Creazione di report tra database cloud con scalabilità orizzontale (anteprima)
Si applica a: ![]() Database SQL di Azure
Database SQL di Azure
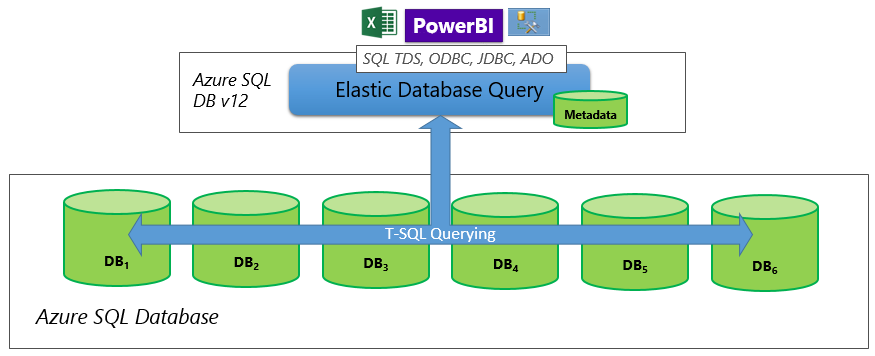
I database partizionati distribuiscono righe su un livello di dati a scalabilità orizzontale. Lo schema è identico in tutti i database partecipanti, ed è denominato anche partizionamento orizzontale. Con una query elastica è possibile creare report che si estendono a tutti i database di un database partizionato.
Per l'avvio rapido, vedere Creazione di report tra database cloud con scalabilità orizzontale.
Per i database non partizionati, vedere Eseguire query in database cloud con schemi diversi.
Prerequisiti
- Creare una mappa partizioni usando la libreria client dei database elastici. Vedere Gestione mappe partizioni. In alternativa, usare l'app di esempio in Introduzione agli strumenti del database elastico.
- In alternativa, vedere Migrate existing databases to scaled-out databases(Eseguire la migrazione di database esistenti per la scalabilità orizzontale).
- L'utente deve disporre dell'autorizzazione ALTER ANY origine dei dati esterni. Questa autorizzazione è inclusa nell'autorizzazione ALTER DATABASE.
- Per il riferimento all'origine dati sottostante sono necessarie autorizzazioni ALTER ANY EXTERNAL DATA SOURCE.
Panoramica
Queste istruzioni creano la rappresentazione dei metadati del livello dati con partizionamento orizzontale nel database elastico sottoposto a query.
- CREATE MASTER KEY
- CREATE DATABASE SCOPED CREDENTIAL
- CREATE EXTERNAL DATA SOURCE
- CREATE EXTERNAL TABLE
1.1 Creare la chiave master e le credenziali con ambito database
Le credenziali vengono usate dalla query elastica per connettersi ai database remoti.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
CREATE DATABASE SCOPED CREDENTIAL [<credential_name>] WITH IDENTITY = '<username>',
SECRET = '<password>';
Nota
Assicurarsi che il "<nome utente>" non includa alcun suffisso "@servername".
1.2 Creare origini dati esterne
Sintassi:
<External_Data_Source> ::=
CREATE EXTERNAL DATA SOURCE <data_source_name> WITH
(TYPE = SHARD_MAP_MANAGER,
LOCATION = '<fully_qualified_server_name>',
DATABASE_NAME = '<shardmap_database_name>',
CREDENTIAL = <credential_name>,
SHARD_MAP_NAME = '<shardmapname>'
) [;]
Esempio
CREATE EXTERNAL DATA SOURCE MyExtSrc
WITH
(
TYPE=SHARD_MAP_MANAGER,
LOCATION='myserver.database.windows.net',
DATABASE_NAME='ShardMapDatabase',
CREDENTIAL= SMMUser,
SHARD_MAP_NAME='ShardMap'
);
Recuperare l'elenco di origini dati esterne correnti:
select * from sys.external_data_sources;
L'origine dati esterna fa riferimento alla mappa partizioni. Una query elastica usa quindi l'origine dati esterna e la mappa partizioni sottostante per enumerare i database che partecipano al livello dati. Le stesse credenziali vengono usate per leggere la mappa partizioni e per accedere ai dati nelle partizioni durante l'elaborazione di una query elastica.
1.3 Creare tabelle esterne
Sintassi:
CREATE EXTERNAL TABLE [ database_name . [ schema_name ] . | schema_name. ] table_name
( { <column_definition> } [ ,...n ])
{ WITH ( <sharded_external_table_options> ) }
) [;]
<sharded_external_table_options> ::=
DATA_SOURCE = <External_Data_Source>,
[ SCHEMA_NAME = N'nonescaped_schema_name',]
[ OBJECT_NAME = N'nonescaped_object_name',]
DISTRIBUTION = SHARDED(<sharding_column_name>) | REPLICATED |ROUND_ROBIN
Esempio
CREATE EXTERNAL TABLE [dbo].[order_line](
[ol_o_id] int NOT NULL,
[ol_d_id] tinyint NOT NULL,
[ol_w_id] int NOT NULL,
[ol_number] tinyint NOT NULL,
[ol_i_id] int NOT NULL,
[ol_delivery_d] datetime NOT NULL,
[ol_amount] smallmoney NOT NULL,
[ol_supply_w_id] int NOT NULL,
[ol_quantity] smallint NOT NULL,
[ol_dist_info] char(24) NOT NULL
)
WITH
(
DATA_SOURCE = MyExtSrc,
SCHEMA_NAME = 'orders',
OBJECT_NAME = 'order_details',
DISTRIBUTION=SHARDED(ol_w_id)
);
Recuperare l'elenco di tabelle esterne dal database corrente:
SELECT * from sys.external_tables;
Per eliminare le tabelle esterne:
DROP EXTERNAL TABLE [ database_name . [ schema_name ] . | schema_name. ] table_name[;]
Osservazioni:
La clausola DATA_SOURCE definisce l'origine dati esterna (una mappa di partizioni) usata per la tabella esterna.
Le clausole SCHEMA_NAME e OBJECT_NAME eseguono il mapping della definizione della tabella esterna a una tabella in uno schema diverso. Se queste clausole vengono omesse, si presuppone che lo schema dell'oggetto remoto sia dbo e che il relativo nome sia identico al nome della tabella esterna in fase di definizione. Questo è utile se il nome della tabella remota è già in uso nel database in cui si vuole creare la tabella esterna. Ad esempio, si vuole definire una tabella esterna per ottenere una visualizzazione aggregata delle viste del catalogo o delle viste a gestione dinamica (DMV) nel livello dati con scalabilità orizzontale. Poiché le viste del catalogo e le DMV esistono già localmente, non sarà possibile usare i rispettivi nomi per la definizione della tabella esterna. Usare invece un nome diverso e usare il nome della vista del catalogo o della vista DMV nelle clausole SCHEMA_NAME e/o OBJECT_NAME. Vedere l'esempio seguente.
La clausola DISTRIBUTION specifica la distribuzione dei dati usata per questa tabella. Query Processor utilizza le informazioni fornite nella clausola DISTRIBUTION per generare i piani di query più efficienti.
- SHARDED significa che i dati sono partizionati orizzontalmente tra i database. La chiave di partizionamento per la distribuzione dei dati è il parametro <sharding_column_name>.
- REPLICATED indica che in ogni database sono presenti copie identiche della tabella. Sarà quindi necessario assicurarsi che le repliche siano identiche in tutti i database.
- ROUND_ROBIN indica che la tabella è partizionata orizzontalmente con un metodo di distribuzione dipendente dall'applicazione.
Riferimento al livello dati: il DDL della tabella esterna fa riferimento a un'origine dati esterna. L'origine dati esterna specifica una mappa partizioni che fornisce alla tabella esterna le informazioni necessarie per individuare tutti i database nel livello dati.
Considerazioni sulla sicurezza
Gli utenti con accesso alla tabella esterna ottengono automaticamente l'accesso alle tabelle remote sottostanti con le credenziali specificate nella definizione dell'origine dati esterna. Evitare l'elevazione dei privilegi indesiderata mediante le credenziali dell'origine dati esterna. Usare GRANT o REVOKE per la tabella esterna, come se fosse una tabella comune.
Dopo aver definito l'origine dati esterna e le tabelle esterne, è ora possibile usare la sintassi T-SQL completa sulle tabelle esterne.
Esempio: esecuzione di query su database partizionati orizzontalmente
La query seguente esegue un join a tre vie tra magazzini, ordini e righe di ordine e usa diverse funzioni di aggregazione e un filtro selettivo. Presuppone che (1) venga usato il partizionamento orizzontale, che (2) i magazzini, gli ordini e le righe di ordine siano partizionati orizzontalmente in base alla colonna identificativa di magazzino e che la query elastica possa condividere i join sulle partizioni ed elaborare la parte più onerosa della query sulle partizioni in parallelo.
select
w_id as warehouse,
o_c_id as customer,
count(*) as cnt_orderline,
max(ol_quantity) as max_quantity,
avg(ol_amount) as avg_amount,
min(ol_delivery_d) as min_deliv_date
from warehouse
join orders
on w_id = o_w_id
join order_line
on o_id = ol_o_id and o_w_id = ol_w_id
where w_id > 100 and w_id < 200
group by w_id, o_c_id
Stored procedure per l'esecuzione remota di T-SQL: sp_execute_remote
La query elastica introduce anche una stored procedure che fornisce l'accesso diretto alle partizioni. La stored procedure è denominata sp_execute _remote e può essere usata per eseguire stored procedure remote o un codice T-SQL sui database remoti. È necessario specificare i seguenti parametri:
- Nome dell'origine dati (nvarchar): il nome dell'origine dati esterna di tipo RDBMS.
- Query (nvarchar): la query T-SQL da eseguire in ogni partizione.
- Dichiarazione del parametro (nvarchar) - Facoltativo: stringa con definizioni del tipo di dati per i parametri usati nel parametro della query, ad esempio sp_executesql.
- Elenco di valori dei parametri (facoltativo): elenco delimitato da virgole di valori dei parametri, ad esempio sp_executesql.
La stored procedure sp_execute_remote usa l'origine dati esterna specificata nei parametri di chiamata per eseguire l'istruzione T-SQL inclusa nei database remoti. Usa le credenziali dell'origine dati esterna per connettersi al database di gestione shardmap e ai database remoti.
Esempio:
EXEC sp_execute_remote
N'MyExtSrc',
N'select count(w_id) as foo from warehouse'
Connettività per gli strumenti
Usare le normali stringhe di connessione di SQL Server per connettere l'applicazione, gli strumenti di Business Intelligence e di integrazione dei dati al database con le definizioni delle tabelle esterne. Assicurarsi che SQL Server sia supportato come origine dati per lo strumento. Fare quindi riferimento al database elastico sottoposto a query in modo analogo a qualsiasi altro database di SQL Server connesso allo strumento e usare le tabelle esterne dallo strumento o dall'applicazione come se fossero tabelle locali.
Procedure consigliate
- Assicurarsi che il database di endpoint della query elastica abbia l'accesso al database di mappe partizioni e a tutte le partizioni attraverso i firewall del database SQL.
- Convalidare o imporre la distribuzione di dati definita dalla tabella esterna. Se la distribuzione di dati effettivo è diversa dalla distribuzione specificata nella definizione di tabella, le query possono restituire risultati imprevisti.
- La query elastica non esegue attualmente l'eliminazione di partizioni quando i predicati sulla chiave di partizionamento consentono l'esclusione sicura di alcune partizioni dall'elaborazione.
- La query elastica funziona in modo ottimale per le query in cui la maggior parte dei calcoli può essere eseguita sulle partizioni. In genere si ottiene le migliori prestazioni di query con predicati del filtro selettivo che può essere valutata in join le partizioni tramite le chiavi di partizionamento che possono essere eseguite in modo su tutte le partizioni allineate alle partizioni. Altri modelli di query potrebbero richiedere il caricamento di quantità elevate di dati dalle partizioni al nodo head e potrebbero offrire prestazioni ridotte.
Passaggi successivi
- Per un approfondimento, vedere Panoramica delle query elastiche.
- Per un'esercitazione sul partizionamento verticale, vedere Introduzione alle query tra database (partizionamento verticale).
- Per le query di esempio e sintassi per i dati con partizionamento verticale, vedere Eseguire query su dati con partizionamento verticale
- Per un'esercitazione sul partizionamento orizzontale, vedere la guida introduttiva alle query elastiche per il partizionamento orizzontale.
- Vedere sp_execute _remote per una stored procedure che esegue un'istruzione Transact-SQL su un singolo database SQL di Azure remoto o un set di database che fungono da partizioni in uno schema di partizionamento orizzontale.