Che cos'è osservabilità avanzata della rete
Osservabilità avanzata della rete è una funzionalità innovativa della suite di servizi avanzati di rete per contenitori. Offre strumenti di monitoraggio e diagnostica di livello superiore, dando una visibilità senza precedenti sui carichi di lavoro in contenitori. Questi strumenti consentono di individuare e risolvere facilmente i problemi di rete, garantendo prestazioni ottimali per le applicazioni.
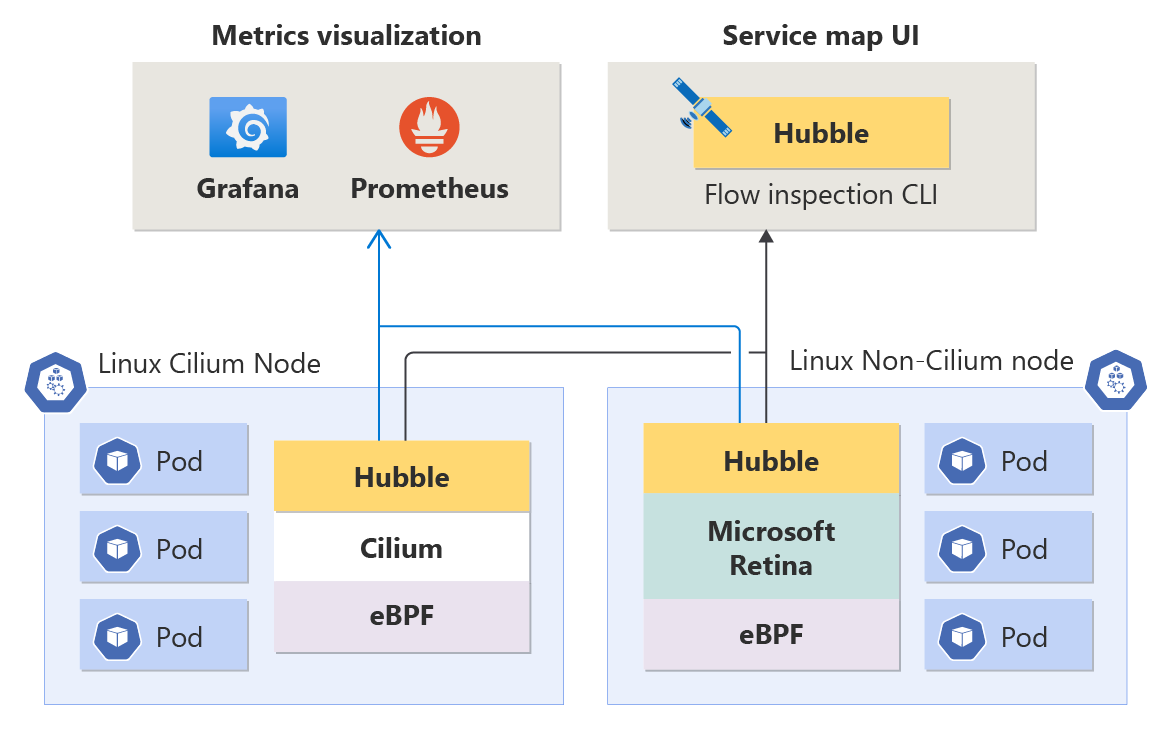
Osservabilità avanzata della rete è compatibile con tutti i carichi di lavoro Linux che si integrano facilmente con Hubble, indipendentemente dal fatto che il piano dati sottostante sia Cilium o non Cilium (entrambi supportati), garantendo flessibilità per le esigenze di rete dei contenitori.
Nota
Per gli scenari del piano dati Cilium, osservabilità avanzata della rete è disponibile a partire dalla versione 1.29 di Kubernetes. Per gli scenari del piano dati non Cilium, osservabilità avanzata della rete è supportata in tutte le distribuzioni Linux, tra cui Azure Linux a partire dalla versione 2.0.
Funzionalità di osservabilità avanzata della rete
Osservabilità avanzata della rete offre le funzionalità seguenti per monitorare i problemi correlati alla rete nel cluster:
Metriche a livello di nodo: comprendere l'integrità della rete del contenitore a livello di nodo è fondamentale per mantenere le prestazioni ottimali dell'applicazione. Queste metriche forniscono informazioni dettagliate su volume del traffico, pacchetti eliminati, numero di connessioni e così via per ciascun nodo. Le metriche vengono archiviate in formato Prometheus e, di conseguenza, è possibile visualizzarle in Grafana.
Metriche Hubble (metriche DNS e a livello di pod): queste metriche Prometheus includono informazioni sui pod di origine e di destinazione, che consentono di individuare i problemi relativi alla rete a livello granulare. Le metriche riguardano il volume del traffico, i pacchetti eliminati, le reimpostazioni TCP, i flussi di pacchetti L4/L7 e così via. Esistono anche metriche DNS (attualmente solo per i piani dati non Cilium), che coprono gli errori DNS e le richieste DNS mancanti.
Log dei flussi Hubble: i log dei flussi offrono una visibilità approfondita dell'attività di rete del cluster. Tutte le comunicazioni da e verso i pod vengono registrate, consentendo di analizzare i problemi di connettività nel tempo. I log dei flussi consentono di rispondere a domande quali: il server ha ricevuto la richiesta del client? Qual è la latenza di round trip tra la richiesta del client e la risposta del server?
Interfaccia della riga di comando di Hubble: può recuperare i log dei flussi nell'intero cluster mediante filtri e formattazioni personalizzabili.
Interfaccia utente Hubble: intuitiva e basata su browser, per l'esplorazione dell'attività di rete del cluster. Crea un grafico di connessione al servizio basato sui log dei flussi e li visualizza per lo spazio dei nomi selezionato. Gli utenti sono responsabili del provisioning e della gestione dell'infrastruttura necessaria per eseguire l'interfaccia utente di Hubble.
Vantaggi principali di osservabilità avanzata della rete
Indipendente da CNI: supportata in tutte le varianti Azure CNI, incluso kubenet.
Cilium e non Cilium: offre un'esperienza uniforme e senza interruzioni nei piani dati Cilium e non Cilium.
Osservabilità della rete basata su eBPF: sfrutta eBPF (extended Berkeley Packet Filter) per ottenere prestazioni e scalabilità, in modo da identificare potenziali colli di bottiglia e problemi di congestione, prima che influiscano sulle prestazioni dell'applicazione. Consente di ottenere informazioni dettagliate sugli indicatori chiave di integrità della rete, inclusi il volume del traffico, i pacchetti eliminati e le informazioni di connessione.
Visibilità approfondita sull'attività di rete: permette di comprendere come le applicazioni comunicano tra loro mediante log dettagliati dei flussi di rete.
Opzioni semplificate di archiviazione e visualizzazione delle metriche: scegliere tra:
- Prometheus gestito di Azure e Grafana: Azure gestisce l'infrastruttura e la manutenzione, consentendo agli utenti di concentrarsi sulla configurazione e sulla visualizzazione delle metriche.
- Bring Your Own (BYO) di Prometheus e Grafana: gli utenti distribuiscono e configurano le proprie istanze, gestendo l'infrastruttura sottostante.
Metrica
Metriche a livello di nodo
Le metriche seguenti vengono aggregate per ciascun nodo. Tutte le metriche includono etichette:
clusterinstance(nome nodo)
Per gli scenari del piano dati non Cilium, osservabilità avanzata della rete fornisce metriche per i sistemi operativi Linux e Windows. La tabella seguente illustra le diverse metriche generate.
| Nome misurazione | Descrizione | Etichette aggiuntive | Linux | Windows |
|---|---|---|---|---|
| networkobservability_forward_count | Numero totale di pacchetti inoltrati | direction |
✅ | ✅ |
| networkobservability_forward_bytes | Totale conteggio byte inoltrati | direction |
✅ | ✅ |
| networkobservability_drop_count | Totale conteggio pacchetti eliminati | direction, reason |
✅ | ✅ |
| networkobservability_drop_bytes | Totale conteggio byte eliminati | direction, reason |
✅ | ✅ |
| networkobservability_tcp_state | Numero di socket TCP attualmente attivi in base allo stato TCP. | state |
✅ | ✅ |
| networkobservability_tcp_connection_remote | Numero di socket TCP attualmente attivi in base all'IP/porta remota. | address (IP), port |
✅ | ❌ |
| networkobservability_tcp_connection_stats | Statistiche sulla connessione TCP. (ad esempio: ACL ritardati, TCPKeepAlive, TCPSackFailures) | statistic |
✅ | ✅ |
| networkobservability_tcp_flag_counters | Numero di pacchetti TCP per flag. | flag |
❌ | ✅ |
| networkobservability_ip_connection_stats | Statistiche sulla connessione IP. | statistic |
✅ | ❌ |
| networkobservability_udp_connection_stats | Statistiche di connessione UDP. | statistic |
✅ | ❌ |
| networkobservability_udp_active_sockets | Numero di socket UDP attualmente attivi | ✅ | ❌ | |
| networkobservability_interface_stats | Statistiche dell'interfaccia. | InterfaceName, statistic |
✅ | ✅ |
Metriche a livello di pod (metriche Hubble)
Le metriche seguenti vengono aggregate per ogni pod, mantenendo le informazioni sul nodo. Tutte le metriche includono etichette:
clusterinstance(nome nodo)sourceoppuredestination
Per il traffico in uscita, sarà presente un'etichetta source con spazio dei nomi/nome del pod di origine.
Per il traffico in ingresso, sarà presente un'etichetta destination con spazio dei nomi/nome del pod di destinazione.
| Nome misurazione | Descrizione | Etichette aggiuntive | Linux | Windows |
|---|---|---|---|---|
| hubble_dns_queries_total | Totale richieste DNS per query | source o destination, query, qtypes (tipo di query) |
✅ | ❌ |
| hubble_dns_responses_total | Risposte DNS totali per query/risposta | source o destination, query, qtypes (tipo di query), rcode (codice restituito), ips_returned (numero di indirizzi IP) |
✅ | ❌ |
| hubble_drop_total | Totale conteggio pacchetti eliminati | source o destination, protocol, reason |
✅ | ❌ |
| hubble_tcp_flags_total | Numero totale di pacchetti TCP per flag. | source o destination, flag |
✅ | ❌ |
| hubble_flows_processed_total | Flussi di rete totali elaborati (traffico L4/L7) | source o destination, protocol, verdict, type, subtype |
✅ | ❌ |
Limiti
- Le metriche a livello di pod sono disponibili solo in Linux.
- Il piano dati Cilium è supportato a partire dalla versione 1.29 di Kubernetes.
- Le etichette delle metriche possono avere differenze sottili tra i cluster Cilium e non Cilium.
- Il piano dati Cilium attualmente non supporta le metriche DNS.
Ridimensiona
Prometheus gestito di Azure e Grafana impongono limitazioni di scalabilità specifiche del servizio. Per altre informazioni, vedere metriche Scrape Prometheus su larga scala in Monitoraggio di Azure
Passaggi successivi
Per altre informazioni sui servizi avanzati di rete per contenitori per il servizio Azure Kubernetes, vedere Che cosa sono i servizi avanzati di rete per contenitori per il servizio Azure Kubernetes?.
Per creare un cluster del servizio Azure Kubernetes con osservabilità avanzata della rete e Prometheus gestito di Azure e Grafana, vedere Configurare osservabilità avanzata della rete per il servizio Azure Kubernetes gestito da Azure Prometheus e Grafana.
Per creare un cluster del servizio Azure Kubernetes con osservabilità avanzata della rete e BYO di Prometheus e Grafana, vedere Configurare osservabilità avanzata della rete per il servizio Azure Kubernetes BYO Prometheus e Grafana.

Azure Kubernetes Service