L'elaborazione del linguaggio naturale (NLP, Natural Language Processing) viene usata per attività quali l'analisi del sentiment, il rilevamento di argomenti, il rilevamento della lingua, l'estrazione di frasi chiave e la categorizzazione di documenti.
In particolare, è possibile utilizzare NPL per:
- Classificare i documenti. Ad esempio, è possibile etichettare i documenti come sensibili o spam.
- Eseguire successive operazioni di elaborazione o ricerche. È possibile usare l'output NLP per questi scopi.
- Un altro possibile uso è quello di fornire una sintesi di un documento identificando le entità presenti nel testo.
- Contrassegna i documenti con parole chiave. Per le parole chiave, NLP può usare entità identificate.
- Eseguire la ricerca e il recupero basati sul contenuto. L'assegnazione di tag rende possibile questa funzionalità.
- Riepilogare gli argomenti importanti di un documento. L'NLP può combinare entità identificate in argomenti.
- Classificare i documenti per lo spostamento. A questo scopo, la prevenzione della perdita dei dati usa gli argomenti rilevati.
- Enumerare i documenti correlati in base a un argomento selezionato. A questo scopo, la prevenzione della perdita dei dati usa gli argomenti rilevati.
- Assegnare un punteggio al sentiment. Usando questa funzionalità, è possibile valutare il tono positivo o negativo di un documento.
Apache®, Apache Spark e il logo con la fiamma sono marchi o marchi registrati di Apache Software Foundation negli Stati Uniti e/o in altri Paesi. L'uso di questi marchi non implica alcuna approvazione da parte di Apache Software Foundation.
Potenziali casi d'uso
Gli scenari aziendali che possono trarre vantaggio dalla prevenzione della perdita di rete personalizzata includono:
- Intelligence sui documenti per documenti scritti a mano o creati da computer in finanza, sanità, vendita al dettaglio, governo e altri settori.
- Attività NLP indipendenti dal settore per l'elaborazione del testo, ad esempio il riconoscimento delle entità dei nomi (NER), la classificazione, il riepilogo e l'estrazione delle relazioni. Queste attività automatizzano il processo di recupero, identificazione e analisi delle informazioni sui documenti, ad esempio testo e dati non strutturati. Esempi di queste attività includono modelli di stratificazione dei rischi, classificazione dell'ontologia e riepiloghi delle vendite al dettaglio.
- Recupero delle informazioni e creazione del grafico delle informazioni per la ricerca semantica. Questa funzionalità consente di creare grafici di conoscenze mediche che supportano la scoperta di farmaci e studi clinici.
- Traduzione testuale per sistemi di intelligenza artificiale conversazionale nelle applicazioni rivolte ai clienti in settori retail, finance, travel e altri settori.
Apache Spark come framework NLP personalizzato
Apache Spark è un framework di elaborazione parallela che supporta l'elaborazione in memoria per migliorare le prestazioni di applicazioni analitiche di Big Data. Azure Synapse Analytics, Azure HDInsight e Azure Databricks offrono l'accesso a Spark e sfruttano la potenza di elaborazione.
Per i carichi di lavoro NLP personalizzati, Spark NLP funge da framework efficiente per l'elaborazione di una grande quantità di testo. Questa libreria NLP open source offre librerie Python, Java e Scala che offrono la funzionalità completa delle librerie NLP tradizionali, ad esempio spaCy, NLTK, Stanford CoreNLP e Open NLP. Spark NLP offre anche funzionalità come il controllo ortografico, l'analisi del sentiment e la classificazione dei documenti. Spark NLP migliora le attività precedenti fornendo precisione, velocità e scalabilità all'avanguardia.
I benchmark pubblici recenti mostrano Spark NLP come 38 e 80 volte più veloci rispetto a spaCy, con un'accuratezza paragonabile per il training di modelli personalizzati. Spark NLP è l'unica libreria open source che può usare un cluster Spark distribuito. Spark NLP è un'estensione nativa di Spark ML che opera direttamente nei frame di dati. Di conseguenza, le velocità in un cluster comportano un altro ordine di miglioramento delle prestazioni. Poiché ogni pipeline NLP spark è una pipeline di Spark ML, L'NLP di Spark è particolarmente adatta per la creazione di pipeline di NLP e Machine Learning unificate, ad esempio la classificazione dei documenti, la stima dei rischi e le pipeline di raccomandazione.
Oltre a prestazioni eccellenti, Spark NLP offre anche un'accuratezza all'avanguardia per un numero crescente di attività NLP. Il team spark NLP legge regolarmente i documenti accademici più recenti e implementa modelli all'avanguardia. Negli ultimi due-tre anni, i modelli con prestazioni migliori hanno usato l'apprendimento avanzato. La libreria include modelli di Deep Learning predefiniti per il riconoscimento di entità denominate, la classificazione dei documenti, il rilevamento di sentimenti ed emozioni e il rilevamento delle frasi. La raccolta include anche decine di modelli linguistici con training preliminare che includono il supporto per word, blocchi, frasi e incorporamenti di documenti.
La libreria include build ottimizzate per CPU, GPU e chip Intel Xeon più recenti. È possibile ridimensionare i processi di training e inferenza per sfruttare i vantaggi dei cluster Spark. Questi processi possono essere eseguiti in produzione in tutte le piattaforme di analisi più diffuse.
Problematiche
- L'elaborazione di una raccolta di documenti di testo in formato libero richiede una quantità significativa di risorse di calcolo. Anche l'elaborazione richiede molto tempo. Questi processi spesso comportano la distribuzione di calcolo GPU.
- Senza un formato standardizzato per i documenti, può essere difficile ottenere risultati precisi e coerenti usando l'elaborazione di testo in formato libero per estrarre dati specifici da un documento. Se si considera ad esempio una rappresentazione testuale di una fattura, può essere difficile creare un processo che consenta di estrarre correttamente il numero e la data delle fatture di più fornitori.
Criteri di scelta principali
In Azure, i servizi Spark come Azure Databricks, Azure Synapse Analytics e Azure HDInsight offrono funzionalità NLP quando vengono usate con Spark NLP. I servizi di intelligenza artificiale di Azure sono un'altra opzione per la funzionalità NLP. Per decidere quale servizio utilizzare, considerare le seguenti domande:
Si desidera usare modelli predefiniti? In caso affermativo, prendere in considerazione l'uso delle API offerte dai servizi di intelligenza artificiale di Azure. Oppure scaricare il modello preferito tramite Spark NLP.
È necessario eseguire il training di modelli personalizzati con una raccolta di grandi dimensioni di dati di testo? In caso affermativo, prendere in considerazione l'uso di Azure Databricks, Azure Synapse Analytics o Azure HDInsight con Spark NLP.
Sono necessarie funzionalità di elaborazione del linguaggio naturale di base, quali tokenizzazione, stemming, lemmatizzazione e frequenza del termine/frequenza inversa del documento (TF/IDF)? In caso affermativo, prendere in considerazione l'uso di Azure Databricks, Azure Synapse Analytics o Azure HDInsight con Spark NLP. In alternativa, usare una libreria software open source nello strumento di elaborazione preferito.
Sono necessarie funzionalità di elaborazione del linguaggio naturale avanzate, quali identificazione di entità e finalità, rilevamento dell'argomento, controllo ortografico o analisi del sentiment? In caso affermativo, prendere in considerazione l'uso delle API offerte dai servizi di intelligenza artificiale di Azure. Oppure scaricare il modello preferito tramite Spark NLP.
Matrice delle funzionalità
Le tabelle seguenti riassumono le principali differenze nelle capacità dei servizi di PNL.
Funzionalità generali
| Funzionalità | Servizio Spark (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) con Spark NLP | Servizi di Azure AI |
|---|---|---|
| Fornisce modelli sottoposti a training come servizio | Sì | Sì |
| REST API | Sì | Sì |
| Programmabilità | Python Scala | Per sapere quali lingue sono supportate, vedere Ulteriori risorse. |
| Supporta l'elaborazione di set di Big Data e documenti di grandi dimensioni | Sì | No |
Funzionalità NLP di basso livello
| Funzionalità di annotatori | Servizio Spark (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) con Spark NLP | Servizi di Azure AI |
|---|---|---|
| Rilevamento frasi | Sì | No |
| Rilevamento frasi profonde | Sì | Sì |
| Tokenizer | Sì | Sì |
| Generatore N-gram | Sì | No |
| Segmentazione delle parole | Sì | Sì |
| Stemmer | Sì | No |
| Lemmatizer | Sì | No |
| Tag delle parti del discorso | Sì | No |
| Parser delle dipendenze | Sì | No |
| Traduzione | Sì | No |
| Pulitura parola non significative | Sì | No |
| Correzione dell'ortografia | Sì | No |
| Normalizer | Sì | Sì |
| Matcher di testo | Sì | No |
| TF/IDF | Sì | No |
| Corrisponde all'espressione regolare | Sì | Incorporato nel servizio Language Understanding (LUIS). Non supportato in Conversational Language Understanding (CLU), che sostituisce LUIS. |
| Matcher data | Sì | Possibile in LUIS e CLU tramite riconoscitori DateTime |
| Chunker | Sì | No |
Funzionalità NLP di alto livello
| Funzionalità | Servizio Spark (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) con Spark NLP | Servizi di Azure AI |
|---|---|---|
| Controllo ortografia | Sì | No |
| Riepilogo | Sì | Sì |
| Risposta alle domande | Sì | Sì |
| Rilevamento del sentiment | Sì | Sì |
| Rilevamento delle emozioni | Sì | Supporta il opinion mining |
| Classificazione dei token | Sì | Sì, tramite modelli personalizzati |
| Classificazione testo | Sì | Sì, tramite modelli personalizzati |
| Rappresentazione di testo | Sì | No |
| NERE | Sì | Sì: l'analisi del testo fornisce un set di modelli NER e i modelli personalizzati sono nel riconoscimento delle entità |
| Riconoscimento delle entità | Sì | Sì, tramite modelli personalizzati |
| Rilevamento lingua | Sì | Sì |
| Supporto altre lingue oltre all'inglese | Sì, supporta più di 200 lingue | Sì, supporta più di 97 lingue |
Configurare Spark NLP in Azure
Per installare Spark NLP, usare il codice seguente, ma sostituire <version> con il numero di versione più recente. Per altre informazioni, vedere la documentazione Spark NPL.
# Install Spark NLP from PyPI.
pip install spark-nlp==<version>
# Install Spark NLP from Anacodna or Conda.
conda install -c johnsnowlabs spark-nlp
# Load Spark NLP with Spark Shell.
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with PySpark.
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with Spark Submit.
spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP as an external JAR after compiling and building Spark NLP by using sbt assembly.
spark-shell --jars spark-nlp-assembly-3 <version>.jar
Sviluppa pipeline NLP
Per l'ordine di esecuzione di una pipeline NLP, Spark NLP segue lo stesso concetto di sviluppo dei modelli di Machine Learning Spark ML tradizionali. Tuttavia, Spark NLP applica tecniche NLP.
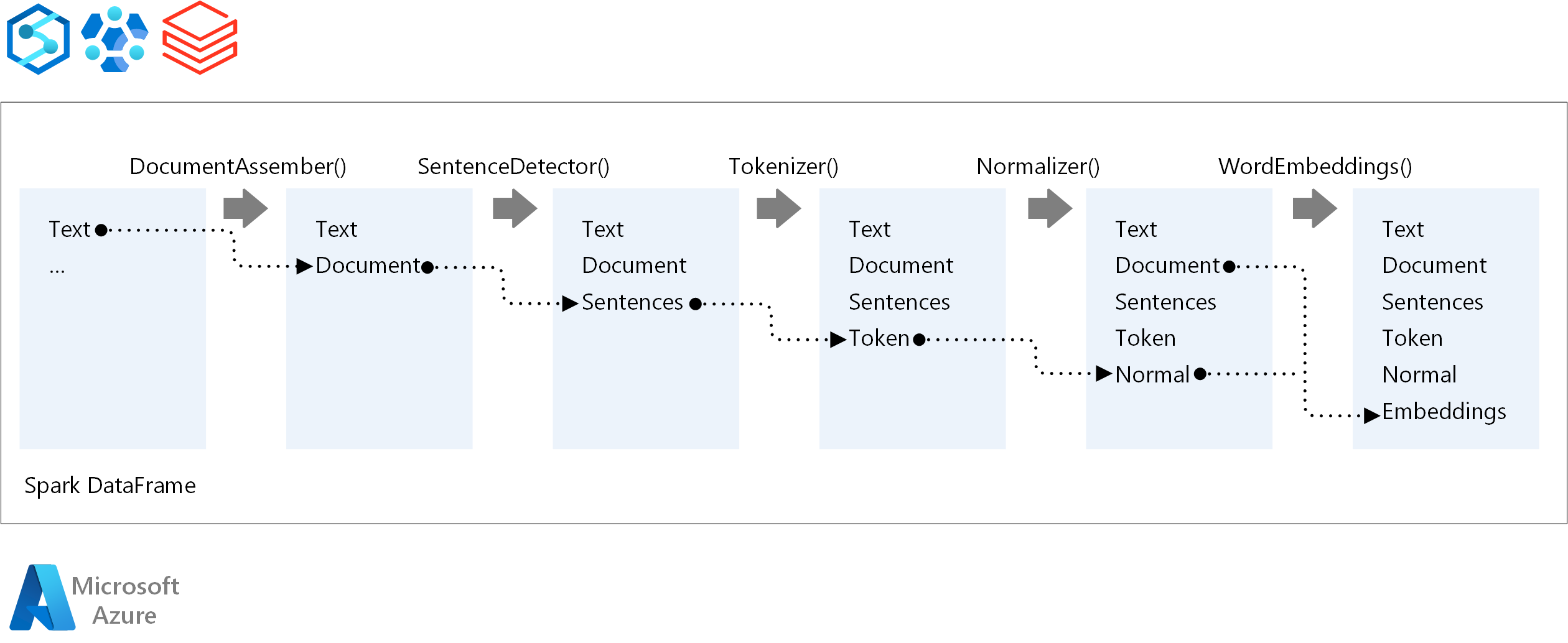
I componenti principali di una pipeline spark NLP sono:
DocumentAssembler: trasformatore che prepara i dati modificandoli in un formato che Spark NLP può elaborare. Questa fase è il punto di ingresso per ogni pipeline spark NLP. DocumentAssembler può leggere una
Stringcolonna o un oggettoArray[String]. È possibile usaresetCleanupModeper pre-elaborare il testo. Per impostazione predefinita, questa modalità è disattivata.SentenceDetector: annotatore che rileva i limiti delle frasi usando l'approccio specificato. Questo annotatore può restituire ogni frase estratta in un oggetto
Array. Può anche restituire ogni frase in una riga diversa, se impostata suexplodeSentencestrue.Tokenizer: annotatore che separa il testo non elaborato in token o unità come parole, numeri e simboli e restituisce i token in una
TokenizedSentencestruttura. Questa classe non è adattata. Se si adatta un tokenizer, l'internoRuleFactoryusa la configurazione di input per configurare le regole di tokenizzazione. Tokenizer usa standard aperti per identificare i token. Se le impostazioni predefinite non soddisfano le proprie esigenze, è possibile aggiungere regole per personalizzare Tokenizer.Normalizer: annotatore che pulisce i token. Normalizer richiede gli steli. Normalizer usa espressioni regolari e un dizionario per trasformare il testo e rimuovere caratteri dirty.
WordEmbeddings: cercare annotatori che eseguono il mapping dei token ai vettori. È possibile usare
setStoragePathper specificare un dizionario di ricerca token personalizzato per gli incorporamenti. Ogni riga del dizionario deve contenere un token e la relativa rappresentazione vettoriale, separati da spazi. Se un token non viene trovato nel dizionario, il risultato è un vettore zero della stessa dimensione.
Spark NLP usa pipeline MLlib Spark, supportate in modo nativo da MLflow. MLflow è una piattaforma open source per il ciclo di vita dell'apprendimento automatico. I suoi componenti includono:
- MLflow Tracking: registra gli esperimenti e offre un modo per eseguire query sui risultati.
- Progetti MLflow: consente di eseguire codice di data science in qualsiasi piattaforma.
- Modelli MLflow: distribuisce modelli in ambienti diversi.
- Registro modelli: gestisce i modelli archiviati in un repository centrale.
MLflow è integrato in Azure Databricks. È possibile installare MLflow in qualsiasi altro ambiente basato su Spark per tenere traccia e gestire gli esperimenti. È anche possibile usare il Registro modelli MLflow per rendere disponibili i modelli a scopo di produzione.
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autori principali:
- Merge Steller | Senior Cloud Solution Architect
- Zoiner Tejada | CEO e architetto
Passaggi successivi
Documentazione di Spark NPL:
Componenti di Azure:
Informazioni sulle risorse:
Risorse correlate
- Elaborazione del linguaggio naturale personalizzato su larga scala in Azure
- Scegliere una tecnologia per i servizi di Microsoft Azure AI
- Confrontare i prodotti e le tecnologie di apprendimento automatico di Microsoft
- MLflow e Azure Machine Learning
- Arricchimento tramite intelligenza artificiale con elaborazione di immagini e linguaggio naturale in Ricerca cognitiva di Azure
- Analizzare i newsfeed con analisi near real-time usando l'elaborazione di immagini e linguaggio naturale