Procedure consigliate per i progetti di data science con l'analisi su scala cloud in Azure
Raccomandiamo queste migliori pratiche per usare l'analisi su scala cloud in Microsoft Azure per rendere operativi i progetti di data science.
Sviluppare un modello
Sviluppare un modello che aggrega un set di servizi per i progetti di data science. Usare un modello che aggrega un set di servizi per garantire la coerenza tra i vari casi d'uso dei team di data science. È consigliabile sviluppare un progetto coerente sotto forma di repository di modelli. È possibile usare questo repository per vari progetti di data science all'interno dell'organizzazione per ridurre i tempi di distribuzione.
Linee guida per i modelli di data science
Sviluppare un modello di data science per l'organizzazione con le linee guida seguenti:
Sviluppare un set di modelli di infrastruttura come codice (IaC) per distribuire un'area di lavoro di Azure Machine Learning. Includere risorse come un Key Vault, un account di archiviazione, un registro contenitori e Application Insights.
Includere la configurazione di archivi dati e destinazioni di calcolo in questi modelli, ad esempio istanze di calcolo, cluster di calcolo e Azure Databricks.
Buone pratiche di distribuzione
In tempo reale
- Includere una distribuzione di Azure Data Factory o Azure Synapse nei modelli e in Servizi cognitivi di Azure.
- I modelli devono fornire tutti gli strumenti necessari per eseguire la fase di esplorazione dell'analisi scientifica dei dati e l'operazionalizzazione iniziale del modello.
Considerazioni per una configurazione iniziale
In alcuni casi, i data scientist dell'organizzazione potrebbero richiedere un ambiente per un'analisi rapida in base alle esigenze. Questa situazione è comune quando un progetto di data science non è configurato formalmente. Ad esempio, un project manager, un codice di costo o un centro di costo che potrebbe essere necessario per l'addebito incrociato in Azure potrebbe non essere presente perché l'elemento mancante richiede l'approvazione. Gli utenti dell'organizzazione o del team potrebbero dover accedere a un ambiente di data science per comprendere i dati ed eventualmente valutare la fattibilità di un progetto. Inoltre, alcuni progetti potrebbero non richiedere un ambiente di data science completo a causa del numero ridotto di prodotti dati.
In altri casi, potrebbe essere necessario un progetto di data science completo, completo con un ambiente dedicato, la gestione dei progetti, il codice di costo e il centro di costo. I progetti di data science completi sono utili per più membri del team che vogliono collaborare, condividere i risultati e dover rendere operativi i modelli al termine della fase di esplorazione.
Processo di installazione
I modelli devono essere distribuiti per ogni progetto dopo essere stati configurati. Ogni progetto dovrebbe ricevere almeno due istanze affinché gli ambienti di sviluppo e produzione siano distinti. Nell'ambiente di produzione, nessun utente deve avere accesso e tutto deve essere distribuito tramite pipeline di integrazione continua o di sviluppo continuo e una principale del servizio. Questi principi dell'ambiente di produzione sono importanti perché Azure Machine Learning non fornisce un modello granulare di controllo degli accessi in base al ruolo all'interno di un'area di lavoro. Non è possibile limitare l'accesso degli utenti a un set specifico di esperimenti, endpoint o pipeline.
Gli stessi diritti di accesso si applicano in genere a tipi diversi di artefatti. È importante separare lo sviluppo dall'ambiente di produzione per impedire l'eliminazione di pipeline o endpoint di produzione all'interno di un'area di lavoro. Oltre al modello, è necessario creare un processo per consentire ai team del prodotto dati di richiedere nuovi ambienti.
È consigliabile configurare servizi di intelligenza artificiale diversi, ad esempio Servizi cognitivi di Azure, in base al progetto. Configurando diversi servizi di intelligenza artificiale in base al progetto, le distribuzioni vengono eseguite per ogni gruppo di risorse del prodotto dati. Questo criterio crea una netta separazione dal punto di vista dell'accesso ai dati e riduce il rischio di accesso non autorizzato ai dati da parte dei team sbagliati.
Scenario di streaming
Per i casi d'uso in tempo reale e di streaming, è necessario testare le implementazioni in un Azure Kubernetes Service (AKS). Il test può trovarsi nell'ambiente di sviluppo per risparmiare sui costi prima della distribuzione nel servizio Azure Kubernetes di produzione o nel servizio app di Azure per i contenitori. È consigliabile eseguire semplici test di input e output per assicurarsi che i servizi rispondano come previsto.
Successivamente, è possibile distribuire i modelli nel servizio desiderato. Questa destinazione di calcolo della distribuzione è l'unica disponibile a livello generale e consigliata per i carichi di lavoro di produzione in un cluster del servizio Azure Kubernetes. Questo passaggio diventa più importante se è richiesto il supporto per l'unità di elaborazione grafica (GPU) o per l'array di gate programmabili in campo. Altre opzioni di distribuzione native che supportano questi requisiti hardware non sono attualmente disponibili in Azure Machine Learning.
Azure Machine Learning richiede una mappatura uno-a-uno con i cluster di Azure Kubernetes Service. Ogni nuova connessione a un'area di lavoro di Azure Machine Learning interrompe la connessione precedente tra AKS e Azure Machine Learning. Dopo aver attenuato tale limitazione, è consigliabile distribuire cluster AKS centrali come risorse condivise e collegarli ai rispettivi workspace.
Un'altra istanza del servizio Azure Kubernetes di test centrale deve essere ospitata se è necessario eseguire test di stress prima di spostare un modello nel servizio Azure Kubernetes di produzione. L'ambiente di test deve fornire la stessa risorsa di calcolo dell'ambiente di produzione per garantire che i risultati siano il più possibile simili all'ambiente di produzione.
Scenario batch
Non tutti i casi d'uso richiedono distribuzioni di cluster degli AKS. Un caso d'uso non necessita di una distribuzione di un cluster AKS se grandi quantità di dati necessitano solo di valutazione regolare o se si basano su un evento. Ad esempio, grandi quantità di dati possono dipendere da quando i dati vengono archiviati in un account di archiviazione specifico. Le pipeline di Azure Machine Learning e i cluster di calcolo di Azure Machine Learning devono essere usati per la distribuzione durante questi tipi di scenari. Queste pipeline devono essere orchestrate ed eseguite in Data Factory.
Identificare le risorse di calcolo corrette
Prima di distribuire un modello in Azure Machine Learning su AKS, l'utente deve specificare le risorse, come CPU, RAM e GPU, da allocare per il rispettivo modello. La definizione di questi parametri può essere un processo complesso e noioso. È necessario eseguire test di stress con configurazioni diverse per identificare un buon set di parametri. È possibile semplificare questo processo con la funzionalità di profilatura del modello in Azure Machine Learning, che è un'attività a lungo termine che testa diverse combinazioni di allocazioni delle risorse e usa una latenza identificata e un tempo di andata e ritorno (RTT) per consigliare una combinazione ottimale. Queste informazioni possono facilitare la distribuzione reale del modello su AKS.
Per aggiornare in modo sicuro i modelli in Azure Machine Learning, i team devono usare la funzionalità di implementazione controllata (anteprima) per ridurre al minimo i tempi di inattività e mantenere coerente l'endpoint REST del modello.
Le migliori pratiche e il flusso di lavoro per MLOps
Includere il codice di esempio nei repository di data science
È possibile semplificare e accelerare i progetti di data science se i team hanno determinati artefatti e procedure consigliate. È consigliabile creare strumenti condivisi che tutti i team di data science possono utilizzare nell'interazione con Azure Machine Learning e i rispettivi strumenti dell'ambiente del prodotto dati. I data e i tecnici di Machine Learning devono creare e fornire gli artefatti.
Questi artefatti devono includere:
Esempi di notebook che mostrano come:
- Caricare, montare e gestire prodotti di dati.
- Registrare metriche e parametri.
- Invia processi di training ai cluster di calcolo.
Elementi necessari per l'operazionalizzazione:
- Esempi di pipeline di Azure Machine Learning
- Azure Pipelines di esempio
- Altri script necessari per eseguire le pipeline
Documentazione
Usare artefatti ben progettati per rendere operative le pipeline
Gli artefatti possono velocizzare le fasi di esplorazione e operazionalizzazione dei progetti di data science. Una strategia di 'fork' in DevOps consente di espandere questi artefatti in tutti i progetti. Poiché questa configurazione promuove l'uso di Git, gli utenti e il processo di automazione generale possono trarre vantaggio dagli artefatti forniti.
Consiglio
Le pipeline di esempio di Azure Machine Learning devono essere compilate con Python Software Developer Kit (SDK) o basate sul linguaggio YAML. La nuova esperienza YAML sarà più a prova di futuro, perché il team del prodotto Azure Machine Learning sta attualmente lavorando a una nuova interfaccia dell'SDK e della riga di comando. Il team del prodotto Azure Machine Learning è sicuro che YAML fungerà da linguaggio di definizione per tutti gli artefatti all'interno di Azure Machine Learning.
Le pipeline di esempio non sono immediatamente funzionanti per ogni progetto, ma possono essere usate come punto di riferimento. È possibile modificare le pipeline di esempio per i progetti. Una pipeline deve includere gli aspetti più rilevanti di ogni progetto. Ad esempio, una pipeline può fare riferimento a una destinazione di calcolo, fare riferimento a prodotti dati di riferimento, definire parametri, definire gli input e definire i passaggi di esecuzione. Lo stesso processo deve essere eseguito per Azure Pipelines. Azure Pipelines dovrebbe utilizzare anche Azure Machine Learning SDK o CLI.
Le pipeline devono illustrare come:
- Connettersi a un'area di lavoro dall'interno di una pipeline DevOps.
- Controllare se il calcolo necessario è disponibile.
- Inviare un'attività.
- Registrare e distribuire un modello.
Gli artefatti non sono adatti a tutti i progetti per tutto il tempo e potrebbero richiedere la personalizzazione, ma avere una base può velocizzare l'operazionalizzazione e la distribuzione di un progetto.
Strutturare il repository MLOps
Potrebbero verificarsi situazioni in cui gli utenti perdono traccia della posizione in cui possono trovare e archiviare gli artefatti. Per evitare queste situazioni, è necessario richiedere più tempo per comunicare e costruire una struttura di cartelle di primo livello per il repository standard. Tutti i progetti devono seguire la struttura di cartelle.
Nota
I concetti menzionati in questa sezione possono essere usati in ambienti locali, Amazon Web Services, Palantir e Azure.
La struttura di cartelle di primo livello proposta per un repository MLOps (operazioni di Machine Learning) è illustrata nel diagramma seguente:
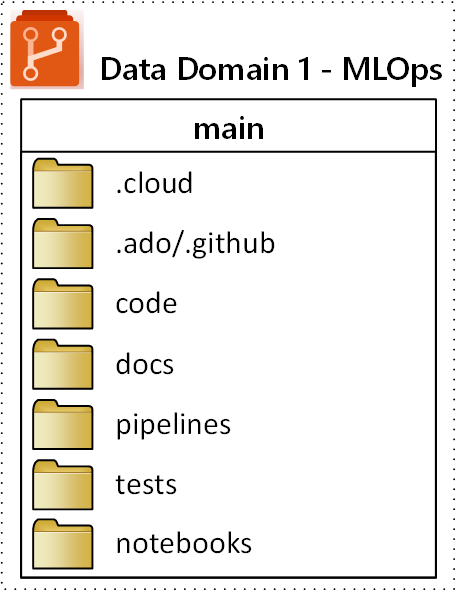
Gli scopi seguenti si applicano a ogni cartella nel repository:
| Cartella | Scopo |
|---|---|
.cloud |
Archiviare codice e artefatti specifici del cloud in questa cartella. Gli artefatti includono i file di configurazione per l'area di lavoro di Azure Machine Learning, incluse le definizioni di destinazione di calcolo, i processi, i modelli registrati e gli endpoint. |
.ado/.github |
Archivia gli artefatti di Azure DevOps o GitHub, come le pipeline YAML o i file dei proprietari del codice, in questa cartella. |
code |
Includere il codice effettivo sviluppato come parte del progetto in questa cartella. Questa cartella può contenere pacchetti Python e alcuni script usati per i rispettivi passaggi della pipeline di Machine Learning. È consigliabile separare i singoli passaggi che devono essere eseguiti in questa cartella. I passaggi comuni sono la pre-elaborazione, l'addestramento del modello e la registrazione del modello . Definire dipendenze come dipendenze Conda, immagini Docker o altre per ogni cartella. |
docs |
Usare questa cartella a scopo di documentazione. Questa cartella archivia file e immagini Markdown per descrivere il progetto. |
pipelines |
Archiviare le definizioni delle pipeline di Azure Machine Learning in YAML o Python in questa cartella. |
tests |
Scrivere unit test e test di integrazione che devono essere eseguiti per individuare bug e problemi nelle prime fasi del progetto in questa cartella. |
notebooks |
Separa i notebook di Jupyter dal progetto Python vero e proprio utilizzando questa cartella. All'interno della cartella, ogni utente dovrebbe avere una sottocartella per controllare i propri notebook e impedire i conflitti di merge di Git. |