Considerazioni sulla progettazione per le piattaforme dati self-service
La mesh di dati è un nuovo approccio interessante per la progettazione e lo sviluppo dell'architettura dei dati. A differenza dell'architettura dei dati tradizionale, la mesh di dati separa la responsabilità tra i domini dati funzionali che si concentrano sulla creazione di prodotti dati e un team di piattaforma incentrato sulle funzionalità tecniche. Questa separazione delle responsabilità deve essere riflessa nella piattaforma. È necessario trovare un equilibrio tra fornire funzionalità indipendenti dal dominio e consentire ai team di dominio di modellare, elaborare e distribuire i dati all'interno dell'organizzazione.
La scelta del livello corretto di granularità e regole di dominio per la disaccoppiamento con le piattaforme non è facile. Questo articolo contiene diversi scenari che forniscono indicazioni dettagliate.
Analisi cloud
Quando si vuole creare una mesh di dati con Azure, è consigliabile adottare l'analisi su scala cloud. Questo framework è un'architettura di riferimento distribuibile e include modelli open source e procedure consigliate. L'architettura di analisi su scala cloud ha due blocchi predefiniti principali fondamentali per tutte le scelte di distribuzione:
- Zona di destinazione della gestione dei dati: la base dell'architettura dei dati. Contiene tutte le funzionalità critiche per la gestione dei dati, ad esempio il catalogo dati, la derivazione dei dati, il catalogo API, la gestione dei dati master e così via.
- Zone di destinazione dei dati: sottoscrizioni che ospitano le soluzioni di analisi e intelligenza artificiale. Includono funzionalità chiave per l'hosting di una piattaforma di analisi.
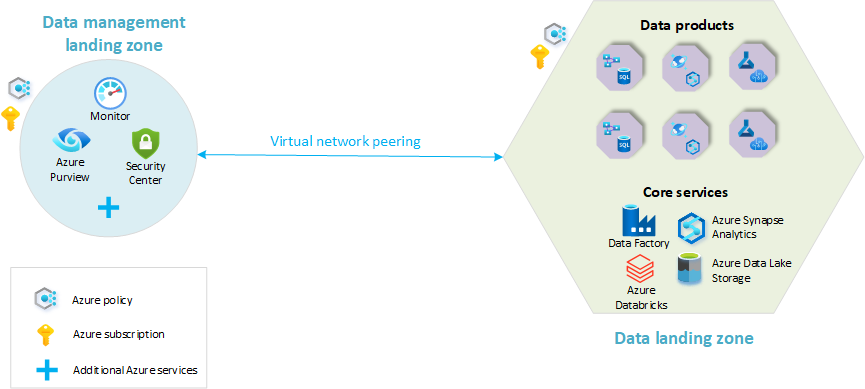
Il diagramma seguente offre una panoramica di una piattaforma di analisi su scala cloud con una zona di destinazione di gestione dei dati e una singola zona di destinazione dei dati. Nel diagramma non sono rappresentati tutti i servizi di Azure. È stata semplificata per evidenziare l'organizzazione delle risorse dei concetti di base all'interno di questa architettura.
Il framework di analisi basato sul cloud non è esplicito sul tipo esatto di architettura dei dati di cui è necessario eseguire il provisioning. È possibile usarlo per molte soluzioni di analisi su scala cloud comuni, tra cui data warehouse (enterprise), data lake, case data lake e mesh di dati. Tutte le soluzioni di esempio in questo articolo usano l'architettura della mesh di dati.
Comprendere che tutte le architetture rispettano i principi della mesh di dati: proprietà del dominio, dati come prodotto, piattaforma dati self-service e governance di calcolo federata. Percorsi diversi possono portare a una mesh di dati. Non c'è una sola risposta giusta o sbagliata. È necessario apportare i compromessi giusti per le esigenze dell'organizzazione.
Singola zona di destinazione dei dati
Il modello di distribuzione più semplice per la creazione di un'architettura mesh di dati prevede una zona di destinazione per la gestione dei dati e una zona di destinazione dei dati. L'architettura dei dati in uno scenario di questo tipo sarà simile alla seguente:

In questo modello tutti i domini dati funzionali risiedono nella stessa zona di destinazione dei dati. Una singola sottoscrizione contiene un set standard di servizi. I gruppi di risorse separano domini dati e prodotti dati diversi. I servizi dati standard, ad esempio Azure Data Lake Store, App per la logica di Azure e Azure Synapse Analytics, si applicano a tutti i domini.
Tutti i domini dati seguono i principi della mesh dei dati: i dati seguono la proprietà del dominio e i dati vengono trattati come prodotti. La piattaforma è completamente self-service, anche se esistono variazioni limitate di servizi. Tutti i domini devono rispettare e rispettare gli stessi principi di gestione dei dati.
Questa opzione di distribuzione può essere utile per aziende più piccole o progetti greenfield che vogliono adottare mesh di dati, ma non cose eccessivamente complicate. Questa distribuzione può anche essere un punto di partenza per un'organizzazione che prevede di creare qualcosa di più complesso. In questo caso, pianificare l'espansione in più zone di destinazione in un secondo momento.
Zone di destinazione allineate al sistema di origine e allineate al consumer
Nel modello precedente non sono stati preso in considerazione altre sottoscrizioni o applicazioni locali. È possibile modificare leggermente il modello precedente aggiungendo una zona di destinazione allineata al sistema di origine per gestire tutti i dati in ingresso. L'onboarding dei dati è un processo difficile, quindi la disponibilità di due zone di destinazione dei dati è utile. L'onboarding rimane una delle parti più complesse dell'uso dei dati in grandi dimensioni. L'onboarding richiede spesso strumenti aggiuntivi per affrontare l'integrazione, perché le sfide sono diverse da quelle dell'integrazione. Consente di distinguere tra la fornitura di dati e l'utilizzo dei dati.

Nell'architettura a sinistra di questo diagramma i servizi facilitano l'onboarding di tutti i dati, ad esempio CDC, i servizi per il pull delle API o i servizi data lake per la compilazione dinamica dei set di dati. I servizi in questa piattaforma possono eseguire il pull dei dati da ambienti locali, cloud o fornitori SaaS. Questo tipo di piattaforma comporta in genere un sovraccarico maggiore, perché esiste un maggiore accoppiamento con le applicazioni operative sottostanti. È consigliabile trattarlo in modo diverso da qualsiasi utilizzo dei dati.
Nell'architettura a destra del diagramma, l'organizzazione ottimizza l'utilizzo e ha servizi incentrati sulla trasformazione dei dati in valore. Questi servizi possono includere Machine Learning, creazione di report e così via.
Questi domini di architettura seguono tutti i principi della mesh di dati. I domini assumono la proprietà dei dati e possono distribuire direttamente i dati ad altri domini.
Zone di destinazione dei dati hub, generiche e speciali
L'opzione di distribuzione successiva è un'altra iterazione della progettazione precedente. Questa distribuzione segue una topologia mesh regolamentata: i dati vengono distribuiti tramite un hub centrale, in cui i dati vengono partizionati per dominio, isolati logicamente e non integrati. L'hub di questo modello usa la propria zona di destinazione dei dati (indipendente dal dominio) e può essere di proprietà di un team di governance dei dati centrale che supervisiona i dati distribuiti a quali altri domini. L'hub include anche servizi che facilitano l'onboarding dei dati.

Per i domini che richiedono servizi standard per l'utilizzo, l'uso, l'analisi e la creazione di nuovi dati, usare la zona di destinazione dei dati generici. Questa singola sottoscrizione contiene un set standard di servizi. Applicare anche la virtualizzazione dei dati, poiché la maggior parte dei prodotti dati è già persistente nell'hub e non è necessaria una maggiore duplicazione dei dati.
Questa distribuzione consente "speciali": zone di destinazione aggiuntive di cui è possibile effettuare il provisioning quando non è possibile raggruppare logicamente i domini. Potrebbero essere necessari quando si applicano limiti regionali o legali o quando i domini hanno requisiti univoci e contrastanti. Potrebbero anche essere necessari in situazioni in cui viene applicata una forte governance globale delle filiali con eccezioni per le attività all'estero.
Se l'organizzazione deve controllare quali dati vengono distribuiti e usati da quali domini, la distribuzione dell'hub è un'ottima opzione. È anche un'opzione che consente di risolvere problemi di tipo time-variant e non volatili per i consumer di dati di grandi dimensioni. È possibile standardizzare fortemente la progettazione del prodotto dei dati, che consente ai domini di viaggiare in tempo ed eseguire operazioni di rollforward. Questo modello è particolarmente comune all'interno del settore finanziario.
Zone di destinazione dei dati funzionali e allineate a livello di area
Il provisioning di più zone di destinazione dei dati consente di raggruppare i domini funzionali in base alla coesione e all'efficienza per lavorare e condividere i dati. Tutte le zone di destinazione dei dati rispettano gli stessi controlli e controllo, ma è comunque possibile avere flessibilità e modifiche di progettazione tra zone di destinazione dei dati diverse.

Determinare i domini di dati funzionali da raggruppare logicamente per una zona di destinazione dei dati condivisi. Ad esempio, è possibile implementare gli stessi modelli se sono presenti limiti a livello di area. La proprietà, la sicurezza o i limiti legali possono forzare la separazione dei domini. La flessibilità, il ritmo del cambiamento e la separazione o la vendita delle funzionalità sono anche fattori importanti da considerare.
Altre indicazioni e procedure consigliate sono disponibili nei domini dati.
Le diverse zone di destinazione non sono autonome. Possono connettersi ai data lake ospitati in altre zone. In questo modo i domini possono collaborare in tutta l'azienda. È anche possibile applicare la persistenza poliglotta per combinare tecnologie di archivio dati diverse. La persistenza poliglotta consente ai domini di leggere direttamente i dati da altri domini senza duplicare i dati.
Quando si distribuiscono più zone di destinazione dei dati, tenere presente che è presente un sovraccarico di gestione collegato a ogni zona di destinazione dei dati. È necessario applicare il peering reti virtuali tra tutte le zone di destinazione dei dati, è necessario gestire endpoint privati aggiuntivi e così via.
La distribuzione di più zone di destinazione dei dati è un'opzione valida se l'architettura dei dati è di grandi dimensioni. È possibile aggiungere altre zone di destinazione all'architettura per soddisfare le esigenze comuni di vari domini. Queste zone di destinazione aggiuntive usano il peering di rete virtuale per connettersi sia alla zona di destinazione di gestione dei dati che a tutte le altre zone di destinazione. Il peering consente di condividere set di dati e risorse tra le zone di destinazione. La suddivisione dei dati tra zone separate consente di distribuire i carichi di lavoro tra le sottoscrizioni e le risorse di Azure. Questo approccio consente di implementare in modo organico la mesh di dati.
Aziende su larga scala che richiedono zone di gestione dei dati diverse
Le aziende di grandi dimensioni che operano su scala globale possono avere requisiti di gestione dei dati contrastanti tra diverse parti dell'organizzazione. Per risolvere questo problema, è possibile distribuire più zone di gestione dei dati e di destinazione dei dati. Il diagramma seguente mostra un esempio di questo tipo di architettura:

Più zone di destinazione per la gestione dei dati devono giustificare la complessità dell'overhead e dell'integrazione. Ad esempio, un'altra zona di destinazione per la gestione dei dati può avere senso per situazioni in cui i dati dell'organizzazione (meta)non devono essere visualizzati da nessuno all'esterno dell'organizzazione.
Conclusione
La transizione verso la mesh dei dati è un cambiamento culturale che coinvolge sfumature, compromessi e considerazioni. È possibile usare l'analisi su scala cloud per ottenere procedure consigliate e risorse eseguibili. Le architetture di riferimento di questo articolo offrono punti di partenza per avviare l'implementazione.