Guida introduttiva: Riconoscere gli intenti con il servizio Voce e LUIS
Importante
LUIS verrà ritirato il 1° ottobre 2025. A partire dal 1° aprile 2023 non è possibile creare nuove risorse LUIS. È consigliabile eseguire la migrazione delle applicazioni LUIS a comprensione del linguaggio di conversazione (CLU) per trarre vantaggio dal supporto continuo del prodotto e dalle funzionalità multilingua.
CLU (Comprensione del linguaggio di conversazione) è disponibile per C# e C++ con Speech SDK versione 1.25 o successiva. Vedere l’avvio rapido per riconoscere gli intenti con Speech SDK e CLU.
Documentazione di riferimento | Pacchetto (NuGet) | Ulteriori esempi in GitHub
In questo argomento di avvio rapido si useranno Speech SDK e il servizio LUIS (Language Understanding) per riconoscere le finalità dai dati audio acquisiti da un microfono. In particolare, si userà Speech SDK per acquisire la voce e un dominio predefinito di LUIS per identificare le finalità per la domotica, come l'accensione e lo spegnimento di una luce.
Prerequisiti
- Sottoscrizione di Azure: creare un account gratuito
-
Creare una risorsa di linguaggio nel portale di Azure. È possibile usare il piano tariffario gratuito (
F0) per provare il servizio ed eseguire in un secondo momento l'aggiornamento a un livello a pagamento per la produzione. Questa volta non sarà necessaria una risorsa Voce. - Ottenere la chiave e la regione della risorsa di linguaggio. Dopo aver distribuito la risorsa di linguaggio, selezionare Vai alla risorsa per visualizzare e gestire le chiavi.
Creare un'app LUIS per il riconoscimento delle finalità
Per completare l'argomento di avvio rapido sul riconoscimento di finalità, è necessario creare un account e un progetto LUIS usando l'anteprima del portale LUIS. Questa guida introduttiva richiede una sottoscrizione LUIS in un'area in cui è disponibile il riconoscimento degli intenti. Non è necessario avere una sottoscrizione del servizio Voce.
Per prima cosa è necessario creare un account e un'app LUIS tramite l'anteprima del portale LUIS. L'app LUIS creata userà un dominio predefinito per la domotica, che fornisce finalità, entità ed espressioni di esempio. Al termine, sarà disponibile un endpoint LUIS in esecuzione nel cloud che è possibile chiamare con Speech SDK.
Per creare l'app LUIS, seguire queste istruzioni:
Al termine, saranno necessari quattro elementi:
- Eseguire di nuovo la pubblicazione con il priming del riconoscimento vocale attivato
- La chiave primaria di LUIS
- La località di LUIS
- L'ID app di LUIS
È possibile trovare queste informazioni nell'anteprima del portale LUIS:
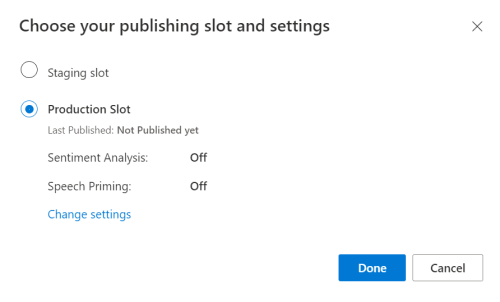
Nel portale di anteprima LUIS selezionare l'app e quindi selezionare il pulsante Pubblica.
Selezionare lo slot di produzione; se si usa
en-US, selezionare Modifica impostazioni e spostare l'opzione Priming vocale sulla posizione On. Quindi selezionare il pulsante Pubblica.Importante
L'opzione di priming del riconoscimento vocale è particolarmente consigliata, in quanto migliorerà l'accuratezza del riconoscimento vocale.
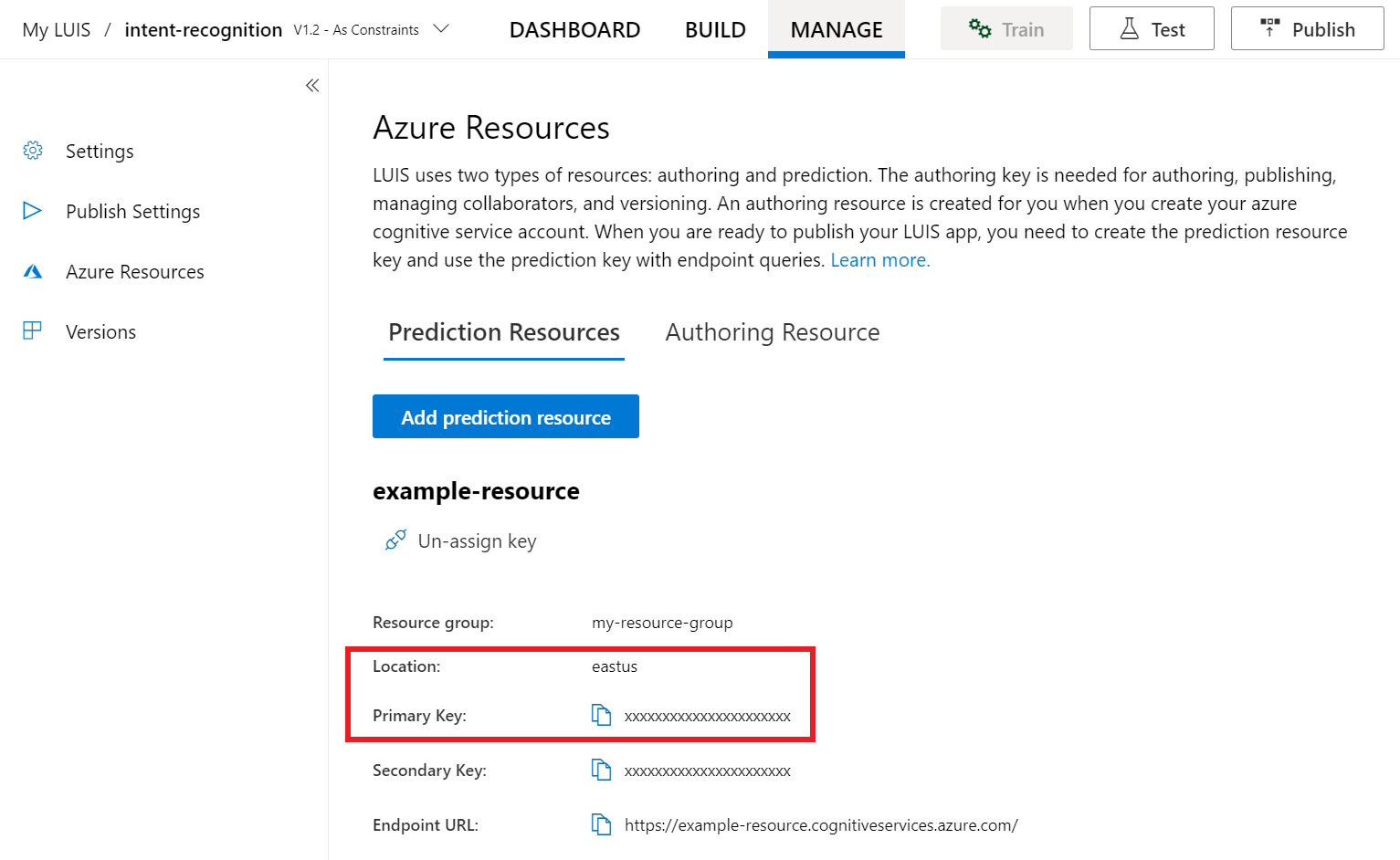
Nell'anteprima del portale LUIS selezionare Gestisci e quindi Risorse di Azure. In questa pagina sono disponibili la chiave e la posizione LUIS (talvolta denominata area) per la risorsa di previsione LUIS.
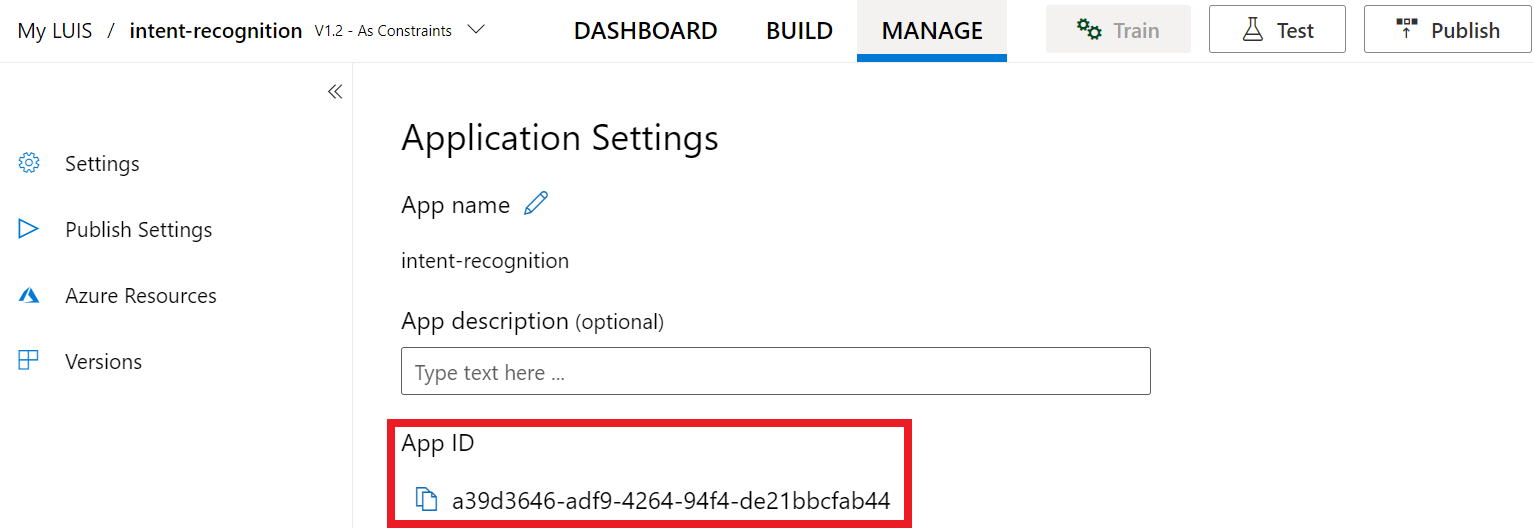
Una volta ottenute la chiave e l'area, sarà necessario l'ID app. Seleziona Impostazioni. L'ID app è disponibile in questa pagina.
Aprire il progetto in Visual Studio
Aprire quindi il progetto in Visual Studio.
- Avviare Visual Studio 2019.
- Caricare il progetto e aprire
Program.cs.
Iniziare con un codice boilerplate
Aggiungere codice che funga da scheletro del progetto. Si noti che è stato creato un metodo asincrono denominato RecognizeIntentAsync().
using System;
using System.Threading.Tasks;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Intent;
namespace helloworld
{
class Program
{
public static async Task RecognizeIntentAsync()
{
}
static async Task Main()
{
await RecognizeIntentAsync();
Console.WriteLine("Please press <Return> to continue.");
Console.ReadLine();
}
}
}
Creare una configurazione di Voce
Prima di inizializzare un oggetto IntentRecognizer, è necessario creare una configurazione che usi la chiave e l'area della risorsa di previsione di LUIS.
Importante
La chiave di avvio e le chiavi di creazione non funzioneranno. È necessario usare la chiave e l'area di previsione create in precedenza. Per altre informazioni, vedere Creare un'app LUIS per il riconoscimento delle finalità.
Inserire questo codice nel metodo RecognizeIntentAsync(). Assicurarsi di aggiornare questi valori:
- Sostituire
"YourLanguageUnderstandingSubscriptionKey"con la chiave di previsione di LUIS. - Sostituire
"YourLanguageUnderstandingServiceRegion"con l'area di LUIS. Usare l'identificatore di area corrispondente all'area.
Suggerimento
Per informazioni su come trovare questi valori, vedere Creare un'app LUIS per il riconoscimento delle finalità.
Importante
Al termine, ricordarsi di rimuovere la chiave dal codice e non renderlo mai pubblico. Per un ambiente di produzione usare un metodo sicuro per l'archiviazione e l'accesso alle proprie credenziali, ad esempio Azure Key Vault. Per altre informazioni, vedere l'articolo sulla sicurezza del Servizi di Azure AI.
var config = SpeechConfig.FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
Questo esempio usa il metodo FromSubscription() per creare SpeechConfig. Per un elenco completo dei metodi disponibili, vedere Classe SpeechConfig.
Per impostazione predefinita, Speech SDK riconoscerà l'uso di en-us per la lingua. Per informazioni sulla scelta della lingua di origine, vedere Come riconoscere il riconoscimento vocale.
Inizializzare un oggetto IntentRecognizer
Creare ora un oggetto IntentRecognizer. Questo oggetto viene creato all'interno di un'istruzione using per garantire il corretto rilascio delle risorse non gestite. Inserire questo codice nel metodo RecognizeIntentAsync(), immediatamente sotto la configurazione di Voce.
// Creates an intent recognizer using microphone as audio input.
using (var recognizer = new IntentRecognizer(config))
{
}
Aggiungere un oggetto LanguageUnderstandingModel e le finalità
È necessario associare un oggetto LanguageUnderstandingModel allo strumento di riconoscimento di finalità e aggiungere le finalità da riconoscere. Verranno usate le finalità del dominio predefinito per la domotica. Inserire questo codice nell'istruzione using della sezione precedente. Assicurarsi di sostituire "YourLanguageUnderstandingAppId" con l'ID dell'app LUIS.
Suggerimento
Per informazioni su come trovare questo valore, vedere Creare un'app LUIS per il riconoscimento delle finalità.
// Creates a Language Understanding model using the app id, and adds specific intents from your model
var model = LanguageUnderstandingModel.FromAppId("YourLanguageUnderstandingAppId");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
Questo esempio usa la funzione AddIntent() per aggiungere le finalità singolarmente. Se si vogliono aggiungere tutte le finalità da un modello, usare AddAllIntents(model) e passare il modello.
Riconoscere una finalità
Dall'oggetto IntentRecognizer chiamare il metodo RecognizeOnceAsync(). Questo metodo consente al servizio Voce di rilevare che si sta inviando una singola frase per il riconoscimento e di interrompere il riconoscimento vocale una volta identificata la frase.
All'interno dell'istruzione using aggiungere il codice seguente sotto il modello.
// Starts recognizing.
Console.WriteLine("Say something...");
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
var result = await recognizer.RecognizeOnceAsync();
Visualizzare i risultati (o gli errori) del riconoscimento
Quando il servizio Voce restituisce il risultato del riconoscimento, in genere lo si usa per qualche scopo. Per semplicità, in questo caso i risultati verranno stampati sulla console.
All'interno dell'istruzione using, sotto RecognizeOnceAsync(), aggiungere il codice seguente:
// Checks result.
switch (result.Reason)
{
case ResultReason.RecognizedIntent:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent Id: {result.IntentId}.");
var json = result.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
Console.WriteLine($" Language Understanding JSON: {json}.");
break;
case ResultReason.RecognizedSpeech:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent not recognized.");
break;
case ResultReason.NoMatch:
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
break;
case ResultReason.Canceled:
var cancellation = CancellationDetails.FromResult(result);
Console.WriteLine($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you update the subscription info?");
}
break;
}
Controllare il codice
A questo punto il codice dovrà avere questo aspetto:
Nota
In questa versione sono stati aggiunti alcuni commenti.
//
// Copyright (c) Microsoft. All rights reserved.
// Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
//
// <skeleton_1>
using System;
using System.Threading.Tasks;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Intent;
namespace helloworld
{
class Program
{
public static async Task RecognizeIntentAsync()
{
// </skeleton_1>
// Creates an instance of a speech config with specified subscription key
// and service region. Note that in contrast to other services supported by
// the Cognitive Services Speech SDK, the Language Understanding service
// requires a specific subscription key from https://www.luis.ai/.
// The Language Understanding service calls the required key 'endpoint key'.
// Once you've obtained it, replace with below with your own Language Understanding subscription key
// and service region (e.g., "westus").
// The default language is "en-us".
// <create_speech_configuration>
var config = SpeechConfig.FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
// </create_speech_configuration>
// <create_intent_recognizer_1>
// Creates an intent recognizer using microphone as audio input.
using (var recognizer = new IntentRecognizer(config))
{
// </create_intent_recognizer_1>
// <add_intents>
// Creates a Language Understanding model using the app id, and adds specific intents from your model
var model = LanguageUnderstandingModel.FromAppId("YourLanguageUnderstandingAppId");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// </add_intents>
// To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
// recognizer.AddAllIntents(model);
// <recognize_intent>
// Starts recognizing.
Console.WriteLine("Say something...");
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
var result = await recognizer.RecognizeOnceAsync();
// </recognize_intent>
// <print_results>
// Checks result.
switch (result.Reason)
{
case ResultReason.RecognizedIntent:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent Id: {result.IntentId}.");
var json = result.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
Console.WriteLine($" Language Understanding JSON: {json}.");
break;
case ResultReason.RecognizedSpeech:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent not recognized.");
break;
case ResultReason.NoMatch:
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
break;
case ResultReason.Canceled:
var cancellation = CancellationDetails.FromResult(result);
Console.WriteLine($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you update the subscription info?");
}
break;
}
// </print_results>
// <create_intent_recognizer_2>
}
// </create_intent_recognizer_2>
// <skeleton_2>
}
static async Task Main()
{
await RecognizeIntentAsync();
Console.WriteLine("Please press <Return> to continue.");
Console.ReadLine();
}
}
}
// </skeleton_2>
Compilare ed eseguire l'app
A questo punto è possibile compilare l'app e testare il riconoscimento vocale con il servizio Voce.
- Compilare il codice: dalla barra dei menu di Visual Studio scegliere Compila>Compila soluzione.
- Avviare l'app: dalla barra dei menu scegliere Debug>Avvia debug o premere F5.
- Avviare il riconoscimento: verrà richiesto di pronunciare una frase in inglese. La voce viene inviata al servizio Voce, trascritta come testo e visualizzata nella console.
Documentazione di riferimento | Pacchetto (NuGet) | Ulteriori esempi in GitHub
In questo argomento di avvio rapido si useranno Speech SDK e il servizio LUIS (Language Understanding) per riconoscere le finalità dai dati audio acquisiti da un microfono. In particolare, si userà Speech SDK per acquisire la voce e un dominio predefinito di LUIS per identificare le finalità per la domotica, come l'accensione e lo spegnimento di una luce.
Prerequisiti
- Sottoscrizione di Azure: creare un account gratuito
-
Creare una risorsa di linguaggio nel portale di Azure. È possibile usare il piano tariffario gratuito (
F0) per provare il servizio ed eseguire in un secondo momento l'aggiornamento a un livello a pagamento per la produzione. Questa volta non sarà necessaria una risorsa Voce. - Ottenere la chiave e la regione della risorsa di linguaggio. Dopo aver distribuito la risorsa di linguaggio, selezionare Vai alla risorsa per visualizzare e gestire le chiavi.
Creare un'app LUIS per il riconoscimento delle finalità
Per completare l'argomento di avvio rapido sul riconoscimento di finalità, è necessario creare un account e un progetto LUIS usando l'anteprima del portale LUIS. Questa guida introduttiva richiede una sottoscrizione LUIS in un'area in cui è disponibile il riconoscimento degli intenti. Non è necessario avere una sottoscrizione del servizio Voce.
Per prima cosa è necessario creare un account e un'app LUIS tramite l'anteprima del portale LUIS. L'app LUIS creata userà un dominio predefinito per la domotica, che fornisce finalità, entità ed espressioni di esempio. Al termine, sarà disponibile un endpoint LUIS in esecuzione nel cloud che è possibile chiamare con Speech SDK.
Per creare l'app LUIS, seguire queste istruzioni:
Al termine, saranno necessari quattro elementi:
- Eseguire di nuovo la pubblicazione con il priming del riconoscimento vocale attivato
- La chiave primaria di LUIS
- La località di LUIS
- L'ID app di LUIS
È possibile trovare queste informazioni nell'anteprima del portale LUIS:
Nel portale di anteprima LUIS selezionare l'app e quindi selezionare il pulsante Pubblica.
Selezionare lo slot di produzione; se si usa
en-US, selezionare Modifica impostazioni e spostare l'opzione Priming vocale sulla posizione On. Quindi selezionare il pulsante Pubblica.Importante
L'opzione di priming del riconoscimento vocale è particolarmente consigliata, in quanto migliorerà l'accuratezza del riconoscimento vocale.
Nell'anteprima del portale LUIS selezionare Gestisci e quindi Risorse di Azure. In questa pagina sono disponibili la chiave e la posizione LUIS (talvolta denominata area) per la risorsa di previsione LUIS.
Una volta ottenute la chiave e l'area, sarà necessario l'ID app. Seleziona Impostazioni. L'ID app è disponibile in questa pagina.
Aprire il progetto in Visual Studio
Aprire quindi il progetto in Visual Studio.
- Avviare Visual Studio 2019.
- Caricare il progetto e aprire
helloworld.cpp.
Iniziare con un codice boilerplate
Aggiungere codice che funga da scheletro del progetto. Si noti che è stato creato un metodo asincrono denominato recognizeIntent().
#include "stdafx.h"
#include <iostream>
#include <speechapi_cxx.h>
using namespace std;
using namespace Microsoft::CognitiveServices::Speech;
using namespace Microsoft::CognitiveServices::Speech::Intent;
void recognizeIntent()
{
}
int wmain()
{
try
{
recognizeIntent();
}
catch (exception e)
{
cout << e.what();
}
cout << "Please press a key to continue.\n";
cin.get();
return 0;
}
Creare una configurazione di Voce
Prima di inizializzare un oggetto IntentRecognizer, è necessario creare una configurazione che usi la chiave e l'area della risorsa di previsione di LUIS.
Importante
La chiave di avvio e le chiavi di creazione non funzioneranno. È necessario usare la chiave e l'area di previsione create in precedenza. Per altre informazioni, vedere Creare un'app LUIS per il riconoscimento delle finalità.
Inserire questo codice nel metodo recognizeIntent(). Assicurarsi di aggiornare questi valori:
- Sostituire
"YourLanguageUnderstandingSubscriptionKey"con la chiave di previsione di LUIS. - Sostituire
"YourLanguageUnderstandingServiceRegion"con l'area di LUIS. Usare l'identificatore di area corrispondente all'area.
Suggerimento
Per informazioni su come trovare questi valori, vedere Creare un'app LUIS per il riconoscimento delle finalità.
Importante
Al termine, ricordarsi di rimuovere la chiave dal codice e non renderlo mai pubblico. Per un ambiente di produzione usare un metodo sicuro per l'archiviazione e l'accesso alle proprie credenziali, ad esempio Azure Key Vault. Per altre informazioni, vedere l'articolo sulla sicurezza del Servizi di Azure AI.
auto config = SpeechConfig::FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
Questo esempio usa il metodo FromSubscription() per creare SpeechConfig. Per un elenco completo dei metodi disponibili, vedere Classe SpeechConfig.
Per impostazione predefinita, Speech SDK riconoscerà l'uso di en-us per la lingua. Per informazioni sulla scelta della lingua di origine, vedere Come riconoscere il riconoscimento vocale.
Inizializzare un oggetto IntentRecognizer
Creare ora un oggetto IntentRecognizer. Inserire questo codice nel metodo recognizeIntent(), immediatamente sotto la configurazione di Voce.
// Creates an intent recognizer using microphone as audio input.
auto recognizer = IntentRecognizer::FromConfig(config);
Aggiungere un oggetto LanguageUnderstandingModel e le finalità
È necessario associare un oggetto LanguageUnderstandingModel allo strumento di riconoscimento di finalità e aggiungere le finalità da riconoscere. Verranno usate le finalità del dominio predefinito per la domotica.
Inserire questo codice sotto IntentRecognizer. Assicurarsi di sostituire "YourLanguageUnderstandingAppId" con l'ID dell'app LUIS.
Suggerimento
Per informazioni su come trovare questo valore, vedere Creare un'app LUIS per il riconoscimento delle finalità.
// Creates a Language Understanding model using the app id, and adds specific intents from your model
auto model = LanguageUnderstandingModel::FromAppId("YourLanguageUnderstandingAppId");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
Questo esempio usa la funzione AddIntent() per aggiungere le finalità singolarmente. Se si vogliono aggiungere tutte le finalità da un modello, usare AddAllIntents(model) e passare il modello.
Riconoscere una finalità
Dall'oggetto IntentRecognizer chiamare il metodo RecognizeOnceAsync(). Questo metodo consente al servizio Voce di rilevare che si sta inviando una singola frase per il riconoscimento e di interrompere il riconoscimento vocale una volta identificata la frase. Per semplicità, attendere il completamento della funzionalità restituita.
Inserire questo codice sotto il modello:
cout << "Say something...\n";
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
auto result = recognizer->RecognizeOnceAsync().get();
Visualizzare i risultati (o gli errori) del riconoscimento
Quando il servizio Voce restituisce il risultato del riconoscimento, in genere lo si usa per qualche scopo. Per semplicità, in questo caso il risultato verrà stampato sulla console.
Inserire questo codice sotto auto result = recognizer->RecognizeOnceAsync().get();:
// Checks result.
if (result->Reason == ResultReason::RecognizedIntent)
{
cout << "RECOGNIZED: Text=" << result->Text << std::endl;
cout << " Intent Id: " << result->IntentId << std::endl;
cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl;
}
else if (result->Reason == ResultReason::RecognizedSpeech)
{
cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl;
}
else if (result->Reason == ResultReason::NoMatch)
{
cout << "NOMATCH: Speech could not be recognized." << std::endl;
}
else if (result->Reason == ResultReason::Canceled)
{
auto cancellation = CancellationDetails::FromResult(result);
cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl;
if (cancellation->Reason == CancellationReason::Error)
{
cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl;
cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl;
cout << "CANCELED: Did you update the subscription info?" << std::endl;
}
}
Controllare il codice
A questo punto il codice dovrà avere questo aspetto:
Nota
In questa versione sono stati aggiunti alcuni commenti.
//
// Copyright (c) Microsoft. All rights reserved.
// Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
//
// <skeleton_1>
#include "stdafx.h"
#include <iostream>
#include <speechapi_cxx.h>
using namespace std;
using namespace Microsoft::CognitiveServices::Speech;
using namespace Microsoft::CognitiveServices::Speech::Intent;
void recognizeIntent()
{
// </skeleton_1>
// Creates an instance of a speech config with specified subscription key
// and service region. Note that in contrast to other services supported by
// the Cognitive Services Speech SDK, the Language Understanding service
// requires a specific subscription key from https://www.luis.ai/.
// The Language Understanding service calls the required key 'endpoint key'.
// Once you've obtained it, replace with below with your own Language Understanding subscription key
// and service region (e.g., "westus").
// The default recognition language is "en-us".
// <create_speech_configuration>
auto config = SpeechConfig::FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
// </create_speech_configuration>
// <create_intent_recognizer>
// Creates an intent recognizer using microphone as audio input.
auto recognizer = IntentRecognizer::FromConfig(config);
// </create_intent_recognizer>
// <add_intents>
// Creates a Language Understanding model using the app id, and adds specific intents from your model
auto model = LanguageUnderstandingModel::FromAppId("YourLanguageUnderstandingAppId");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// </add_intents>
// To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
// recognizer->AddAllIntents(model);
// <recognize_intent>
cout << "Say something...\n";
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
auto result = recognizer->RecognizeOnceAsync().get();
// </recognize_intent>
// <print_results>
// Checks result.
if (result->Reason == ResultReason::RecognizedIntent)
{
cout << "RECOGNIZED: Text=" << result->Text << std::endl;
cout << " Intent Id: " << result->IntentId << std::endl;
cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl;
}
else if (result->Reason == ResultReason::RecognizedSpeech)
{
cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl;
}
else if (result->Reason == ResultReason::NoMatch)
{
cout << "NOMATCH: Speech could not be recognized." << std::endl;
}
else if (result->Reason == ResultReason::Canceled)
{
auto cancellation = CancellationDetails::FromResult(result);
cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl;
if (cancellation->Reason == CancellationReason::Error)
{
cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl;
cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl;
cout << "CANCELED: Did you update the subscription info?" << std::endl;
}
}
// </print_results>
// <skeleton_2>
}
int wmain()
{
try
{
recognizeIntent();
}
catch (exception e)
{
cout << e.what();
}
cout << "Please press a key to continue.\n";
cin.get();
return 0;
}
// </skeleton_2>
Compilare ed eseguire l'app
A questo punto è possibile compilare l'app e testare il riconoscimento vocale con il servizio Voce.
- Compilare il codice: dalla barra dei menu di Visual Studio scegliere Compila>Compila soluzione.
- Avviare l'app: dalla barra dei menu scegliere Debug>Avvia debug o premere F5.
- Avviare il riconoscimento: verrà richiesto di pronunciare una frase in inglese. La voce viene inviata al servizio Voce, trascritta come testo e visualizzata nella console.
documentazione di riferimento | Esempi aggiuntivi in GitHub
In questo argomento di avvio rapido si useranno Speech SDK e il servizio LUIS (Language Understanding) per riconoscere le finalità dai dati audio acquisiti da un microfono. In particolare, si userà Speech SDK per acquisire la voce e un dominio predefinito di LUIS per identificare le finalità per la domotica, come l'accensione e lo spegnimento di una luce.
Prerequisiti
- Sottoscrizione di Azure: creare un account gratuito
-
Creare una risorsa di linguaggio nel portale di Azure. È possibile usare il piano tariffario gratuito (
F0) per provare il servizio ed eseguire in un secondo momento l'aggiornamento a un livello a pagamento per la produzione. Questa volta non sarà necessaria una risorsa Voce. - Ottenere la chiave e la regione della risorsa di linguaggio. Dopo aver distribuito la risorsa di linguaggio, selezionare Vai alla risorsa per visualizzare e gestire le chiavi.
È necessario Installare Speech SDK per l'ambiente di sviluppo e creare un progetto di esempio vuoto.
Creare un'app LUIS per il riconoscimento delle finalità
Per completare l'argomento di avvio rapido sul riconoscimento di finalità, è necessario creare un account e un progetto LUIS usando l'anteprima del portale LUIS. Questa guida introduttiva richiede una sottoscrizione LUIS in un'area in cui è disponibile il riconoscimento degli intenti. Non è necessario avere una sottoscrizione del servizio Voce.
Per prima cosa è necessario creare un account e un'app LUIS tramite l'anteprima del portale LUIS. L'app LUIS creata userà un dominio predefinito per la domotica, che fornisce finalità, entità ed espressioni di esempio. Al termine, sarà disponibile un endpoint LUIS in esecuzione nel cloud che è possibile chiamare con Speech SDK.
Per creare l'app LUIS, seguire queste istruzioni:
Al termine, saranno necessari quattro elementi:
- Eseguire di nuovo la pubblicazione con il priming del riconoscimento vocale attivato
- La chiave primaria di LUIS
- La località di LUIS
- L'ID app di LUIS
È possibile trovare queste informazioni nell'anteprima del portale LUIS:
Nel portale di anteprima LUIS selezionare l'app e quindi selezionare il pulsante Pubblica.
Selezionare lo slot di produzione; se si usa
en-US, selezionare Modifica impostazioni e spostare l'opzione Priming vocale sulla posizione On. Quindi selezionare il pulsante Pubblica.Importante
L'opzione di priming del riconoscimento vocale è particolarmente consigliata, in quanto migliorerà l'accuratezza del riconoscimento vocale.
Nell'anteprima del portale LUIS selezionare Gestisci e quindi Risorse di Azure. In questa pagina sono disponibili la chiave e la posizione LUIS (talvolta denominata area) per la risorsa di previsione LUIS.
Una volta ottenute la chiave e l'area, sarà necessario l'ID app. Seleziona Impostazioni. L'ID app è disponibile in questa pagina.
Apri il tuo progetto
- Aprire l'IDE preferito.
- Caricare il progetto e aprire
Main.java.
Iniziare con un codice boilerplate
Aggiungere codice che funga da scheletro del progetto.
package speechsdk.quickstart;
import com.microsoft.cognitiveservices.speech.*;
import com.microsoft.cognitiveservices.speech.intent.*;
/**
* Quickstart: recognize speech using the Speech SDK for Java.
*/
public class Main {
/**
* @param args Arguments are ignored in this sample.
*/
public static void main(String[] args) {
} catch (Exception ex) {
System.out.println("Unexpected exception: " + ex.getMessage());
assert(false);
System.exit(1);
}
}
}
Creare una configurazione di Voce
Prima di inizializzare un oggetto IntentRecognizer, è necessario creare una configurazione che usi la chiave e l'area della risorsa di previsione di LUIS.
Inserire il codice nel blocco try/catch in main(). Assicurarsi di aggiornare questi valori:
- Sostituire
"YourLanguageUnderstandingSubscriptionKey"con la chiave di previsione di LUIS. - Sostituire
"YourLanguageUnderstandingServiceRegion"con l'area di LUIS. Usare l'identificatore di area corrispondente all'area.
Suggerimento
Per informazioni su come trovare questi valori, vedere Creare un'app LUIS per il riconoscimento delle finalità.
Importante
Al termine, ricordarsi di rimuovere la chiave dal codice e non renderlo mai pubblico. Per un ambiente di produzione usare un metodo sicuro per l'archiviazione e l'accesso alle proprie credenziali, ad esempio Azure Key Vault. Per altre informazioni, vedere l'articolo sulla sicurezza del Servizi di Azure AI.
// Replace below with with specified subscription key (called 'endpoint key' by the Language Understanding service)
String languageUnderstandingSubscriptionKey = "YourLanguageUnderstandingSubscriptionKey";
// Replace below with your own service region (e.g., "westus").
String languageUnderstandingServiceRegion = "YourLanguageUnderstandingServiceRegion";
// Creates an instance of intent recognizer with a given speech configuration.
// Recognizer is created with the default microphone audio input and default language "en-us".
try (SpeechConfig config = SpeechConfig.fromSubscription(languageUnderstandingSubscriptionKey, languageUnderstandingServiceRegion);
Questo esempio usa il metodo FromSubscription() per creare SpeechConfig. Per un elenco completo dei metodi disponibili, vedere Classe SpeechConfig.
Per impostazione predefinita, Speech SDK riconoscerà l'uso di en-us per la lingua. Per informazioni sulla scelta della lingua di origine, vedere Come riconoscere il riconoscimento vocale.
Inizializzare un oggetto IntentRecognizer
Creare ora un oggetto IntentRecognizer. Inserire questo codice immediatamente sotto la configurazione di Voce.
IntentRecognizer recognizer = new IntentRecognizer(config)) {
Aggiungere un oggetto LanguageUnderstandingModel e le finalità
È necessario associare un oggetto LanguageUnderstandingModel allo strumento di riconoscimento di finalità e aggiungere le finalità da riconoscere. Verranno usate le finalità del dominio predefinito per la domotica.
Inserire questo codice sotto IntentRecognizer. Assicurarsi di sostituire "YourLanguageUnderstandingAppId" con l'ID dell'app LUIS.
Suggerimento
Per informazioni su come trovare questo valore, vedere Creare un'app LUIS per il riconoscimento delle finalità.
// Creates a language understanding model using the app id, and adds specific intents from your model
LanguageUnderstandingModel model = LanguageUnderstandingModel.fromAppId("YourLanguageUnderstandingAppId");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
Questo esempio usa la funzione addIntent() per aggiungere le finalità singolarmente. Se si vogliono aggiungere tutte le finalità da un modello, usare addAllIntents(model) e passare il modello.
Riconoscere una finalità
Dall'oggetto IntentRecognizer chiamare il metodo recognizeOnceAsync(). Questo metodo consente al servizio Voce di rilevare che si sta inviando una singola frase per il riconoscimento e di interrompere il riconoscimento vocale una volta identificata la frase.
Inserire questo codice sotto il modello:
System.out.println("Say something...");
// Starts recognition. It returns when the first utterance has been recognized.
IntentRecognitionResult result = recognizer.recognizeOnceAsync().get();
Visualizzare i risultati (o gli errori) del riconoscimento
Quando il servizio Voce restituisce il risultato del riconoscimento, in genere lo si usa per qualche scopo. Per semplicità, in questo caso il risultato verrà stampato sulla console.
Inserire questo codice sotto la chiamata a recognizeOnceAsync().
// Checks result.
if (result.getReason() == ResultReason.RecognizedIntent) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent Id: " + result.getIntentId());
System.out.println(" Intent Service JSON: " + result.getProperties().getProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult));
}
else if (result.getReason() == ResultReason.RecognizedSpeech) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent not recognized.");
}
else if (result.getReason() == ResultReason.NoMatch) {
System.out.println("NOMATCH: Speech could not be recognized.");
}
else if (result.getReason() == ResultReason.Canceled) {
CancellationDetails cancellation = CancellationDetails.fromResult(result);
System.out.println("CANCELED: Reason=" + cancellation.getReason());
if (cancellation.getReason() == CancellationReason.Error) {
System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode());
System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails());
System.out.println("CANCELED: Did you update the subscription info?");
}
}
Controllare il codice
A questo punto il codice dovrà avere questo aspetto:
Nota
In questa versione sono stati aggiunti alcuni commenti.
//
// Copyright (c) Microsoft. All rights reserved.
// Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
//
// <skeleton_1>
package speechsdk.quickstart;
import com.microsoft.cognitiveservices.speech.*;
import com.microsoft.cognitiveservices.speech.intent.*;
/**
* Quickstart: recognize speech using the Speech SDK for Java.
*/
public class Main {
/**
* @param args Arguments are ignored in this sample.
*/
public static void main(String[] args) {
// </skeleton_1>
// <create_speech_configuration>
// Replace below with with specified subscription key (called 'endpoint key' by the Language Understanding service)
String languageUnderstandingSubscriptionKey = "YourLanguageUnderstandingSubscriptionKey";
// Replace below with your own service region (e.g., "westus").
String languageUnderstandingServiceRegion = "YourLanguageUnderstandingServiceRegion";
// Creates an instance of intent recognizer with a given speech configuration.
// Recognizer is created with the default microphone audio input and default language "en-us".
try (SpeechConfig config = SpeechConfig.fromSubscription(languageUnderstandingSubscriptionKey, languageUnderstandingServiceRegion);
// </create_speech_configuration>
// <create_intent_recognizer>
IntentRecognizer recognizer = new IntentRecognizer(config)) {
// </create_intent_recognizer>
// <add_intents>
// Creates a language understanding model using the app id, and adds specific intents from your model
LanguageUnderstandingModel model = LanguageUnderstandingModel.fromAppId("YourLanguageUnderstandingAppId");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// </add_intents>
// To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
// recognizer.addAllIntents(model);
// <recognize_intent>
System.out.println("Say something...");
// Starts recognition. It returns when the first utterance has been recognized.
IntentRecognitionResult result = recognizer.recognizeOnceAsync().get();
// </recognize_intent>
// <print_result>
// Checks result.
if (result.getReason() == ResultReason.RecognizedIntent) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent Id: " + result.getIntentId());
System.out.println(" Intent Service JSON: " + result.getProperties().getProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult));
}
else if (result.getReason() == ResultReason.RecognizedSpeech) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent not recognized.");
}
else if (result.getReason() == ResultReason.NoMatch) {
System.out.println("NOMATCH: Speech could not be recognized.");
}
else if (result.getReason() == ResultReason.Canceled) {
CancellationDetails cancellation = CancellationDetails.fromResult(result);
System.out.println("CANCELED: Reason=" + cancellation.getReason());
if (cancellation.getReason() == CancellationReason.Error) {
System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode());
System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails());
System.out.println("CANCELED: Did you update the subscription info?");
}
}
// </print_result>
// <skeleton_2>
} catch (Exception ex) {
System.out.println("Unexpected exception: " + ex.getMessage());
assert(false);
System.exit(1);
}
}
}
// </skeleton_2>
Compilare ed eseguire l'app
Premere F11 o selezionare Esegui>Debug. I successivi 15 secondi di input vocale dal microfono verranno riconosciuti e registrati nella finestra della console.
Documentazione di riferimento | Pacchetto (npm) | Ulteriori esempi in GitHub | Codice sorgente della libreria
In questo argomento di avvio rapido si useranno Speech SDK e il servizio LUIS (Language Understanding) per riconoscere le finalità dai dati audio acquisiti da un microfono. In particolare, si userà Speech SDK per acquisire la voce e un dominio predefinito di LUIS per identificare le finalità per la domotica, come l'accensione e lo spegnimento di una luce.
Prerequisiti
- Sottoscrizione di Azure: creare un account gratuito
-
Creare una risorsa di linguaggio nel portale di Azure. È possibile usare il piano tariffario gratuito (
F0) per provare il servizio ed eseguire in un secondo momento l'aggiornamento a un livello a pagamento per la produzione. Questa volta non sarà necessaria una risorsa Voce. - Ottenere la chiave e la regione della risorsa di linguaggio. Dopo aver distribuito la risorsa di linguaggio, selezionare Vai alla risorsa per visualizzare e gestire le chiavi.
È necessario Installare Speech SDK per l'ambiente di sviluppo e creare un progetto di esempio vuoto.
Creare un'app LUIS per il riconoscimento delle finalità
Per completare l'argomento di avvio rapido sul riconoscimento di finalità, è necessario creare un account e un progetto LUIS usando l'anteprima del portale LUIS. Questa guida introduttiva richiede una sottoscrizione LUIS in un'area in cui è disponibile il riconoscimento degli intenti. Non è necessario avere una sottoscrizione del servizio Voce.
Per prima cosa è necessario creare un account e un'app LUIS tramite l'anteprima del portale LUIS. L'app LUIS creata userà un dominio predefinito per la domotica, che fornisce finalità, entità ed espressioni di esempio. Al termine, sarà disponibile un endpoint LUIS in esecuzione nel cloud che è possibile chiamare con Speech SDK.
Per creare l'app LUIS, seguire queste istruzioni:
Al termine, saranno necessari quattro elementi:
- Eseguire di nuovo la pubblicazione con il priming del riconoscimento vocale attivato
- La chiave primaria di LUIS
- La località di LUIS
- L'ID app di LUIS
È possibile trovare queste informazioni nell'anteprima del portale LUIS:
Nel portale di anteprima LUIS selezionare l'app e quindi selezionare il pulsante Pubblica.
Selezionare lo slot di produzione; se si usa
en-US, selezionare Modifica impostazioni e spostare l'opzione Priming vocale sulla posizione On. Quindi selezionare il pulsante Pubblica.Importante
L'opzione di priming del riconoscimento vocale è particolarmente consigliata, in quanto migliorerà l'accuratezza del riconoscimento vocale.
Nell'anteprima del portale LUIS selezionare Gestisci e quindi Risorse di Azure. In questa pagina sono disponibili la chiave e la posizione LUIS (talvolta denominata area) per la risorsa di previsione LUIS.
Una volta ottenute la chiave e l'area, sarà necessario l'ID app. Seleziona Impostazioni. L'ID app è disponibile in questa pagina.
Iniziare con un codice boilerplate
Aggiungere codice che funga da scheletro del progetto.
<!DOCTYPE html>
<html>
<head>
<title>Microsoft Azure AI Speech SDK JavaScript Quickstart</title>
<meta charset="utf-8" />
</head>
<body style="font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; font-size:13px;">
</body>
</html>
Aggiungere elementi dell'interfaccia utente
A questo punto verranno aggiunti elementi di base dell'interfaccia utente per le caselle di input, si farà riferimento al codice JavaScript di Speech SDK e si acquisirà un token di autorizzazione, se disponibile.
Importante
Al termine, ricordarsi di rimuovere la chiave dal codice e non renderlo mai pubblico. Per un ambiente di produzione usare un metodo sicuro per l'archiviazione e l'accesso alle proprie credenziali, ad esempio Azure Key Vault. Per altre informazioni, vedere l'articolo sulla sicurezza del Servizi di Azure AI.
<body style="font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; font-size:13px;">
<div id="content" style="display:none">
<table width="100%">
<tr>
<td></td>
<td><h1 style="font-weight:500;">Microsoft Azure AI Speech SDK JavaScript Quickstart</h1></td>
</tr>
<tr>
<td align="right"><a href="https://video2.skills-academy.com/azure/ai-services/speech-service/overview" target="_blank">Subscription</a>:</td>
<td><input id="subscriptionKey" type="text" size="40" value="subscription"></td>
</tr>
<tr>
<td align="right">Region</td>
<td><input id="serviceRegion" type="text" size="40" value="YourServiceRegion"></td>
</tr>
<tr>
<td align="right">Application ID:</td>
<td><input id="appId" type="text" size="60" value="YOUR_LANGUAGE_UNDERSTANDING_APP_ID"></td>
</tr>
<tr>
<td></td>
<td><button id="startIntentRecognizeAsyncButton">Start Intent Recognition</button></td>
</tr>
<tr>
<td align="right" valign="top">Input Text</td>
<td><textarea id="phraseDiv" style="display: inline-block;width:500px;height:200px"></textarea></td>
</tr>
<tr>
<td align="right" valign="top">Result</td>
<td><textarea id="statusDiv" style="display: inline-block;width:500px;height:100px"></textarea></td>
</tr>
</table>
</div>
<script src="microsoft.cognitiveservices.speech.sdk.bundle.js"></script>
<script>
// Note: Replace the URL with a valid endpoint to retrieve
// authorization tokens for your subscription.
var authorizationEndpoint = "token.php";
function RequestAuthorizationToken() {
if (authorizationEndpoint) {
var a = new XMLHttpRequest();
a.open("GET", authorizationEndpoint);
a.setRequestHeader("Content-Type", "application/x-www-form-urlencoded");
a.send("");
a.onload = function() {
var token = JSON.parse(atob(this.responseText.split(".")[1]));
serviceRegion.value = token.region;
authorizationToken = this.responseText;
subscriptionKey.disabled = true;
subscriptionKey.value = "using authorization token (hit F5 to refresh)";
console.log("Got an authorization token: " + token);
}
}
}
</script>
<script>
// status fields and start button in UI
var phraseDiv;
var statusDiv;
var startIntentRecognizeAsyncButton;
// subscription key, region, and appId for LUIS services.
var subscriptionKey, serviceRegion, appId;
var authorizationToken;
var SpeechSDK;
var recognizer;
document.addEventListener("DOMContentLoaded", function () {
startIntentRecognizeAsyncButton = document.getElementById("startIntentRecognizeAsyncButton");
subscriptionKey = document.getElementById("subscriptionKey");
serviceRegion = document.getElementById("serviceRegion");
appId = document.getElementById("appId");
phraseDiv = document.getElementById("phraseDiv");
statusDiv = document.getElementById("statusDiv");
startIntentRecognizeAsyncButton.addEventListener("click", function () {
startIntentRecognizeAsyncButton.disabled = true;
phraseDiv.innerHTML = "";
statusDiv.innerHTML = "";
});
if (!!window.SpeechSDK) {
SpeechSDK = window.SpeechSDK;
startIntentRecognizeAsyncButton.disabled = false;
document.getElementById('content').style.display = 'block';
document.getElementById('warning').style.display = 'none';
// in case we have a function for getting an authorization token, call it.
if (typeof RequestAuthorizationToken === "function") {
RequestAuthorizationToken();
}
}
});
</script>
Creare una configurazione di Voce
Prima di inizializzare un oggetto SpeechRecognizer, è necessario creare una configurazione che usi la chiave e l'area di sottoscrizione. Inserire questo codice nel metodo startRecognizeOnceAsyncButton.addEventListener().
Nota
Per impostazione predefinita, Speech SDK riconoscerà l'uso di en-us per la lingua. Per informazioni sulla scelta della lingua di origine, vedere Come riconoscere il riconoscimento vocale.
// if we got an authorization token, use the token. Otherwise use the provided subscription key
var speechConfig;
if (authorizationToken) {
speechConfig = SpeechSDK.SpeechConfig.fromAuthorizationToken(authorizationToken, serviceRegion.value);
} else {
if (subscriptionKey.value === "" || subscriptionKey.value === "subscription") {
alert("Please enter your Microsoft Azure AI Speech subscription key!");
return;
}
startIntentRecognizeAsyncButton.disabled = false;
speechConfig = SpeechSDK.SpeechConfig.fromSubscription(subscriptionKey.value, serviceRegion.value);
}
speechConfig.speechRecognitionLanguage = "en-US";
Creare una configurazione audio
Ora è necessario creare un oggetto AudioConfig che punta al dispositivo di input. Inserire questo codice nel metodo startIntentRecognizeAsyncButton.addEventListener(), immediatamente sotto la configurazione di Voce.
var audioConfig = SpeechSDK.AudioConfig.fromDefaultMicrophoneInput();
Inizializzare un oggetto IntentRecognizer
A questo punto, creare l'oggetto IntentRecognizer usando gli oggetti SpeechConfig e AudioConfig creati in precedenza. Inserire questo codice nel metodo startIntentRecognizeAsyncButton.addEventListener().
recognizer = new SpeechSDK.IntentRecognizer(speechConfig, audioConfig);
Aggiungere un oggetto LanguageUnderstandingModel e le finalità
È necessario associare un oggetto LanguageUnderstandingModel allo strumento di riconoscimento di finalità e aggiungere le finalità da riconoscere. Verranno usate le finalità del dominio predefinito per la domotica.
Inserire questo codice sotto IntentRecognizer. Assicurarsi di sostituire "YourLanguageUnderstandingAppId" con l'ID dell'app LUIS.
if (appId.value !== "" && appId.value !== "YOUR_LANGUAGE_UNDERSTANDING_APP_ID") {
var lm = SpeechSDK.LanguageUnderstandingModel.fromAppId(appId.value);
recognizer.addAllIntents(lm);
}
Nota
Speech SDK supporta solo gli endpoint LUIS v2.0. È necessario modificare manualmente l'URL dell'endpoint v3.0 trovato nel campo della query di esempio per usare un modello di URL v2.0. Gli endpoint LUIS v2.0 seguono sempre uno di questi due modelli:
https://{AzureResourceName}.cognitiveservices.azure.com/luis/v2.0/apps/{app-id}?subscription-key={subkey}&verbose=true&q=https://{Region}.api.cognitive.microsoft.com/luis/v2.0/apps/{app-id}?subscription-key={subkey}&verbose=true&q=
Riconoscere una finalità
Dall'oggetto IntentRecognizer chiamare il metodo recognizeOnceAsync(). Questo metodo consente al servizio Voce di rilevare che si sta inviando una singola frase per il riconoscimento e di interrompere il riconoscimento vocale una volta identificata la frase.
Inserire questo codice sotto l'aggiunta del modello:
recognizer.recognizeOnceAsync(
function (result) {
window.console.log(result);
phraseDiv.innerHTML = result.text + "\r\n";
statusDiv.innerHTML += "(continuation) Reason: " + SpeechSDK.ResultReason[result.reason];
switch (result.reason) {
case SpeechSDK.ResultReason.RecognizedSpeech:
statusDiv.innerHTML += " Text: " + result.text;
break;
case SpeechSDK.ResultReason.RecognizedIntent:
statusDiv.innerHTML += " Text: " + result.text + " IntentId: " + result.intentId;
// The actual JSON returned from Language Understanding is a bit more complex to get to, but it is available for things like
// the entity name and type if part of the intent.
statusDiv.innerHTML += " Intent JSON: " + result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
phraseDiv.innerHTML += result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult) + "\r\n";
break;
case SpeechSDK.ResultReason.NoMatch:
var noMatchDetail = SpeechSDK.NoMatchDetails.fromResult(result);
statusDiv.innerHTML += " NoMatchReason: " + SpeechSDK.NoMatchReason[noMatchDetail.reason];
break;
case SpeechSDK.ResultReason.Canceled:
var cancelDetails = SpeechSDK.CancellationDetails.fromResult(result);
statusDiv.innerHTML += " CancellationReason: " + SpeechSDK.CancellationReason[cancelDetails.reason];
if (cancelDetails.reason === SpeechSDK.CancellationReason.Error) {
statusDiv.innerHTML += ": " + cancelDetails.errorDetails;
}
break;
}
statusDiv.innerHTML += "\r\n";
startIntentRecognizeAsyncButton.disabled = false;
},
function (err) {
window.console.log(err);
phraseDiv.innerHTML += "ERROR: " + err;
startIntentRecognizeAsyncButton.disabled = false;
});
Controllare il codice
<!DOCTYPE html>
<html>
<head>
<title>Microsoft Cognitive Services Speech SDK JavaScript Quickstart</title>
<meta charset="utf-8" />
</head>
<body style="font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; font-size:13px;">
<div id="warning">
<h1 style="font-weight:500;">Speech Recognition Speech SDK not found (microsoft.cognitiveservices.speech.sdk.bundle.js missing).</h1>
</div>
<div id="content" style="display:none">
<table width="100%">
<tr>
<td></td>
<td><h1 style="font-weight:500;">Microsoft Cognitive Services Speech SDK JavaScript Quickstart</h1></td>
</tr>
<tr>
<td align="right"><a href="https://docs.microsoft.com/azure/cognitive-services/speech-service/quickstarts/intent-recognition?pivots=programming-language-csharp#create-a-luis-app-for-intent-recognition" target="_blank">LUIS Primary Key</a>:</td>
<td><input id="subscriptionKey" type="text" size="40" value="subscription"></td>
</tr>
<tr>
<td align="right">LUIS Location</td>
<td><input id="serviceRegion" type="text" size="40" value="YourServiceRegion"></td>
</tr>
<tr>
<td align="right">LUIS App ID:</td>
<td><input id="appId" type="text" size="60" value="YOUR_LANGUAGE_UNDERSTANDING_APP_ID"></td>
</tr>
<tr>
<td></td>
<td><button id="startIntentRecognizeAsyncButton">Start Intent Recognition</button></td>
</tr>
<tr>
<td align="right" valign="top">Input Text</td>
<td><textarea id="phraseDiv" style="display: inline-block;width:500px;height:200px"></textarea></td>
</tr>
<tr>
<td align="right" valign="top">Result</td>
<td><textarea id="statusDiv" style="display: inline-block;width:500px;height:100px"></textarea></td>
</tr>
</table>
</div>
<!-- Speech SDK reference sdk. -->
<script src="https://aka.ms/csspeech/jsbrowserpackageraw"></script>
<!-- Speech SDK USAGE -->
<script>
// status fields and start button in UI
var phraseDiv;
var statusDiv;
var startIntentRecognizeAsyncButton;
// subscription key and region for speech services.
var subscriptionKey, serviceRegion, appId;
var SpeechSDK;
var recognizer;
document.addEventListener("DOMContentLoaded", function () {
startIntentRecognizeAsyncButton = document.getElementById("startIntentRecognizeAsyncButton");
subscriptionKey = document.getElementById("subscriptionKey");
serviceRegion = document.getElementById("serviceRegion");
appId = document.getElementById("appId");
phraseDiv = document.getElementById("phraseDiv");
statusDiv = document.getElementById("statusDiv");
startIntentRecognizeAsyncButton.addEventListener("click", function () {
startIntentRecognizeAsyncButton.disabled = true;
phraseDiv.innerHTML = "";
statusDiv.innerHTML = "";
let audioConfig = SpeechSDK.AudioConfig.fromDefaultMicrophoneInput();
if (subscriptionKey.value === "" || subscriptionKey.value === "subscription") {
alert("Please enter your Microsoft Cognitive Services Speech subscription key!");
startIntentRecognizeAsyncButton.disabled = false;
return;
}
var speechConfig = SpeechSDK.SpeechConfig.fromSubscription(subscriptionKey.value, serviceRegion.value);
speechConfig.speechRecognitionLanguage = "en-US";
recognizer = new SpeechSDK.IntentRecognizer(speechConfig, audioConfig);
// Set up a Language Understanding Model from Language Understanding Intelligent Service (LUIS).
// See https://www.luis.ai/home for more information on LUIS.
if (appId.value !== "" && appId.value !== "YOUR_LANGUAGE_UNDERSTANDING_APP_ID") {
var lm = SpeechSDK.LanguageUnderstandingModel.fromAppId(appId.value);
recognizer.addAllIntents(lm);
}
recognizer.recognizeOnceAsync(
function (result) {
window.console.log(result);
phraseDiv.innerHTML = result.text + "\r\n";
statusDiv.innerHTML += "(continuation) Reason: " + SpeechSDK.ResultReason[result.reason];
switch (result.reason) {
case SpeechSDK.ResultReason.RecognizedSpeech:
statusDiv.innerHTML += " Text: " + result.text;
break;
case SpeechSDK.ResultReason.RecognizedIntent:
statusDiv.innerHTML += " Text: " + result.text + " IntentId: " + result.intentId;
// The actual JSON returned from Language Understanding is a bit more complex to get to, but it is available for things like
// the entity name and type if part of the intent.
statusDiv.innerHTML += " Intent JSON: " + result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
phraseDiv.innerHTML += result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult) + "\r\n";
break;
case SpeechSDK.ResultReason.NoMatch:
var noMatchDetail = SpeechSDK.NoMatchDetails.fromResult(result);
statusDiv.innerHTML += " NoMatchReason: " + SpeechSDK.NoMatchReason[noMatchDetail.reason];
break;
case SpeechSDK.ResultReason.Canceled:
var cancelDetails = SpeechSDK.CancellationDetails.fromResult(result);
statusDiv.innerHTML += " CancellationReason: " + SpeechSDK.CancellationReason[cancelDetails.reason];
if (cancelDetails.reason === SpeechSDK.CancellationReason.Error) {
statusDiv.innerHTML += ": " + cancelDetails.errorDetails;
}
break;
}
statusDiv.innerHTML += "\r\n";
startIntentRecognizeAsyncButton.disabled = false;
},
function (err) {
window.console.log(err);
phraseDiv.innerHTML += "ERROR: " + err;
startIntentRecognizeAsyncButton.disabled = false;
});
});
if (!!window.SpeechSDK) {
SpeechSDK = window.SpeechSDK;
startIntentRecognizeAsyncButton.disabled = false;
document.getElementById('content').style.display = 'block';
document.getElementById('warning').style.display = 'none';
}
});
</script>
</body>
</html>
Creare l'origine del token (facoltativo)
Se si vuole ospitare la pagina Web in un server Web, facoltativamente è possibile specificare un'origine del token per l'applicazione demo. In questo modo la chiave di sottoscrizione non lascerà mai il server, consentendo agli utenti di usare le funzionalità di riconoscimento vocale senza dover immettere codici di autorizzazione.
Creare un file denominato token.php. In questo esempio si presuppone che il server Web supporti il linguaggio di scripting PHP con curl abilitato. Immetti il codice seguente:
<?php
header('Access-Control-Allow-Origin: ' . $_SERVER['SERVER_NAME']);
// Replace with your own subscription key and service region (e.g., "westus").
$subscriptionKey = 'YourSubscriptionKey';
$region = 'YourServiceRegion';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'https://' . $region . '.api.cognitive.microsoft.com/sts/v1.0/issueToken');
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, '{}');
curl_setopt($ch, CURLOPT_HTTPHEADER, array('Content-Type: application/json', 'Ocp-Apim-Subscription-Key: ' . $subscriptionKey));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
echo curl_exec($ch);
?>
Nota
I token di autorizzazione hanno una durata limitata. Questo esempio semplificato non illustra come aggiornare automaticamente i token di autorizzazione. Come utente, è possibile ricaricare la pagina manualmente o premere F5 per aggiornare.
Compilare ed eseguire l'esempio in locale
Per avviare l'app, fare doppio clic sul file index.html o aprirlo con il Web browser preferito. Presenterà una semplice interfaccia utente grafica che consente di immettere la chiave LUIS, l'area LUISe l'ID applicazione LUIS. Una volta immessi i campi, è possibile fare clic sul pulsante appropriato per attivare un riconoscimento tramite il microfono.
Nota
Questo metodo non funziona con il browser Safari. In Safari, la pagina Web di esempio deve essere ospitata in un server Web. Safari non consente ai siti Web caricati da un file locale di usare il microfono.
Compilare ed eseguire l'esempio tramite un server Web
Per avviare l'app, aprire il Web browser preferito e passare all'URL pubblico in cui è ospitata la cartella, immettere l'area LUIS oltre all'ID applicazione LUIS e attivare un riconoscimento tramite il microfono. Se il comportamento è configurato, verrà acquisito un token dall'origine del token e verrà avviato il riconoscimento dei comandi vocali.
Documentazione di riferimento | Pacchetto (PyPi) | Ulteriori esempi in GitHub
In questo argomento di avvio rapido si useranno Speech SDK e il servizio LUIS (Language Understanding) per riconoscere le finalità dai dati audio acquisiti da un microfono. In particolare, si userà Speech SDK per acquisire la voce e un dominio predefinito di LUIS per identificare le finalità per la domotica, come l'accensione e lo spegnimento di una luce.
Prerequisiti
- Sottoscrizione di Azure: creare un account gratuito
-
Creare una risorsa di linguaggio nel portale di Azure. È possibile usare il piano tariffario gratuito (
F0) per provare il servizio ed eseguire in un secondo momento l'aggiornamento a un livello a pagamento per la produzione. Questa volta non sarà necessaria una risorsa Voce. - Ottenere la chiave e la regione della risorsa di linguaggio. Dopo aver distribuito la risorsa di linguaggio, selezionare Vai alla risorsa per visualizzare e gestire le chiavi.
È necessario Installare Speech SDK per l'ambiente di sviluppo e creare un progetto di esempio vuoto.
Creare un'app LUIS per il riconoscimento delle finalità
Per completare l'argomento di avvio rapido sul riconoscimento di finalità, è necessario creare un account e un progetto LUIS usando l'anteprima del portale LUIS. Questa guida introduttiva richiede una sottoscrizione LUIS in un'area in cui è disponibile il riconoscimento degli intenti. Non è necessario avere una sottoscrizione del servizio Voce.
Per prima cosa è necessario creare un account e un'app LUIS tramite l'anteprima del portale LUIS. L'app LUIS creata userà un dominio predefinito per la domotica, che fornisce finalità, entità ed espressioni di esempio. Al termine, sarà disponibile un endpoint LUIS in esecuzione nel cloud che è possibile chiamare con Speech SDK.
Per creare l'app LUIS, seguire queste istruzioni:
Al termine, saranno necessari quattro elementi:
- Eseguire di nuovo la pubblicazione con il priming del riconoscimento vocale attivato
- La chiave primaria di LUIS
- La località di LUIS
- L'ID app di LUIS
È possibile trovare queste informazioni nell'anteprima del portale LUIS:
Nel portale di anteprima LUIS selezionare l'app e quindi selezionare il pulsante Pubblica.
Selezionare lo slot di produzione; se si usa
en-US, selezionare Modifica impostazioni e spostare l'opzione Priming vocale sulla posizione On. Quindi selezionare il pulsante Pubblica.Importante
L'opzione di priming del riconoscimento vocale è particolarmente consigliata, in quanto migliorerà l'accuratezza del riconoscimento vocale.
Nell'anteprima del portale LUIS selezionare Gestisci e quindi Risorse di Azure. In questa pagina sono disponibili la chiave e la posizione LUIS (talvolta denominata area) per la risorsa di previsione LUIS.
Una volta ottenute la chiave e l'area, sarà necessario l'ID app. Seleziona Impostazioni. L'ID app è disponibile in questa pagina.
Apri il tuo progetto
- Aprire l'IDE preferito.
- Creare un nuovo progetto e un file denominato
quickstart.py, quindi aprirlo.
Iniziare con un codice boilerplate
Aggiungere codice che funga da scheletro del progetto.
import azure.cognitiveservices.speech as speechsdk
print("Say something...")
Creare una configurazione di Voce
Prima di inizializzare un oggetto IntentRecognizer, è necessario creare una configurazione che usi la chiave e l'area della risorsa di previsione di LUIS.
Inserire questo codice in quickstart.py. Assicurarsi di aggiornare questi valori:
- Sostituire
"YourLanguageUnderstandingSubscriptionKey"con la chiave di previsione di LUIS. - Sostituire
"YourLanguageUnderstandingServiceRegion"con l'area di LUIS. Usare l'identificatore di area corrispondente all'area.
Suggerimento
Per informazioni su come trovare questi valori, vedere Creare un'app LUIS per il riconoscimento delle finalità.
Importante
Al termine, ricordarsi di rimuovere la chiave dal codice e non renderlo mai pubblico. Per un ambiente di produzione usare un metodo sicuro per l'archiviazione e l'accesso alle proprie credenziali, ad esempio Azure Key Vault. Per altre informazioni, vedere l'articolo sulla sicurezza del Servizi di Azure AI.
# Set up the config for the intent recognizer (remember that this uses the Language Understanding key, not the Speech Services key)!
intent_config = speechsdk.SpeechConfig(
subscription="YourLanguageUnderstandingSubscriptionKey",
region="YourLanguageUnderstandingServiceRegion")
Questo esempio crea l'oggetto SpeechConfig usando la chiave e l'area di LUIS. Per un elenco completo dei metodi disponibili, vedere Classe SpeechConfig.
Per impostazione predefinita, Speech SDK riconoscerà l'uso di en-us per la lingua. Per informazioni sulla scelta della lingua di origine, vedere Come riconoscere il riconoscimento vocale.
Inizializzare un oggetto IntentRecognizer
Creare ora un oggetto IntentRecognizer. Inserire questo codice immediatamente sotto la configurazione di Voce.
# Set up the intent recognizer
intent_recognizer = speechsdk.intent.IntentRecognizer(speech_config=intent_config)
Aggiungere un oggetto LanguageUnderstandingModel e le finalità
È necessario associare un oggetto LanguageUnderstandingModel allo strumento di riconoscimento di finalità e aggiungere le finalità da riconoscere. Verranno usate le finalità del dominio predefinito per la domotica.
Inserire questo codice sotto IntentRecognizer. Assicurarsi di sostituire "YourLanguageUnderstandingAppId" con l'ID dell'app LUIS.
Suggerimento
Per informazioni su come trovare questo valore, vedere Creare un'app LUIS per il riconoscimento delle finalità.
# set up the intents that are to be recognized. These can be a mix of simple phrases and
# intents specified through a LanguageUnderstanding Model.
model = speechsdk.intent.LanguageUnderstandingModel(app_id="YourLanguageUnderstandingAppId")
intents = [
(model, "HomeAutomation.TurnOn"),
(model, "HomeAutomation.TurnOff"),
("This is a test.", "test"),
("Switch to channel 34.", "34"),
("what's the weather like", "weather"),
]
intent_recognizer.add_intents(intents)
Questo esempio usa la funzione add_intents() per aggiungere un elenco di finalità definite in modo esplicito. Se si vogliono aggiungere tutte le finalità da un modello, usare add_all_intents(model) e passare il modello.
Riconoscere una finalità
Dall'oggetto IntentRecognizer chiamare il metodo recognize_once(). Questo metodo consente al servizio Voce di rilevare che si sta inviando una singola frase per il riconoscimento e di interrompere il riconoscimento vocale una volta identificata la frase.
Inserire questo codice sotto il modello.
intent_result = intent_recognizer.recognize_once()
Visualizzare i risultati (o gli errori) del riconoscimento
Quando il servizio Voce restituisce il risultato del riconoscimento, in genere lo si usa per qualche scopo. Per semplicità, in questo caso il risultato verrà stampato sulla console.
Sotto la chiamata a recognize_once() aggiungere il codice seguente.
# Check the results
if intent_result.reason == speechsdk.ResultReason.RecognizedIntent:
print("Recognized: \"{}\" with intent id `{}`".format(intent_result.text, intent_result.intent_id))
elif intent_result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized: {}".format(intent_result.text))
elif intent_result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized: {}".format(intent_result.no_match_details))
elif intent_result.reason == speechsdk.ResultReason.Canceled:
print("Intent recognition canceled: {}".format(intent_result.cancellation_details.reason))
if intent_result.cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(intent_result.cancellation_details.error_details))
Controllare il codice
A questo punto l'aspetto del codice sarà simile al seguente.
Nota
In questa versione sono stati aggiunti alcuni commenti.
# Copyright (c) Microsoft. All rights reserved.
# Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
# <skeleton>
import azure.cognitiveservices.speech as speechsdk
print("Say something...")
# </skeleton>
"""performs one-shot intent recognition from input from the default microphone"""
# <create_speech_configuration>
# Set up the config for the intent recognizer (remember that this uses the Language Understanding key, not the Speech Services key)!
intent_config = speechsdk.SpeechConfig(
subscription="YourLanguageUnderstandingSubscriptionKey",
region="YourLanguageUnderstandingServiceRegion")
# </create_speech_configuration>
# <create_intent_recognizer>
# Set up the intent recognizer
intent_recognizer = speechsdk.intent.IntentRecognizer(speech_config=intent_config)
# </create_intent_recognizer>
# <add_intents>
# set up the intents that are to be recognized. These can be a mix of simple phrases and
# intents specified through a LanguageUnderstanding Model.
model = speechsdk.intent.LanguageUnderstandingModel(app_id="YourLanguageUnderstandingAppId")
intents = [
(model, "HomeAutomation.TurnOn"),
(model, "HomeAutomation.TurnOff"),
("This is a test.", "test"),
("Switch to channel 34.", "34"),
("what's the weather like", "weather"),
]
intent_recognizer.add_intents(intents)
# </add_intents>
# To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
# intent_recognizer.add_all_intents(model)
# Starts intent recognition, and returns after a single utterance is recognized. The end of a
# single utterance is determined by listening for silence at the end or until a maximum of about 30
# seconds of audio is processed. It returns the recognition text as result.
# Note: Since recognize_once() returns only a single utterance, it is suitable only for single
# shot recognition like command or query.
# For long-running multi-utterance recognition, use start_continuous_recognition() instead.
# <recognize_intent>
intent_result = intent_recognizer.recognize_once()
# </recognize_intent>
# <print_results>
# Check the results
if intent_result.reason == speechsdk.ResultReason.RecognizedIntent:
print("Recognized: \"{}\" with intent id `{}`".format(intent_result.text, intent_result.intent_id))
elif intent_result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized: {}".format(intent_result.text))
elif intent_result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized: {}".format(intent_result.no_match_details))
elif intent_result.reason == speechsdk.ResultReason.Canceled:
print("Intent recognition canceled: {}".format(intent_result.cancellation_details.reason))
if intent_result.cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(intent_result.cancellation_details.error_details))
# </print_results>
Compilare ed eseguire l'app
Eseguire l'esempio dalla console o nell'IDE:
python quickstart.py
I successivi 15 secondi di input vocale dal microfono verranno riconosciuti e registrati nella finestra della console.
Documentazione di riferimento | Pacchetto (Go) | Ulteriori esempi in GitHub
Speech SDK per Go non supporta il riconoscimento dell'intento. Selezionare un altro linguaggio di programmazione oppure vedere le informazioni di riferimento e gli esempi collegati all'inizio dell'articolo.
Documentazione di riferimento | Pacchetto (download) | Ulteriori esempi in GitHub
Speech SDK per Objective-C supporta il riconoscimento degli intenti, ma in questa documentazione non è stata ancora inclusa la relativa guida. Selezionare un altro linguaggio di programmazione per iniziare ad apprendere i relativi concetti oppure vedere le informazioni di riferimento e gli esempi di Objective-C collegati all'inizio dell'articolo.
Documentazione di riferimento | Pacchetto (download) | Ulteriori esempi in GitHub
Speech SDK per Swift supporta il riconoscimento degli intenti, ma in questa documentazione non è stata ancora inclusa la relativa guida. Seleziona un altro linguaggio di programmazione per iniziare a conoscere i concetti oppure vedere le informazioni di riferimento e gli esempi di Swift collegati all'inizio dell'articolo.
Informazioni di riferimento sull'API REST di riconoscimento vocale | Informazioni di riferimento sull'API REST di riconoscimento vocale per audio brevi | Ulteriori esempi in GitHub
È possibile usare l'API REST per il riconoscimento degli intenti, ma non è ancora disponibile una guida. Selezionare un altro linguaggio di programmazione per iniziare e ottenere informazioni sui concetti.
L'interfaccia della riga di comando (CLI) di Voce supporta il riconoscimento degli intenti, ma non è ancora stata inclusa una guida qui. Selezionare un altro linguaggio di programmazione per iniziare e ottenere informazioni sui concetti oppure vedere Panoramica sull'interfaccia della riga di comando (CLI) di Voce per altre informazioni sull'interfaccia della riga di comando.