Esaminare l'integrità dei nodi e dei pod
Questo articolo fa parte di una serie. Iniziare con la panoramica.
Se il cluster verifica che è stato eseguito nel passaggio precedente è chiaro, controllare l'integrità dei nodi di lavoro servizio Azure Kubernetes (servizio Azure Kubernetes). Seguire i sei passaggi descritti in questo articolo per controllare l'integrità dei nodi, determinare il motivo di un nodo non integro e risolvere il problema.
Passaggio 1: Controllare l'integrità dei nodi di lavoro
Vari fattori possono contribuire a nodi non integri in un cluster del servizio Azure Kubernetes. Un motivo comune è la suddivisione della comunicazione tra il piano di controllo e i nodi. Questa comunicazione errata è spesso causata da errori di configurazione nelle regole di routing e firewall.
Quando si configura il cluster del servizio Azure Kubernetes per il routing definito dall'utente, è necessario configurare i percorsi in uscita tramite un'appliance virtuale di rete o un firewall, ad esempio un firewall di Azure. Per risolvere un problema di configurazione errata, è consigliabile configurare il firewall per consentire le porte necessarie e i nomi di dominio completi (FQDN) in base alle indicazioni sul traffico in uscita del servizio Azure Kubernetes.
Un altro motivo per cui i nodi non integri potrebbero essere risorse di calcolo, memoria o archiviazione inadeguate che creano pressioni kubelet. In questi casi, l'aumento delle risorse può risolvere il problema in modo efficace.
In un cluster del servizio Azure Kubernetes privato, i problemi di risoluzione DNS (Domain Name System) possono causare problemi di comunicazione tra il piano di controllo e i nodi. È necessario verificare che il nome DNS del server API Kubernetes venga risolto nell'indirizzo IP privato del server API. La configurazione errata di un server DNS personalizzato è una causa comune di errori di risoluzione DNS. Se si usano server DNS personalizzati, assicurarsi di specificarli correttamente come server DNS nella rete virtuale in cui viene effettuato il provisioning dei nodi. Verificare anche che il server API privato del servizio Azure Kubernetes possa essere risolto tramite il server DNS personalizzato.
Dopo aver risolto questi potenziali problemi relativi alla comunicazione del piano di controllo e alla risoluzione DNS, è possibile risolvere in modo efficace i problemi di integrità dei nodi all'interno del cluster del servizio Azure Kubernetes.
È possibile valutare l'integrità dei nodi usando uno dei metodi seguenti.
Visualizzazione dell'integrità dei contenitori di Monitoraggio di Azure
Per visualizzare l'integrità dei nodi, dei pod utente e dei pod di sistema nel cluster del servizio Azure Kubernetes, seguire questa procedura:
- Nel portale di Azure passare a Monitoraggio di Azure.
- Nella sezione Insights del riquadro di spostamento selezionare Contenitori.
- Selezionare Cluster monitorati per un elenco dei cluster del servizio Azure Kubernetes monitorati.
- Scegliere un cluster del servizio Azure Kubernetes dall'elenco per visualizzare l'integrità dei nodi, dei pod utente e dei pod di sistema.

Visualizzazione dei nodi del servizio Azure Kubernetes
Per assicurarsi che tutti i nodi del cluster del servizio Azure Kubernetes siano nello stato pronto, seguire questa procedura:
- Nella portale di Azure passare al cluster del servizio Azure Kubernetes.
- Nella sezione Impostazioni del riquadro di spostamento selezionare Pool di nodi.
- Selezionare Nodi.
- Verificare che tutti i nodi siano nello stato pronto.

Monitoraggio in cluster con Prometheus e Grafana
Se prometheus e Grafana sono stati distribuiti nel cluster del servizio Azure Kubernetes, è possibile usare il dashboard dettagli cluster K8 per ottenere informazioni dettagliate. Questo dashboard mostra le metriche del cluster Prometheus e presenta informazioni essenziali, ad esempio utilizzo della CPU, utilizzo della memoria, attività di rete e utilizzo del file system. Vengono inoltre visualizzate statistiche dettagliate per singoli pod, contenitori e servizi di sistema.
Nel dashboard selezionare Condizioni del nodo per visualizzare le metriche relative all'integrità e alle prestazioni del cluster. È possibile tenere traccia dei nodi che potrebbero avere problemi, ad esempio problemi con la pianificazione, la rete, la pressione del disco, la pressione della memoria, la pressione proporzionale derivata integrale (PID) o lo spazio su disco. Monitorare queste metriche, in modo da poter identificare e risolvere in modo proattivo eventuali problemi che influiscono sulla disponibilità e sulle prestazioni del cluster del servizio Azure Kubernetes.

Monitorare il servizio gestito per Prometheus e Grafana gestito di Azure
È possibile usare dashboard predefiniti per visualizzare e analizzare le metriche di Prometheus. A tale scopo, è necessario configurare il cluster del servizio Azure Kubernetes per raccogliere le metriche di Prometheus nel servizio gestito di Monitoraggio per Prometheus e connettere l'area di lavoro Monitoraggio a un'area di lavoro Grafana gestita di Azure. Questi dashboard offrono una visualizzazione completa delle prestazioni e dell'integrità del cluster Kubernetes.
Il provisioning dei dashboard viene eseguito nell'istanza di Grafana gestita di Azure specificata nella cartella Managed Prometheus . Alcuni dashboard includono:
- Kubernetes/Risorse di calcolo/Cluster
- Kubernetes/Risorse di calcolo/Spazio dei nomi (pod)
- Kubernetes/Risorse di calcolo/Nodo (pod)
- Kubernetes/Risorse di calcolo/Pod
- Kubernetes/Risorse di calcolo/Spazio dei nomi (carichi di lavoro)
- Kubernetes/Risorse di calcolo/Carico di lavoro
- Kubernetes/Kubelet
- Node Exporter/U edizione Standard Method/Node
- Utilità di esportazione/nodi del nodo
- Kubernetes/Risorse di calcolo/Cluster (Windows)
- Kubernetes/Risorse di calcolo/Spazio dei nomi (Windows)
- Kubernetes/Risorse di calcolo/Pod (Windows)
- Metodo Kubernetes/U edizione Standard/Cluster (Windows)
- Metodo Kubernetes/U edizione Standard/Node (Windows)
Questi dashboard predefiniti sono ampiamente usati nella community open source per il monitoraggio dei cluster Kubernetes con Prometheus e Grafana. Usare questi dashboard per visualizzare le metriche, ad esempio l'utilizzo delle risorse, l'integrità dei pod e l'attività di rete. È anche possibile creare dashboard personalizzati personalizzati in base alle esigenze di monitoraggio. I dashboard consentono di monitorare e analizzare in modo efficace le metriche di Prometheus nel cluster del servizio Azure Kubernetes, che consente di ottimizzare le prestazioni, risolvere i problemi e garantire un funzionamento uniforme dei carichi di lavoro Kubernetes.
È possibile usare il dashboard Kubernetes/Risorse di calcolo/Nodo (pod) per visualizzare le metriche per i nodi dell'agente Linux. È possibile visualizzare l'utilizzo della CPU, la quota di CPU, l'utilizzo della memoria e la quota di memoria per ogni pod.

Se il cluster include nodi agente Windows, è possibile usare il dashboard Kubernetes/U edizione Standard Method/Node (Windows) per visualizzare le metriche prometheus raccolte da questi nodi. Questo dashboard offre una visualizzazione completa dell'utilizzo delle risorse e delle prestazioni per i nodi Windows all'interno del cluster.
Sfruttare questi dashboard dedicati in modo da poter monitorare e analizzare facilmente metriche importanti correlate a CPU, memoria e altre risorse nei nodi dell'agente Linux e Windows. Questa visibilità consente di identificare potenziali colli di bottiglia, ottimizzare l'allocazione delle risorse e garantire un'operazione efficiente nel cluster del servizio Azure Kubernetes.
Passaggio 2: Verificare la connettività del piano di controllo e del nodo di lavoro
Se i nodi di lavoro sono integri, è necessario esaminare la connettività tra il piano di controllo del servizio Azure Kubernetes gestito e i nodi del ruolo di lavoro del cluster. Il servizio Azure Kubernetes consente la comunicazione tra il server API Kubernetes e i singoli kubelet a nodo tramite un metodo di comunicazione tunnel sicuro. Questi componenti possono comunicare anche se si trovano in reti virtuali diverse. Il tunnel è protetto con la crittografia mTLS (Mutual Transport Layer Security). Il tunnel primario usato dal servizio Azure Kubernetes è denominato Konnectivity(in precedenza noto come apiserver-network-proxy). Assicurarsi che tutte le regole di rete e i nomi di dominio completi siano conformi alle regole di rete di Azure necessarie.
Per verificare la connettività tra il piano di controllo del servizio Azure Kubernetes gestito e i nodi del ruolo di lavoro del cluster di un cluster del servizio Azure Kubernetes, è possibile usare lo strumento da riga di comando kubectl .
Per assicurarsi che i pod dell'agente Konnectivity funzionino correttamente, eseguire il comando seguente:
kubectl get deploy konnectivity-agent -n kube-system
Assicurarsi che i pod siano in uno stato pronto.
Se si verifica un problema di connettività tra il piano di controllo e i nodi di lavoro, stabilire la connettività dopo aver verificato che siano consentite le regole di traffico in uscita del servizio Azure Kubernetes necessarie.
Eseguire il comando seguente per riavviare i konnectivity-agent pod:
kubectl rollout restart deploy konnectivity-agent -n kube-system
Se il riavvio dei pod non corregge la connessione, verificare la presenza di eventuali anomalie nei log. Eseguire il comando seguente per visualizzare i log dei konnectivity-agent pod:
kubectl logs -l app=konnectivity-agent -n kube-system --tail=50
I log dovrebbero mostrare l'output seguente:
I1012 12:27:43.521795 1 options.go:102] AgentCert set to "/certs/client.crt".
I1012 12:27:43.521831 1 options.go:103] AgentKey set to "/certs/client.key".
I1012 12:27:43.521834 1 options.go:104] CACert set to "/certs/ca.crt".
I1012 12:27:43.521837 1 options.go:105] ProxyServerHost set to "sethaks-47983508.hcp.switzerlandnorth.azmk8s.io".
I1012 12:27:43.521841 1 options.go:106] ProxyServerPort set to 443.
I1012 12:27:43.521844 1 options.go:107] ALPNProtos set to [konnectivity].
I1012 12:27:43.521851 1 options.go:108] HealthServerHost set to
I1012 12:27:43.521948 1 options.go:109] HealthServerPort set to 8082.
I1012 12:27:43.521956 1 options.go:110] AdminServerPort set to 8094.
I1012 12:27:43.521959 1 options.go:111] EnableProfiling set to false.
I1012 12:27:43.521962 1 options.go:112] EnableContentionProfiling set to false.
I1012 12:27:43.521965 1 options.go:113] AgentID set to b7f3182c-995e-4364-aa0a-d569084244e4.
I1012 12:27:43.521967 1 options.go:114] SyncInterval set to 1s.
I1012 12:27:43.521972 1 options.go:115] ProbeInterval set to 1s.
I1012 12:27:43.521980 1 options.go:116] SyncIntervalCap set to 10s.
I1012 12:27:43.522020 1 options.go:117] Keepalive time set to 30s.
I1012 12:27:43.522042 1 options.go:118] ServiceAccountTokenPath set to "".
I1012 12:27:43.522059 1 options.go:119] AgentIdentifiers set to .
I1012 12:27:43.522083 1 options.go:120] WarnOnChannelLimit set to false.
I1012 12:27:43.522104 1 options.go:121] SyncForever set to false.
I1012 12:27:43.567902 1 client.go:255] "Connect to" server="e9df3653-9bd4-4b09-b1a7-261f6104f5d0"
Nota
Quando un cluster del servizio Azure Kubernetes viene configurato con un'integrazione della rete virtuale del server API e un'interfaccia di rete del contenitore di Azure o un'istanza CNI di Azure con assegnazione di indirizzi IP pod dinamici, non è necessario distribuire gli agenti Konnectivity. I pod del server API integrati possono stabilire comunicazioni dirette con i nodi del ruolo di lavoro del cluster tramite la rete privata.
Tuttavia, quando si usa l'integrazione della rete virtuale del server API con Azure CNI Overlay o bring your own CNI (BYOCNI), Konnectivity viene distribuito per facilitare la comunicazione tra i server API e gli INDIRIZZI IP pod. La comunicazione tra i server API e i nodi di lavoro rimane diretta.
È anche possibile cercare i log dei contenitori nel servizio di registrazione e monitoraggio per recuperare i log. Per un esempio che cerca errori di connettività del collegamento al servizio Azure Kubernetes, vedere Eseguire query sui log dai dati analitici del contenitore.
Eseguire la query seguente per recuperare i log:
ContainerLogV2
| where _ResourceId =~ "/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.ContainerService/managedClusters/<cluster-ID>" // Use the IDs and names of your resources for these values.
| where ContainerName has "aks-link"
| project LogSource,LogMessage, TimeGenerated, Computer, PodName, ContainerName, ContainerId
| order by TimeGenerated desc
| limit 200
Eseguire la query seguente per cercare i log dei contenitori per qualsiasi pod non riuscito in uno spazio dei nomi specifico:
let KubePodInv = KubePodInventory
| where TimeGenerated >= startTime and TimeGenerated < endTime
| where _ResourceId =~ "<cluster-resource-ID>" // Use your resource ID for this value.
| where Namespace == "<pod-namespace>" // Use your target namespace for this value.
| where PodStatus == "Failed"
| extend ContainerId = ContainerID
| summarize arg_max(TimeGenerated, *) by ContainerId, PodStatus, ContainerStatus
| project ContainerId, PodStatus, ContainerStatus;
KubePodInv
| join
(
ContainerLogV2
| where TimeGenerated >= startTime and TimeGenerated < endTime
| where PodNamespace == "<pod-namespace>" //update with target namespace
) on ContainerId
| project TimeGenerated, PodName, PodStatus, ContainerName, ContainerId, ContainerStatus, LogMessage, LogSource
Se non è possibile ottenere i log usando query o lo strumento kubectl, usare l'autenticazione Secure Shell (SSH). Questo esempio trova il pod tunnelfront dopo la connessione al nodo tramite SSH.
kubectl pods -n kube-system -o wide | grep tunnelfront
ssh azureuser@<agent node pod is on, output from step above>
docker ps | grep tunnelfront
docker logs …
nslookup <ssh-server_fqdn>
ssh -vv azureuser@<ssh-server_fqdn> -p 9000
docker exec -it <tunnelfront_container_id> /bin/bash -c "ping bing.com"
kubectl get pods -n kube-system -o wide | grep <agent_node_where_tunnelfront_is_running>
kubectl delete po <kube_proxy_pod> -n kube-system
Passaggio 3: Convalidare la risoluzione DNS quando si limita l'uscita
La risoluzione DNS è un aspetto fondamentale del cluster del servizio Azure Kubernetes. Se la risoluzione DNS non funziona correttamente, può causare errori del piano di controllo o errori di pull dell'immagine del contenitore. Per assicurarsi che la risoluzione DNS al server API Kubernetes funzioni correttamente, seguire questa procedura:
Eseguire il comando kubectl exec per aprire una shell dei comandi nel contenitore in esecuzione nel pod.
kubectl exec --stdin --tty your-pod --namespace <namespace-name> -- /bin/bashControllare se gli strumenti nslookup o dig sono installati nel contenitore.
Se nessuno degli strumenti è installato nel pod, eseguire il comando seguente per creare un pod di utilità nello stesso spazio dei nomi.
kubectl run -i --tty busybox --image=busybox --namespace <namespace-name> --rm=true -- shÈ possibile recuperare l'indirizzo del server API dalla pagina di panoramica del cluster del servizio Azure Kubernetes nel portale di Azure oppure eseguire il comando seguente.
az aks show --name <aks-name> --resource-group <resource-group-name> --query fqdn --output tsvEseguire il comando seguente per tentare di risolvere il server API del servizio Azure Kubernetes. Per altre informazioni, vedere Risolvere gli errori di risoluzione DNS dall'interno del pod, ma non dal nodo di lavoro.
nslookup myaks-47983508.hcp.westeurope.azmk8s.ioControllare il server DNS upstream dal pod per determinare se la risoluzione DNS funziona correttamente. Ad esempio, per DNS di Azure, eseguire il
nslookupcomando .nslookup microsoft.com 168.63.129.16Se i passaggi precedenti non forniscono informazioni dettagliate, connettersi a uno dei nodi di lavoro e tentare la risoluzione DNS dal nodo. Questo passaggio consente di identificare se il problema è correlato al servizio Azure Kubernetes o alla configurazione di rete.
Se la risoluzione DNS ha esito positivo dal nodo ma non dal pod, il problema potrebbe essere correlato al DNS Kubernetes. Per la procedura per eseguire il debug della risoluzione DNS dal pod, vedere Risolvere gli errori di risoluzione DNS.
Se la risoluzione DNS non riesce dal nodo, esaminare la configurazione di rete per assicurarsi che i percorsi di routing e le porte appropriati siano aperti per facilitare la risoluzione DNS.
Passaggio 4: Verificare la presenza di errori kubelet
Verificare la condizione del processo kubelet eseguito in ogni nodo del ruolo di lavoro e assicurarsi che non sia sotto pressione. La potenziale pressione potrebbe riguardare CPU, memoria o archiviazione. Per verificare lo stato dei singoli kubelet dei nodi, è possibile usare uno dei metodi seguenti.
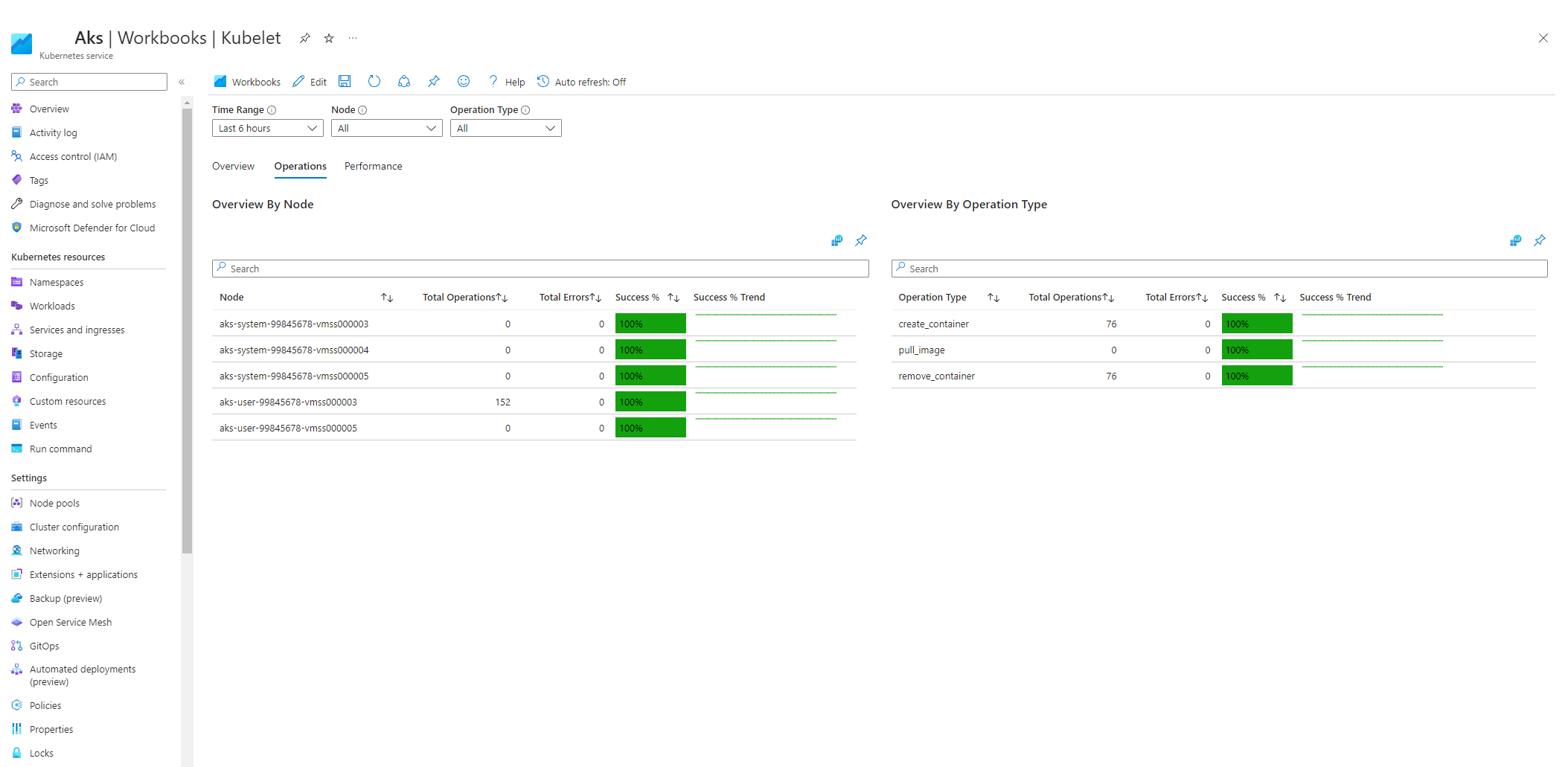
Cartella di lavoro kubelet del servizio Azure Kubelet
Per assicurarsi che kubelet del nodo agente funzioni correttamente, seguire questa procedura:
Passare al cluster del servizio Azure Kubernetes nel portale di Azure.
Nella sezione Monitoraggio del riquadro di spostamento selezionare Cartelle di lavoro.
Selezionare la cartella di lavoro di Kubelet .

Selezionare Operazioni e assicurarsi che le operazioni per tutti i nodi di lavoro siano completate.


Monitoraggio in cluster con Prometheus e Grafana
Se Prometheus e Grafana sono stati distribuiti nel cluster del servizio Azure Kubernetes, è possibile usare il dashboard Kubernetes/Kubelet per ottenere informazioni dettagliate sull'integrità e sulle prestazioni dei singoli kubelet dei nodi.

Monitorare il servizio gestito per Prometheus e Grafana gestito di Azure
È possibile usare il dashboard predefinito kubernetes/Kubelet per visualizzare e analizzare le metriche di Prometheus per i kubelet del nodo di lavoro. A tale scopo, è necessario configurare il cluster del servizio Azure Kubernetes per raccogliere le metriche di Prometheus nel servizio gestito di Monitoraggio per Prometheus e connettere l'area di lavoro Monitoraggio a un'area di lavoro Grafana gestita di Azure.

La pressione aumenta quando un kubelet viene riavviato e causa un comportamento sporadico e imprevedibile. Assicurarsi che il conteggio degli errori non si cresca continuamente. Un errore occasionale è accettabile, ma una crescita costante indica un problema sottostante che è necessario analizzare e risolvere.
Passaggio 5: Usare lo strumento NpD (Node Problem Detector) per controllare l'integrità dei nodi
NPD è uno strumento Kubernetes che è possibile usare per identificare e segnalare i problemi correlati al nodo. Opera come servizio di sistema in ogni nodo all'interno del cluster. Raccoglie metriche e informazioni di sistema, ad esempio l'utilizzo della CPU, l'utilizzo del disco e lo stato della connettività di rete. Quando viene rilevato un problema, lo strumento NPD genera un report sugli eventi e sulla condizione del nodo. Nel servizio Azure Kubernetes lo strumento NPD viene usato per monitorare e gestire i nodi in un cluster Kubernetes ospitato nel cloud di Azure. Per altre informazioni, vedere Server dei criteri di rete nei nodi del servizio Azure Kubernetes.
Passaggio 6: Controllare le operazioni di I/O su disco al secondo (IOPS) per la limitazione delle richieste
Per assicurarsi che le operazioni di I/O al secondo non vengano limitate e influiscano sui servizi e sui carichi di lavoro all'interno del cluster del servizio Azure Kubernetes, è possibile usare uno dei metodi seguenti.
Cartella di lavoro di I/O del disco del nodo del servizio Azure Kubernetes
Per monitorare le metriche correlate all'I/O del disco dei nodi di lavoro nel cluster del servizio Azure Kubernetes, è possibile usare la cartella di lavoro di I/O del disco del nodo. Per accedere alla cartella di lavoro, seguire questa procedura:
Passare al cluster del servizio Azure Kubernetes nel portale di Azure.
Nella sezione Monitoraggio del riquadro di spostamento selezionare Cartelle di lavoro.
Selezionare la cartella di lavoro I/O del disco del nodo.

Esaminare le metriche correlate all'I/O.



Monitoraggio in cluster con Prometheus e Grafana
Se Prometheus e Grafana sono stati distribuiti nel cluster del servizio Azure Kubernetes, è possibile usare il dashboard U edizione Standard Method/Node per ottenere informazioni dettagliate sull'I/O del disco per i nodi del ruolo di lavoro del cluster.

Monitorare il servizio gestito per Prometheus e Grafana gestito di Azure
È possibile usare il dashboard predefinito Utilità di esportazione/nodi del nodo per visualizzare e analizzare le metriche correlate all'I/O del disco dai nodi di lavoro. A tale scopo, è necessario configurare il cluster del servizio Azure Kubernetes per raccogliere le metriche di Prometheus nel servizio gestito di Monitoraggio per Prometheus e connettere l'area di lavoro Monitoraggio a un'area di lavoro Grafana gestita di Azure.

Operazioni di I/O al secondo e dischi di Azure
I dispositivi di archiviazione fisica presentano limitazioni intrinseche in termini di larghezza di banda e il numero massimo di operazioni di file che possono gestire. I dischi di Azure vengono usati per archiviare il sistema operativo in esecuzione nei nodi del servizio Azure Kubernetes. I dischi sono soggetti agli stessi vincoli di archiviazione fisica del sistema operativo.
Si consideri il concetto di velocità effettiva. È possibile moltiplicare le dimensioni medie di I/O in base alle operazioni di I/O al secondo per determinare la velocità effettiva in megabyte al secondo (MBps). Le dimensioni di I/O maggiori si traducono in operazioni di I/O inferiori a causa della velocità effettiva fissa del disco.
Quando un carico di lavoro supera i limiti massimi del servizio operazioni di I/O al secondo assegnati ai dischi di Azure, il cluster potrebbe non rispondere e immettere uno stato di attesa di I/O. Nei sistemi basati su Linux, molti componenti vengono considerati come file, ad esempio socket di rete, CNI, Docker e altri servizi che dipendono dall'I/O di rete. Di conseguenza, se il disco non può essere letto, l'errore si estende a tutti questi file.
Diversi eventi e scenari possono attivare la limitazione delle operazioni di I/O al secondo, tra cui:
Numero sostanziale di contenitori eseguiti nei nodi, perché Docker I/O condivide il disco del sistema operativo.
Strumenti personalizzati o di terze parti usati per la sicurezza, il monitoraggio e la registrazione, che potrebbero generare operazioni di I/O aggiuntive sul disco del sistema operativo.
Eventi di failover dei nodi e processi periodici che intensificano il carico di lavoro o ridimensionano il numero di pod. Questo aumento del carico aumenta la probabilità di limitazione delle occorrenze, causando potenzialmente la transizione di tutti i nodi a uno stato non pronto fino alla conclusione delle operazioni di I/O.
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autori principali:
- Paolo Salvatori | Principal Customer Engineer
- Francesco Simy Nazareth | Senior Technical Specialist
Per visualizzare i profili LinkedIn non pubblici, accedere a LinkedIn.