Risolvere i colli di bottiglia delle prestazioni in Azure Databricks
Nota
Questo articolo si basa su una libreria open source ospitata in GitHub all'indirizzo: https://github.com/mspnp/spark-monitoring.
La libreria originale supporta Azure Databricks Runtimes 10.x (Spark 3.2.x) e versioni precedenti.
Databricks ha apportato una versione aggiornata per supportare Azure Databricks Runtimes 11.0 (Spark 3.3.x) e versioni successive nel ramo l4jv2 all'indirizzo: https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Si noti che la versione 11.0 non è compatibile con le versioni precedenti a causa dei diversi sistemi di registrazione usati in Databricks Runtimes. Assicurarsi di usare la compilazione corretta per Databricks Runtime. La libreria e il repository GitHub sono in modalità manutenzione. Non sono previsti piani per altre versioni e il supporto per i problemi sarà solo un'operazione ottimale. Per eventuali ulteriori domande relative alla libreria o alla roadmap per il monitoraggio e la registrazione degli ambienti Azure Databricks, contattare azure-spark-monitoring-help@databricks.com.
Questo articolo descrive come usare i dashboard di monitoraggio per trovare colli di bottiglia delle prestazioni nei processi Spark in Azure Databricks.
Azure Databricks è un servizio di analisi basato su Apache Spark che semplifica lo sviluppo e la distribuzione rapidi dell'analisi dei Big Data. Il monitoraggio e la risoluzione dei problemi delle prestazioni sono aspetti fondamentali quando si utilizzano i carichi di lavoro di Azure Databricks. Per identificare i problemi di prestazioni comuni, è utile usare le visualizzazioni di monitoraggio in base ai dati di telemetria.
Prerequisiti
Per configurare i dashboard di Grafana illustrati in questo articolo:
Configurare il cluster Databricks per inviare dati di telemetria a un'area di lavoro Log Analytics usando la libreria di monitoraggio di Azure Databricks. Per informazioni dettagliate, vedere il file Leggimi di GitHub.
Distribuire Grafana in una macchina virtuale. Per maggiori informazioni, consultare la sezione Usare le dashboard per visualizzare le metriche di Azure Databricks.
Il dashboard di Grafana distribuito include un set di visualizzazioni di serie temporali. Ogni grafico è un tracciato di serie temporali di metriche correlate a un processo di Apache Spark, alle fasi del processo e alle attività che costituiscono ogni fase.
Panoramica delle prestazioni di Azure Databricks
Azure Databricks è basato su Apache Spark, un sistema di calcolo distribuito per utilizzo generico. Il codice dell'applicazione, noto come processo, viene eseguito in un cluster Apache Spark, coordinato dal gestore del cluster. In generale, un processo è l'unità di calcolo di livello più elevato. Un processo rappresenta l'operazione completa eseguita dall'applicazione Spark. Un'operazione tipica include la lettura dei dati da un'origine, l'applicazione di trasformazioni dei dati e la scrittura dei risultati nell'archiviazione o in un'altra destinazione.
I processi vengono suddivisi in fasi. Il processo avanza nelle fasi in sequenza, ovvero le fasi successive devono attendere il completamento delle fasi precedenti. Le fasi contengono gruppi di attività identiche che possono essere eseguite in parallelo in più nodi del cluster Spark. Le attività sono l'unità di esecuzione più granulare che si svolge in un subset di dati.
Le sezioni successive descrivono alcune visualizzazioni del dashboard utili per la risoluzione dei problemi di prestazioni.
Latenza del processo e della fase
La latenza del processo è la durata dell'esecuzione di un processo dall'avvio fino al completamento. Viene visualizzata come percentile di un'esecuzione del processo per cluster e ID applicazione, per consentire la visualizzazione degli outlier. Il grafico seguente mostra una cronologia del processo in cui il 90° percentile ha raggiunto 50 secondi, anche se il 50° percentile è stato costantemente intorno ai 10 secondi.
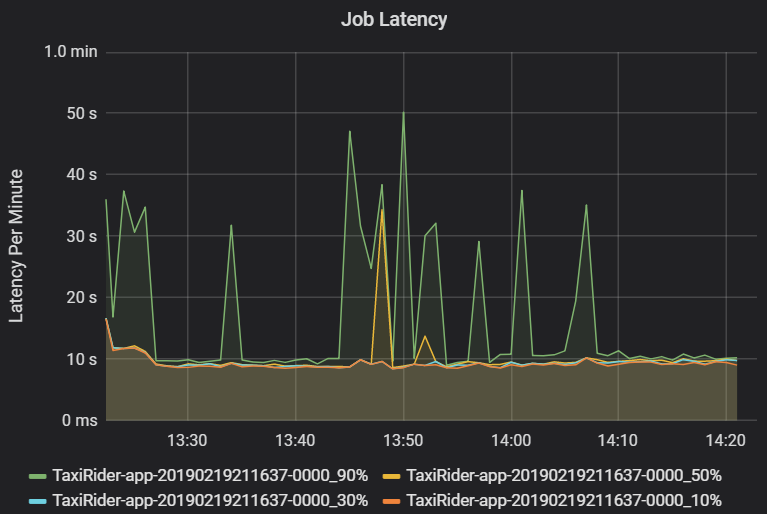
Analizzare l'esecuzione del processo in base al cluster e all'applicazione, cercando picchi di latenza. Dopo aver identificato cluster e applicazioni con latenza elevata, passare a esaminare la latenza della fase.
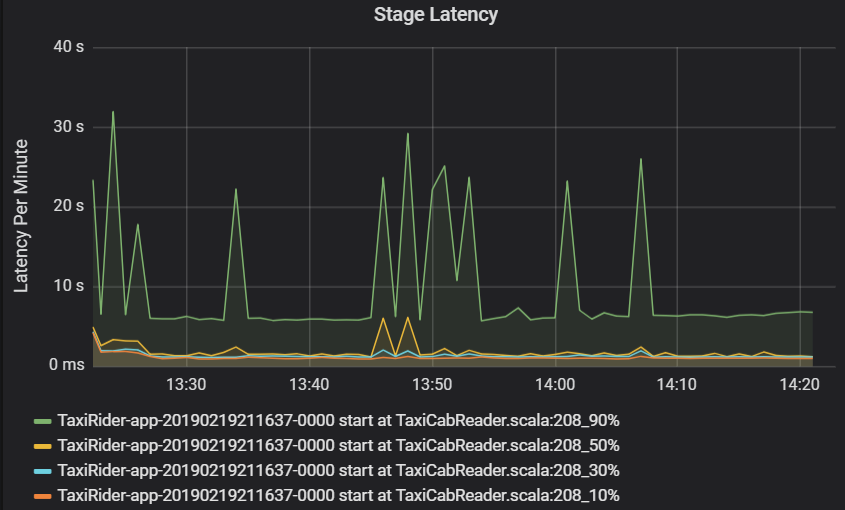
La latenza della fase viene visualizzata anche come percentile per consentire la visualizzazione degli outlier. La latenza della fase viene suddivisa in base al cluster, all'applicazione e al nome della fase. Identificare i picchi di latenza delle attività nel grafico per determinare quali attività impediscono il completamento della fase.
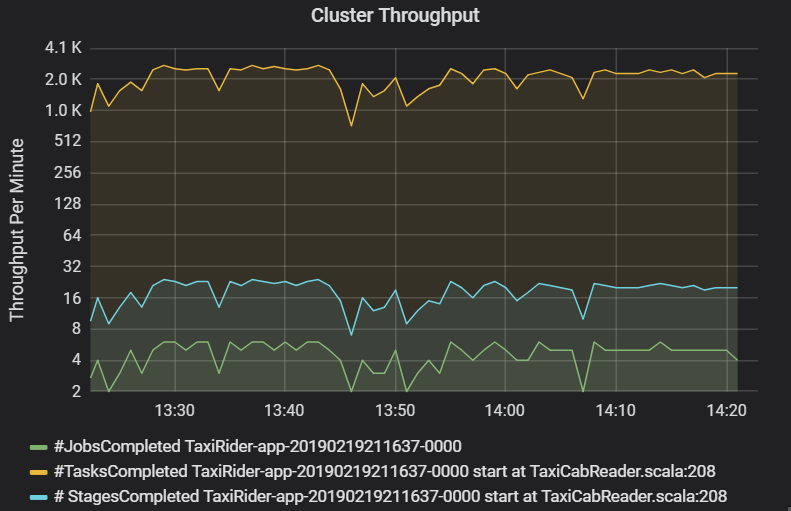
Il grafico della velocità effettiva del cluster mostra il numero di processi, fasi e attività completati al minuto. In questo modo, è possibile comprendere il carico di lavoro in base al relativo numero di fasi e attività per processo. Qui è possibile vedere che il numero di processi al minuto è compreso tra 2 e 6, mentre il numero di fasi è di circa 12-24 al minuto.
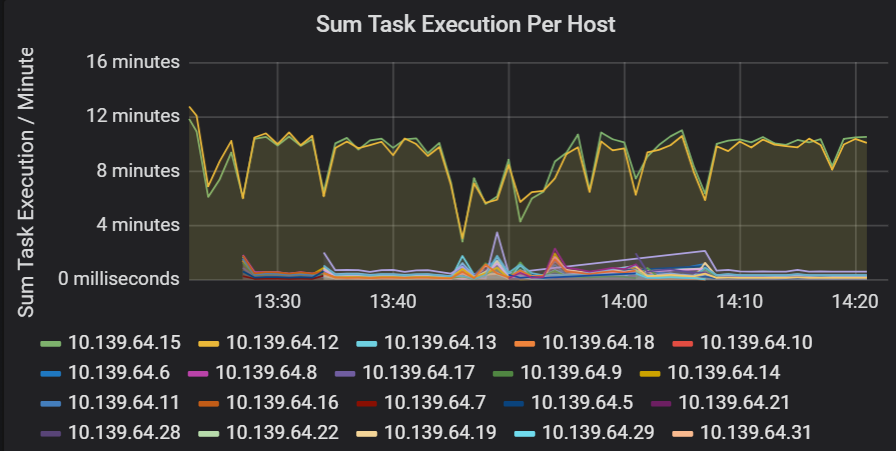
Somma della latenza di esecuzione dell'attività
Questa visualizzazione mostra la somma della latenza di esecuzione delle attività per ogni host in esecuzione in un cluster. Usare questo grafico per rilevare le attività che vengono eseguite lentamente a causa del rallentamento dell'host in un cluster o di un'errata allocazione delle attività per executor. Nel grafico seguente la maggior parte degli host ha una somma di circa 30 secondi. Tuttavia, due degli host hanno somme che si aggirano intorno ai 10 minuti. L'esecuzione degli host è lenta o il numero di attività per executor non è allocato.
Il numero di attività per executor indica che a due executor viene assegnato un numero sproporzionato di attività, causando un collo di bottiglia.
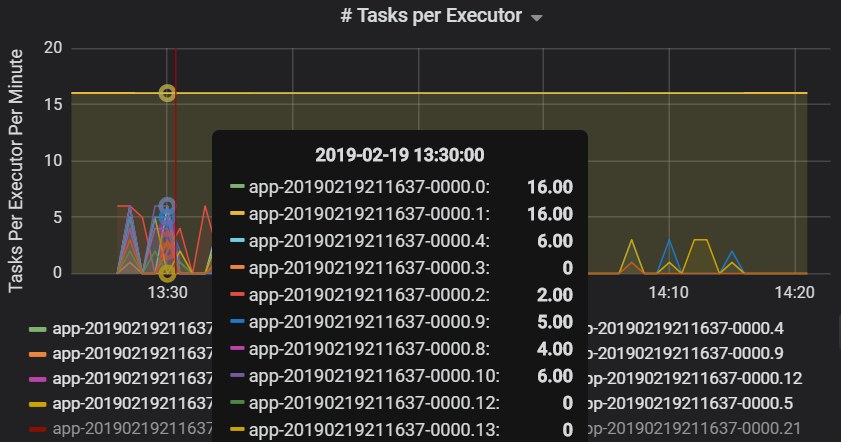
Metriche delle attività per fase
La visualizzazione delle metriche delle attività fornisce la suddivisione dei costi per l'esecuzione di un'attività. È possibile usarla per visualizzare il tempo relativo dedicato ad attività quali la serializzazione e la deserializzazione. Questi dati possono mostrare opportunità di ottimizzazione, ad esempio usando variabili di trasmissione per evitare la spedizione dei dati. Le metriche delle attività mostrano anche le dimensioni dei dati casuali per un'attività e i tempi di lettura e scrittura casuali. Se questi valori sono elevati, significa che molti dati si stanno spostando attraverso la rete.
Un'altra metrica delle attività è il ritardo dell'utilità di pianificazione, che misura il tempo necessario per pianificare un'attività. Idealmente, questo valore deve essere basso rispetto al tempo di calcolo dell'executor, ovvero il tempo impiegato per l'esecuzione dell'attività.
Il grafico seguente mostra un tempo di ritardo dell'utilità di pianificazione (3,7 s) che supera il tempo di calcolo dell'executor (1,1 s). Ciò significa che viene impiegato più tempo in attesa della pianificazione delle attività rispetto all'esecuzione del lavoro effettivo.
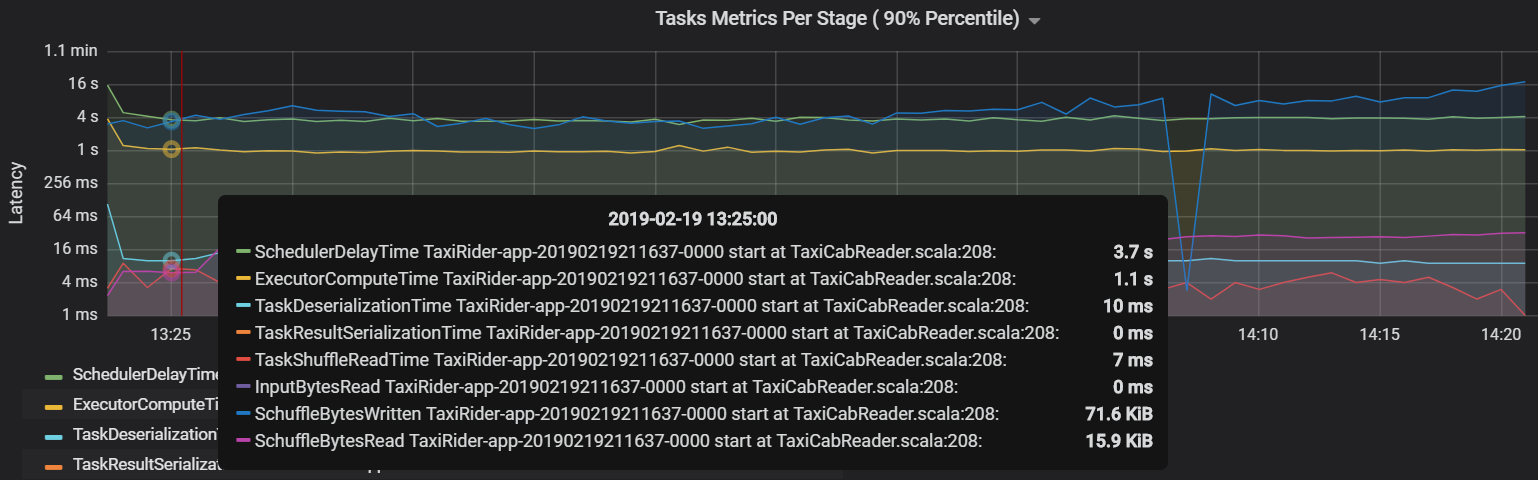
In questo caso, il problema è stato causato dalla presenza di un numero eccessivo di partizioni, che ha comportato un sovraccarico elevato. La riduzione del numero di partizioni ha abbassato il ritardo dell'utilità di pianificazione. Il grafico successivo mostra che la maggior parte del tempo viene dedicato all'esecuzione dell'attività.
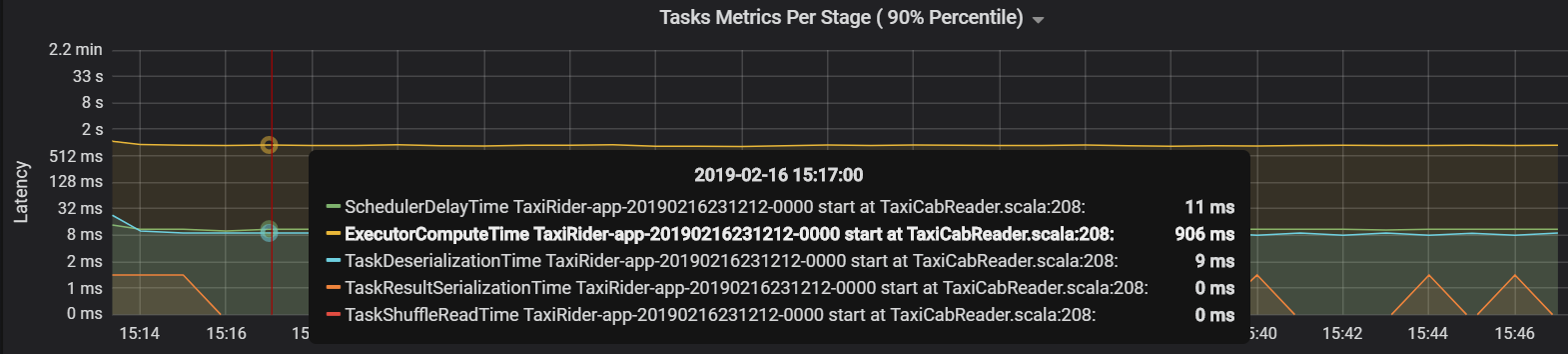
Latenza e velocità effettiva del flusso
La velocità effettiva del flusso è direttamente correlata al flusso strutturato. Alla velocità effettiva del flusso sono associate due metriche importanti: righe di input al secondo e righe elaborate al secondo. Se le righe di input al secondo superano le righe elaborate al secondo, significa che il sistema di elaborazione del flusso è in ritardo. Inoltre, se i dati di input provengono da Hub eventi o Kafka, le righe di input al secondo devono rimanere al passo con la velocità di inserimento dei dati nel front-end.
Due processi possono avere una velocità effettiva del cluster simile, ma metriche di flusso molto diverse. Lo screenshot seguente mostra due carichi di lavoro diversi. Sono simili in termini di velocità effettiva del cluster (processi, fasi e attività al minuto). Ma la seconda esecuzione elabora 12.000 righe/sec rispetto a 4000 righe/sec.
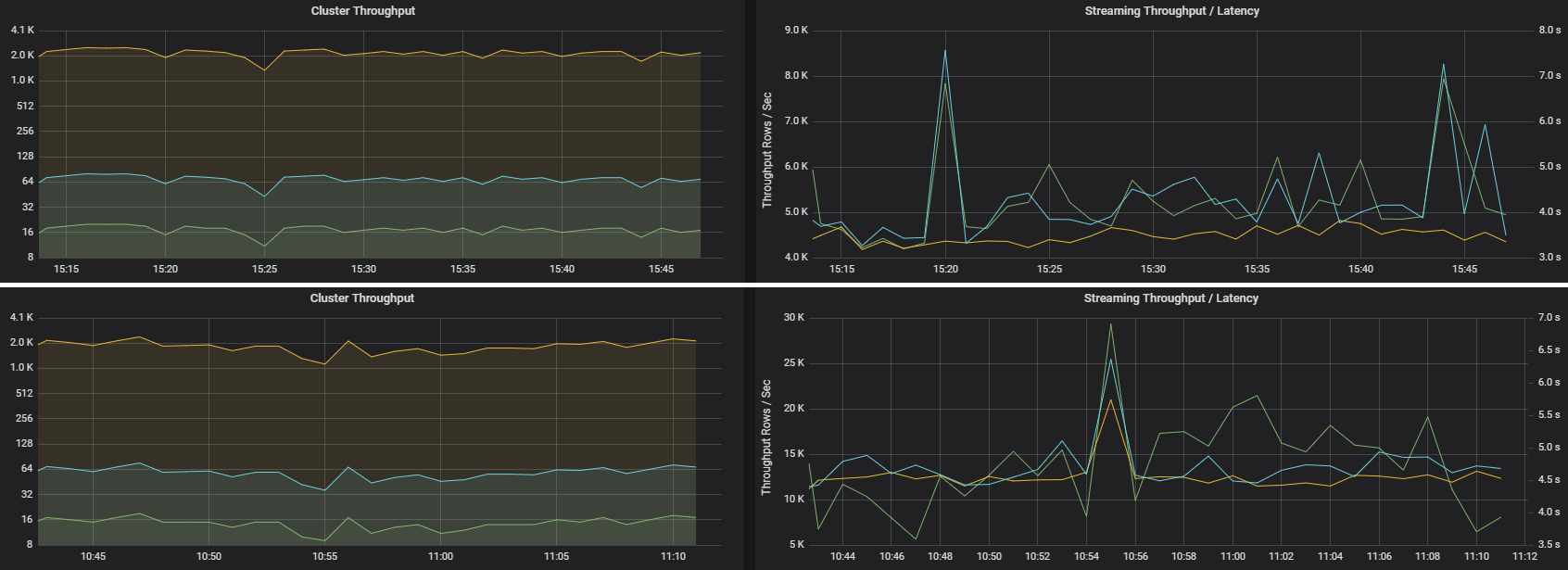
La velocità effettiva del flusso è spesso una metrica aziendale migliore rispetto alla velocità effettiva del cluster, perché misura il numero di record di dati elaborati.
Utilizzo delle risorse per executor
Queste metriche consentono di comprendere il lavoro eseguito da ogni executor.
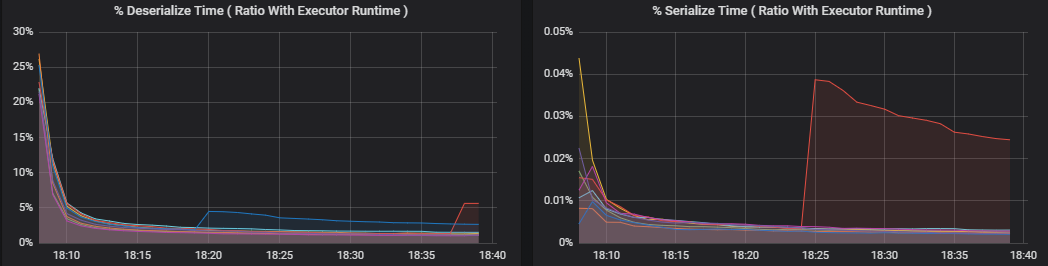
Le metriche percentuali misurano il tempo impiegato da un executor per l'esecuzione di varie operazioni, espresso come rapporto tra il tempo impiegato e il tempo di calcolo complessivo dell'executor. Le metriche sono le seguenti:
- % tempo per la serializzazione
- % tempo per la deserializzazione
- % tempo dell'executor della CPU
- % tempo JVM
Queste visualizzazioni mostrano quanto ognuna di queste metriche contribuisce all'elaborazione complessiva dell'executor.
Le metriche casuali sono metriche correlate alla riproduzione casuale dei dati tra gli executor.
- I/O casuale
- Memoria casuale
- Utilizzo del file system
- Utilizzo del disco
Colli di bottiglia delle prestazioni comuni
Due colli di bottiglia delle prestazioni comuni in Spark sono i ritardi delle attività e un numero di partizioni casuali non ottimale.
Ritardi delle attività
Le fasi di un processo vengono eseguite in sequenza, con le fasi precedenti che bloccano le fasi successive. Se un'attività esegue una partizione casuale più lentamente rispetto ad altre attività, tutte le attività nel cluster devono attendere il completamento dell'attività lenta prima che la fase possa terminare. Questo può verificarsi per i motivi seguenti:
L'esecuzione di un host o di un gruppo di host è lenta. Sintomi: latenza elevata di attività, fasi o processi e velocità effettiva del cluster ridotta. La somma delle latenze delle attività per ogni host non verrà distribuita in modo uniforme. Tuttavia, l'utilizzo delle risorse verrà distribuito in modo uniforme tra gli executor.
L'esecuzione dell'aggregazione è onerosa per le attività (asimmetria dei dati). Sintomi: latenza elevata di attività, fasi e processi o velocità effettiva del cluster ridotta, ma la somma delle latenze per host viene distribuita in modo uniforme. L'utilizzo delle risorse verrà distribuito in modo uniforme tra gli executor.
Se le partizioni hanno dimensioni disuguali, una partizione più grande può causare un'esecuzione di attività non bilanciata (asimmetria delle partizioni). Sintomi: l'utilizzo delle risorse dell'executor è elevato rispetto ad altri executor in esecuzione nel cluster. Tutte le attività in esecuzione nell'executor verranno eseguite lentamente e rallenteranno l'esecuzione della fase nella pipeline. Queste fasi vengono definite barriere di fase.
Numero di partizioni casuali non ottimale
Durante una query di flusso strutturato, l'assegnazione di un'attività a un executor è un'operazione a elevato utilizzo di risorse per il cluster. Se le dimensioni dei dati casuali non sono ottimali, la quantità di ritardo per un'attività inciderà negativamente sulla velocità effettiva e sulla latenza. Se è presente un numero troppo basso di partizioni, i core nel cluster saranno sottoutilizzati e ciò può causare inefficienze nell'elaborazione. Al contrario, se sono presenti troppe partizioni, si verifica un sovraccarico di gestione elevato per un numero ridotto di attività.
Usare le metriche sull'utilizzo delle risorse per risolvere i problemi di asimmetria delle partizioni e allocazione errata degli executor nel cluster. Se una partizione è asimmetrica, le risorse dell'executor saranno elevate rispetto ad altri executor in esecuzione nel cluster.
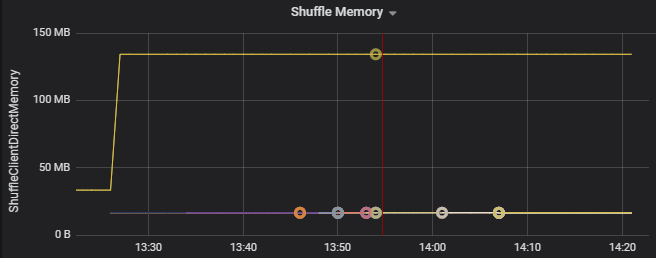
Ad esempio, il grafico seguente mostra che la memoria usata dalla riproduzione casuale nei primi due executor è 90 volte maggiore rispetto agli altri executor:
Passaggi successivi
- Monitoraggio di Azure Databricks in un'area di lavoro Analisi dei log di Azure
- Percorso di apprendimento: creare e gestire soluzioni di machine learning con Azure Databricks
- Documentazione di Azure Databricks
- Panoramica di Monitoraggio di Azure
Risorse correlate
- Monitoraggio di Azure Databricks
- Inviare i log dell'applicazione di Azure Databricks a Monitoraggio di Azure
- Usare i dashboard per visualizzare le metriche di Azure Databricks
- Architettura di analisi moderna con Azure Databricks
- Pipeline di inserimento, ETL (estrazione, trasformazione, caricamento) e di elaborazione flusso con Azure Databricks