Istruzioni di avvio rapido: comprensione del linguaggio di conversazione
Leggere questo articolo per iniziare a usare Comprensione del linguaggio di conversazione con Studio di linguaggio e l'API REST. Seguire questa procedura per provare un esempio.
Prerequisiti
- Sottoscrizione di Azure: creare un account gratuito.
Accedere a Studio di linguaggio
Passare a Language Studio e accedere con l'account Azure.
Nella finestra Selezionare una risorsa Lingua visualizzata individuare la sottoscrizione di Azure e selezionare la risorsa Linguaggio. Se non si ha una risorsa, è possibile crearne una nuova.
Dettagli dell'istanza Valore obbligatorio Sottoscrizione di Azure La sottoscrizione di Azure. Gruppo di risorse di Azure Nome di gruppo di risorse di Azure. Nome risorsa di Azure Nome della risorsa di Azure. Ufficio Una delle regioni supportate per la risorsa Linguaggio. Ad esempio: "Stati Uniti occidentali 2". Piano tariffario Uno dei piani tariffarivalidi per la risorsa Linguaggio. Per provare il servizio, è possibile usare il piano tariffario gratuito (F0). 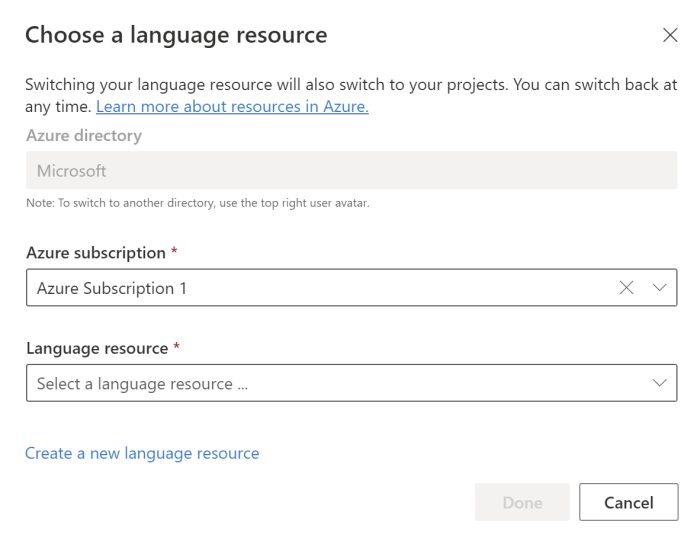

Creare un progetto di comprensione del linguaggio di conversazione
Dopo aver selezionato una risorsa Linguaggio, creare un progetto di comprensione del linguaggio di conversazione. Un progetto è un'area di lavoro per la creazione di modelli di Machine Learning personalizzati sulla base dei propri dati. Al progetto può accedere solo l'utente e altri utenti che hanno accesso alla risorsa di Linguaggio usata.
Per queste istruzioni di avvio rapido, è possibile scaricare questo file di progetto di esempio e importarlo. Questo progetto è in grado di stimare i comandi previsti dall'input dell'utente, ad esempio la lettura e l'eliminazione di e-mail e l'allegare un documento a un'e-mail.
In Studio del linguaggio nella sezione Comprendere le domande e il linguaggio di conversazioneselezionare Comprensione del linguaggio di conversazione.
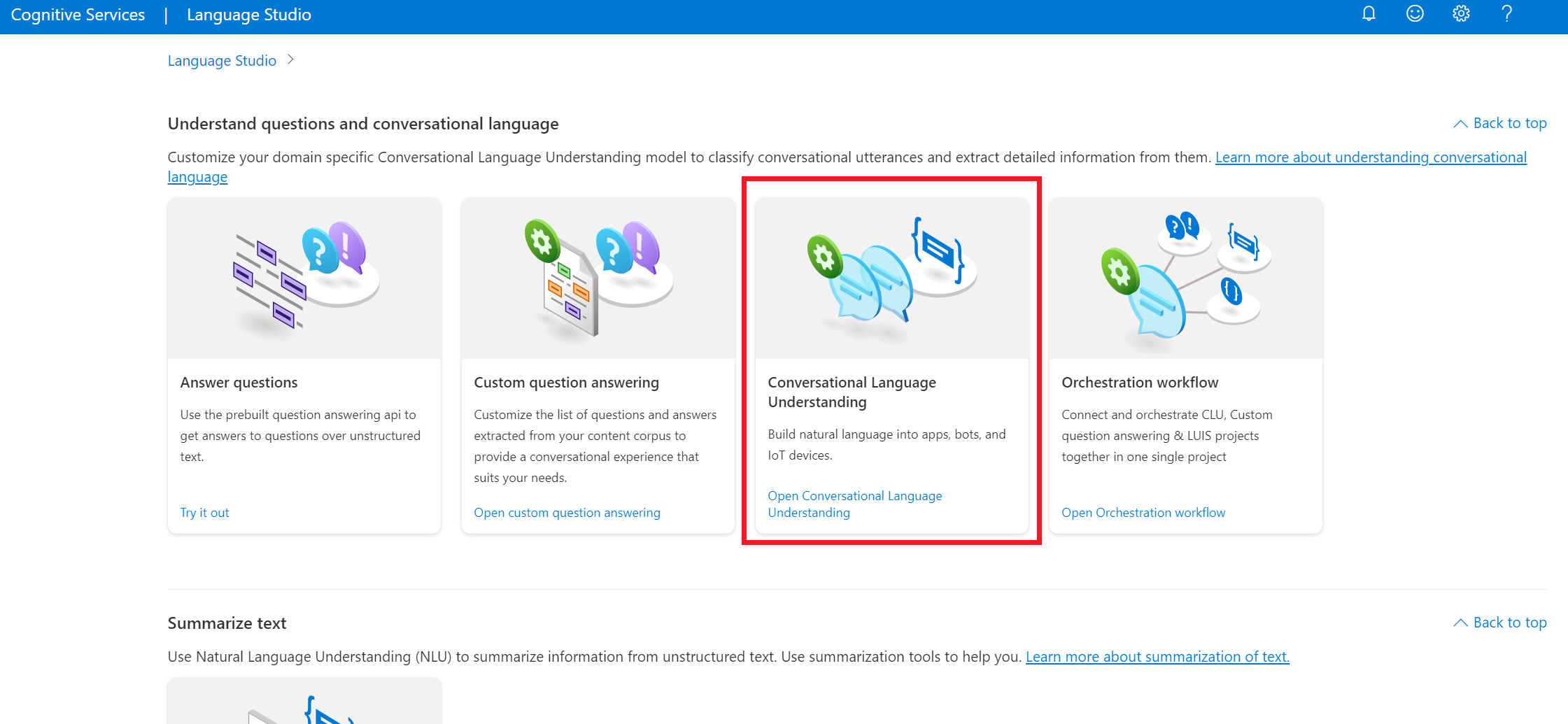
Verrà visualizzata la pagina dei Progetti di comprensione del linguaggio di conversazione. Accanto al pulsante Crea nuovo progetto selezionare Importa.
Nella finestra visualizzata caricare il file JSON da importare. Assicurarsi che il file segua il formato JSON supportato.


Al termine del caricamento verrà visualizzata la pagina Definizione schema. In questo avvio rapido lo schema è già compilato e le espressioni sono già etichettate con finalità ed entità.
Eseguire il training del modello
In genere, dopo aver creato un progetto è necessario compilare uno schema ed etichettare le espressioni. In questo avvio rapido è già stato importato un progetto pronto con lo schema compilato e le espressioni etichettate.
Per eseguire il training di un modello è necessario avviare un processo di training. L'output di un processo di training corretto è il modello sottoposto a training.
Per avviare il training del modello dallo Studio del linguaggio:
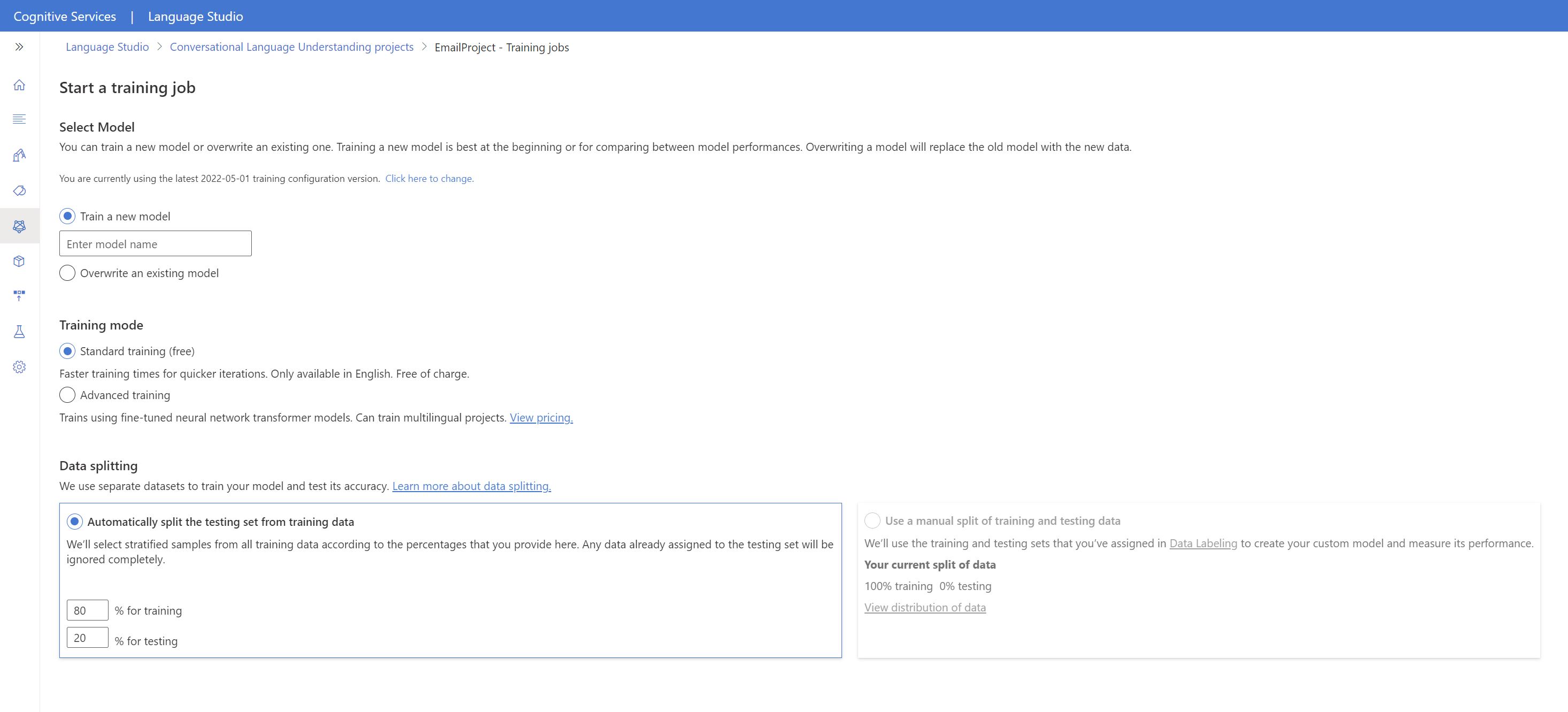
Selezionare Esegui training del modello nel menu a sinistra.
Selezionare Avvia un processo di training nel menu in alto.
Selezionare Esegui training di un nuovo modello e digitare il nome di un modello nuovo nella casella di testo. In alternativa, per sostituire un modello esistente con uno sottoposto a training sui nuovi dati, selezionare Sovrascrivi un modello esistente e poi selezionare un modello esistente. La sovrascrittura di un modello sottoposto a training è irreversibile, ma non influisce sui modelli distribuiti fino a quando non si distribuisce il nuovo modello.
Selezionare la modalità di training. È possibile scegliere Training standard per un training più rapido; anche se è disponibile solo in inglese. In alternativa, è possibile scegliere Training avanzato, che supporta altre lingue e progetti multilingue, ma comporta tempi di training più lunghi. Altre informazioni sulle modalità di training.
Selezionare il metodo di divisione dei dati. È possibile scegliere Divisione automatica del set di test dai dati di training: il sistema dividerà le espressioni tra il set di training e il set di test in base alle percentuali specificate. In alternativa, è possibile scegliere l’opzione Usa una divisione manuale dei dati di training e di testing che è abilitata solo se sono state aggiunte espressioni al set di test durante l’etichettatura delle espressioni.
Selezionare il pulsante Esegui il training.
Selezionare l'ID processo di training dall'elenco. Sarà visualizzato un riquadro in cui è possibile verificare lo stato del training, lo stato del processo e altri dettagli sul processo.
Nota
- Solo i processi di training completati correttamente genereranno modelli.
- Il training può richiedere da un paio di minuti a un paio d’ore, in base al numero di espressioni.
- È possibile eseguire un solo processo di training alla volta. Non è possibile avviare altri processi di training nello stesso progetto fino al completamento del processo in esecuzione.
- L'apprendimento automatico usato per eseguire il training dei modelli viene aggiornato regolarmente. Per eseguire il training su una precedente versione di configurazione selezionare Selezionare qui per modificare nella pagina Avvia un processo di training e scegliere una versione precedente.

Distribuire il modello
In genere dopo il training di un modello, si esaminano i relativi dettagli di valutazione. In questo avvio rapido si distribuirà solo il modello e lo si renderà disponibile per la prova in Studio del linguaggio; in alternativa, è possibile effettuare la chiamata all' API di stima.
Per distribuire un modello all’interno di Studio di linguaggio:
Selezionare Distribuzione di un modello nel menu a sinistra.
Selezionare Aggiungi distribuzione per avviare la procedura guidata Aggiungi distribuzione.

Selezionare Crea un nuovo nome di distribuzione per creare una nuova distribuzione e assegnare un modello sottoposto a training dall'elenco a discesa seguente. In alternativa, selezionare Sovrascrivi un nome di distribuzione esistente per sostituire effettivamente il modello usato da una distribuzione esistente.
Nota
La sovrascrittura di una distribuzione esistente non richiede modifiche alla chiamata API di previsione, ma i risultati ottenuti saranno basati sul modello appena assegnato.

Selezionare un modello sottoposto a training dall'elenco a discesa Modello.
Fare clic su Distribuisci per avviare il processo di distribuzione.
Al termine della distribuzione verrà visualizzata una data di scadenza. La scadenza della distribuzione indica quando il modello non potrà essere usato per la stima, ossia generalmente dodici mesi dopo la scadenza di una configurazione di training.


Testa modello distribuito
Per testare i modelli distribuiti da Studio di linguaggio:
Selezionare Test delle distribuzioni nel menu a sinistra.
Per i progetti multilingue, nell'elenco a discesa Seleziona linguaggio di testo selezionare la lingua dell'espressione di cui si esegue il test.
Nell'elenco a discesa Nome distribuzione selezionare il nome della distribuzione corrispondente al modello da testare. È possibile testare solo i modelli assegnati alle distribuzioni.
Nella casella di testo immettere un'espressione da testare. Ad esempio, se è stata creata un'applicazione per espressioni correlate alla posta elettronica, è possibile immettere Elimina questo messaggio di posta elettronica.
Nella parte superiore della pagina selezionare Esegui il test.
Dopo aver eseguito il test, nel risultato dovrebbe essere visualizzata la risposta del modello. È possibile visualizzare i risultati nella visualizzazione delle schede delle entità o visualizzarli in formato JSON.
Pulire le risorse
Quando il progetto non è più necessario, è possibile eliminare il progetto usando Language Studio. Selezionare Progetti nel menu di spostamento a sinistra, selezionare il progetto da eliminare, quindi selezionare Elimina nel menu in alto.
Prerequisiti
- Sottoscrizione di Azure: creare un account gratuito.
Creare una nuova risorsa dal portale di Azure
Accedere al portale di Azure per creare una nuova risorsa di Lingua di Azure AI.
Selezionare Crea una nuova risorsa
Nella finestra visualizzata cercare Servizio di linguaggio
Selezionare Crea.
Creare una risorsa linguistica con i dettagli seguenti.
Dettagli dell'istanza Valore obbligatorio Area Una delle regioni supportate per la risorsa Linguaggio. Nome Nome obbligatorio per la risorsa Linguaggio Piano tariffario Uno dei piani tariffari supportati per la risorsa Linguaggio.
Ottenere le chiavi e l’endpoint di una risorsa
Accedere alla pagina di panoramica della risorsa nel portale di Azure.
Nel menu sul lato sinistro, scegliere Chiavi ed endpoint. Si useranno l'endpoint e la chiave per le richieste API


Importare un nuovo progetto di esempio CLU
Dopo aver creato una risorsa Linguaggio, creare un progetto Comprensione del linguaggio di conversazione Un progetto è un'area di lavoro per la creazione di modelli di Machine Learning personalizzati sulla base dei propri dati. Al progetto può accedere solo l'utente e altri utenti che hanno accesso alla risorsa di Linguaggio usata.
Per queste istruzioni di avvio rapido, è possibile scaricare questo progetto di esempio e importarlo. Questo progetto è in grado di stimare i comandi previsti dall'input dell'utente, ad esempio la lettura e l'eliminazione di e-mail e l'allegare un documento a un'e-mail.
Attivare il processo di importazione del progetto
Inviare una richiesta POST usando l'URL, le intestazioni e il corpo JSON seguenti per importare il progetto.
Richiesta URL
Usare l'URL seguente per la creazione della richiesta API. Sostituire i valori segnaposto con i propri valori.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:import?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Questo valore fa distinzione tra maiuscole e minuscole e deve corrispondere al nome del progetto nel file JSON importato. | EmailAppDemo |
{API-VERSION} |
La versione dell'API che viene richiamata. | 2023-04-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
La chiave della risorsa. È usata per l’autenticazione delle richieste API. |
Corpo
Il corpo JSON inviato è simile all'esempio seguente. Per altri dettagli sull'oggetto JSON, vedere la documentazione di riferimento.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "Conversation",
"settings": {
"confidenceThreshold": 0.7
},
"projectName": "{PROJECT-NAME}",
"multilingual": true,
"description": "Trying out CLU",
"language": "{LANGUAGE-CODE}"
},
"assets": {
"projectKind": "Conversation",
"intents": [
{
"category": "intent1"
},
{
"category": "intent2"
}
],
"entities": [
{
"category": "entity1"
}
],
"utterances": [
{
"text": "text1",
"dataset": "{DATASET}",
"intent": "intent1",
"entities": [
{
"category": "entity1",
"offset": 5,
"length": 5
}
]
},
{
"text": "text2",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"intent": "intent2",
"entities": []
}
]
}
}
| Chiave | Segnaposto | Valore | Esempio |
|---|---|---|---|
{API-VERSION} |
La versione dell'API che viene richiamata. | 2023-04-01 |
|
projectName |
{PROJECT-NAME} |
Il nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | EmailAppDemo |
language |
{LANGUAGE-CODE} |
Una stringa che specifica il codice lingua per le espressioni usate nel progetto. Se il progetto è un progetto multilingue, scegliere il codice linguaggio della maggior parte delle espressioni. | en-us |
multilingual |
true |
Valore booleano che consente di avere documenti in diversi linguaggi nel set di dati. Quando il modello viene distribuito, è possibile eseguire query sul modello in qualsiasi linguaggio supportato, compresi quelli non inclusi nei documenti di training. | true |
dataset |
{DATASET} |
Vedere come eseguire il training di un modello per informazioni sulla suddivisione dei dati tra un set di test e uno di training. I valori possibili per questo campo sono Train e Test. |
Train |
Quando una richiesta ha esito positivo, la risposta API conterrà un'intestazione operation-location con un URL che è possibile usare per controllare lo stato del processo di importazione. È formattata come segue:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
Ottenere lo stato del processo di importazione
Quando si invia una richiesta di importazione di progetto con esito positivo, l'URL completo della richiesta per verificare lo stato del processo di importazione (incluso l'endpoint, il nome del progetto e l'ID processo) è contenuto nell'intestazione operation-location della risposta.
Usare la richiesta GET seguente per eseguire un query dello stato del processo di importazione. È possibile usare l'URL ricevuto dal passaggio precedente oppure sostituire i valori segnaposto con i propri valori.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{JOB-ID} |
L'ID per individuare lo stato del processo di importazione. | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
La versione dell'API che viene richiamata. | 2023-04-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | Descrizione | Valore |
|---|---|---|
Ocp-Apim-Subscription-Key |
La chiave della risorsa. È usata per l’autenticazione delle richieste API. | {YOUR-PRIMARY-RESOURCE-KEY} |
Corpo della risposta
Dopo aver inviato la richiesta, si otterrà la risposta seguente. Mantenere il polling di questo endpoint fino a quando il parametro dello stato diventa "succeeded".
{
"jobId": "xxxxx-xxxxx-xxxx-xxxxx",
"createdDateTime": "2022-04-18T15:17:20Z",
"lastUpdatedDateTime": "2022-04-18T15:17:22Z",
"expirationDateTime": "2022-04-25T15:17:20Z",
"status": "succeeded"
}
Avviare il training di un modello
In genere, dopo aver creato un progetto, è necessario compilare uno schema ed contrassegnare espressioni. Per queste istruzioni di avvio rapido è già stato importato un progetto pronto con lo schema compilato e le espressioni con tag.
Creare una richiesta POST usando l'URL, le intestazioni e il corpo JSON seguenti per inviare un processo di training.
Richiesta URL
Usare l'URL seguente per la creazione della richiesta API. Sostituire i valori segnaposto con i propri valori.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | EmailApp |
{API-VERSION} |
La versione dell'API che si sta richiamando. | 2023-04-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
La chiave della risorsa. È usata per l’autenticazione delle richieste API. |
Corpo della richiesta
Usare l’oggetto seguente nella richiesta. Il modello verrà denominato dopo il valore usato per il parametro modelLabel al termine del training.
{
"modelLabel": "{MODEL-NAME}",
"trainingMode": "{TRAINING-MODE}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"testingSplitPercentage": 20,
"trainingSplitPercentage": 80
}
}
| Chiave | Segnaposto | Valore | Esempio |
|---|---|---|---|
modelLabel |
{MODEL-NAME} |
Il nome del modello. | Model1 |
trainingConfigVersion |
{CONFIG-VERSION} |
La versione del modello di configurazione del training. Per impostazione predefinita, viene utilizzata la versione del modello più recente. | 2022-05-01 |
trainingMode |
{TRAINING-MODE} |
La modalità da utilizzare per il training. Le modalità supportate sono Training standard, Training più veloce, disponibile solo in inglese e Training avanzato supportata per altre lingue e progetti multilingue, ma che prevede tempi di training più lunghi. Altre informazioni sulle modalità di training. | standard |
kind |
percentage |
Metodi di divisione. I possibili valori sono percentage o manual. Per altre informazioni, vedere Come eseguire il training di un modello. |
percentage |
trainingSplitPercentage |
80 |
Percentuale dei dati con tag da includere nel set di training. Il valore consigliato è 80. |
80 |
testingSplitPercentage |
20 |
Percentuale dei dati con tag da includere nel set di test. Il valore consigliato è 20. |
20 |
Nota
trainingSplitPercentage e testingSplitPercentage sono necessari solo se Kind è impostato su percentage e la somma di entrambe le percentuali deve essere uguale a 100.
Dopo aver inviato la richiesta API, si riceverà una risposta 202 indicante l'esito positivo. Nelle intestazioni della risposta, estrarre il valore operation-location. Il formato sarà simile al seguente:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
È possibile usare questo URL per ottenere lo stato del processo di training.
Ottenere lo stato del processo di training
Il completamento del training può richiedere tempo, a volte tra 10 e 30 minuti. È possibile usare la richiesta seguente per mantenere il polling dello stato del processo di training fino a quando viene completato correttamente.
Quando si invia una richiesta di training con esito positivo, l'URL completo della richiesta per verificare lo stato del processo (incluso l'endpoint, il nome del progetto e l'ID processo) è contenuto nell'intestazione operation-location della risposta.
Usare la seguente richiesta GET per ottenere lo stato dello stato di avanzamento del training del modello. Sostituire i valori segnaposto seguenti con i propri valori.
Richiesta URL
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{YOUR-ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | EmailApp |
{JOB-ID} |
L’ID per individuare lo stato del training del modello. | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
La versione dell'API che viene richiamata. | 2023-04-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
La chiave della risorsa. È usata per l’autenticazione delle richieste API. |
Testo della risposta
Dopo aver inviato la richiesta, si otterrà la risposta seguente. Continuare il polling di questo endpoint fino a quando il parametro dello stato diventa "succeeded".
{
"result": {
"modelLabel": "{MODEL-LABEL}",
"trainingConfigVersion": "{TRAINING-CONFIG-VERSION}",
"trainingMode": "{TRAINING-MODE}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "xxxxx-xxxxx-xxxx-xxxxx-xxxx",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
| Chiave | valore | Esempio |
|---|---|---|
modelLabel |
Nome del modello | Model1 |
trainingConfigVersion |
La versione della configurazione del training. Per impostazione predefinita, viene utilizzata la versione più recente. | 2022-05-01 |
trainingMode |
La modalità di training selezionata. | standard |
startDateTime |
L’ora di inizio del training | 2022-04-14T10:23:04.2598544Z |
status |
Lo stato del processo di training | running |
estimatedEndDateTime |
Il tempo stimato per il completamento del processo di training | 2022-04-14T10:29:38.2598544Z |
jobId |
L'ID del processo di training | xxxxx-xxxx-xxxx-xxxx-xxxxxxxxx |
createdDateTime |
La data e l'ora di creazione del processo di training | 2022-04-14T10:22:42Z |
lastUpdatedDateTime |
Data e ora dell'ultimo aggiornamento del processo di training | 2022-04-14T10:23:45Z |
expirationDateTime |
La data e l'ora di scadenza del processo di training | 2022-04-14T10:22:42Z |
Distribuire il modello
In genere dopo il training di un modello, esaminare i relativi dettagli di valutazione. In queste istruzioni di avvio rapido si distribuirà semplicemente il modello e si chiamerà l'API di stima per eseguire query sui risultati.
Invia processo di distribuzione
Creare una richiesta PUT usando l'URL, le intestazioni e il corpo JSON seguenti per iniziare a distribuire un modello di comprensione del linguaggio di conversazione.
Richiesta URL
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{DEPLOYMENT-NAME} |
Nome della distribuzione. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | staging |
{API-VERSION} |
La versione dell'API che si sta richiamando. | 2023-04-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
La chiave della risorsa. È usata per l’autenticazione delle richieste API. |
Corpo della richiesta
{
"trainedModelLabel": "{MODEL-NAME}",
}
| Chiave | Segnaposto | Valore | Esempio |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
Nome del modello che verrà assegnato alla distribuzione. È possibile assegnare solo modelli il cui training è stato eseguito correttamente. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myModel |
Dopo aver inviato la richiesta API, si riceverà una risposta 202 indicante l'esito positivo. Nelle intestazioni della risposta, estrarre il valore operation-location. Il formato sarà simile al seguente:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
È possibile usare questo URL per ottenere lo stato del processo di distribuzione.
Ottieni stato del processo di distribuzione
Quando si invia una richiesta di distribuzione con esito positivo, l'URL completo della richiesta per verificare lo stato del processo (incluso l'endpoint, il nome del progetto e l'ID processo) è contenuto nell'intestazione operation-location della risposta.
Usare la richiesta GET seguente per ottenere lo stato del processo di distribuzione. Sostituire i valori segnaposto con i propri valori.
Richiesta URL
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{DEPLOYMENT-NAME} |
Nome della distribuzione. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | staging |
{JOB-ID} |
L’ID per individuare lo stato del training del modello. | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
La versione dell'API che viene richiamata. | 2023-04-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
La chiave della risorsa. È usata per l’autenticazione delle richieste API. |
Testo della risposta
Dopo aver inviato la richiesta, si otterrà la risposta seguente. Mantenere il polling di questo endpoint fino a quando il parametro dello stato diventa "succeeded".
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Eseguire query sul modello
Dopo aver distribuito il modello, è possibile iniziare a usarlo per creare previsioni usando l'API di stima.
Al termine della distribuzione, è possibile iniziare a eseguire query sul modello distribuito per le stime.
Creare una richiesta POST usando l'URL, le intestazioni e il corpo JSON seguenti per iniziare a testare un modello di comprensione del linguaggio di conversazione.
Richiesta URL
{ENDPOINT}/language/:analyze-conversations?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
La versione dell'API che viene richiamata. | 2023-04-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
La chiave della risorsa. È usata per l’autenticazione delle richieste API. |
Corpo della richiesta
{
"kind": "Conversation",
"analysisInput": {
"conversationItem": {
"id": "1",
"participantId": "1",
"text": "Text 1"
}
},
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}",
"stringIndexType": "TextElement_V8"
}
}
| Chiave | Segnaposto | Valore | Esempio |
|---|---|---|---|
participantId |
{JOB-NAME} |
"MyJobName |
|
id |
{JOB-NAME} |
"MyJobName |
|
text |
{TEST-UTTERANCE} |
Espressione da cui si desidera stimare la finalità ed estrarre le entità. | "Read Matt's email |
projectName |
{PROJECT-NAME} |
Il nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
deploymentName |
{DEPLOYMENT-NAME} |
Il nome della distribuzione. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | staging |
Dopo aver inviato la richiesta, si otterrà la risposta seguente per la previsione
Corpo della risposta
{
"kind": "ConversationResult",
"result": {
"query": "Text1",
"prediction": {
"topIntent": "inten1",
"projectKind": "Conversation",
"intents": [
{
"category": "intent1",
"confidenceScore": 1
},
{
"category": "intent2",
"confidenceScore": 0
},
{
"category": "intent3",
"confidenceScore": 0
}
],
"entities": [
{
"category": "entity1",
"text": "text1",
"offset": 29,
"length": 12,
"confidenceScore": 1
}
]
}
}
}
| Chiave | Valore di esempio | Descrizione |
|---|---|---|
| query | "Leggi l'e-mail di Matt" | il testo inviato per la query. |
| topIntent | "Leggere" | La finalità stimata con il punteggio di attendibilità più alto. |
| Finalità | [] | Elenco di tutte le finalità stimate per il testo della query, ognuna delle quali con un punteggio di attendibilità. |
| entities | [] | array contenente l'elenco di entità estratte dal testo della query. |
Risposta dell'API per un progetto di conversazioni
In un progetto di conversazione si otterranno stime sia per le finalità che per le entità presenti all'interno del progetto.
- Le finalità e le entità includono un punteggio di attendibilità compreso tra 0,0 e 1,0 associato al grado di attendibilità con cui il modello esegua la previsione di un determinato elemento nel progetto.
- La finalità di punteggio più alto è contenuta all'interno del proprio parametro.
- Nella risposta verranno visualizzate solo le entità stimate.
- Le entità indicano:
- Il testo dell'entità estratta
- La posizione iniziale indicata da un valore di offset
- La lunghezza del testo dell'entità denotata da un valore di lunghezza.
Pulire le risorse
Quando il progetto non è più necessario, è possibile eliminarlo usando le API.
Creare una richiesta ELIMINA usando l'URL, le intestazioni e il corpo JSON seguenti per eliminare un progetto di comprensione del linguaggio di conversazione.
Richiesta URL
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{API-VERSION} |
La versione dell'API che si sta richiamando. | 2023-04-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
La chiave della risorsa. È usata per l’autenticazione delle richieste API. |
Dopo aver inviato la richiesta API, si riceverà una risposta 202 che indica l'esito positivo, che significa che il progetto è stato eliminato.