato l'etichettatura delle espressioni, è possibile avviare il training di un modello. Il training è il processo in cui il modello apprende dalle espressioni etichettate.
Per eseguire il training di un modello, avviare un processo di training. Solo i processi completati correttamente creano un modello. I processi di training scadono dopo sette giorni e non sarà possibile recuperare i dettagli dei processi dopo questa scadenza. Se il processo di training è stato completato correttamente ed è stato creato un modello, tale modello non è interessato dalla scadenza del processo. È possibile eseguire un solo processo di training alla volta e non è possibile avviare altri processi nello stesso progetto.
Il training può richiedere da pochi secondi, quando si gestiscono progetti semplici, fino a un paio d’ore, quando si raggiunge il limite massimo di espressioni.
La valutazione del modello viene attivata automaticamente dopo che è stato eseguito il training correttamente. Il processo di valutazione inizia usando il modello sottoposto a training per l’esecuzione delle stime sulle espressioni nel set di test, poi prosegue con il confronto dei risultati stimati con le etichette fornite (per stabilire una baseline di verità).
Prerequisiti
- Un progetto creato correttamente con un account di archiviazione BLOB di Azure configurato
- Espressioni etichettate
Bilanciare i dati per eseguire il training
Quando si tratta di dati di training, tentare di mantenere lo schema ben bilanciato. L’inclusione di grandi quantità di dati di una singola finalità e minori quantità di un’altra finalità comporta una distorsione del modello verso determinate finalità.
Per risolvere questo scenario, potrebbe essere necessario eseguire il sottocampionamento del set di training. Oppure potrebbe essere necessario aggiungerlo. Per eseguire il sottocampionamento, è possibile:
- Eliminare una determinata percentuale dei dati di training in modo casuale.
- Analizzare il set di dati e rimuovere voci duplicate sovrarappresentata, che è un modo più sistematico.
Per aggiungere al set di training, in Language Studio, nella scheda Etichettatura dati selezionare Suggerisci espressioni. Comprensione del linguaggio di conversazione invia quindi una chiamata ad Azure OpenAI per generare espressioni simili.

È inoltre consigliabile ricercare "criteri" non previsti nel set di training. Ad esempio, verificare se il set di training per una determinata finalità è tutto in minuscolo o inizia con una frase specifica. In questi casi, il modello di cui si esegue il training potrebbe apprendere le distorsioni non previste nel set di training anziché eseguire la generalizzazione.
È consigliabile introdurre la diversità di maiuscole/minuscole e di punteggiatura nel set di training. Se si prevede la gestione delle variazioni da parte del modello, assicurarsi di disporre di un set di training che rifletta anche tale diversità. Ad esempio, includere alcune espressioni con in maiuscole/minuscole e altre tutte in lettere minuscole.
Separazione dei dati
Prima di iniziare il processo di training, le espressioni etichettate nel progetto vengono divise in un set di training e un set di test. Ognuno svolge una funzione diversa. Il set di training viene usato nel training del modello ed è il set da cui il modello apprende le espressioni etichettate. Il set di test è un set cieco che non viene introdotto nel modello durante il training, ma solo durante la valutazione.
Una volta eseguito il training del modello correttamente, è possibile usare il modello per eseguire stime dalle espressioni nel set di test. Tali stime vengono usate per calcolare metriche di valutazione. È preferibile accertarsi che tutti le finalità e le entità siano adeguatamente rappresentate sia nel set di training che nel set di test.
La comprensione del linguaggio di conversazione supporta due metodi per la suddivisione dei dati:
- Divisione automatica del set di test dai dati di training: il sistema dividerà i dati con tag tra il set di training e il set di test in base alle percentuali scelte dall’utente. La divisione percentuale consigliata è l'80% per il training e il 20% per i test.
Nota
Se si sceglie l'opzione Divisione automatica del set di test dai dati di training, solo i dati assegnati al set di training verranno divisi in base alle percentuali specificate.
- Usa una divisione manuale dei dati di training e di test: questo metodo consente agli utenti di definire a quale set devono appartenere le espressioni. Questo passaggio è abilitato solo se sono state aggiunte espressioni al set di test durante l’etichettatura.
Modalità di training
La CLU supporta due modalità per il training dei modelli
Il training standard usa algoritmi di apprendimento automatico veloci per eseguire il training dei modelli in modo relativamente rapido. Questa opzione è attualmente disponibile solo per l'inglese ed è disabilitata per i progetti che non usano l'inglese (Stati Uniti) o l'inglese (Regno Unito) come lingua principale. Questa opzione di training è gratuita. Il training standard consente di aggiungere espressioni e testarle rapidamente in modo gratuito. I punteggi di valutazione visualizzati dovrebbero essere utili per stabilire dove apportare modifiche nel progetto e aggiungere altre espressioni. Dopo aver eseguito l'iterazione alcune volte e aver apportato miglioramenti incrementali, è possibile prendere in considerazione l'uso del training avanzato per eseguire il training di un'altra versione del modello.
Il training avanzato usa la tecnologia di apprendimento automatico più recente per personalizzare i modelli con i dati. Ciò dovrebbe mostrare punteggi di prestazioni migliori per i modelli e consentirà anche di usare le funzionalità multilingue della CLU. Il training avanzato ha un prezzo differente. Per informazioni dettagliate, vedere le informazioni sui prezzi.
Usare i punteggi di valutazione per guidare le decisioni. Potrebbero verificarsi dei casi in un cui un esempio specifico viene stimato in modo non corretto nel training avanzato rispetto a quando è stata usata la modalità di training standard. Tuttavia, se i risultati complessivi della valutazione sono migliori usando il training avanzato, è consigliabile usare il modello finale. Se questo non è il caso e non si intende usare funzionalità multilingue, è possibile continuare a usare il modello sottoposto a training con la modalità standard.
Nota
Si dovrebbe vedere una differenza nei comportamenti nei punteggi di attendibilità delle finalità tra le modalità di training, in quanto ogni algoritmo calibra i punteggi in modo diverso.
Eseguire il training del modello
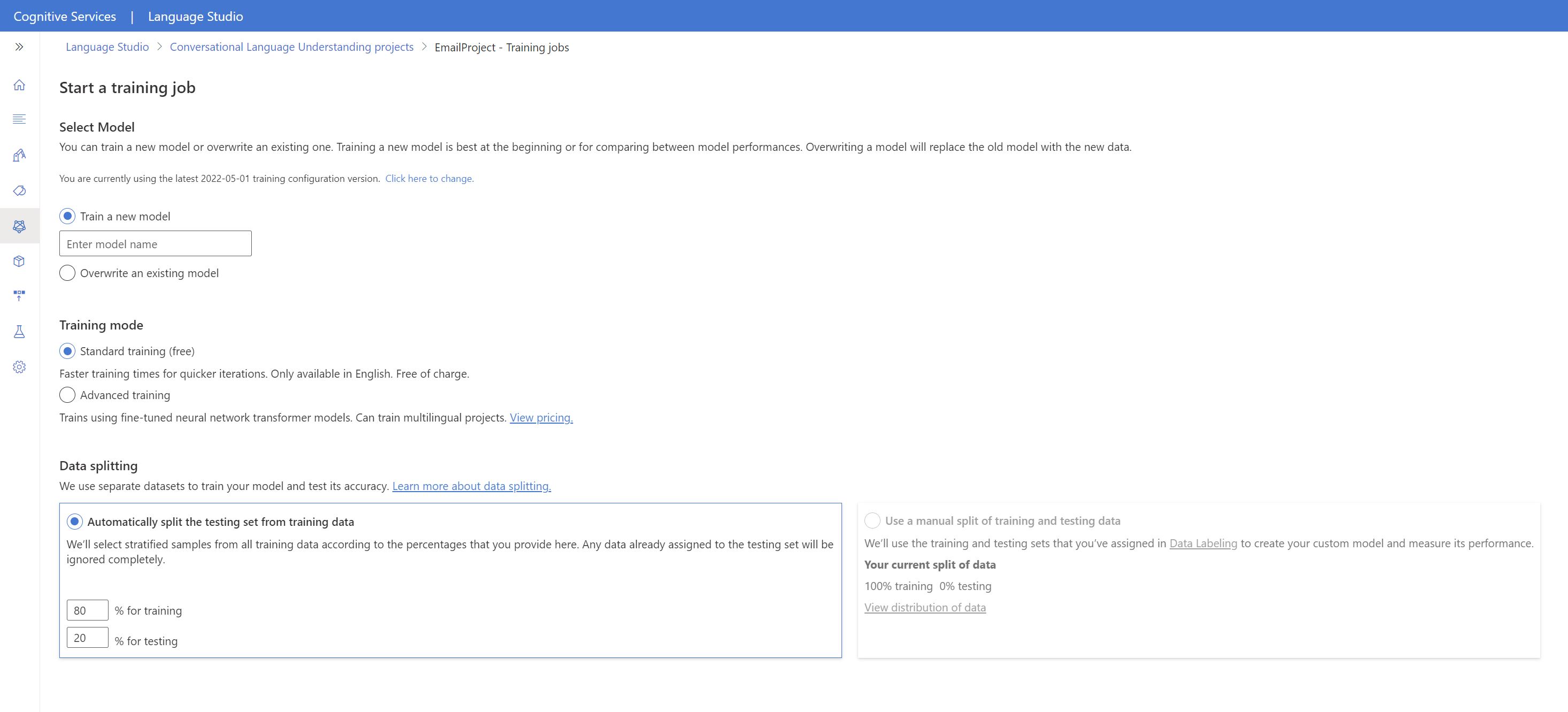
Per avviare il training del modello da Studio di linguaggio:
Selezionare Esegui training del modello nel menu a sinistra.
Selezionare Avvia un processo di training nel menu in alto.
Selezionare Esegui training di un nuovo modello e digitare il nome di un modello nuovo nella casella di testo. In alternativa, per sostituire un modello esistente con uno sottoposto a training sui nuovi dati, selezionare Sovrascrivi un modello esistente e poi selezionare un modello esistente. La sovrascrittura di un modello sottoposto a training è irreversibile, ma non influisce sui modelli distribuiti fino a quando non si distribuisce il nuovo modello.
Selezionare la modalità di training. È possibile scegliere Training standard per un training più rapido; anche se è disponibile solo in inglese. In alternativa, è possibile scegliere Training avanzato, che supporta altre lingue e progetti multilingue, ma comporta tempi di training più lunghi. Altre informazioni sulle modalità di training.
Selezionare il metodo di divisione dei dati. È possibile scegliere Divisione automatica del set di test dai dati di training: il sistema dividerà le espressioni tra il set di training e il set di test in base alle percentuali specificate. In alternativa, è possibile scegliere l’opzione Usa una divisione manuale dei dati di training e di testing che è abilitata solo se sono state aggiunte espressioni al set di test durante l’etichettatura delle espressioni.
Selezionare il pulsante Esegui il training.
Selezionare l'ID processo di training dall'elenco. Sarà visualizzato un riquadro in cui è possibile verificare lo stato del training, lo stato del processo e altri dettagli sul processo.
Nota
- Solo i processi di training completati correttamente genereranno modelli.
- Il training può richiedere da un paio di minuti a un paio d’ore, in base al numero di espressioni.
- È possibile eseguire un solo processo di training alla volta. Non è possibile avviare altri processi di training nello stesso progetto fino al completamento del processo in esecuzione.
- L'apprendimento automatico usato per eseguire il training dei modelli viene aggiornato regolarmente. Per eseguire il training su una precedente versione di configurazione selezionare Selezionare qui per modificare nella pagina Avvia un processo di training e scegliere una versione precedente.

Annulla processo di training
Per annullare un processo di training da Studio di linguaggio
- Nella pagina Esegui training modello selezionare il processo di training da annullare e selezionare Annulla nel menu in alto.