Elaborare un set di messaggi correlati in un ordine definito, senza bloccare l'elaborazione di altri gruppi di messaggi.
Contesto e problema
Le applicazioni spesso devono elaborare una sequenza di messaggi nell'ordine in cui arrivano, pur essendo in grado di aumentare il numero di istanze per gestire un carico maggiore. In un'architettura distribuita, l'elaborazione di questi messaggi in ordine non è semplice, perché i lavoratori possono ridimensionare i messaggi in modo indipendente e spesso eseguire il pull dei messaggi in modo indipendente, usando un modello Consumer concorrenti.
Ad esempio, un sistema di rilevamento degli ordini riceve un libro mastro contenente ordini e le operazioni pertinenti su tali ordini. Queste operazioni possono essere per creare un ordine, aggiungere una transazione all'ordine, modificare una transazione precedente o eliminare un ordine. In questo sistema, le operazioni devono essere eseguite in modo FIFO (First-In-First Out), ma solo a livello di ordine. Tuttavia, la coda iniziale riceve un libro mastro contenente transazioni per molti ordini, che possono essere interleaved.
Soluzione
Eseguire il push dei messaggi correlati in categorie all'interno del sistema di accodamento e bloccare i listener della coda ed eseguire il pull solo da una categoria, un messaggio alla volta.
Di seguito è riportato l'aspetto del modello sequenziale generale del convoglio:
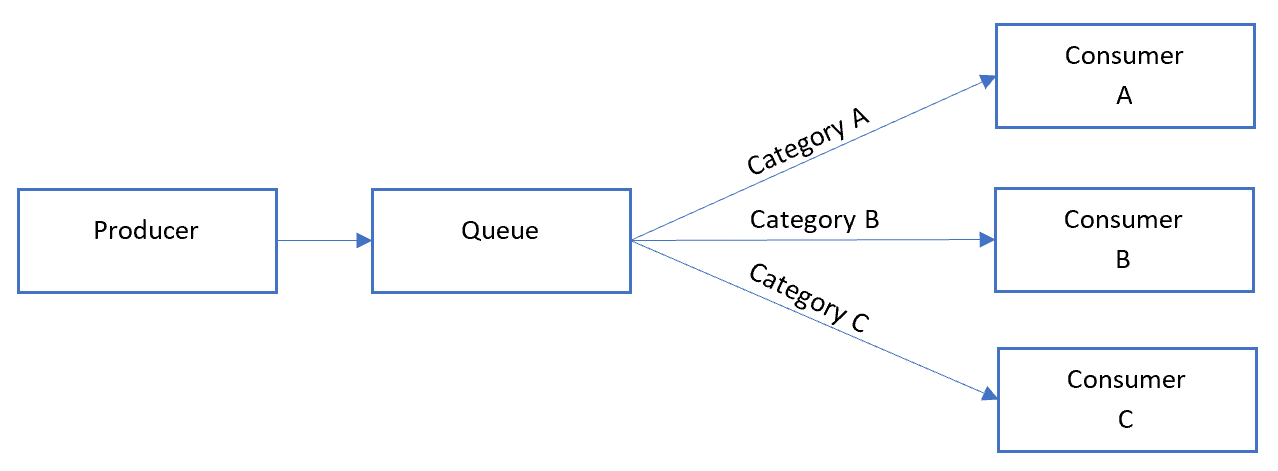
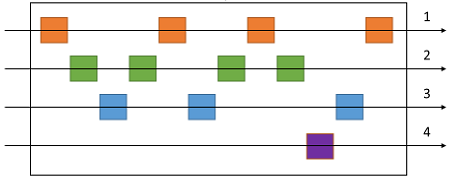
Nella coda i messaggi per categorie diverse possono essere interleaved, come illustrato nel diagramma seguente:
Considerazioni e problemi
Prima di decidere come implementare questo modello, considerare quanto segue:
- Categoria/unità di scala. Quale proprietà dei messaggi in arrivo è possibile aumentare le prestazioni? Nello scenario di rilevamento degli ordini questa proprietà è l'ID dell'ordine.
- Velocità effettiva. Qual è la velocità effettiva del messaggio di destinazione? Se è molto elevato, potrebbe essere necessario riconsiderare i requisiti FIFO. Ad esempio, è possibile applicare un messaggio di inizio/fine, ordinare in base all'ora, quindi inviare un batch per l'elaborazione?
- Funzionalità del servizio. La scelta del bus di messaggi consente l'elaborazione occasionale dei messaggi all'interno di una coda o di una categoria di una coda?
- Elulubilità. Come si aggiungerà una nuova categoria di messaggi al sistema? Si supponga, ad esempio, che il sistema libro mastro descritto in precedenza sia specifico di un cliente. Se è necessario eseguire l'onboarding di un nuovo cliente, è possibile avere un set di processori libro mastro che distribuiscono il lavoro per ID cliente?
- È possibile che i consumer ricevano un messaggio non in ordine, a causa della latenza di rete variabile durante l'invio di messaggi. Prendere in considerazione l'uso dei numeri di sequenza per verificare l'ordinamento. È anche possibile includere un flag speciale "fine della sequenza" nell'ultimo messaggio di una transazione. Le tecnologie di elaborazione dei flussi, ad esempio Spark o Analisi di flusso di Azure, possono elaborare i messaggi in ordine entro un intervallo di tempo.
Quando usare questo modello
Usare questo modello quando:
- Si dispone di messaggi che arrivano in ordine e devono essere elaborati nello stesso ordine.
- I messaggi in arrivo sono o possono essere "classificati" in modo che la categoria diventi un'unità di scala per il sistema.
Questo modello potrebbe non essere adatto per:
- Scenari con velocità effettiva estremamente elevata (milioni di messaggi al minuto o secondo), poiché il requisito FIFO limita il ridimensionamento che può essere eseguito dal sistema.
Progettazione del carico di lavoro
Un architetto deve valutare il modo in cui il modello di convoglio sequenziale può essere usato nella progettazione del carico di lavoro per soddisfare gli obiettivi e i principi trattati nei pilastri di Azure Well-Architected Framework. Ad esempio:
| Concetto fondamentale | Come questo modello supporta gli obiettivi di pilastro |
|---|---|
| Le decisioni di progettazione dell'affidabilità consentono al carico di lavoro di diventare resilienti a malfunzionamenti e di assicurarsi che venga ripristinato in uno stato completamente funzionante dopo che si verifica un errore. | Questo modello può eliminare le race condition difficili da risolvere, la gestione dei messaggi contesa o altre soluzioni alternative per l'indirizzamento non corretto dei messaggi ordinati che possono causare malfunzionamenti. - Flussi critici RE:02 - RE:07 Processi in background |
Come per qualsiasi decisione di progettazione, prendere in considerazione eventuali compromessi rispetto agli obiettivi degli altri pilastri che potrebbero essere introdotti con questo modello.
Esempio
In Azure questo modello può essere implementato usando bus di servizio di Azure sessioni di messaggi. Per i consumer, è possibile usare App per la logica con il connettore bus di servizio peek-lock o Funzioni di Azure con il trigger bus di servizio.
Per l'esempio di rilevamento degli ordini precedente, elaborare ogni messaggio mastro nell'ordine in cui viene ricevuto e inviare ogni transazione a un'altra coda in cui la categoria è impostata sull'ID ordine. Una transazione non si estenderà mai su più ordini in questo scenario, quindi i consumer elaborano ogni categoria in parallelo ma FIFO all'interno della categoria.
Il processore di ledge rimuove i messaggi de-batch eseguendo il de-batch del contenuto di ogni messaggio nella prima coda:
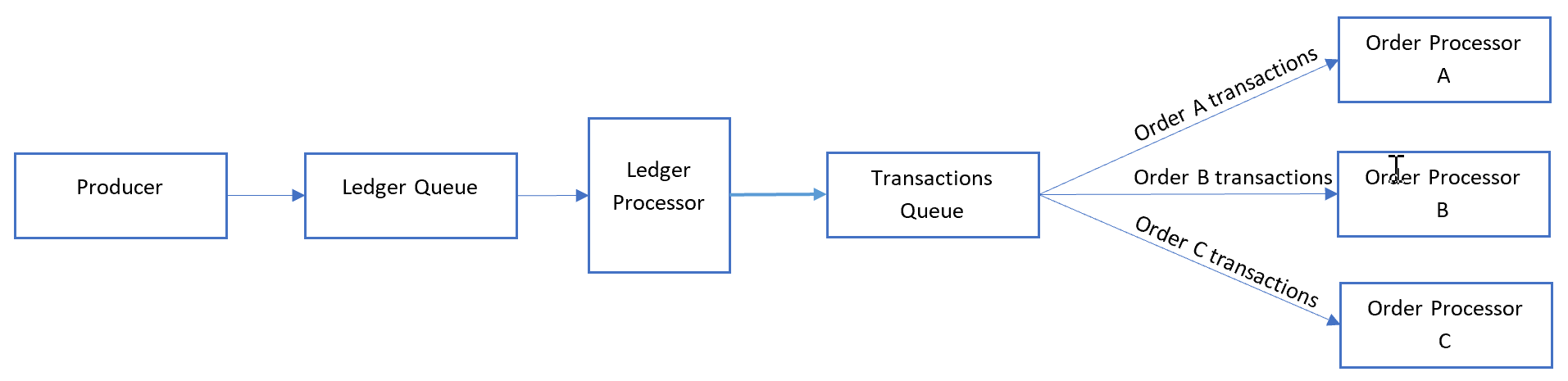
Il processore del libro mastro si occupa di:
- Camminare il libro mastro una transazione alla volta.
- Impostazione dell'ID sessione del messaggio in modo che corrisponda all'ID dell'ordine.
- Invio di ogni transazione libro mastro a una coda secondaria con l'ID sessione impostato sull'ID ordine.
I consumer ascoltano la coda secondaria in cui elaborano tutti i messaggi con ID ordine corrispondenti in ordine dalla coda. I consumer usano la modalità peek-lock .
Quando si considera la scalabilità, la coda del libro mastro è un collo di bottiglia principale. Transazioni diverse registrate nel libro mastro potrebbero fare riferimento allo stesso ID ordine. Tuttavia, i messaggi possono visualizzare i messaggi dopo il libro mastro al numero di ordini in un ambiente serverless.
Passaggi successivi
Per l'implementazione di questo modello possono risultare utili anche le informazioni seguenti: