Spostamento di dati tra database cloud con scalabilità orizzontale
Si applica a: ![]() Database SQL di Azure
Database SQL di Azure
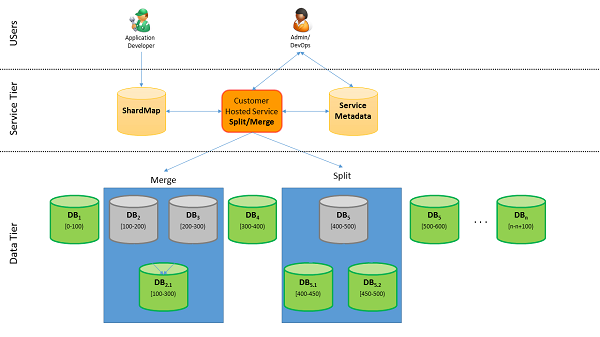
Se lo sviluppatore di un'app SaaS (Software as a Service) registra un incremento importante della richiesta dell'app, dovrà far fronte alla domanda. A tale scopo aggiungerà altri database (partizioni). Come ridistribuire i dati nei nuovi database senza comprometterne l'integrità? Per spostare dati dai database vincolati ai nuovi database, usare lo strumento di suddivisione-unione .
Lo strumento di suddivisione-unione viene eseguito come servizio Web di Azure. Un amministratore o uno sviluppatore usa lo strumento per spostare shardlet (dati di una partizione) tra diversi database (partizioni). Lo strumento usa la gestione delle mappe partizioni per gestire il database di metadati del servizio e per garantire mapping coerenti.
Scarica
Microsoft.Azure.SqlDatabase.ElasticScale.Service.SplitMerge
Documentazione
- Esercitazione relativa allo strumento divisione-unione del database elastico
- Configurazione della sicurezza del servizio di divisione e unione
- Considerazioni sulla sicurezza dello strumento di suddivisione-unione
- Gestione mappe partizioni
- Migrate existing databases to scale-out (Eseguire la migrazione di database esistenti per la scalabilità orizzontale)
- Strumenti di database elastici
- Glossario sugli strumenti di database elastici
Perché usare lo strumento di suddivisione-unione
Flessibilità
Le applicazioni devono essere sufficientemente flessibili per superare i limiti di un singolo database in database SQL di Azure. Lo strumento consente di spostare i dati nei nuovi database senza compromettere l'integrità.
Dividere per crescere
Per aumentare la capacità complessiva in modo da gestire una crescita straordinaria, creare capacità aggiuntiva tramite il partizionamento orizzontale e la distribuzione dei dati in un numero sempre crescente di database, fino a soddisfare le esigenze di capacità. Questo è un ottimo esempio della funzionalità di suddivisione.
Unire per ridurre
In certi casi è necessario ridurre la capacità, per la natura stagionale dell'attività commerciale. Lo strumento consente di passare a un numero inferiore di unità di scala quando l'attività rallenta. La funzionalità di unione del servizio di suddivisione-unione della scalabilità elastica permette di soddisfare questo requisito.
Gestire gli hotspot mediante lo spostamento di shardlet
A causa della presenza di più tenant per ogni database, l'allocazione di shardlet alle partizioni può provocare colli di bottiglia di capacità in alcune partizioni. Sarà quindi necessario riallocare gli shardlet o spostare gli shardlet occupati in partizioni nuove o meno usate.
Concetti e funzionalità principali
Servizi ospitati dal cliente
Il servizio di suddivisione-unione viene offerto come servizio ospitato dal cliente. È necessario distribuire e ospitare il servizio nella sottoscrizione di Microsoft Azure. Il pacchetto scaricato da NuGet include un modello di configurazione da completare con le informazioni specifiche per la distribuzione. Per informazioni dettagliate, vedere l' esercitazione relativa alla suddivisione-unione . Poiché il servizio è in esecuzione nella sottoscrizione Azure, sarà possibile controllare e configurare la maggior parte degli aspetti relativi alla sicurezza del servizio. Il modello predefinito include le opzioni necessarie per configurare TLS, l'autenticazione client basata su certificato, la crittografia per le credenziali archiviate, la protezione DoS e le restrizioni IP. Altre informazioni sugli aspetti relativi alla sicurezza sono disponibili nel documento seguente relativo alla configurazione di sicurezza della suddivisione-unione.
Il servizio distribuito predefinito viene eseguito con un ruolo di lavoro e un ruolo Web. Ogni ruolo usa la dimensione di VM A1 in Servizi cloud di Azure. Benché non sia possibile modificare queste impostazioni durante la distribuzione del pacchetto, è possibile modificarle dopo una distribuzione corretta nel servizio cloud in esecuzione, tramite il portale di Azure. Si noti che per motivi tecnici il ruolo di lavoro deve essere configurato solo per un'istanza.
Integrazione della mappa partizioni
Il servizio di suddivisione-unione interagisce con la mappa partizioni dell'applicazione. Quando si usa il servizio di suddivisione-unione per suddividere o unire intervalli o per spostare shardlet tra le diverse partizioni, il servizio mantiene automaticamente aggiornata la mappa partizioni. Per ottenere questo risultato, il servizio si connette al database di gestione delle mappe partizioni dell'applicazione e gestisce gli intervalli e i mapping durante lo svolgimento delle richieste di suddivisione/unione/spostamento. Ciò garantisce che la mappa partizioni presenti sempre una visualizzazione aggiornata durante l'esecuzione delle operazioni di suddivisione-unione. Le operazioni di suddivisione, unione e spostamento di shardlet vengono implementate tramite lo spostamento di un batch di shardlet dalla partizione di origine alla partizione di destinazione. Durante l'operazione di spostamento di shardlet, gli shardlet inclusi nel batch corrente vengono contrassegnati come offline nella mappa partizioni e non sono disponibili per connessioni di routing dipendenti dai dati tramite l'API OpenConnectionForKey .
Connessioni a shardlet coerenti
All'avvio dello spostamento di dati per un nuovo batch di shardlet, eventuali connessioni di routing dipendenti dai dati e fornite dalla mappa partizioni alla partizione in cui sono archiviati gli shardlet verranno terminate e le connessioni successive dalle API della mappa partizioni a questi shardlet verranno bloccate durante lo spostamento dei dati, in modo da evitare incoerenze. Verranno terminate anche le connessioni ad altri shardlet nella stessa partizione, ma queste connessioni avranno esito positivo immediato al tentativo successivo. Al termine dello spostamento del batch, gli shardlet verranno contrassegnati di nuovo come online per la partizione di destinazione e i dati di origine verranno rimossi dalla partizione di origine. Il servizio esegue questi passaggi per ogni batch, fino al completamento dello spostamento di tutti gli shardlet. Si verificheranno quindi alcune operazioni di interruzione delle connessioni durante il completamento dell'operazione di suddivisione/unione/spostamento.
Gestione della disponibilità di shardlet
la limitazione dell'interruzione delle connessioni al batch attuale di shardlet, come illustrato in precedenza, limita anche l'ambito di non disponibilità a un unico batch di shardlet alla volta. Questo approccio è preferibile a un approccio in cui la partizione completa rimane offline per tutti gli shardlet corrispondenti durante l'esecuzione di un'operazione di suddivisione o unione. La dimensione di un batch, definita come il numero di shardlet distinti da muovere in un determinato momento, è un parametro di configurazione. Può essere definita per ogni operazione di suddivisione o unione, in base alle esigenze di disponibilità e prestazioni dell'applicazione. Si noti che l'intervallo bloccato nella mappa partizioni potrebbe avere dimensioni superiori rispetto a quelle del batch specificato. Ciò è dovuto al fatto che il servizio definisce una dimensione di intervallo in modo che il numero effettivo di valori di chiave di partizionamento orizzontale nei dati corrisponda in modo approssimativo alla dimensione del batch. È importante ricordare questo aspetto, in particolare per le chiavi di partizionamento orizzontale popolate in modo sparse.
Archiviazione dei metadati
Il servizio di suddivisione-unione usa un database per gestire il proprio stato e per creare log durante l'elaborazione delle richieste. L'utente crea questo database nella propria sottoscrizione e fornisce la stringa di connessione corrispondente nel file di configurazione per la distribuzione del servizio. Gli amministratori dell'organizzazione dell'utente possono anche connettersi a questo database per esaminare lo stato della richiesta e per analizzare le informazioni dettagliate su potenziali errori.
Rilevamento del partizionamento orizzontale
Il servizio di suddivisione-unione riconosce le differenze tra (1) tabelle partizionate, (2) tabelle di riferimento e (3) tabelle normali. La semantica di un'operazione di suddivisione/unione/spostamento dipende dal tipo di tabella usata e viene definita nel seguente modo:
Tabelle partizionate
Le operazioni di suddivisione, unione e spostamento consentono di spostare gli shardlet dalla partizione di origine a quella di destinazione. Dopo il completamento corretto della richiesta complessiva, questi shardlet non saranno più presenti nell'origine. Si noti che le tabelle di destinazione devono esistere nella partizione di destinazione e non devono includere dati nell'intervallo di destinazione prima dell'elaborazione dell'operazione.
Tabelle di riferimento
Per le tabelle di riferimento, le operazioni di suddivisione, unione e spostamento copiano i dati dalla partizione di origine a quella di destinazione. Si noti tuttavia che nella partizione di destinazione per una determinata tabella non vengono applicate modifiche se questa tabella nella partizione di destinazione include già alcune righe. Per permettere l'elaborazione dell'operazione di copia di tabelle di riferimento, è necessario che la tabella sia vuota.
Altre tabelle
Nell'origine o nella destinazione di un'operazione di suddivisione e unione possono essere presenti altre tabelle. Il servizio di suddivisione-unione ignora tali tabelle per eventuali operazioni di spostamento o copia dei dati. Si noti, tuttavia, che in caso di vincoli queste tabelle possono interferire con le operazioni.
Le informazioni relative al confronto tra tabelle di riferimento e tabelle partizionate vengono fornite dalle API
SchemaInfonella mappa partizioni. Il seguente esempio illustra l'uso di queste API in un determinato oggetto del gestore delle mappe partizioni:// Create the schema annotations SchemaInfo schemaInfo = new SchemaInfo(); // reference tables schemaInfo.Add(new ReferenceTableInfo("dbo", "region")); schemaInfo.Add(new ReferenceTableInfo("dbo", "nation")); // sharded tables schemaInfo.Add(new ShardedTableInfo("dbo", "customer", "C_CUSTKEY")); schemaInfo.Add(new ShardedTableInfo("dbo", "orders", "O_CUSTKEY")); // publish smm.GetSchemaInfoCollection().Add(Configuration.ShardMapName, schemaInfo);Le tabelle
regionenationsono definite come tabelle di riferimento e vengono copiate con operazioni di suddivisione/unione/spostamento. Le tabellecustomereordersa loro volta sono definite come tabelle partizionate.C_CUSTKEYeO_CUSTKEYfungono da chiave di partizionamento.
Integrità referenziale
Il servizio di suddivisione-unione analizza le dipendenze tra le tabelle e usa relazioni chiave esterna-chiave primaria per la gestione temporanea delle operazioni di spostamento delle tabelle di riferimento e degli shardlet. Le tabelle di riferimento vengono in genere copiate per prime in ordine di dipendenza, quindi vengono copiati gli shardlet, in base al rispettivo ordine di dipendenza in ogni batch. Ciò è necessario per permettere il rispetto dei vincoli di chiave esterna-chiave primaria nella partizione di destinazione all'arrivo di nuovi dati.
Coerenza della mappa partizioni e completamento finale
In caso di errori, il servizio di suddivisione-unione si riattiva dopo eventuali interruzioni e cerca di completare eventuali richieste in corso. È tuttavia possibile che si verifichino situazioni irreversibili, ad esempio nel caso in cui la partizione di destinazione vada persa o sia danneggiata in modo irreparabile. In queste circostanze è possibile che alcuni shardlet che dovevano essere spostati si trovino ancora nella partizione di origine. Il servizio assicura che i mapping di shardlet vengano aggiornati solo dopo il completamento corretto della copia dei dati necessari nella destinazione. Gli shardlet vengono eliminati dall'origine solo dopo la copia di tutti i rispettivi dati nella destinazione e dopo l'aggiornamento corretto dei mapping corrispondenti. L'operazione di eliminazione si verifica in background, mentre l'intervallo risulta già online nella partizione di destinazione. Il servizio di suddivisione-unione assicura sempre la correttezza dei mapping archiviati nella mappa partizioni.
Interfaccia utente del servizio di suddivisione-unione
Il pacchetto del servizio di suddivisione-unione include un ruolo di lavoro e un ruolo Web. Il ruolo Web viene usato per inviare richieste di suddivisione-unione in modo interattivo. I componenti principali dell'interfaccia utente sono i seguenti:
Tipo di operazione
Il tipo di operazione è un pulsante di opzione che controlla il tipo di operazione eseguita dal servizio per questa richiesta. È possibile scegliere tra scenari di suddivisione, unione e spostamento. È anche possibile annullare un'operazione inviata in precedenza. È possibile usare richieste di suddivisione, unione e spostamento per le mappe partizioni di tipo intervallo. Le mappe partizioni di tipo elenco supportano solo operazioni di spostamento.
Mappa partizioni
La sezione successiva dei parametri della richiesta include informazioni sulla mappa partizioni e sul database che la ospita. È in particolare necessario specificare il nome del server e del database che ospita la mappa partizioni, le credenziali per la connessione al database di mappe partizioni e infine il nome della mappa partizioni. L'operazione accetta attualmente solo un singolo set di credenziali. È necessario che le credenziali abbiano autorizzazioni sufficienti per apportare le modifiche alla mappa partizioni oltre che i dati utente nelle partizioni.
Intervallo di origine (suddivisione e unione)
Un'operazione di suddivisione e unione elabora un intervallo usando le relative chiavi superiore e inferiore. Per specificare un'operazione con un valore di chiave superiore non associato, selezionare la casella di controllo "Chiave superiore massima" e lasciare vuoto il campo della chiave superiore. Non è necessario che i valori dell'intervallo di chiavi specificati corrispondano esattamente a un mapping e ai relativi limiti nella mappa partizioni. Se non si specifica alcun limite dell'intervallo, il servizio dedurrà automaticamente l'intervallo più vicino. Per recuperare i mapping attuali in una determinata mappa partizioni, è possibile usare lo script GetMappings.ps1 di PowerShell.
Comportamento origine di suddivisione (suddivisione)
Per le operazioni di suddivisione, definire il punto in cui si vuole dividere l'intervallo di origine. Per ottenere questo risultato, si specifica la chiave di partizionamento orizzontale nel punto in cui si deve verificare la suddivisione. Usare il pulsante di opzione per indicare se si vuole spostare la parte inferiore dell'intervallo (escludendo la chiave di suddivisione) o la parte superiore (inclusa la chiave di suddivisione).
Shardlet di origine (spostamento)
Molte operazioni si differenziano dalle operazioni di suddivisione o unione poiché non richiedono un intervallo per la descrizione dell'origine. Un'origine per lo spostamento viene identificata semplicemente dal valore della chiave di partizionamento orizzontale che si prevede di spostare.
Partizione di destinazione (suddivisione)
Dopo avere specificato le informazioni sull'origine dell'operazione di suddivisione, è necessario indicare la destinazione della copia dei dati specificando il nome del server e del database per la destinazione.
Intervallo di destinazione (unione)
Le operazioni di unione spostano gli shardlet in una partizione esistente. Per identificare la partizione esistente, è necessario specificare i limiti dell'intervallo esistente con cui si vuole ottenere l'unione.
Dimensioni batch
Le dimensioni del batch controllano il numero di shardlet che saranno offline contemporaneamente durante lo spostamento dei dati. Si tratta di un valore Integer. È possibile usare valori ridotti se si preferisce evitare periodi di inattività prolungati per gli shardlet. I valori più elevati comporteranno un incremento del tempo per cui un determinato shardlet risulterà offline, ma potrebbero migliorare le prestazioni.
ID operazione (annullamento)
Se è in corso un'operazione che non è più necessaria, è possibile annullarla specificando l'ID operazione corrispondente in questo campo. L'ID operazione può essere recuperato dalla tabella di stato dell'operazione (vedere la Sezione 8.1) o dall'output nel Web browser in cui è stata inviata la richiesta.
Requisiti e limitazioni
L'implementazione corrente del servizio di suddivisione-unione deve rispettare i seguenti requisiti e limitazioni:
- Le partizioni devono esistere ed essere registrate nella mappa partizioni perché sia possibile eseguire un'operazione di suddivisione-unione in tali partizioni.
- Il servizio attualmente non crea in modo automatico tabelle o altri oggetti di database. È quindi necessario che lo schema per tutte le tabelle partizionate e le tabelle di riferimento esista nella partizione di destinazione prima dell'esecuzione di qualsiasi operazione di suddivisione/unione/spostamento. È in particolare necessario che le tabelle partizionate siano vuote nell'intervallo in cui l'operazione di suddivisione/unione/spostamento deve aggiungere shardlet. In caso contrario, l'operazione non riuscirà a eseguire la verifica di coerenza nella partizione di destinazione. Si noti anche che i dati di riferimento vengono copiati solo se la tabella di riferimento è vuota e che non sono previste garanzie a livello di coerenza rispetto ad altre operazioni di scrittura concorrenti nelle tabelle di riferimento. Si consiglia questo: durante l'esecuzione di operazioni di suddivisione/unione, altre operazioni di scrittura non devono apportare modifiche alle tabelle di riferimento.
- Per migliorare le prestazioni e l'affidabilità per shardlet di grandi dimensioni, il servizio si basa attualmente sull'identità di riga definita da un indice o una chiave univoca che include la chiave di partizionamento orizzontale. Ciò permette al servizio di spostare i dati con un livello di granularità maggiore rispetto al solo valore di chiave di partizionamento orizzontale, contribuendo quindi a ridurre la quantità massima di spazio di log e i blocchi necessari durante l'operazione. È consigliabile creare un indice univoco o una chiave primaria che include la chiave di partizionamento orizzontale in una determinata tabella se si vuole usare quella tabella con le richieste di suddivisione/unione/spostamento. Per motivi di prestazioni, è consigliabile che la chiave di partizionamento orizzontale costituisca la colonna iniziale nella chiave o nell'indice.
- Durante l'elaborazione delle richieste è possibile che alcuni dati di shardlet siano presenti sia nella partizione di origine che nella partizione di destinazione. Ciò è attualmente necessario per la protezione in caso di errori durante lo spostamento di shardlet. L'integrazione del servizio di suddivisione-unione con la mappa partizioni garantisce che le connessioni tramite le API di routing dipendenti dai dati che usano il metodo OpenConnectionForKey sulla mappa partizioni non rilevino stati intermedi incoerenti. Quando ci si connette alle partizioni di origine o di destinazione senza usare il metodo OpenConnectionForKey , è tuttavia possibile che stati intermedi incoerenti risultino visibili durante l'esecuzione di richieste di suddivisione/unione/spostamento. È possibile che queste connessioni mostrino risultati parziali o duplicati, in base all'intervallo o alla partizione sottostante per la connessione. Questa limitazione include attualmente le connessioni effettuate dalle query su più partizioni di Scalabilità elastica.
- Il database dei metadati per il servizio di suddivisione-unione non deve essere condiviso tra ruoli diversi. Ad esempio, un ruolo del servizio di suddivisione-unione in esecuzione in gestione temporanea deve fare riferimento a un database dei metadati diverso rispetto al ruolo di produzione.
Fatturazione
Il servizio di suddivisione-unione viene eseguito come servizio cloud nella sottoscrizione Microsoft Azure. Pertanto all'istanza del servizio vengono applicate tariffe per i servizi cloud. Se non si eseguono spesso operazioni di suddivisione/unione/spostamento, è consigliabile eliminare il servizio cloud di suddivisione-unione, in modo da ridurre i costi per le istanze dei servizi cloud in esecuzione o distribuite. È possibile eseguire di nuovo la distribuzione e avviare la configurazione pronta per l'esecuzione quando occorre eseguire operazioni di suddivisione-unione.
Monitoraggio
Tabelle di stato
Il servizio di suddivisione-unione fornisce la tabella RequestStatus nel database archivio di metadati per il monitoraggio delle richieste completate e in corso. La tabella include una riga per ogni richiesta di suddivisione-unione inviata a questa istanza del servizio di suddivisione-unione. Fornisce le seguenti informazioni per ogni richiesta:
Timestamp:
Ora e data di inizio della richiesta.
OperationId
GUID che identifica in modo univoco la richiesta. Questa richiesta può essere usata anche per annullare l'operazione durante l'esecuzione.
Stato
Stato attuale della richiesta. per le richieste in corso indica anche la fase attuale dell'esecuzione della richiesta.
CancelRequest
Flag che indica se la richiesta è stata annullata.
Progress
Stima della percentuale di completamento dell'operazione. Un valore pari a 50 indica che la percentuale di completamento dell'operazione è pari a circa il 50%.
Dettagli
Valore XML che fornisce un report di stato più dettagliato. Il report di stato viene aggiornato periodicamente durante la copia di set di righe dall'origine alla destinazione. In caso di errori o eccezioni, questa colonna include anche informazioni più dettagliate sull'errore.
Diagnostica di Azure
Il servizio di suddivisione-unione utilizza la diagnostica Azure basata su Azure SDK 2.5 per il monitoraggio e la diagnostica. È possibile controllare la configurazione della diagnostica come indicato di seguito: Abilitazione della diagnostica nei servizi cloud e nelle macchine virtuali di Azure. Il pacchetto di download include due configurazioni della diagnostica: una per il ruolo Web e una per il ruolo di lavoro. Essi includono le definizioni per la registrazione di contatori delle prestazioni, log IIS, registri eventi di Windows e registri eventi dell'applicazione di suddivisione-unione.
Distribuire la diagnostica
Nota
Questo articolo usa il modulo di PowerShell Azure Az consigliato per l'interazione con Azure. Per iniziare a usare il modulo Az PowerShell, vedere Installare Azure PowerShell. Per informazioni su come eseguire la migrazione al modulo Az PowerShell, vedere Eseguire la migrazione di Azure PowerShell da AzureRM ad Az.
Importante
Il modulo Azure Resource Manager di PowerShell è ancora supportato, ma tutte le future attività di sviluppo sono incentrate sul modulo Az.Sql. Per informazioni su questi cmdlet, vedere AzureRM.Sql. Gli argomenti per i comandi nei moduli Az e AzureRm sono sostanzialmente identici.
Per abilitare il monitoraggio e la diagnostica utilizzando la configurazione della diagnostica per i ruoli Web e di lavoro forniti dal pacchetto NuGet, eseguire i seguenti comandi utilizzando Azure PowerShell:
$storageName = "<azureStorageAccount>"
$key = "<azureStorageAccountKey"
$storageContext = New-AzStorageContext -StorageAccountName $storageName -StorageAccountKey $key
$configPath = "<filePath>\SplitMergeWebContent.diagnostics.xml"
$serviceName = "<cloudServiceName>"
Set-AzureServiceDiagnosticsExtension -StorageContext $storageContext `
-DiagnosticsConfigurationPath $configPath -ServiceName $serviceName `
-Slot Production -Role "SplitMergeWeb"
Set-AzureServiceDiagnosticsExtension -StorageContext $storageContext `
-DiagnosticsConfigurationPath $configPath -ServiceName $serviceName `
-Slot Production -Role "SplitMergeWorker"
Altre informazioni su come configurare e distribuire le impostazioni di diagnostica sono disponibili qui: Abilitazione della diagnostica nei servizi cloud e nelle macchine virtuali di Azure.
Recuperare la diagnostica
È possibile accedere con facilità alla diagnostica da Esplora server di Visual Studio, nella sezione dedicata ad Azure della struttura ad albero della finestra di esplorazione. Aprire un'istanza di Visual Studio e nella barra dei menu fare clic su Visualizza, quindi su Esplora server. Fare clic sull'icona di Azure per connettersi alla sottoscrizione Azure. Passare quindi ad Azure -> Archiviazione -><your storage account> -> Tabelle -> WADLogsTable. Per altre informazioni, vedere Esplora server.
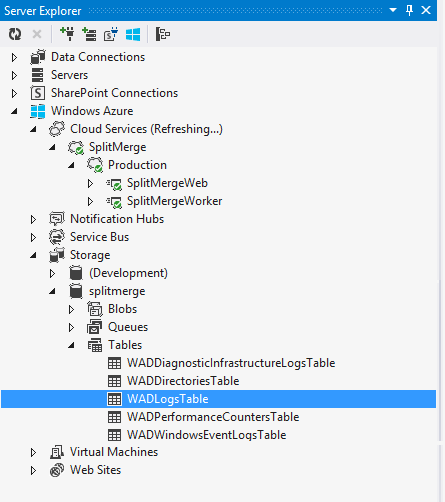
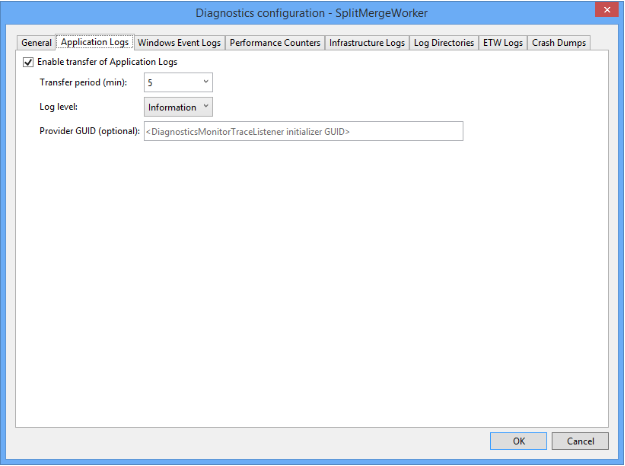
La tabella WADLogsTable evidenziata nella figura precedente include gli eventi dettagliati del log applicazione del servizio di suddivisione-unione. Si noti che la configurazione predefinita del pacchetto scaricato è destinata a una distribuzione in produzione. L'intervallo di estrazione dei log e dei contatori dalle istanze del servizio è quindi lungo (5 minuti). Per gli scenari di test e di sviluppo, ridurre l'intervallo, modificando le impostazioni di diagnostica del ruolo Web o del ruolo di lavoro in base alle esigenze specifiche. Fare clic con il pulsante destro del mouse sul ruolo in Esplora server di Visual Studio (vedere sopra), quindi modificare il periodo di trasferimento nella finestra di dialogo relativa alle impostazioni di configurazione di diagnostica:
Prestazioni
In generale i livelli di servizio più elevati ed efficienti del offrono prestazioni migliori. Allocazioni di IO, CPU e memoria più elevate per i livelli di servizio superiori risulteranno utili per le operazioni di copia ed eliminazione in blocco usate internamente dal servizio di suddivisione-unione. Per questo motivo, aumentare il livello di servizio solo per tali database per un periodo di tempo limitato e definito.
Il servizio esegue anche query di convalida come parte del normale funzionamento. Le query di convalida verificano la presenza imprevista di dati nell'intervallo di destinazione e assicurano che eventuali operazioni di suddivisione/unione/spostamento vengano avviate con uno stato coerente. Queste query verranno eseguite in intervalli di chiavi di partizionamento orizzontale definiti dall'ambito dell'operazione e dalla dimensione del batch specificata come parte della definizione della richiesta. Le query vengono eseguite in modo ottimale quando è presente un indice che include la chiave di partizionamento orizzontale come colonna iniziale.
Una proprietà di univocità con la chiave di partizionamento orizzontale come colonna iniziale permetterà inoltre al servizio di usare un approccio ottimizzato, che limita l'utilizzo di risorse a livello di spazio di log e di memoria. Questa proprietà di univocità è obbligatoria per lo spostamento di quantità elevate di dati, in genere superiori a 1 GB.
Come eseguire l'aggiornamento
- Seguire i passaggi in Distribuire un servizio di suddivisione-unione.
- Modificare il file di configurazione del servizio cloud per la distribuzione della suddivisione-unione, in modo da riflettere i nuovi parametri di configurazione. È richiesto un nuovo parametro con le informazioni relative al certificato usato per la crittografia. Per semplificare questa operazione, è possibile confrontare il file del nuovo modello di configurazione dal download con la configurazione esistente. Assicurarsi di aggiungere le impostazioni per
DataEncryptionPrimaryCertificateThumbprinteDataEncryptionPrimarysia per il Web che per il ruolo di lavoro. - Prima di distribuire l'aggiornamento in Azure, assicurarsi che tutte le operazioni di suddivisione-unione in esecuzione siano state completate. A tale scopo, è possibile eseguire una query nelle tabelle RequestStatus e PendingWorkflows nel database dei metadati di suddivisione-unione per le richieste in corso.
- Aggiornare la distribuzione del servizio cloud esistente per il servizio di suddivisione-unione nella sottoscrizione di Azure con il nuovo pacchetto e con il file di configurazione del servizio aggiornato.
Non è necessario eseguire il provisioning di un nuovo database dei metadati per l’aggiornamento della suddivisione-unione. Il database dei metadati esistente verrà aggiornato automaticamente alla nuova versione.
Procedure consigliate e risoluzione dei problemi
- Definire un tenant di test e di provare a eseguire le operazioni di suddivisione/unione/spostamento più importanti con il tenant di test in diverse partizioni. Assicurare che tutti metadati siano definiti correttamente nella mappa partizioni e che le operazioni non violino i vincoli o le chiavi esterne.
- Assicurarsi che le dimensioni dei dati del tenant di test siano superiori alle dimensioni di dati massime del tenant più grande, in modo che non si verifichino problemi correlati alle dimensioni dei dati. In questo modo sarà possibile definire un limite massimo per il tempo necessario per lo spostamento di un singolo tenant.
- Assicurarsi che lo schema consenta le eliminazioni. Per il servizio di suddivisione-unione è necessario potere rimuovere dati dalla partizione di origine dopo una copia riuscita dei dati nella destinazione. I trigger di eliminazione , ad esempio, possono impedire al servizio di eliminare i dati nell'origine e possono ostacolare la riuscita delle operazioni.
- La chiave di partizionamento orizzontale deve essere la colonna iniziale nella definizione della chiave primaria o dell'indice univoco. In questo modo si assicurano prestazioni ottimali per le query di convalida della suddivisione o unione e per le operazioni effettive di spostamento ed eliminazione dei dati, che vengono eseguite sempre negli intervalli delle chiavi di partizionamento orizzontale.
- Collocare il servizio di suddivisione-unione nel centro dati e nell’area in cui si trovano i database.
Contenuto correlato
Se non si usano gli strumenti di database elastici, vedere la Guida introduttiva. In caso di domande, usare la pagina Microsoft Q&A per il database SQL, mentre è possibile inserire le richieste di nuove funzionalità, aggiungere nuove idee o votare quelle esistenti nel forum relativo al feedback sul database SQL.