Questo articolo descrive come un team di sviluppo ha usato le metriche per trovare colli di bottiglia e migliorare le prestazioni di un sistema distribuito. L'articolo si basa sul test di carico effettivo eseguito per un'applicazione di esempio. L'applicazione proviene dalla baseline di servizio Azure Kubernetes (servizio Azure Kubernetes) per i microservizi.
Questo articolo fa parte di una serie. Leggere la prima parte qui.
Scenario: un'applicazione client avvia una transazione aziendale che prevede più passaggi.
Questo scenario prevede un'applicazione di recapito tramite drone eseguita nel servizio Azure Kubernetes. I clienti usano un'app Web per pianificare le consegne tramite drone. Ogni transazione richiede più passaggi eseguiti da microservizi separati nel back-end:
- Il servizio di recapito gestisce le consegne.
- Il servizio Drone Scheduler pianifica i droni per il ritiro.
- Il servizio Pacchetto gestisce i pacchetti.
Esistono altri due servizi: un servizio di inserimento che accetta le richieste client e le inserisce in una coda per l'elaborazione e un servizio flusso di lavoro che coordina i passaggi nel flusso di lavoro.

Per altre informazioni su questo scenario, vedere Progettazione di un'architettura di microservizi.
Test 1: Baseline
Per il primo test di carico, il team ha creato un cluster servizio Azure Kubernetes a sei nodi e ha distribuito tre repliche di ogni microservizio. Il test di carico è stato un test di carico dettagliato, a partire da due utenti simulati e fino a 40 utenti simulati.
| Impostazione | Valore |
|---|---|
| Nodi del cluster | 6 |
| Pod | 3 per servizio |
Il grafico seguente mostra i risultati del test di carico, come illustrato in Visual Studio. La linea viola traccia il carico dell'utente e la linea arancione traccia le richieste totali.
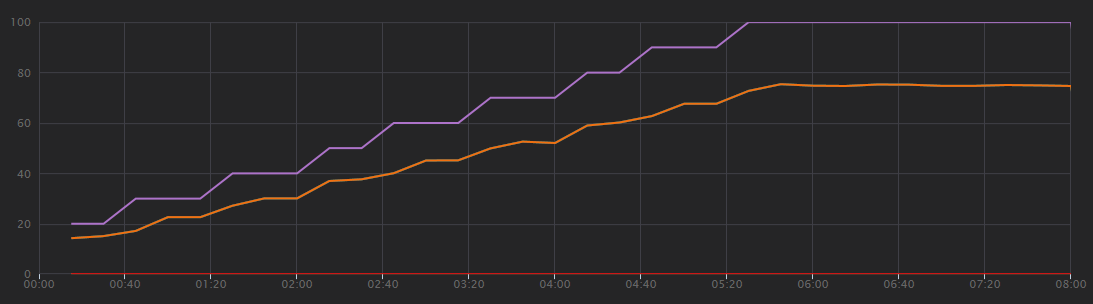
La prima cosa da comprendere su questo scenario è che le richieste client al secondo non sono una metrica utile delle prestazioni. Ciò è dovuto al fatto che l'applicazione elabora le richieste in modo asincrono, in modo che il client ottenga immediatamente una risposta. Il codice di risposta è sempre HTTP 202 (accettato), ovvero la richiesta è stata accettata ma l'elaborazione non è completa.
Ciò che si vuole sapere è se il back-end è sempre al passo con la frequenza delle richieste. La coda del bus di servizio può assorbire i picchi, ma se il back-end non è in grado di gestire un carico sostenuto, l'elaborazione scenderà ulteriormente e ulteriormente dietro.
Ecco un grafico più informativo. Traccia il numero di messaggi in ingresso e in uscita nella coda del bus di servizio. I messaggi in arrivo vengono visualizzati in blu chiaro e i messaggi in uscita vengono visualizzati in blu scuro:
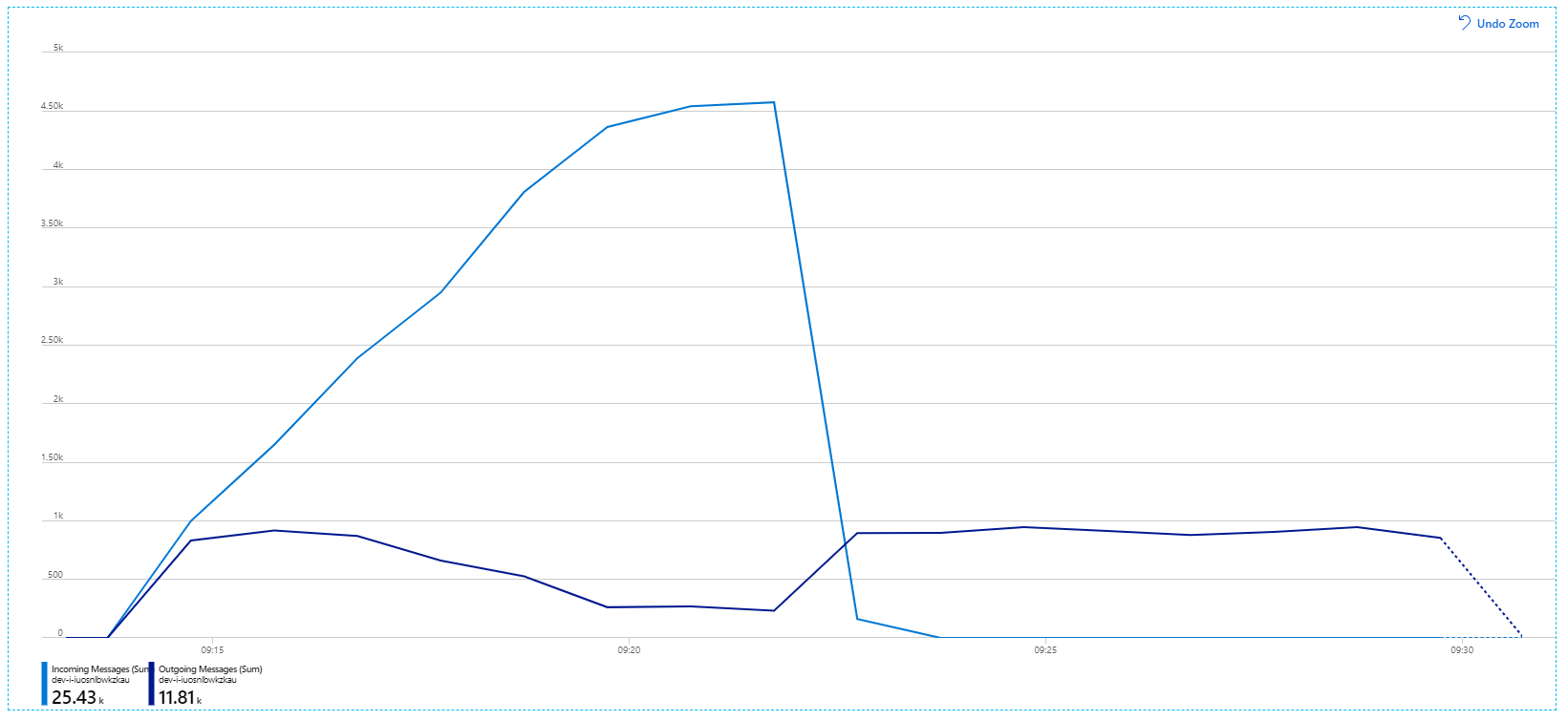
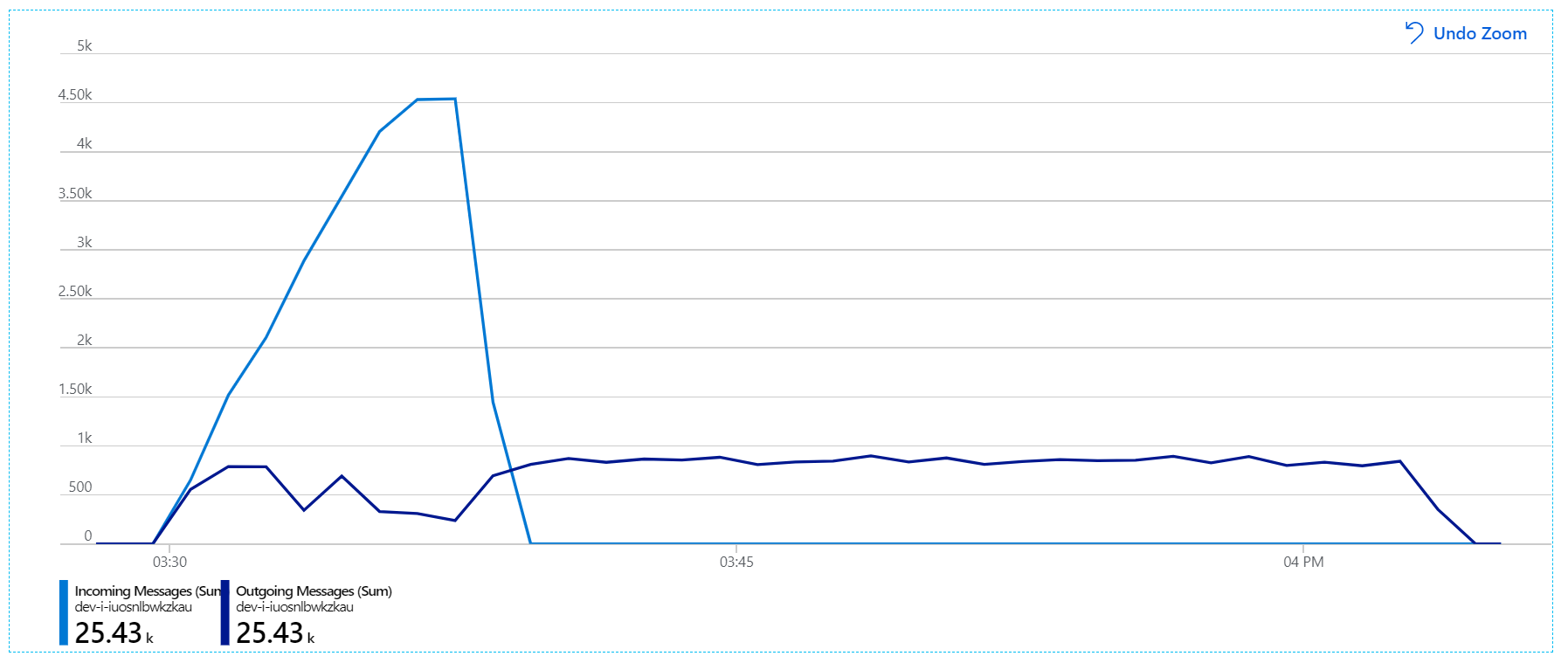
Questo grafico mostra che la frequenza dei messaggi in ingresso aumenta, raggiunge un picco e quindi torna a zero alla fine del test di carico. Ma il numero di messaggi in uscita raggiunge un picco nelle prime fasi del test e poi scende effettivamente. Ciò significa che il servizio Flusso di lavoro, che gestisce le richieste, non è sempre aggiornato. Anche dopo la fine del test di carico (circa 9:22 sul grafico), i messaggi vengono ancora elaborati mentre il servizio flusso di lavoro continua a svuotare la coda.
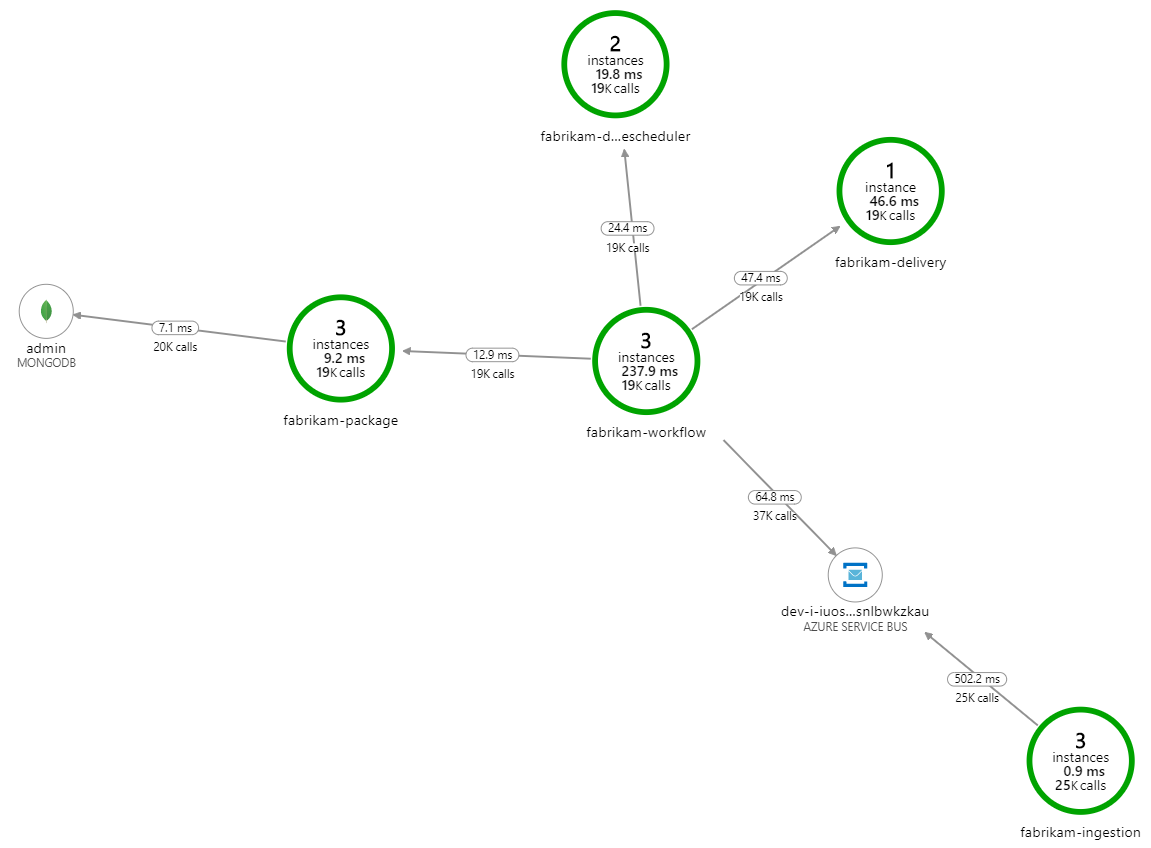
Che cosa rallenta l'elaborazione? La prima cosa da cercare è errori o eccezioni che potrebbero indicare un problema sistematico. La mappa delle applicazioni in Monitoraggio di Azure mostra il grafico delle chiamate tra i componenti ed è un modo rapido per individuare i problemi e quindi fare clic su per ottenere altri dettagli.
La mappa delle applicazioni indica che il servizio flusso di lavoro riceve errori dal servizio di recapito:
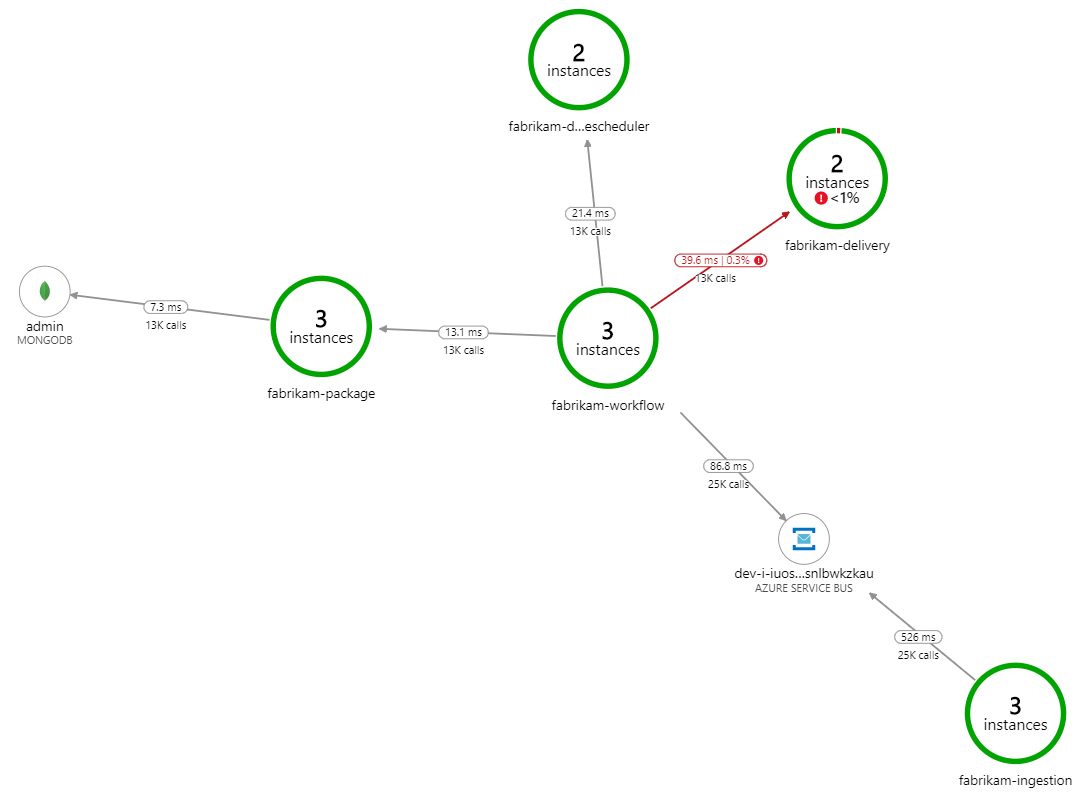
Per visualizzare altri dettagli, è possibile selezionare un nodo nel grafico e fare clic in una visualizzazione delle transazioni end-to-end. In questo caso, indica che il servizio di recapito restituisce errori HTTP 500. I messaggi di errore indicano che viene generata un'eccezione a causa di limiti di memoria in cache di Azure per Redis.
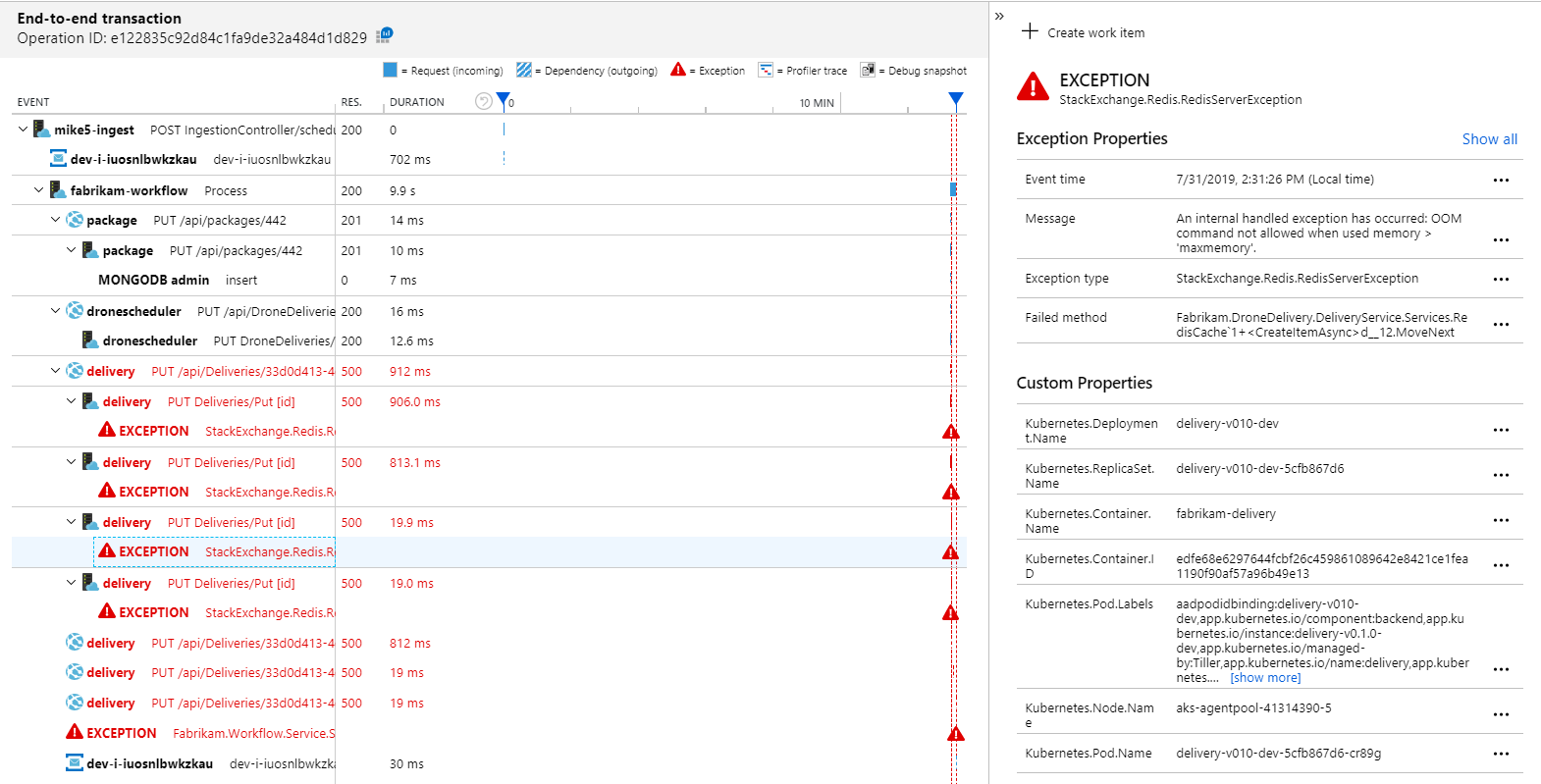
È possibile notare che queste chiamate a Redis non vengono visualizzate nella mappa delle applicazioni. Ciò è dovuto al fatto che la libreria .NET per Application Insights non ha il supporto predefinito per tenere traccia di Redis come dipendenza. Per un elenco delle funzionalità supportate, vedere Raccolta automatica delle dipendenze. Come fallback, è possibile usare l'API TrackDependency per tenere traccia di qualsiasi dipendenza. I test di carico spesso rivelano questi tipi di gap nei dati di telemetria, che possono essere corretti.
Test 2: Aumento delle dimensioni della cache
Per il secondo test di carico, il team di sviluppo ha aumentato le dimensioni della cache in cache di Azure per Redis. Vedere Come ridimensionare cache di Azure per Redis. Questa modifica ha risolto le eccezioni di memoria insufficiente e ora la mappa delle applicazioni mostra zero errori:
Tuttavia, esiste ancora un notevole ritardo nell'elaborazione dei messaggi. Al picco del test di carico, la frequenza dei messaggi in ingresso è superiore a 5× la frequenza in uscita:
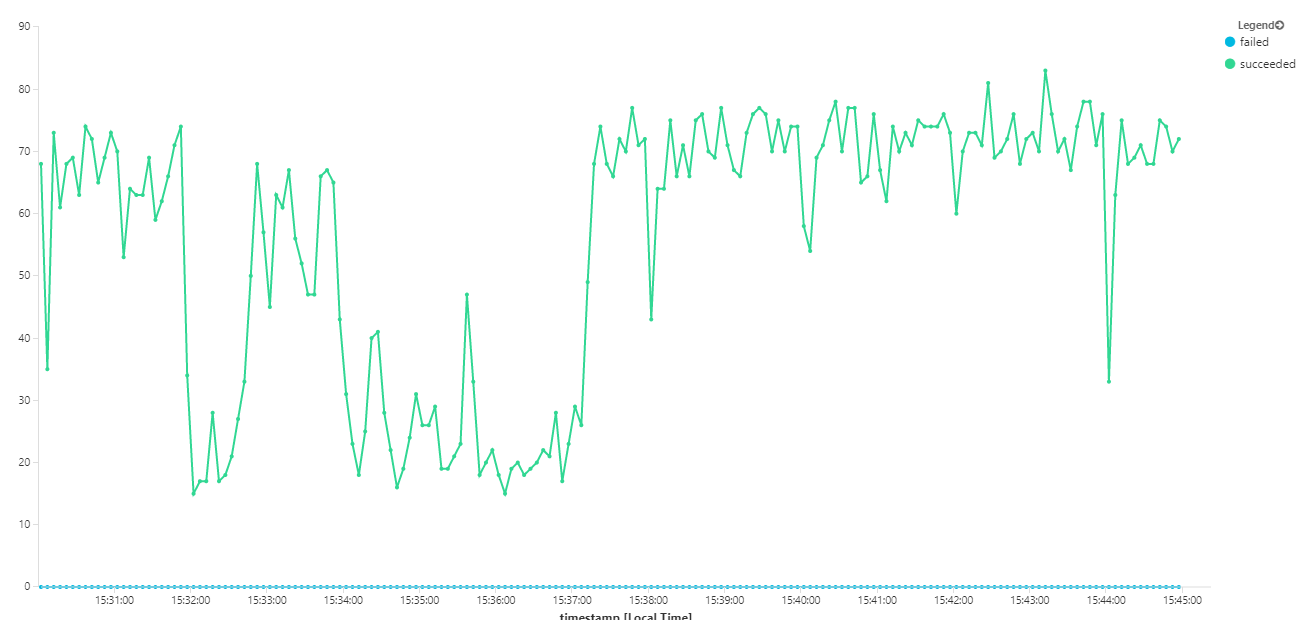
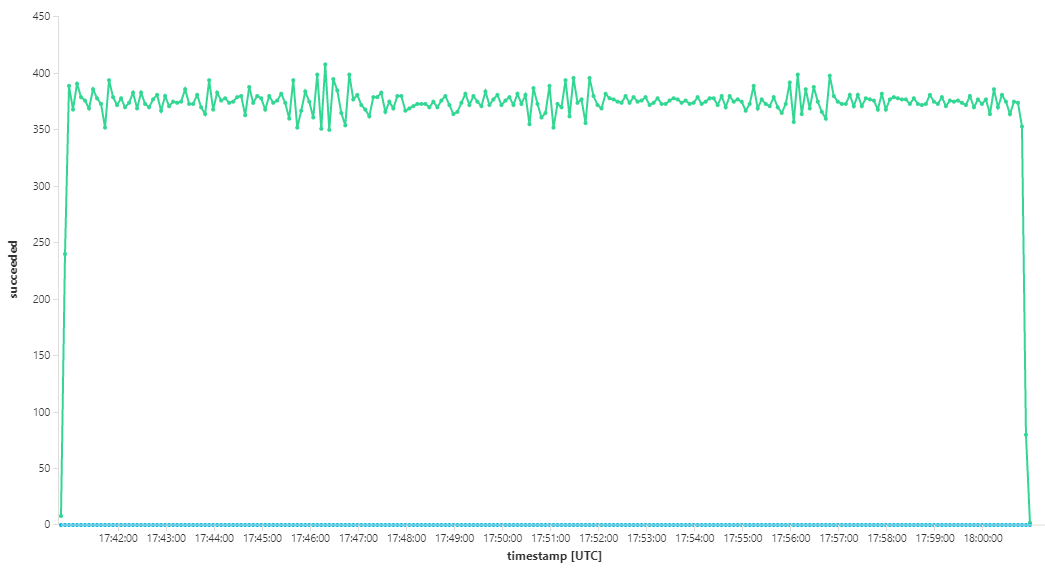
Il grafico seguente misura la velocità effettiva in termini di completamento dei messaggi, ovvero la frequenza con cui il servizio Flusso di lavoro contrassegna i messaggi del bus di servizio come completati. Ogni punto del grafico rappresenta 5 secondi di dati, con una velocità effettiva massima di ~16/sec.
Questo grafico è stato generato eseguendo una query nell'area di lavoro Log Analytics, usando il linguaggio di query Kusto:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
dependencies
| where cloud_RoleName == 'fabrikam-workflow'
| where timestamp > start and timestamp < end
| where type == 'Azure Service Bus'
| where target has 'https://dev-i-iuosnlbwkzkau.servicebus.windows.net'
| where client_Type == "PC"
| where name == "Complete"
| summarize succeeded=sumif(itemCount, success == true), failed=sumif(itemCount, success == false) by bin(timestamp, 5s)
| render timechart
Test 3: Aumentare il numero di istanze dei servizi back-end
Sembra che il back-end sia il collo di bottiglia. Un passaggio successivo semplice consiste nell'aumentare il numero di istanze dei servizi aziendali (Package, Delivery e Drone Scheduler) e verificare se la velocità effettiva migliora. Per il test di carico successivo, il team ha ridimensionato questi servizi da tre repliche a sei repliche.
| Impostazione | Valore |
|---|---|
| Nodi del cluster | 6 |
| Servizio di inserimento | 3 repliche |
| Servizio flusso di lavoro | 3 repliche |
| Package, Delivery, Drone Scheduler services | 6 repliche ognuna |
Sfortunatamente, questo test di carico mostra solo un miglioramento modesto. I messaggi in uscita non sono ancora aggiornati con i messaggi in arrivo:
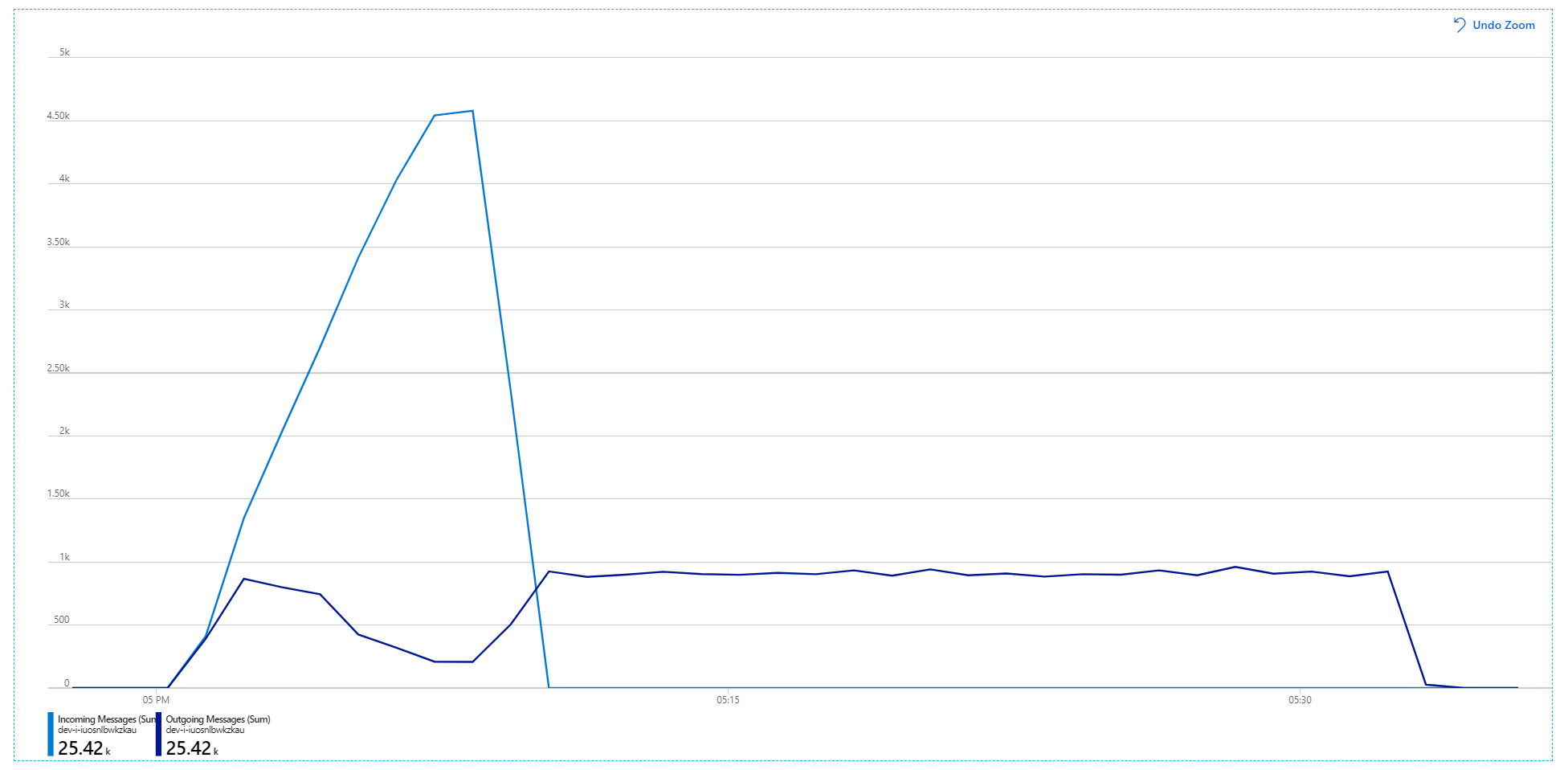
La velocità effettiva è più coerente, ma il massimo ottenuto è uguale al test precedente:
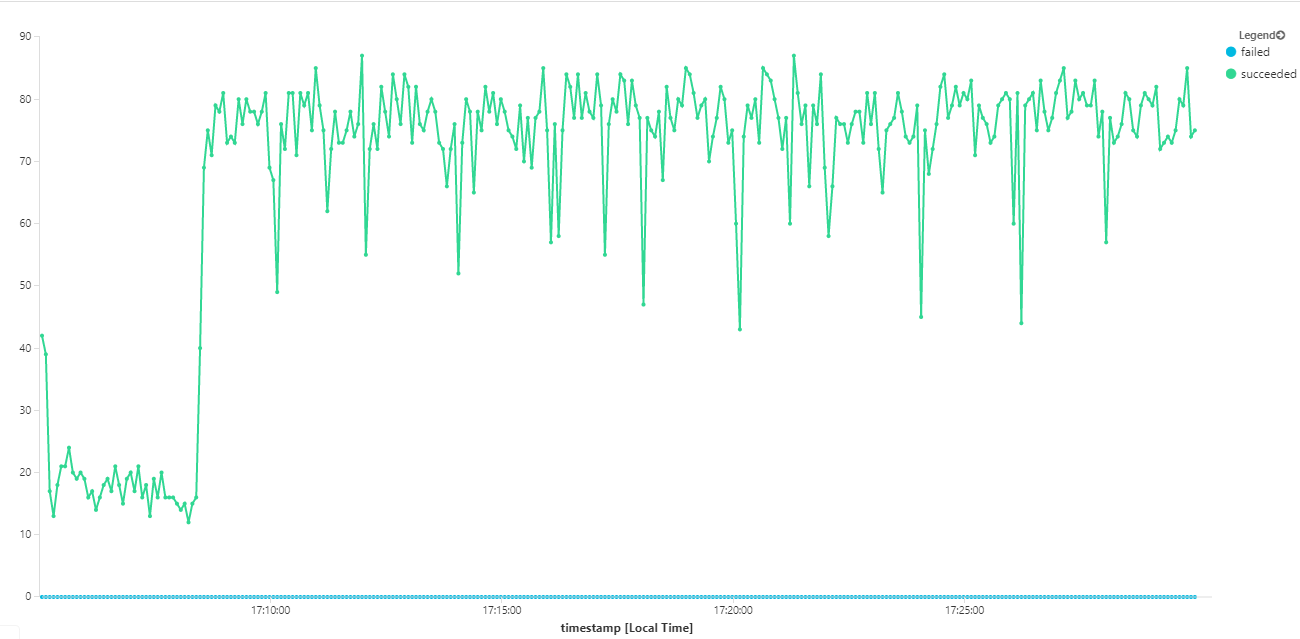
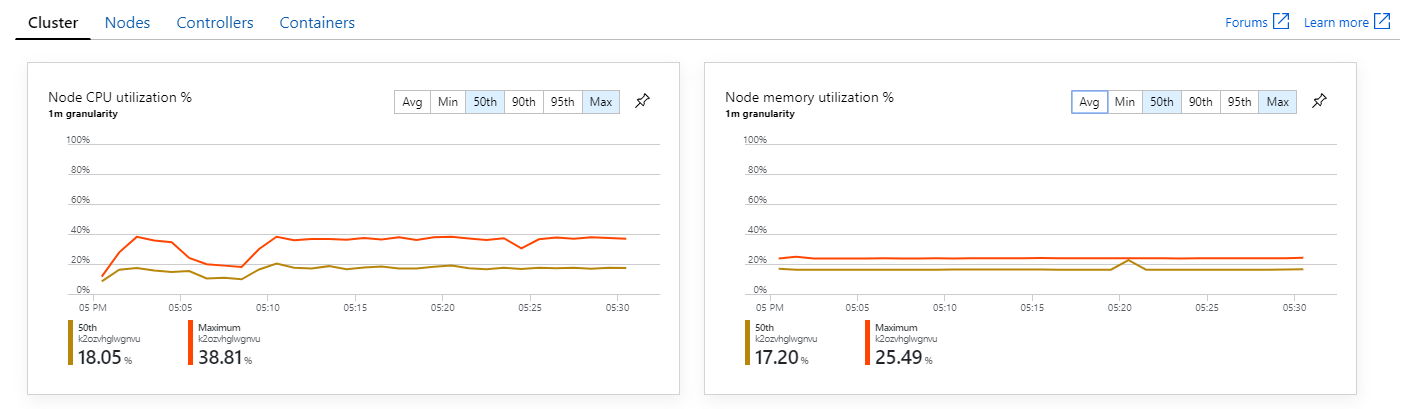
Inoltre, esaminando le informazioni dettagliate sui contenitori di Monitoraggio di Azure, sembra che il problema non sia causato dall'esaurimento delle risorse all'interno del cluster. In primo luogo, le metriche a livello di nodo indicano che l'utilizzo della CPU rimane inferiore al 40% anche al 95° percentile e l'utilizzo della memoria è circa il 20%.
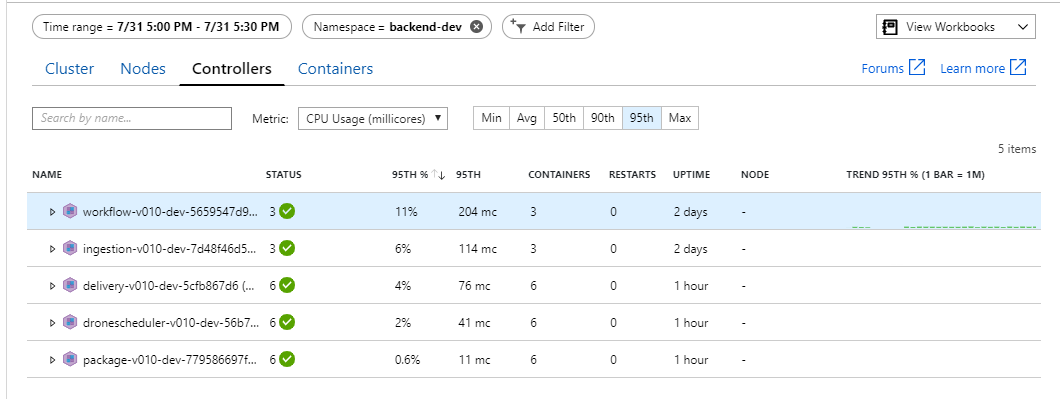
In un ambiente Kubernetes è possibile che i singoli pod siano vincolati alle risorse anche quando i nodi non sono. Tuttavia, la visualizzazione a livello di pod mostra che tutti i pod sono integri.
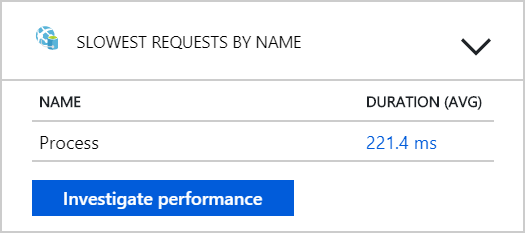
Da questo test sembra che l'aggiunta di più pod al back-end non sia utile. Il passaggio successivo consiste nell'esaminare più attentamente il servizio Flusso di lavoro per comprendere cosa accade quando elabora i messaggi. Application Insights mostra che la durata media dell'operazione del servizio flusso di Process lavoro è di 246 ms.
È anche possibile eseguire una query per ottenere metriche sulle singole operazioni all'interno di ogni transazione:
| target | percentile_duration_50 | percentile_duration_95 |
|---|---|---|
https://dev-i-iuosnlbwkzkau.servicebus.windows.net/ | dev-i-iuosnlbwkzkau |
86.66950203 | 283.4255578 |
| di contenuti | 37 | 57 |
| Pacchetto | 12 | 17 |
| dronescheduler | 21 | 41 |
La prima riga di questa tabella rappresenta la coda del bus di servizio. Le altre righe sono le chiamate ai servizi back-end. Per riferimento, ecco la query di Log Analytics per questa tabella:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
let dataset=dependencies
| where timestamp > start and timestamp < end
| where (cloud_RoleName == 'fabrikam-workflow')
| where name == 'Complete' or target in ('package', 'delivery', 'dronescheduler');
dataset
| summarize percentiles(duration, 50, 95) by target
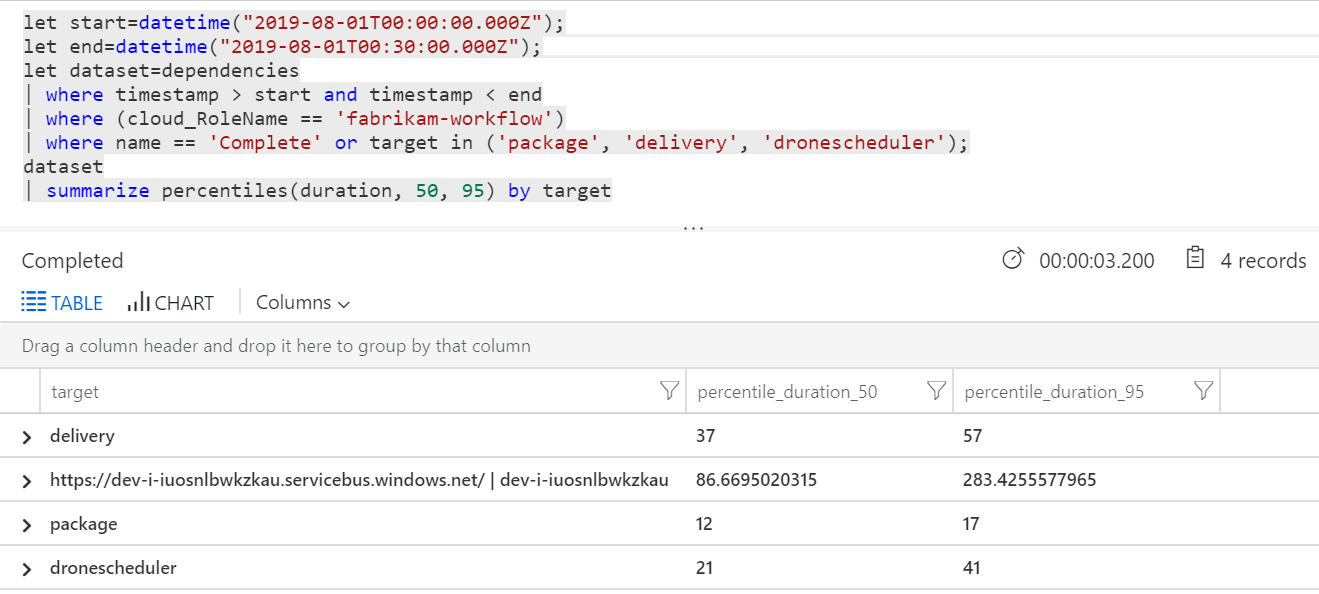
Queste latenze sembrano ragionevoli. Ma ecco le informazioni chiave: se il tempo totale dell'operazione è di circa 250 ms, questo mette un limite massimo rigoroso sulla velocità di elaborazione dei messaggi in serie. La chiave per migliorare la velocità effettiva, pertanto, è un parallelismo maggiore.
Ciò dovrebbe essere possibile in questo scenario, per due motivi:
- Si tratta di chiamate di rete, quindi la maggior parte del tempo viene impiegato in attesa del completamento di I/O
- I messaggi sono indipendenti e non devono essere elaborati in ordine.
Test 4: Aumentare il parallelismo
Per questo test, il team si è concentrato sull'aumento del parallelismo. A tale scopo, sono state modificate due impostazioni nel client del bus di servizio usato dal servizio Flusso di lavoro:
| Impostazione | Descrizione | Predefinito | Nuovo valore |
|---|---|---|---|
MaxConcurrentCalls |
Numero massimo di messaggi da elaborare simultaneamente. | 1 | 20 |
PrefetchCount |
Numero di messaggi che il client recupererà in anticipo nella cache locale. | 0 | 3000 |
Per altre informazioni su queste impostazioni, vedere Procedure consigliate per i miglioramenti delle prestazioni tramite la messaggistica del bus di servizio. L'esecuzione del test con queste impostazioni ha prodotto il grafico seguente:
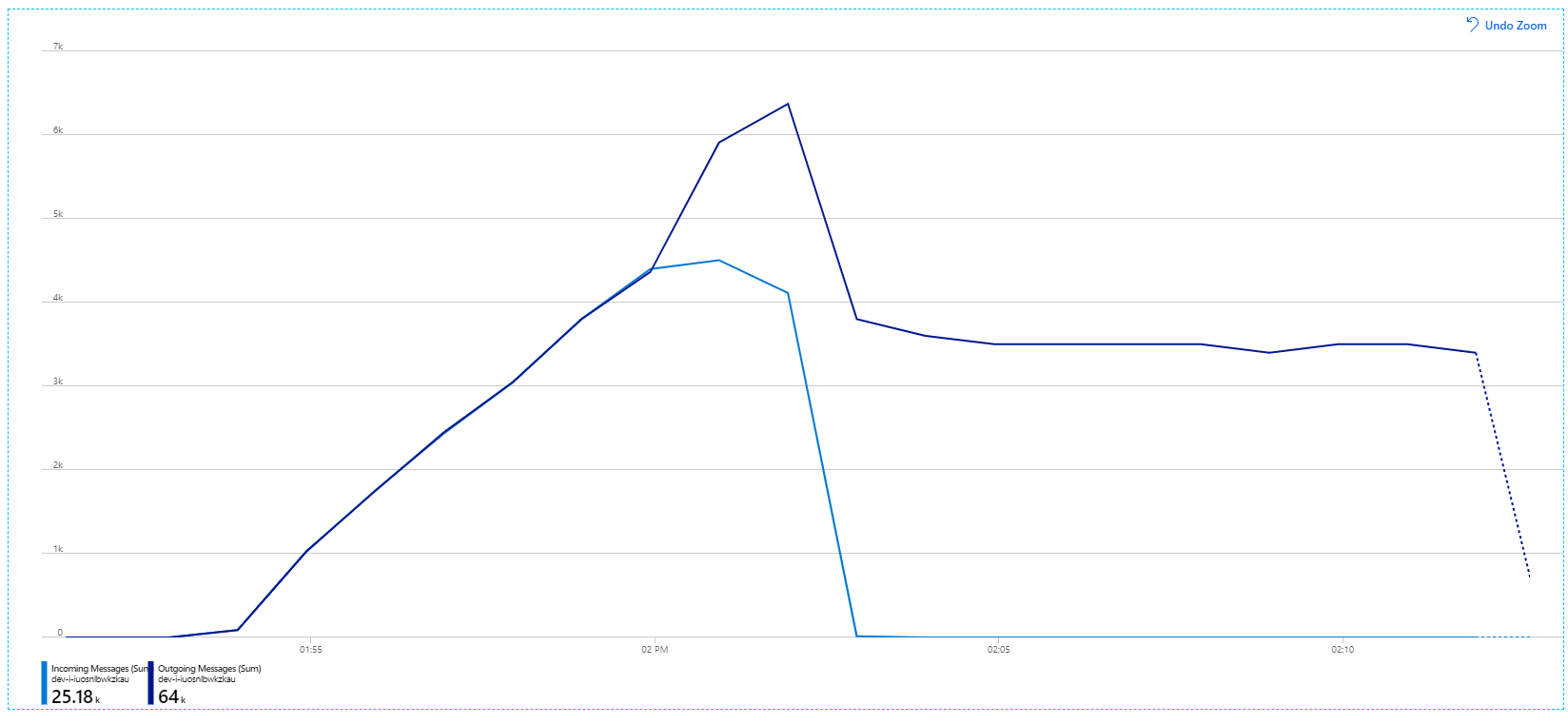
Tenere presente che i messaggi in arrivo vengono visualizzati in blu chiaro e i messaggi in uscita vengono visualizzati in blu scuro.
A prima vista, questo è un grafico molto strano. Per un po', la frequenza dei messaggi in uscita tiene traccia esattamente della frequenza in ingresso. Ma poi, a circa il contrassegno 2:03, la frequenza dei messaggi in arrivo è disattivata, mentre il numero di messaggi in uscita continua ad aumentare, in realtà superando il numero totale di messaggi in arrivo. Sembra impossibile.
L'indizio di questo mistero è disponibile nella visualizzazione Dipendenze in Application Insights. Questo grafico riepiloga tutte le chiamate effettuate dal servizio Flusso di lavoro al bus di servizio:
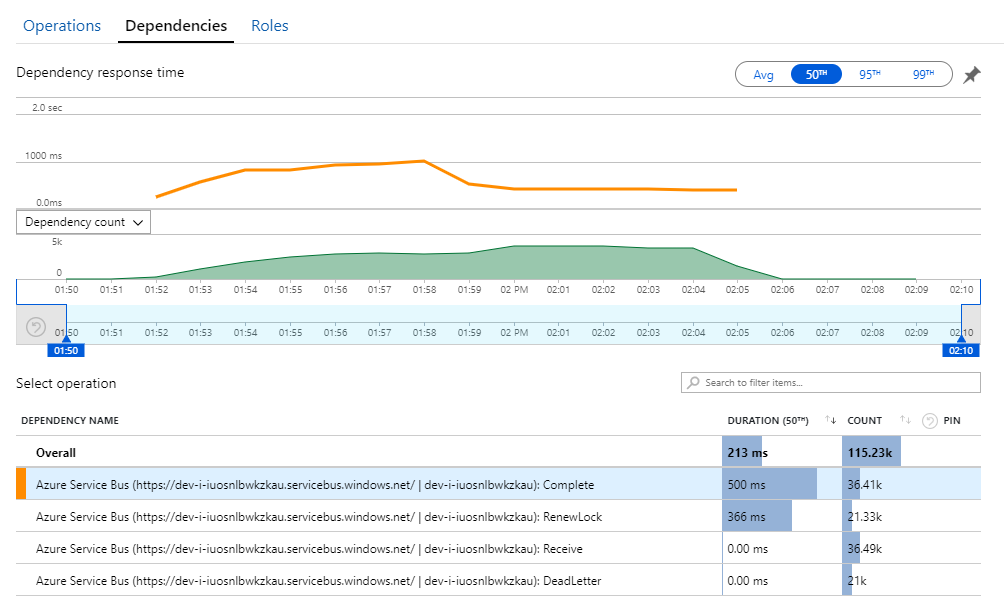
Si noti che la voce per DeadLetter. Le chiamate indicano che i messaggi verranno inseriti nella coda dei messaggi non recapitabili del bus di servizio.
Per comprendere cosa accade, è necessario comprendere la semantica Peek-Lock nel bus di servizio. Quando un client usa Peek-Lock, il bus di servizio recupera e blocca in modo atomico un messaggio. Mentre il blocco viene mantenuto, il messaggio non viene recapitato ad altri ricevitori. Se il blocco scade, il messaggio diventa disponibile per altri ricevitori. Dopo un numero massimo di tentativi di recapito (configurabili), il bus di servizio inserisce i messaggi in una coda di messaggi non recapitabili, in cui può essere esaminato in un secondo momento.
Tenere presente che il servizio Flusso di lavoro esegue il prelettura di batch di messaggi di grandi dimensioni, ovvero 3000 messaggi alla volta. Ciò significa che il tempo totale per elaborare ogni messaggio è più lungo, il che comporta il timeout dei messaggi, il ritorno alla coda e infine l'ingresso nella coda dei messaggi non recapitabili.
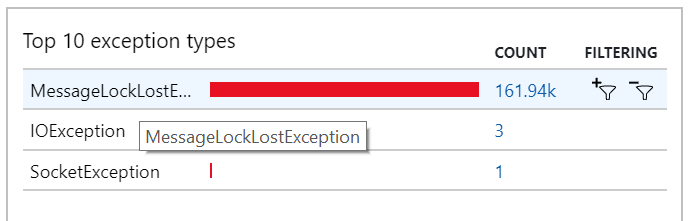
È anche possibile visualizzare questo comportamento nelle eccezioni, in cui vengono registrate numerose MessageLostLockException eccezioni:
Test 5: Aumentare la durata del blocco
Per questo test di carico, la durata del blocco del messaggio è stata impostata su 5 minuti per evitare timeout di blocco. Il grafico dei messaggi in ingresso e in uscita mostra ora che il sistema è in linea con la frequenza dei messaggi in arrivo:
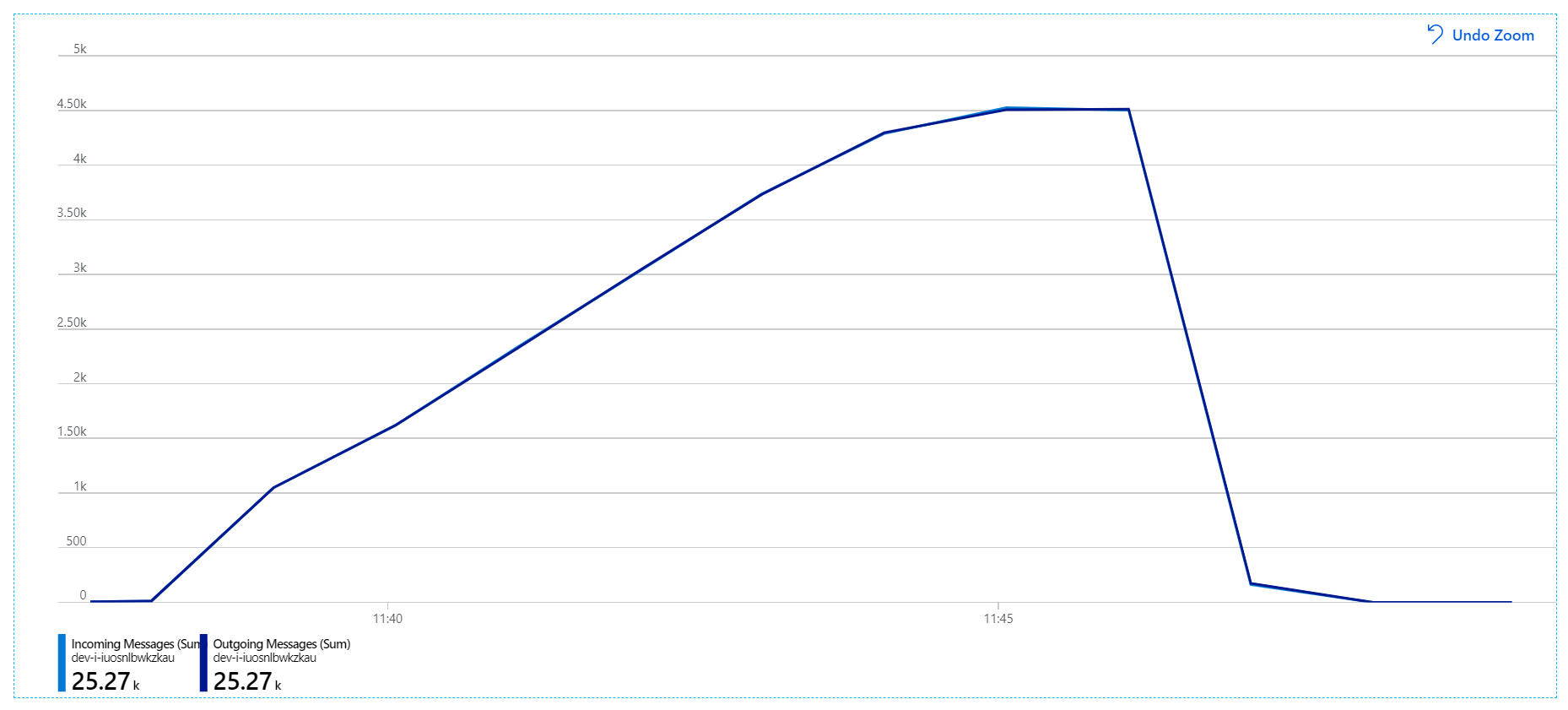
Nel corso della durata totale del test di carico di 8 minuti, l'applicazione ha completato 25 K operazioni, con una velocità effettiva massima di 72 operazioni al secondo, che rappresenta un aumento del 400% della velocità effettiva massima.
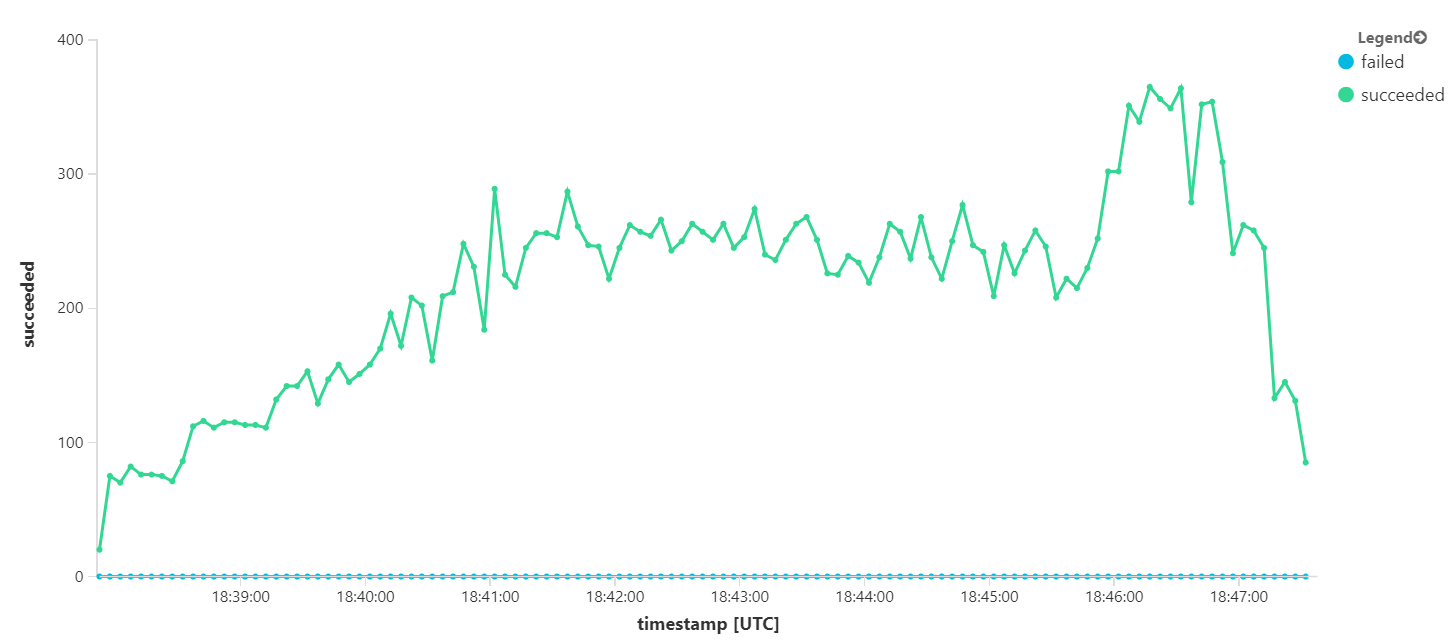
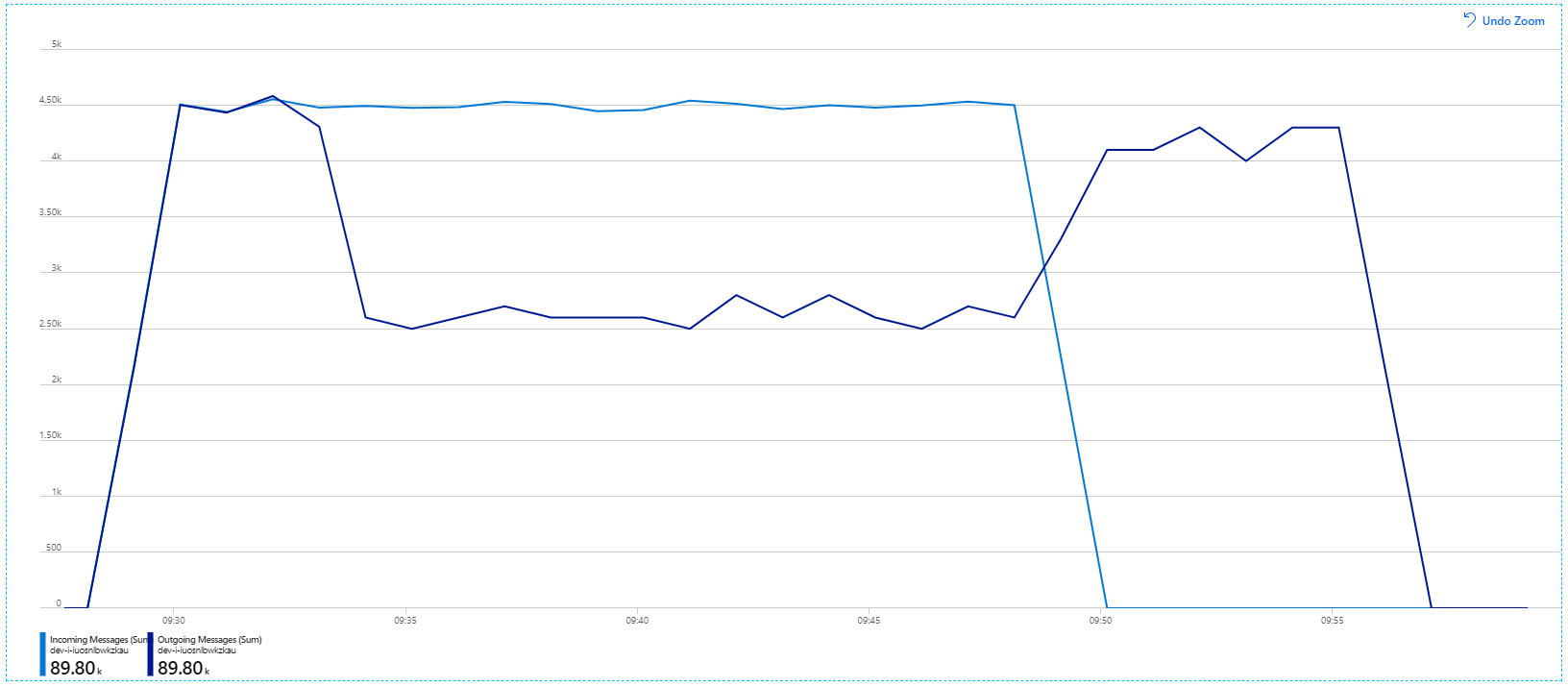
Tuttavia, l'esecuzione dello stesso test con una durata più lunga ha dimostrato che l'applicazione non è riuscita a sostenere questa velocità:
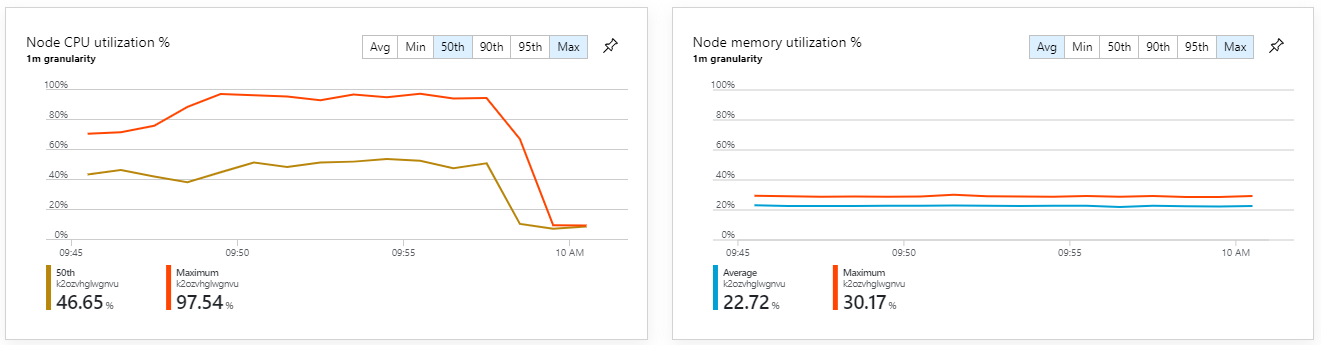
Le metriche del contenitore indicano che l'utilizzo massimo della CPU è stato vicino al 100%. A questo punto, l'applicazione sembra essere associata alla CPU. Il ridimensionamento del cluster potrebbe ora migliorare le prestazioni, a differenza del tentativo precedente di aumentare le prestazioni.
Test 6: aumentare il numero di istanze dei servizi back-end (di nuovo)
Per il test di carico finale della serie, il team ha scalato il cluster e i pod Kubernetes come indicato di seguito:
| Impostazione | Valore |
|---|---|
| Nodi del cluster | 12 |
| Servizio di inserimento | 3 repliche |
| Servizio flusso di lavoro | 6 repliche |
| Package, Delivery, Drone Scheduler services | 9 repliche ciascuna |
Questo test ha comportato una velocità effettiva sostenuta più elevata, senza ritardi significativi nell'elaborazione dei messaggi. Inoltre, l'utilizzo della CPU del nodo è rimasto inferiore all'80%.
Riepilogo
Per questo scenario sono stati identificati i colli di bottiglia seguenti:
- Eccezioni di memoria insufficiente in cache di Azure per Redis.
- Mancanza di parallelismo nell'elaborazione dei messaggi.
- Durata del blocco dei messaggi insufficiente, che comporta timeout di blocco e messaggi inseriti nella coda dei messaggi non recapitabili.
- Esaurimento della CPU.
Per diagnosticare questi problemi, il team di sviluppo si basa sulle metriche seguenti:
- Frequenza dei messaggi del bus di servizio in ingresso e in uscita.
- Mappa delle applicazioni in Application Insights.
- Errori ed eccezioni.
- Query di Log Analytics personalizzate.
- Utilizzo della CPU e della memoria in Informazioni dettagliate sui contenitori di Monitoraggio di Azure.
Passaggi successivi
Per altre informazioni sulla progettazione di questo scenario, vedere Progettazione di un'architettura di microservizi.