Gestire budget, costi e quota per Azure Machine Learning su scala aziendale
Quando si gestiscono i costi di calcolo sostenuti da Azure Machine Learning, a livello di organizzazione con molti carichi di lavoro, molti team e utenti, è necessario affrontare numerose problematiche di gestione e ottimizzazione.
Questo articolo illustra le procedure consigliate per ottimizzare i costi, gestire i budget e condividere le quote con Azure Machine Learning. Riflette l'esperienza e le lezioni apprese dall'esecuzione di team di Machine Learning internamente in Microsoft e durante la collaborazione con i clienti. Si apprenderà come:
- Ottimizzare le risorse di calcolo per soddisfare i requisiti del carico di lavoro.
- Determinare l'uso migliore del budget di un team.
- Pianificare, gestire e condividere budget, costi e quote su scala aziendale.
Ottimizzare l'ambiente di calcolo per soddisfare i requisiti del carico di lavoro
Quando si avvia un nuovo progetto di Machine Learning, potrebbe essere necessario un lavoro esplorativo per ottenere un quadro completo dei requisiti di calcolo. Questa sezione fornisce indicazioni su come determinare la scelta appropriata dello SKU della macchina virtuale (VM) per il training, per l'inferenza o come workstation da cui lavorare.
Determinare le dimensioni di calcolo per il training
I requisiti hardware per il carico di lavoro di training possono variare da un progetto all'altro. Per soddisfare questi requisiti, l'ambiente di calcolo di Azure Machine Learning offre vari tipi di macchine virtuali:
- Utilizzo generico: rapporto equilibrato tra CPU e memoria.
- Ottimizzata per la memoria: rapporto elevato tra memoria e CPU.
- Con ottimizzazione per il calcolo: rapporto elevato tra CPU e memoria.
- High Performance Computing: offre prestazioni, scalabilità ed efficienza in termini di costi di prima classe per un'ampia gamma di carichi di lavoro HPC reali.
- Istanze con GPU: macchine virtuali specializzate ottimizzate per livelli intensivi di rendering della grafica e modifica di video, nonché per il training e l'inferenza dei modelli (ND) con Deep Learning.
È possibile che non si sappiano ancora quali sono i requisiti di calcolo. In questo scenario, è consigliabile iniziare con una delle opzioni predefinite convenienti seguenti. Queste opzioni sono per i test leggeri e per i carichi di lavoro di training.
| Type | Virtual machine size (Dimensioni della macchina virtuale) | Specifiche |
|---|---|---|
| CPU | Standard_DS3_v2 | 4 core, 14 gigabyte (GB) di RAM, 28 GB di spazio di archiviazione |
| GPU | Standard_NC6 | 6 core, 56 gigabyte (GB) di RAM, 380 GB di spazio di archiviazione, GPU NVIDIA Tesla K80 |
Ottenere le dimensioni ottimali della macchina virtuale per il proprio scenario, potrebbe comportare tentativi ed errori. Di seguito sono riportati alcuni aspetti da considerare.
- Se è necessaria una CPU:
- Usare una macchina virtuale ottimizzata per la memoria se si esegue il training su set di dati di grandi dimensioni.
- Usare una macchina virtuale con ottimizzazione per il calcolo se si esegue l'inferenza in tempo reale o altre attività sensibili alla latenza.
- Usare una macchina virtuale con più core e RAM per velocizzare i tempi di training.
- Se è necessaria una GPU, vedere le dimensioni delle macchine virtuali ottimizzate per la GPU per informazioni sulla selezione di una macchina virtuale.
- Se si esegue il training distribuito, usare dimensioni di macchine virtuali con più GPU.
- Se si esegue il training distribuito in più nodi, usare GPU con connessioni NVLink.
Mentre si selezionano il tipo di macchina virtuale e lo SKU più adatti al proprio carico di lavoro, valutare gli SKU delle macchine virtuali confrontabili come compromesso tra prestazioni e prezzi di CPU e GPU. Dal punto di vista della gestione dei costi, un processo potrebbe essere eseguito correttamente su diversi SKU.
Alcune GPU come la famiglia NC, in particolare gli SKU NC_Promo, hanno funzionalità simili ad altre GPU, come la bassa latenza e la capacità di gestire più carichi di lavoro di elaborazione in parallelo. Sono disponibili a prezzi scontati rispetto ad altre GPU. Selezionare attentamente gli SKU della macchina virtuale in base al carico di lavoro, potrebbe alla fine far risparmiare sui costi in modo significativo.
Un promemoria sull'importanza dell'utilizzo è che la registrazione di un numero maggiore di GPU non viene eseguita necessariamente con risultati più rapidi. Assicurarsi invece che le GPU siano completamente utilizzate. Ad esempio, verificare la necessità di NVIDIA CUDA. Anche se potrebbe essere necessaria per l'esecuzione di GPU ad alte prestazioni, il processo potrebbe non dipendere dalla stessa.
Determinare le dimensioni di calcolo per l'inferenza
I requisiti di calcolo per gli scenari di inferenza differiscono dagli scenari di training. Le opzioni disponibili variano a seconda che lo scenario richieda l'inferenza offline in batch o richieda l'inferenza online in tempo reale.
Per gli scenari di inferenza in tempo reale, prendere in considerazione i suggerimenti seguenti:
- Usare le funzionalità di profilatura nel modello con Azure Machine Learning per determinare la quantità di CPU e memoria da allocare per il modello durante la distribuzione come servizio Web.
- Se si esegue l'inferenza in tempo reale ma non è necessaria la disponibilità elevata, eseguire la distribuzione in Istanze di Azure Container (nessuna selezione di SKU).
- Se si esegue l'inferenza in tempo reale ma è necessaria la disponibilità elevata, eseguire la distribuzione nel servizio Azure Kubernetes.
- Se si usano modelli di Machine Learning tradizionali e si ricevono < 10 query al secondo, iniziare con uno SKU CPU. Spesso funzionano anche gli SKU della serie F.
- Se si usano modelli di Deep Learning e si ricevono > 10 query al secondo, provare uno SKU GPU NVIDIA (spesso funziona anche NCasT4_v3) con Triton.
Per gli scenari di inferenza batch, prendere in considerazione i suggerimenti seguenti:
- Quando si usano le pipeline di Azure Machine Learning per l'inferenza batch, seguire le indicazioni in Determinare le dimensioni di calcolo per il training per scegliere le dimensioni iniziali della macchina virtuale.
- Ottimizzare costi e prestazioni con la scalabilità orizzontale. Uno dei metodi chiave per ottimizzare i costi e le prestazioni consiste nel parallelizzare il carico di lavoro con l'aiuto di un passaggio di esecuzione in parallelo in Azure Machine Learning. Questo passaggio della pipeline consente di usare molti nodi più piccoli per eseguire l'attività in parallelo, in modo da consentire la scalabilità orizzontale. Tuttavia, si verifica un sovraccarico per la parallelizzazione. A seconda del carico di lavoro e del grado di parallelismo che è possibile ottenere, un passaggio di esecuzione in parallelo può essere o meno un'opzione.
Determinare le dimensioni per l'istanza di ambiente di calcolo
Per lo sviluppo interattivo, è consigliata l'istanza di ambiente di calcolo di Azure Machine Learning. L'offerta dell'istanza di ambiente di calcolo fornisce un ambiente di calcolo a nodo singolo associato a un singolo utente e che può essere usato come workstation cloud.
Alcune organizzazioni non consentono l'uso dei dati di produzione nelle workstation locali, applicano restrizioni all'ambiente delle workstation o limitano l'installazione di pacchetti e dipendenze nell'ambiente IT aziendale. Un'istanza di ambiente di calcolo può essere usata come workstation per superare la limitazione. Offre un ambiente sicuro con accesso ai dati di produzione e viene eseguita in immagini fornite con i pacchetti e gli strumenti più diffusi per data science preinstallati.
Quando l'istanza di ambiente di calcolo è in esecuzione, all'utente vengono addebitati il calcolo della macchina virtuale, Load Balancer Standard (incluse le regole di bilanciamento del carico/in uscita e i dati elaborati), il disco del sistema operativo (disco P10 gestito SSD Premium), il disco temporaneo (il tipo di disco temporaneo dipende dalle dimensioni della macchina virtuale scelte) e l'indirizzo IP pubblico. Per risparmiare sui costi, è consigliabile:
- Avviare e arrestare l'istanza di ambiente di calcolo quando non è in uso.
- Usare un campione dei dati in un'istanza di ambiente di calcolo e aumentare il numero di istanze nei cluster di elaborazione per usare il set completo di dati.
- Inviare processi di sperimentazione in modalità destinazione di calcolo locale nell'istanza di ambiente di calcolo durante lo sviluppo o il test oppure quando si passa alla capacità di calcolo condivisa quando si inviano processi su larga scala. Ad esempio, molti periodi, set completo di dati e ricerca di iperparametri.
Se si arresta l'istanza di ambiente di calcolo, si interrompe la fatturazione per le ore di calcolo della macchina virtuale, il disco temporaneo e i costi dei dati elaborati di Load Balancer Standard. Si noti che l'utente continua a pagare per il disco del sistema operativo e le regole di bilanciamento del carico/in uscita incluse in Load Balancer Standard anche quando l'istanza di ambiente di calcolo viene arrestata. Tutti i dati vengono salvati in modo permanente sul disco del sistema operativo tramite l'arresto e il riavvio.
Ottimizzare le dimensioni della macchina virtuale scelte monitorando l'utilizzo dell'ambiente di calcolo
È possibile visualizzare le informazioni sull'uso e l'utilizzo dell'ambiente di calcolo di Azure Machine Learning tramite Monitoraggio di Azure. È possibile visualizzare i dettagli sulla distribuzione e la registrazione del modello, i dettagli delle quote come i nodi attivi e inattivi, i dettagli delle esecuzioni come le esecuzioni annullate e completate e l'utilizzo dell'ambiente di calcolo per l'utilizzo di GPU e CPU.
In base alle informazioni presenti nei dettagli di monitoraggio, è possibile pianificare o modificare meglio l'utilizzo delle risorse in tutto il team. Ad esempio, se si notano molti nodi inattivi nell'ultima settimana, è possibile collaborare con i proprietari dell'area di lavoro corrispondente per aggiornare la configurazione del cluster di elaborazione per evitare questo costo aggiuntivo. I vantaggi dell'analisi dei modelli di utilizzo possono essere utili per prevedere i costi e migliorare il budget.
È possibile accedere a queste metriche direttamente dal portale di Azure. Passare all'area di lavoro di Azure Machine Learning e selezionare Metriche nella sezione di monitoraggio nel pannello sinistro. È quindi possibile selezionare i dettagli su ciò che si vuole visualizzare, ad esempio metriche, aggregazione e periodo di tempo. Per altre informazioni, vedere la pagina della documentazione Monitorare Azure Machine Learning.
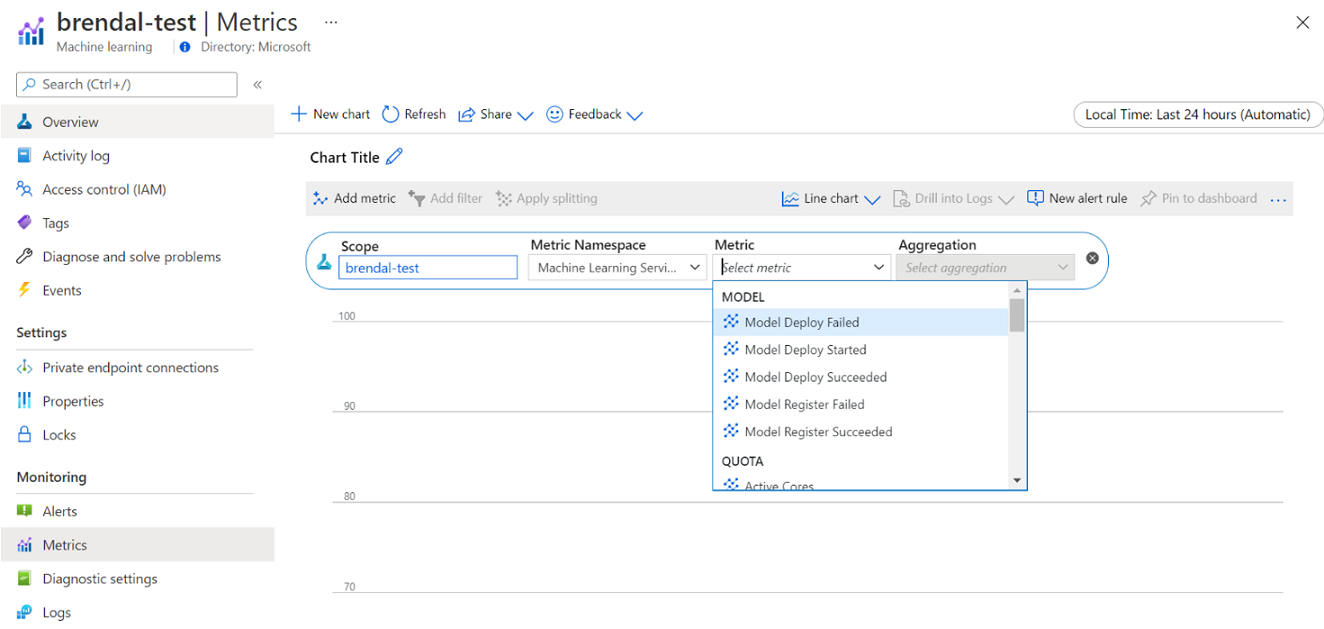
Passare dall'ambiente di calcolo locale a quello cloud a uno o più nodi durante lo sviluppo
Esistono requisiti di calcolo e strumenti diversi per tutto il ciclo di vita di Machine Learning. È possibile interfacciarsi con Azure Machine Learning tramite un'interfaccia SDK e della riga di comando praticamente da qualsiasi configurazione della workstation preferita per soddisfare questi requisiti.
Per risparmiare sui costi e lavorare in modo produttivo, è consigliabile:
- Clonare la codebase di sperimentazione in locale usando Git e inviare processi all'ambiente di calcolo cloud usando l'SDK o l'interfaccia della riga di comando di Azure Machine Learning.
- Se il set di dati è di grandi dimensioni, è consigliabile gestire un campione dei dati nella workstation locale, mantenendo il set di dati completo nell'archiviazione nel cloud.
- Parametrizzare la codebase di sperimentazione in modo da poter configurare i processi da eseguire con un numero variabile di periodi o in set di dati di dimensioni diverse.
- Non impostare il percorso della cartella del set di dati come hardcoded. È quindi possibile riutilizzare facilmente la stessa codebase con set di dati diversi e nel contesto di esecuzione locale e cloud.
- Eseguire il bootstrap dei processi di sperimentazione in modalità destinazione di calcolo locale durante lo sviluppo o il test oppure quando si passa a una capacità del cluster di elaborazione condivisa quando si inviano processi su larga scala.
- Se il set di dati è di grandi dimensioni, usare un campione dei dati nella workstation locale o dell'istanza di ambiente di calcolo, passando all'ambiente di calcolo cloud in Azure Machine Learning per usare il set completo di dati.
- Quando l'esecuzione dei processi richiede molto tempo, è consigliabile ottimizzare la codebase per il training distribuito per consentire la scalabilità orizzontale.
- Progettare i carichi di lavoro del training distribuito per l'elasticità dei nodi, per consentire un uso flessibile dell'ambiente di calcolo a uno e più nodi e semplificare l'utilizzo di un ambiente di calcolo la cui pianificazione può essere sostituita.
Combinare tipi di ambienti di calcolo con le pipeline di Azure Machine Learning
Quando si orchestrano i flussi di lavoro di Machine Learning, è possibile definire una pipeline con più passaggi. Ogni passaggio della pipeline può essere eseguito nel proprio tipo di ambiente di calcolo. Ciò consente di ottimizzare le prestazioni e i costi per soddisfare i diversi requisiti di calcolo nel ciclo di vita di Machine Learning.
Determinare l'uso migliore del budget di un team
Anche se le decisioni di allocazione del budget potrebbero essere fuori dal controllo di un singolo team, un team è in genere in grado di usare il budget allocato in base alle proprie esigenze. Scambiando la priorità del processo rispetto alle prestazioni e ai costi in modo oculato, un team può ottenere un utilizzo più elevato del cluster, ridurre i costi complessivi e usare un numero maggiore di ore di calcolo con lo stesso budget. Ciò può comportare una maggiore produttività del team.
Ottimizzare i costi delle risorse di calcolo condivise
La chiave per ottimizzare i costi delle risorse di calcolo condivise è garantire che vengano usate al massimo della loro capacità. Di seguito sono riportati alcuni suggerimenti per ottimizzare i costi delle risorse condivise:
- Quando si usano le istanze di ambiente di calcolo, attivarle solo quando è necessario eseguire il codice. Arrestarle quando non vengono usate.
- Quando si usano i cluster di elaborazione, impostare il numero minimo di nodi su 0 e il numero massimo di nodi su un numero valutato in base ai vincoli di budget. Usare il calcolatore prezzi di Azure per calcolare il costo dell'utilizzo completo di un nodo della macchina virtuale dello SKU della macchina virtuale scelto. La scalabilità automatica consente di ridurre le prestazioni di tutti i nodi di calcolo quando non vengono usati da nessun utente. Le prestazioni verranno aumentate solo fino al numero di nodi per cui si dispone del budget. È possibile configurare la scalabilità automatica per ridurre le prestazioni di tutti i nodi di calcolo.
- Monitorare l'utilizzo delle risorse come l'utilizzo della CPU e della GPU durante il training dei modelli. Se le risorse non vengono usate completamente, modificare il codice per usare meglio le risorse o ridurre le prestazioni scegliendo dimensioni di macchine virtuali più piccole o più convenienti.
- Valutare se è possibile creare risorse di calcolo condivise per il team per evitare le inefficienze di calcolo causate dalle operazioni di ridimensionamento del cluster.
- Ottimizzare i criteri di timeout di scalabilità automatica dei cluster di elaborazione in base alle metriche di utilizzo.
- Usare le quote dell'area di lavoro per controllare la quantità di risorse di calcolo a cui hanno accesso le singole aree di lavoro.
Introdurre la priorità di pianificazione creando cluster per più SKU di macchine virtuali
Agendo in base a vincoli di quota e di budget, un team deve trovare il giusto compromesso tra esecuzione rapida dei processi e costi, per garantire che i processi importanti siano eseguiti in modo rapido usando il budget nel modo migliore possibile.
Per supportare l'utilizzo ottimale dell'ambiente di calcolo, è consigliabile che i team creino cluster di varie dimensioni e con priorità bassa e priorità di macchine virtuali dedicate. Gli ambienti di calcolo con priorità bassa usano la capacità in eccesso di Azure e quindi hanno tariffe scontate. D'altra parte, la pianificazione di queste macchine può essere sostituita ogni volta che arriva una richiesta con priorità più alta.
Usando i cluster di dimensioni e priorità variabili, è possibile introdurre il concetto di priorità di pianificazione. Ad esempio, quando i processi sperimentali e di produzione competono per la stessa quota GPU NC, un processo di produzione potrebbe avere la precedenza sul processo sperimentale. In tal caso, eseguire il processo di produzione nel cluster di elaborazione dedicato e il processo sperimentale nel cluster di elaborazione con priorità bassa. Quando la quota diventa insufficiente, il processo sperimentale verrà sostituito dal processo di produzione.
Oltre alla priorità della macchina virtuale, valutare la possibilità di eseguire i processi in vari SKU della macchina virtuale. È possibile che l'esecuzione di un processo richieda più tempo su un'istanza di macchina virtuale con una GPU P40 rispetto a una GPU V100. Tuttavia, poiché le istanze della macchina virtuale V100 potrebbero essere occupate o la quota è completamente usata, il tempo di completamento sulla P40 potrebbe essere ancora più veloce dal punto di vista della velocità effettiva del processo. È anche possibile prendere in considerazione l'esecuzione di processi con priorità più bassa in istanze di macchine virtuali meno efficienti e più economiche dal punto di vista della gestione dei costi.
Terminare anticipatamente un'esecuzione quando il training non converge
Quando si sperimenta continuamente per migliorare un modello rispetto alla baseline, si potrebbero eseguire vari esperimenti, ognuno con configurazioni leggermente diverse. Per un'esecuzione, si potrebbero modificare i set di dati di input. Per un'altra esecuzione, si potrebbe apportare una modifica agli iperparametri. Non tutte le modifiche potrebbero essere efficaci come le altre. Si rileva in anticipo che una modifica non ha avuto l'effetto previsto sulla qualità del training del modello. Per rilevare se il training non converge, monitorare lo stato di avanzamento del training durante un'esecuzione. Ad esempio, registrando le metriche delle prestazioni dopo ogni periodo di training. Valutare la possibilità di terminare anticipatamente il processo per liberare risorse e budget per un'altra prova.
Pianificare, gestire e condividere budget, costi e quote
Man mano che un'organizzazione aumenta il numero di casi d'uso e di team di Machine Learning, richiede una maggiore maturità operativa da parte dei reparti di IT e finanza, nonché il coordinamento tra i singoli team di Machine Learning per garantire operazioni efficienti. La gestione della capacità e delle quote su scala aziendale diventa importante per risolvere la scarsità di risorse di calcolo e superare il sovraccarico di gestione.
Questa sezione illustra le procedure consigliate per la pianificazione, la gestione e la condivisione di budget, costi e quote su scala aziendale. Si basa sull'apprendimento della gestione di molte risorse di training GPU per Machine Learning internamente in Microsoft.
Informazioni sulla spesa delle risorse con Azure Machine Learning
Una delle principali sfide dell'amministratore per la pianificazione delle esigenze di calcolo è l'avvio di nuovi progetti senza informazioni cronologiche come stima di base. In pratica, la maggior parte dei progetti inizierà da un budget ridotto come primo passo.
Per comprendere come viene speso il budget, è fondamentale sapere da dove provengono i costi di Azure Machine Learning:
- Azure Machine Learning addebita solo i costi per l'infrastruttura di calcolo usata e non aggiunge un supplemento sui costi dell'ambiente di calcolo.
- Quando viene creata un'area di lavoro di Azure Machine Learning, vengono create anche alcune risorse per abilitare Azure Machine Learning: Key Vault, Application Insights, Archiviazione di Azure e Registro Azure Container. Queste risorse vengono usate in Azure Machine Learning e si pagherà per queste risorse.
- Esistono costi associati all'ambiente di calcolo gestito, ad esempio cluster di training, istanze di ambiente di calcolo ed endpoint di inferenza gestiti. Con queste risorse di calcolo gestite, sono previsti i costi di infrastruttura seguenti: macchine virtuali, rete virtuale, bilanciamento del carico, larghezza di banda e archiviazione.
Tenere traccia dei modelli di spesa e ottenere report migliori con l'assegnazione di tag
Amministrazione istrator spesso vogliono essere in grado di tenere traccia dei costi in risorse diverse in Azure Machine Learning. L'assegnazione di tag è una soluzione naturale a questo problema e si allinea all'approccio generale usato da Azure e da molti altri provider di servizi cloud. Con il supporto dei tag, è ora possibile visualizzare la suddivisione dei costi a livello di calcolo, concedendo quindi l'accesso a una visualizzazione più granulare per facilitare il monitoraggio dei costi, la creazione di report migliorata e una maggiore trasparenza.
L'assegnazione di tag consente di inserire tag personalizzati nelle aree di lavoro e nei calcoli (dai modelli di Azure Resource Manager e studio di Azure Machine Learning) per filtrare ulteriormente queste risorse in Gestione costi Microsoft in base a questi tag per osservare i modelli di spesa. Questa funzionalità può essere usata al meglio per scenari di chargeback interni. Inoltre, i tag possono essere utili per acquisire metadati o dettagli associati al calcolo, ad esempio un progetto, un team o un determinato codice di fatturazione. In questo modo, l'assegnazione di tag risulta molto utile per misurare quanto denaro si sta spendendo su risorse diverse e quindi ottenere informazioni più approfondite sui costi e sui modelli di spesa tra team o progetti.
Esistono anche tag inseriti dal sistema nei calcoli che consentono di filtrare nella pagina Analisi dei costi in base al tag "Tipo di calcolo" per visualizzare una suddivisione a livello di calcolo della spesa totale e determinare quale categoria di risorse di calcolo potrebbe attribuire alla maggior parte dei costi. Ciò è particolarmente utile per ottenere maggiore visibilità sul training e l'inferenza dei modelli di costo.
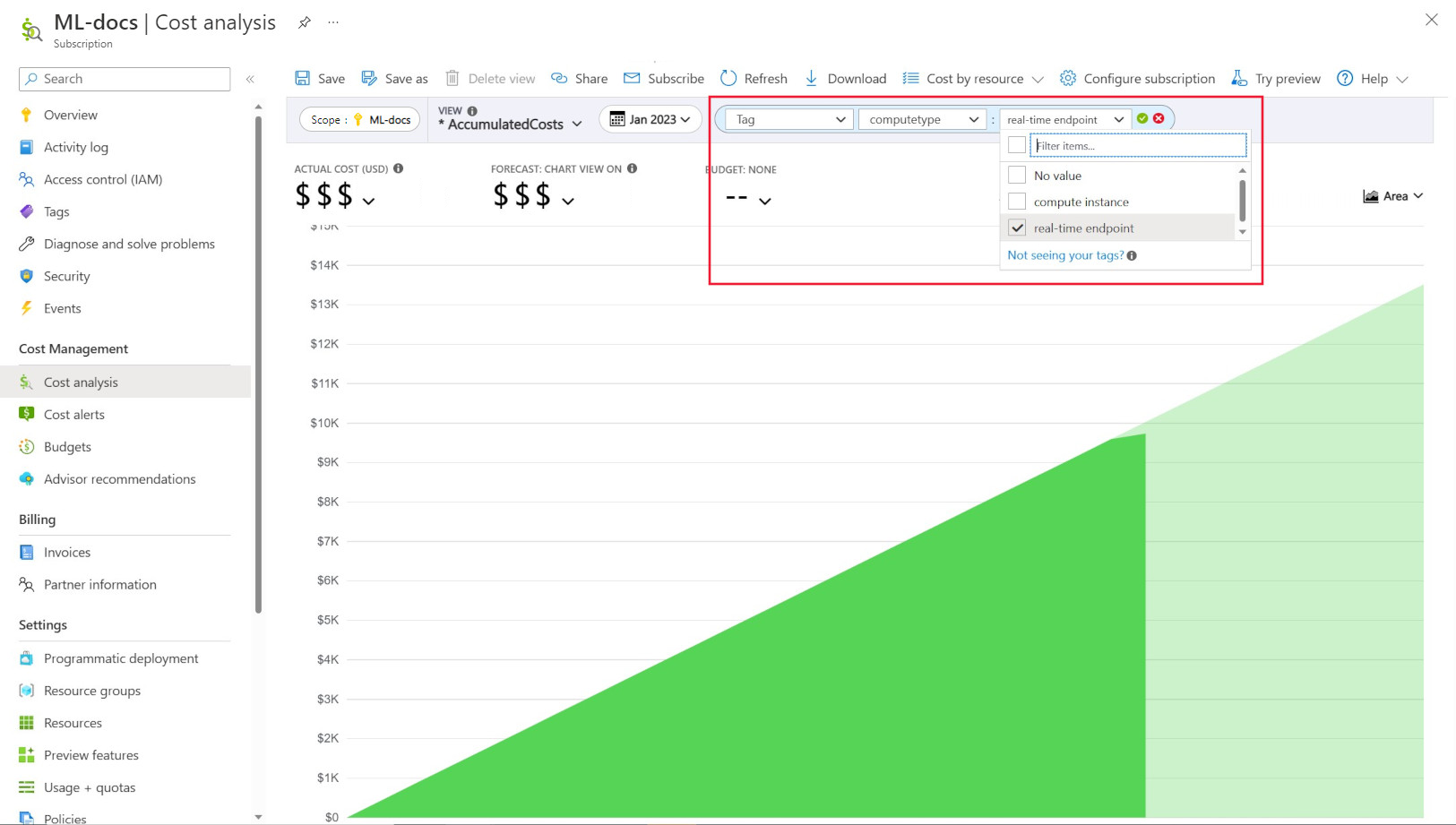
Gestire e limitare l'utilizzo dell'ambiente di calcolo in base ai criteri
Quando si gestisce un ambiente di Azure con molti carichi di lavoro, può essere difficile tenere sotto controllo la spesa delle risorse. Criteri di Azure può aiutare a controllare e gestire la spesa delle risorse, limitando determinati modelli di utilizzo nell'ambiente di Azure.
In particolare per Azure Machine Learning, è consigliabile configurare criteri per consentire solo l'utilizzo di SKU di macchine virtuali specifici. I criteri consentono di impedire e controllare la selezione di macchine virtuali costose. I criteri possono essere usati anche per imporre l'utilizzo di SKU di macchine virtuali con priorità bassa.
Allocare e gestire la quota in base alla priorità aziendale
Azure consente di impostare limiti per l'allocazione delle quote a livello di sottoscrizione e di area di lavoro di Azure Machine Learning. Limitare chi può gestire le quote tramite il controllo degli accessi in base al ruolo di Azure consente di garantire l'utilizzo delle risorse e la prevedibilità dei costi.
La disponibilità della quota GPU può essere limitata nelle sottoscrizioni. Per garantire un utilizzo elevato della quota tra i carichi di lavoro, è consigliabile monitorare se la quota è usata e assegnata in modo ottimale tra i carichi di lavoro.
In Microsoft viene determinato periodicamente se le quote GPU vengono usate e allocate in modo ottimale tra i team di Machine Learning valutando le esigenze di capacità rispetto alle priorità aziendali.
Eseguire il commit della capacità in anticipo
Se si dispone di una buona stima della quantità di calcolo che verrà usata nel prossimo anno o nei prossimi anni, è possibile acquistare istanze di macchina virtuale riservate di Azure a un prezzo scontato. Sono disponibili condizioni di acquisto di un anno o di tre anni. Poiché le istanze di macchina virtuale riservate di Azure sono scontate, è possibile ottenere notevoli risparmi sui costi rispetto ai prezzi con pagamento in base al consumo.
Azure Machine Learning supporta le istanze di ambiente di calcolo riservate. Gli sconti vengono applicati automaticamente per l'ambiente di calcolo gestito di Azure Machine Learning.
Gestire la conservazione dei dati
Ogni volta che viene eseguita una pipeline di Machine Learning, è possibile generare set di dati intermedi in ogni passaggio della pipeline per la memorizzazione nella cache e il riutilizzo dei dati. La crescita dei dati come output di queste pipeline di Machine Learning può diventare un punto dolente per un'organizzazione che esegue molti esperimenti di Machine Learning.
I data scientist in genere non dedicano tempo alla pulizia dei set di dati intermedi generati. Nel tempo, la quantità di dati generati aumenterà. Archiviazione di Azure offre la possibilità di migliorare la gestione del ciclo di vita dei dati. Usando la gestione del ciclo di vita di Archiviazione BLOB di Azure, è possibile configurare criteri generali per spostare i dati inutilizzati in livelli di archiviazione offline più sicura e risparmiare sui costi.
Considerazioni sull'ottimizzazione dei costi dell'infrastruttura
Rete
I costi di rete di Azure vengono sostenuti dalla larghezza di banda in uscita dal data center di Azure. Tutti i dati in ingresso in un data center di Azure sono gratuiti. La chiave per ridurre i costi di rete è distribuire tutte le risorse nella stessa area del data center, quando possibile. Se è possibile distribuire un'area di lavoro e un ambiente di calcolo di Azure Machine Learning nella stessa area in cui sono presenti i dati, è possibile usufruire di costi inferiori e prestazioni più elevate.
Si potrebbe voler avere una connessione privata tra la rete locale e la rete di Azure per avere un ambiente cloud ibrido. ExpressRoute consente di adottare questo approccio, ma considerando il costo elevato di ExpressRoute, potrebbe essere più conveniente scegliere di non usare più una configurazione del cloud ibrido e spostare tutte le risorse nel cloud di Azure.
Registro Azure Container
Per Registro Azure Container, i fattori determinanti per l'ottimizzazione dei costi includono:
- Velocità effettiva necessaria per il download di immagini Docker dal registro contenitori in Azure Machine Learning
- Requisiti per le funzionalità di sicurezza aziendale come Collegamento privato di Azure
Per gli scenari di produzione in cui sono necessarie una velocità effettiva o una sicurezza aziendale elevate, è consigliabile lo SKU Premium di Registro Azure Container.
Per gli scenari di sviluppo/test in cui la velocità effettiva e la sicurezza sono meno importanti, è consigliabile usare lo SKU Standard o lo SKU Premium.
Lo SKU Basic di Registro Azure Container non è consigliato per Azure Machine Learning. Non è consigliabile a causa della bassa velocità effettiva e dello spazio di archiviazione incluso ridotto, che può essere rapidamente superato dalle immagini Docker di Azure Machine Learning di dimensioni relativamente grandi (più di 1 GB).
Considerare la disponibilità del tipo di calcolo quando si scelgono le aree di Azure
Quando si sceglie un'area per l'ambiente di calcolo, tenere presente la disponibilità della quota di calcolo. Le aree più comuni e più grandi come Stati Uniti orientali, Stati Uniti occidentali ed Europa occidentale tendono ad avere valori di quota predefiniti più elevati e una maggiore disponibilità della maggior parte delle CPU e delle GPU, rispetto ad altre aree con restrizioni di capacità più rigorose.
Altre informazioni
Tenere traccia dei costi tra business unit, ambienti o progetti con Cloud Adoption Framework
Passaggi successivi
Per altre informazioni su come organizzare e configurare gli ambienti di Azure Machine Learning, vedere Organizzare e configurare gli ambienti di Azure Machine Learning.
Per altre informazioni sulle procedure consigliate per Machine Learning DevOps con Azure Machine Learning, vedere la Guida di Machine Learning DevOps.