Panoramica della disponibilità elevata e del ripristino di emergenza per il servizio Azure Kubernetes (AKS)
Quando si creano e si gestiscono applicazioni nel cloud, esiste sempre il rischio di interruzioni da interruzioni e emergenze. Per garantire la continuità aziendale (BC), è necessario pianificare la disponibilità elevata e il ripristino di emergenza.
La disponibilità elevata si riferisce alla progettazione e all'implementazione di un sistema o di un servizio altamente affidabile ed è in grado di ridurre al minimo i tempi di inattività. La disponibilità elevata è una combinazione di strumenti, tecnologie e processi che assicurano che un sistema o un servizio sia disponibile per eseguire la funzione prevista. La disponibilità elevata è un componente fondamentale della pianificazione del ripristino di emergenza. Il ripristino di emergenza è il processo di ripristino da un'emergenza e il ripristino delle operazioni aziendali in uno stato normale. Il ripristino di emergenza è un subset di BC, che è il processo di gestione delle funzioni aziendali o la ripresa rapida in caso di grave interruzione.
Questo articolo illustra alcune procedure consigliate per le applicazioni distribuite nel servizio Azure Kubernetes, ma non è un elenco completo di possibili soluzioni.
Panoramica della tecnologia
Un cluster Kubernetes è suddiviso in due componenti:
- Il Piano di controllo offre i servizi Kubernetes di base e l'orchestrazione dei carichi di lavoro dell'applicazione e
- I nodi che eseguono i carichi di lavoro dell'applicazione.
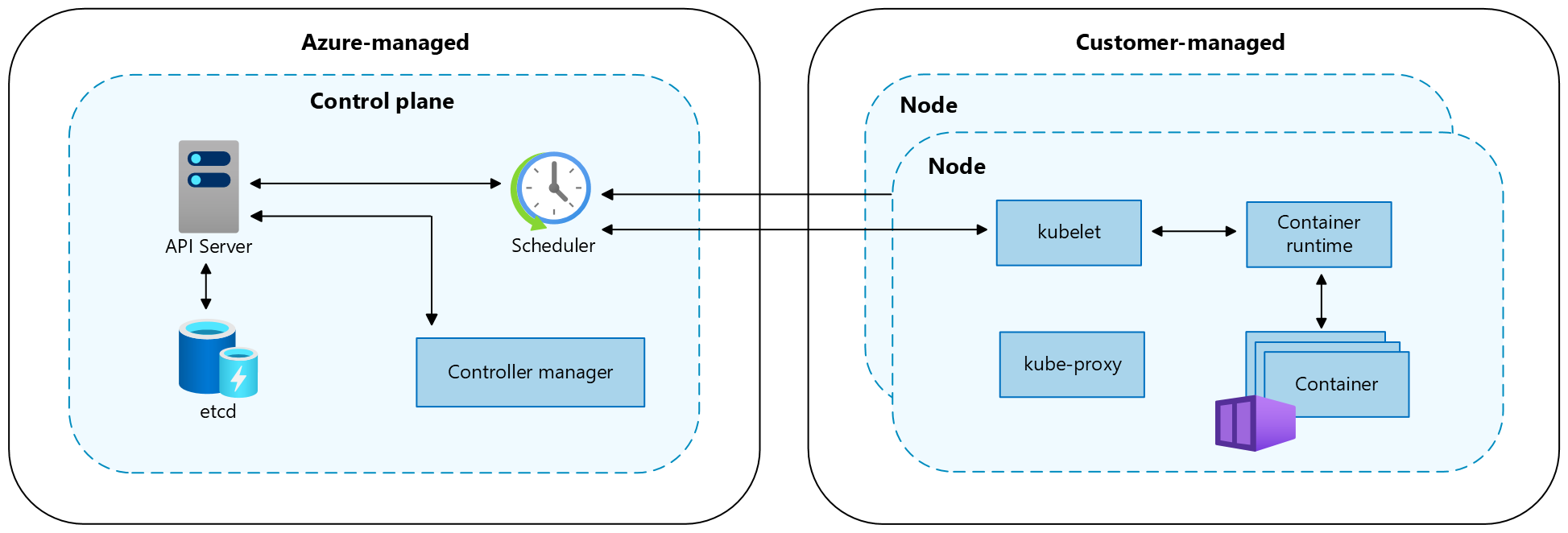
Quando si crea un cluster del servizio Azure Kubernetes, la piattaforma Azure crea e configura automaticamente un piano di controllo. Il servizio Azure Kubernetes offre due piani tariffari per la gestione dei cluster: il livello gratuito e il livello Standard. Per altre informazioni, vedere Piani tariffari Gratuito e Standard per la gestione dei cluster del servizio Azure Kubernetes.
Il piano di controllo e le relative risorse si trovano solo nell'area in cui è stato creato il cluster. AKS fornisce un piano di controllo single-tenant con un server API dedicato, uno scheduler, ecc. L'utente definisce il numero e la dimensioni dei nodi mentre la piattaforma Azure configura la comunicazione sicura tra il piano di controllo e i nodi. L'interazione con il piano din controllo si verifica mediante le API di Kubernetes, ad esempio kubectl o il dashboard di Kubernetes.
Per eseguire le applicazioni e i servizi di supporto, è necessario un nodo Kubernetes. Un cluster AKS ha almeno un nodo, una macchina virtuale (VM) Azure che esegue i componenti del nodo Kubernetes e il runtime dei contenitori. Le dimensioni delle macchine virtuali di Azure per i nodi definiscono CPU, memoria, dimensioni e tipo di archiviazione disponibile, ad esempio UNITÀ SSD a prestazioni elevate o HDD standard. Pianificare la macchina virtuale e le dimensioni di archiviazione per determinare se le applicazioni possono richiedere grandi quantità di CPU e memoria o archiviazione ad alte prestazioni. Nel servizio Azure Kubernetes l'immagine della macchina virtuale per i nodi del cluster si basa su Ubuntu Linux, Azure Linuxo Windows Server 2022. Quando si crea un cluster AKS o si riduce il numero di nodi, la piattaforma Azure crea e configura automaticamente il numero di macchine virtuali richiesto.
Per altre informazioni sui componenti del cluster e del carico di lavoro nel servizio Azure Kubernetes, vedere Concetti di base di Kubernetes per il servizio Azure Kubernetes.
Considerazioni importanti
Risorse internazionali e globali
Il provisioning delle risorse a livello di area viene effettuato come parte di un timbro di distribuzione in una singola area di Azure. Queste risorse non condividono nulla con le risorse in altre aree e possono essere rimosse o replicate in modo indipendente in altre aree. Per altre informazioni, vedere Risorse regionali.
Le risorse globali condividono la durata del sistema e possono essere disponibili a livello globale nel contesto di una distribuzione in più aree. Per altre informazioni, vedere Risorse globali.
Obiettivi di ripristino
Un piano di ripristino di emergenza completo deve specificare i requisiti aziendali per ogni processo implementato dall'applicazione:
- Obiettivo del punto di ripristino (RPO): è la durata massima di perdita dei dati accettabile. RPO viene misurato in unità di tempo, ad esempio minuti, ore o giorni.
- L'obiettivo del tempo di ripristino (RTO) è la durata massima del tempo di inattività accettabile, con tempi di inattività definiti dalla specifica. Ad esempio, se la durata del tempo di inattività accettabile in un'emergenza è otto ore, l'obiettivo RTO è otto ore.
Zone di disponibilità
È possibile usare le zone di disponibilità per distribuire i dati tra più zone nella stessa area. All'interno di un'area, le zone di disponibilità sono sufficienti per avere connessioni a bassa latenza ad altre zone di disponibilità, ma sono sufficientemente distanti per ridurre la probabilità che più di una sia influenzata da interruzioni locali o meteo. Per altre informazioni, vedere Raccomandazioni per l'uso di zone e aree di disponibilità.
Resilienza di zona
I cluster del servizio Azure Kubernetes sono resilienti agli errori di zona. Se una zona ha esito negativo, il cluster continua a essere eseguito nelle zone rimanenti. Il piano di controllo e i nodi del cluster vengono distribuiti tra le zone e la piattaforma Azure gestisce automaticamente la distribuzione dei nodi. Per altre informazioni, vedere Resilienza di zona del servizio Azure Kubernetes.
Bilanciamento del carico
Bilanciamento del carico globale
I servizi di bilanciamento del carico globali distribuiscono il traffico tra back-end a livello di area, cloud o servizi locali ibridi. Questi servizi instradano il traffico dell'utente finale al back-end disponibile più vicino. Reagiscono anche alle modifiche apportate all'affidabilità o alle prestazioni del servizio per ottimizzare la disponibilità e le prestazioni. I servizi di Azure seguenti offrono il bilanciamento del carico globale:
- Frontdoor di Azure
- Gestione traffico di Azure
- Azure Load Balancer tra aree
- Gestione flotta Kubernetes di Azure
Bilanciamento del carico a livello di area
I servizi di bilanciamento del carico a livello di area distribuiscono il traffico all'interno di reti virtuali tra macchine virtuali o endpoint di servizio di zona e con ridondanza della zona all'interno di un'area. I servizi di Azure seguenti offrono il bilanciamento del carico a livello di area:
Osservabilità
È necessario raccogliere dati dalle applicazioni e dall'infrastruttura per consentire operazioni efficaci e ottimizzare l'affidabilità. Azure offre strumenti che consentono di monitorare e gestire i carichi di lavoro del servizio Azure Kubernetes. Per altre informazioni, vedere Risorse di osservabilità.
Definizione degli ambiti
Il tempo di attività dell'applicazione diventa importante quando si gestiscono i cluster del servizio Azure Kubernetes. Per impostazione predefinita, il servizio Azure Kubernetes offre disponibilità elevata usando più nodi in un set di scalabilità di macchine virtuali, ma questi nodi non proteggono il sistema da un errore di area. Per ottimizzare il tempo di attività, pianificare in anticipo la continuità aziendale e prepararsi al ripristino di emergenza usando le procedure consigliate seguenti:
- Eseguire la pianificazione per i cluster del servizio Azure Kubernetes in più aree.
- Indirizzare il traffico tra più cluster con Gestione traffico di Azure.
- Usare la replica geografica per i registri di immagini del contenitore.
- Eseguire la pianificazione dello stato dell'applicazione in più cluster.
- Replicare l'archiviazione tra più aree.
Implementazioni del modello di distribuzione
| Modello di distribuzione | Vantaggi | Svantaggi |
|---|---|---|
| Attivo/attivo | • Nessuna perdita di dati o incoerenza durante il failover • Resilienza elevata • Migliore utilizzo delle risorse con prestazioni più elevate |
• Implementazione e gestione complesse • Costo più alto • Richiede un servizio di bilanciamento del carico e una forma di routing del traffico |
| Attivo-passivo | • Implementazione e gestione più semplici • Costi ridotti • Non richiede un servizio di bilanciamento del carico o una gestione traffico |
• Potenziale di perdita o incoerenza dei dati durante il failover • Tempi di ripristino e tempi di inattività più lunghi • Sottoutilizzazione delle risorse |
| Passivo-cold | • Costo più basso • Non richiede sincronizzazione, replica, bilanciamento del carico o gestione traffico • Adatto per carichi di lavoro non critici e con priorità bassa |
• Rischio elevato di perdita o incoerenza dei dati durante il failover • Tempo di ripristino e tempi di inattività più lunghi • Richiede un intervento manuale per attivare il cluster e attivare il backup |
Modello di distribuzione a disponibilità elevata attiva-attiva
Nel modello di distribuzione disponibilità elevata attiva-attiva sono distribuiti due cluster del servizio Azure Kubernetes indipendenti in due aree di Azure diverse (in genere aree abbinate, ad esempio Canada centrale e Canada orientale o Stati Uniti orientali 2 e Stati Uniti centrali) che gestiscono attivamente il traffico.
Con questa architettura di esempio:
- Si distribuiscono due cluster del servizio Azure Kubernetes in aree di Azure separate.
- Durante le normali operazioni, il traffico di rete viene instradato tra entrambe le aree. Se un'area non è più disponibile, il traffico instrada automaticamente a un'area più vicina all'utente che ha inviato la richiesta.
- È disponibile una coppia hub-spoke distribuita per ogni istanza del servizio Azure Kubernetes a livello di area. I criteri di Gestione firewall di Azure gestiscono le regole del firewall in ogni area.
- Viene effettuato il provisioning di Azure Key Vault in ogni area per archiviare segreti e chiavi.
- Il servizio Front Door di Azure bilancia il carico e instrada il traffico verso un'istanza regionale di del gateway applicazione di Azure, che si trova davanti a ciascun cluster AKS.
- Le istanze regionali di Log Analytics memorizzano le metriche di rete e i log diagnostici regionali.
- Le immagini dei contenitori per il carico di lavoro sono memorizzate in un registro di container gestito. Un singolo Registro Azure Container viene usato per tutte le istanze di Kubernetes nel cluster. La replica geografica per il registro Azure Container consente di replicare le immagini nelle regioni Azure selezionate e di continuare ad accedere alle immagini, anche se una regione subisce un'interruzione.
Per creare un modello di distribuzione attivo-attivo nel servizio Azure Kubernetes, seguire questa procedura:
Creare due distribuzioni identiche in due aree di Azure diverse.
Creare due istanze di un'app Web.
Creare un profilo frontdoor di Azure con le risorse seguenti:
- Endpoint.
- Due gruppi di origine, ognuno con priorità uno.
- Un itinerario.
Limitare il traffico di rete alle app Web solo dall'istanza di Frontdoor di Azure. 5. Configurare tutti gli altri servizi back-end di Azure, ad esempio database, account di archiviazione e provider di autenticazione.
Distribuire il codice in entrambe le app Web con distribuzione continua.
Per altre informazioni, vedere Panoramica della soluzione di disponibilità elevata attiva-attiva consigliata per il servizio Azure Kubernetes.
Modello di distribuzione del ripristino di emergenza attivo-passivo
Nel modello di distribuzione del ripristino di emergenza attivo-passivo sono disponibili due cluster del servizio Azure Kubernetes indipendenti distribuiti in due aree di Azure diverse (in genere aree abbinate, ad esempio Canada centrale e Canada orientale o Stati Uniti orientali 2 e Stati Uniti centrali) che gestiscono attivamente il traffico. Solo uno dei cluster gestisce attivamente il traffico in qualsiasi momento. L'altro cluster contiene gli stessi dati di configurazione e applicazione del cluster attivo, ma non accetta il traffico a meno che non venga indirizzato da una gestione traffico.
Con questa architettura di esempio:
- Si distribuiscono due cluster del servizio Azure Kubernetes in aree di Azure separate.
- Durante le normali operazioni, il traffico di rete viene instradato verso il cluster AKS primario, impostato nella configurazione di Front Door Azure.
- La priorità deve essere impostata tra 1-5 e 1 è la più alta e 5 è la più bassa.
- È possibile impostare più cluster allo stesso livello di priorità e specificare il peso di ciascuno.
- Se il cluster primario diventa indisponibile (si verifica un disastro), il traffico viene instradato automaticamente verso la regione successiva selezionata in Front Door di Azure.
- Tutto il traffico deve passare attraverso Gestione traffico di Frontdoor di Azure per consentire il funzionamento del sistema.
- Frontdoor di Azure instrada il traffico al gateway applicazione di Azure nell'area primaria (il cluster deve essere contrassegnato con priorità 1). Se l'area non riesce, il servizio reindirizza il traffico al cluster successivo nell'elenco di priorità.
- Le regole provengono da Frontdoor di Azure.
- Una coppia hub-spoke viene distribuita per ogni istanza del servizio Azure Kubernetes a livello di area. I criteri di Gestione firewall di Azure gestiscono le regole del firewall in ogni area.
- Viene effettuato il provisioning di Azure Key Vault in ogni area per archiviare segreti e chiavi.
- Le istanze regionali di Log Analytics memorizzano le metriche di rete e i log diagnostici regionali.
- Le immagini dei contenitori per il carico di lavoro sono memorizzate in un registro di container gestito. Un singolo Registro Azure Container viene usato per tutte le istanze di Kubernetes nel cluster. La replica geografica per il registro Azure Container consente di replicare le immagini nelle regioni Azure selezionate e di continuare ad accedere alle immagini, anche se una regione subisce un'interruzione.
Per creare un modello di distribuzione attivo-passivo nel servizio Azure Kubernetes, seguire questa procedura:
Creare due distribuzioni identiche in due aree di Azure diverse.
Configurare le regole di scalabilità automatica per l'applicazione secondaria in modo che venga ridimensionata allo stesso numero di istanze del database primario quando l'area primaria diventa inattiva. Anche se inattivo, non è necessario aumentare le prestazioni. Ciò consente di ridurre i costi.
Creare due istanze dell'applicazione Web, con una in ogni cluster.
Creare un profilo frontdoor di Azure con le risorse seguenti:
- Endpoint.
- Un gruppo di origine con priorità uno per l'area primaria.
- Un secondo gruppo di origine con priorità due per l'area secondaria.
- Un itinerario.
Limitare il traffico di rete alle applicazioni Web solo dall'istanza di Frontdoor di Azure.
Configurare tutti gli altri servizi back-end di Azure, ad esempio database, account di archiviazione e provider di autenticazione.
Distribuire il codice in entrambe le applicazioni Web con distribuzione continua.
Per altre informazioni, vedere Panoramica della soluzione consigliata per il ripristino di emergenza attivo-passivo per il servizio Azure Kubernetes.
Modello di distribuzione del failover a freddo passivo
Il modello di distribuzione del failover passivo a freddo viene configurato allo stesso modo del modello di distribuzione del ripristino di emergenza attivo-passivo, ad eccezione dei cluster che rimangono inattivi fino a quando un utente non li attiva in caso di emergenza. Questo approccio non rientra nell'ambito perché prevede una configurazione simile a quella attiva-passiva, ma con la complessità aggiuntiva dell'intervento manuale per attivare il cluster e attivare un backup.
Con questa architettura di esempio:
- È possibile creare due cluster del servizio Azure Kubernetes, preferibilmente in aree o zone diverse per migliorare la resilienza.
- Quando è necessario eseguire il failover, attivare la distribuzione per assumere il flusso del traffico.
- Nel caso in cui il cluster passivo primario sia inattivo, è necessario attivare manualmente il cluster a freddo per assumere il flusso del traffico.
- Questa condizione deve essere impostata da un input manuale ogni volta o da un determinato evento, come specificato dall'utente.
- Viene effettuato il provisioning di Azure Key Vault in ogni area per archiviare segreti e chiavi.
- Le istanze regionali di Log Analytics memorizzano le metriche di rete regionali e i log diagnostici per ogni cluster.
Per creare un modello di distribuzione di failover passivo a freddo nel servizio Azure Kubernetes, seguire questa procedura:
- Creare due distribuzioni identiche in zone/aree diverse.
- Configurare le regole di scalabilità automatica per l'applicazione secondaria in modo che venga ridimensionata allo stesso numero di istanze del database primario quando l'area primaria diventa inattiva. Anche se inattivo, non è necessario aumentare le prestazioni, riducendo così i costi.
- Creare due istanze dell'applicazione Web, con una in ogni cluster.
- Configurare tutti gli altri servizi back-end di Azure, ad esempio database, account di archiviazione e provider di autenticazione.
- Impostare una condizione quando deve essere attivato il cluster ad accesso sporadico. Se necessario, è possibile usare un servizio di bilanciamento del carico.
Per altre informazioni, vedere La panoramica della soluzione di failover passivo a freddo consigliata per il servizio Azure Kubernetes.
Quote e limiti del servizio
Il servizio Azure Kubernetes imposta limiti e quote predefiniti per risorse e funzionalità, incluse le restrizioni di utilizzo per determinati SKU di macchine virtuali.
| Conto risorse | Limite |
|---|---|
| Numero massimo di cluster per sottoscrizione a livello globale | 5,000 |
| Numero massimo di cluster per sottoscrizione per area 1 | 100 |
| Numero massimo di nodi per cluster con set di scalabilità di macchine virtuali e SKU di Load Balancer Standard | 5.000 in tutti i pool di nodi Nota: se non è possibile aumentare le prestazioni fino a 5.000 nodi per cluster, vedere Procedure consigliate per cluster di grandi dimensioni. |
| Numero massimo per pool di nodi (pool di nodi dei set di scalabilità di macchine virtuali) | 1000 |
| Numero massimo di pool di nodi per cluster | 100 |
| Numero massimo di pod per nodo: con plug-in di rete Kubenet1 | Numero massimo: 250 Impostazione predefinita dell'interfaccia della riga di comando di Azure: 110 Impostazione predefinita del modello di Azure Resource Manager: 110 Impostazione predefinita della distribuzione del portale di Azure: 30 |
| Numero massimo di pod per nodo: con Azure Container Networking Interface (Azure CNI)2 | Numero massimo: 250 Numero massimo consigliato per i contenitori di Windows Server: 110 Valore predefinito: 30 |
| Aprire il componente aggiuntivo Service Mesh del servizio Azure Kubernetes | Versione del cluster Kubernetes: versioni supportate del servizio Azure Kubernetes Controller OSM per cluster: 1 Pod per controller OSM: 1600 Account del servizio Kubernetes gestiti da OSM: 160 |
| Numero massimo di servizi Kubernetes con carico bilanciato per cluster con SKU Load Balancer Standard | 300 |
| Numero massimo di nodi per cluster con set di disponibilità di macchine virtuali e SKU Basic di Load Balancer | 100 |
1 Possibilità di aggiungerne su richiesta.
2 I contenitori di Windows Server devono usare il plug-in di rete Azure CNI. Kubenet non è supportato per i contenitori di Windows Server.
| Livello piano di controllo Kubernetes | Limite |
|---|---|
| Livello Standard | Ridimensiona automaticamente il server API di Kubernetes in base al carico. Limiti maggiori dei componenti del piano di controllo e istanze di server API/ecc. |
| Livello gratuito | Risorse limitate con limite di 50 richieste mutevoli e 100 di sola lettura. Limite di nodi consigliato pari a 10 nodi per cluster. Ideale per esperimenti, apprendimento e test semplici. Non consigliato per carichi di lavoro di produzione/critici. |
Per altre informazioni, vedere Quote e limiti del servizio Batch.
Backup
Backup di Azure supporta il backup delle risorse del cluster del servizio Azure Kubernetes e dei volumi permanenti collegati al cluster usando un'estensione di backup. L'insieme di credenziali di backup di Microsoft Azure comunica con il cluster del servizio Azure Kubernetes tramite l'estensione per eseguire operazioni di backup e ripristino.
Per altre informazioni, vedere gli articoli seguenti:

Azure Kubernetes Service