Modellazione dei dati in Azure Cosmos DB
SI APPLICA A: ![]() NoSQL
NoSQL
Sebbene i database senza schema, come Azure Cosmos DB, semplifichino l'archiviazione e l'esecuzione di query su dati non strutturati e semistrutturati, è consigliabile esaminare il proprio modello di dati per ottenere il massimo dal servizio in termini di prestazioni e scalabilità e costi più bassi.
Come verranno archiviati i dati? In che modo l'applicazione recupererà i dati e ne eseguirà la query? L'applicazione esegue un'intensa attività di lettura o di scrittura?
Alla fine della lettura, si avranno le risposte alle domande seguenti:
- Cos'è la modellazione dei dati e perché è importante?
- In che modo la modellazione dei dati in Azure Cosmos DB è diversa da quella in un database relazionale?
- Come si esprimono le relazioni tra i dati in un database non relazionale?
- Quando si incorporano i dati e quando si creano i collegamenti ai dati?
Numeri in JSON
Azure Cosmos DB salva i documenti in JSON. Ciò significa che è necessario determinare attentamente se bisogna convertire i numeri in stringhe prima di archiviarli in formato JSON o meno. Tutti i numeri devono essere convertiti idealmente in String, se c'è una possibilità che questi non rientrino nei limiti dei numeri a precisione doppia in base a IEEE 754 binary64. La specifica JSON indica i motivi per cui l'uso dei numeri al di fuori di questo limite è in generale una procedura non consigliata in JSON a causa di possibili problemi di interoperabilità. Questi problemi sono particolarmente rilevanti per la colonna chiave della partizione, poiché essa è invariabile e richiede che la migrazione dei dati la modifichi in un secondo momento.
Incorporare i dati
Quando si avvia la modellazione dei dati in Azure Cosmos DB, è consigliabile trattare le entità come elementi autonomi rappresentati come documenti JSON.
Per un confronto, si veda innanzitutto come modellare i dati in un database relazionale. L'esempio seguente mostra come una persona possa essere archiviata in un database relazionale.
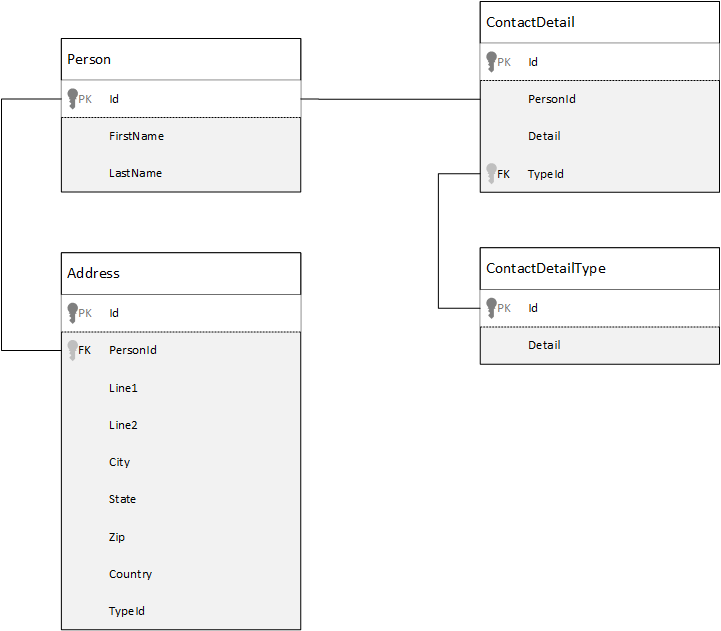
La strategia, quando si usano i database relazionali, consiste nel normalizzare tutti i dati. La normalizzazione dei dati implica di solito la suddivisione di un'entità, ad esempio una persona, in componenti discreti. Nell'esempio, una persona può avere più record di dettagli di contatto e più record di indirizzi. I dettagli di contatto possono essere ulteriormente suddivisi estraendo altri campi comuni come il tipo. Lo stesso vale per l'indirizzo, ogni record può essere di tipo Casa o Lavoro.
Il presupposto principale quando si normalizzano i dati è evitare di archiviare i dati ridondanti in ogni record e fare invece riferimento ai dati. In questo esempio, per leggere una persona, con tutti i dettagli di contatto e gli indirizzi, è necessario usare i join per ricomporre (o denormalizzare) in modo efficace i dati in fase di esecuzione.
SELECT p.FirstName, p.LastName, a.City, cd.Detail
FROM Person p
JOIN ContactDetail cd ON cd.PersonId = p.Id
JOIN ContactDetailType cdt ON cdt.Id = cd.TypeId
JOIN Address a ON a.PersonId = p.Id
Per aggiornare i dettagli contatto e gli indirizzi di una singola persona, è necessario eseguire operazioni di scrittura in più tabelle.
Ora si esaminerà come si modellano gli stessi dati come entità autonoma in Azure Cosmos DB.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"addresses": [
{
"line1": "100 Some Street",
"line2": "Unit 1",
"city": "Seattle",
"state": "WA",
"zip": 98012
}
],
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555", "extension": 5555}
]
}
Con questo approccio il record della persona è stato ora denormalizzato, incorporando tutte le informazioni relative alla persona, ad esempio i dettagli di contatto e gli indirizzi, in un singolo documento JSON. Inoltre, dal momento che non esistono limiti imposti da uno schema fisso, abbiamo la flessibilità necessaria, ad esempio, per avere dettagli contatto di forme completamente diverse.
Il recupero del record completo di una persona dal database è ora una sola operazione di lettura in un singolo contenitore e per un solo elemento. Anche l'aggiornamento dei dettagli di contatto e degli indirizzi del record di una persona richiede una sola operazione di scrittura in un solo elemento.
Denormalizzando i dati, è possibile che l'applicazione debba eseguire meno query e aggiornamenti per completare le comuni operazioni.
Quando eseguire l'incorporamento
In generale, usare i modelli di dati incorporati quando:
- Esistono relazioni indipendenti tra le entità.
- Esistono relazioni one-to-few tra le entità.
- Esistono dati incorporati che cambiano raramente.
- Esistono dati incorporati che non aumentano senza limiti.
- Esistono dati incorporati che di frequente sono sottoposti a query insieme.
Nota
I modelli di dati denormalizzati garantiscono di solito prestazioni di lettura più elevate.
Quando non eseguire l'incorporamento
Sebbene in linea generale in Azure Cosmos DB si denormalizza tutto e si incorporano tutti i dati in un solo elemento, questo può creare situazioni che è consigliabile evitare.
Consideriamo questo frammento JSON.
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"comments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
…
{"id": 100001, "author": "jane", "comment": "and on we go ..."},
…
{"id": 1000000001, "author": "angry", "comment": "blah angry blah angry"},
…
{"id": ∞ + 1, "author": "bored", "comment": "oh man, will this ever end?"},
]
}
Questo potrebbe essere l'aspetto di un'entità post con commenti incorporati, se si modellasse un tipico sistema di blog, o CMS. Il problema di questo esempio è che la matrice di commenti non è limitata, vale a dire che non esiste in pratica un limite al numero di commenti per ogni singolo post. Questo potrebbe diventare un problema perché le dimensioni dell'elemento potrebbero aumentare all'infinito, pertanto è una progettazione da evitare.
Quando le dimensioni dell'elemento aumentano, si influenza anche la capacità di trasmettere i dati nella rete e di leggere e aggiornare l'elemento su larga scala.
In questo caso, è meglio prendere in considerazione il modello di dati seguente.
Post item:
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"recentComments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
{"id": 3, "author": "jane", "comment": "....."}
]
}
Comment items:
[
{"id": 4, "postId": "1", "author": "anon", "comment": "more goodness"},
{"id": 5, "postId": "1", "author": "bob", "comment": "tails from the field"},
...
{"id": 99, "postId": "1", "author": "angry", "comment": "blah angry blah angry"},
{"id": 100, "postId": "2", "author": "anon", "comment": "yet more"},
...
{"id": 199, "postId": "2", "author": "bored", "comment": "will this ever end?"}
]
Questo modello include un documento per ogni commento con una proprietà che contiene l'identificatore del post. Ciò consente ai post di contenere qualsiasi numero di commenti e di crescere in modo efficiente. Gli utenti che non vogliono visualizzare solo i commenti più recenti devono eseguire una query su questo contenitore passando postId, che deve essere la chiave di partizione per il contenitore dei commenti.
Un altro caso in cui non è consigliabile ricorrere all'incorporamento dei dati è quando i dati incorporati vengono usati spesso negli elementi e cambiano di frequente.
Consideriamo questo frammento JSON.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{
"numberHeld": 100,
"stock": { "symbol": "zbzb", "open": 1, "high": 2, "low": 0.5 }
},
{
"numberHeld": 50,
"stock": { "symbol": "xcxc", "open": 89, "high": 93.24, "low": 88.87 }
}
]
}
Questo potrebbe essere il portafoglio azionario di una persona. Si è scelto di incorporare le informazioni sulle azioni in ogni documento del portafoglio. In un ambiente in cui i dati correlati cambiano spesso, come in un'applicazione per le contrattazioni azionarie, l'incorporamento di dati che cambiano spesso obbligherà ad aggiornare continuamente ogni documento del portfolio ogni volta che viene scambiata un'azione.
Il titolo zbzb potrebbe essere scambiato diverse centinaia di volte in un solo giorno e migliaia di utenti potrebbero avere zbzb nel proprio portfolio. Con un modello di dati come quello nell’esempio è necessario aggiornare molte migliaia di documenti del portfolio più volte al giorno, con una scarsa efficienza della scalabilità del sistema.
Dati di riferimento
L'incorporamento dei dati funziona senza problemi in molti casi, ma in altri scenari la denormalizzazione dei dati è più che altro causa di problemi. Cosa si può fare dunque?
Le relazioni tra entità non devono essere necessariamente create in un database relazionale. In un database di documenti è possibile avere in un documento informazioni correlate ai dati di altri documenti. Non è consigliabile creare sistemi più appropriati per un database relazionale in Azure Cosmos DB o in qualsiasi altro database di documenti. Le relazioni semplici, tuttavia, sono adeguate e potrebbero essere molto utili.
Nel codice JSON abbiamo scelto di usare l'esempio del portafoglio di azioni di prima, ma questa volta facciamo riferimento all'elemento titolo nel portafoglio invece di incorporarlo. In questo modo, anche se l'elemento titolo cambia più volte nel corso della giornata, il solo documento da aggiornare è il documento del titolo.
Person document:
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{ "numberHeld": 100, "stockId": 1},
{ "numberHeld": 50, "stockId": 2}
]
}
Stock documents:
{
"id": "1",
"symbol": "zbzb",
"open": 1,
"high": 2,
"low": 0.5,
"vol": 11970000,
"mkt-cap": 42000000,
"pe": 5.89
},
{
"id": "2",
"symbol": "xcxc",
"open": 89,
"high": 93.24,
"low": 88.87,
"vol": 2970200,
"mkt-cap": 1005000,
"pe": 75.82
}
L'aspetto negativo di questo approccio diventa però immediatamente evidente se l'applicazione deve mostrare informazioni su ogni titolo disponibile quando si visualizza il portafoglio di una persona. In questo caso, sarebbe necessario accedere più volte al database per caricare le informazioni del documento di ogni titolo. Qui è stata presa la decisione di aumentare l'efficienza delle operazioni di scrittura, che vengono eseguite spesso durante la giornata, compromettendo però le operazioni di lettura che hanno un impatto potenzialmente minore sulle prestazioni di questo particolare sistema.
Nota
I modelli di dati normalizzati possono richiedere più round trip al server.
Chiavi esterne
Poiché attualmente non esistono vincoli, chiavi esterne o altro, le relazioni esistenti tra i documenti sono di fatto "collegamenti deboli" e non verranno verificate dal database. Per essere certi che i dati a cui un documento fa riferimento esistano davvero, è necessario eseguire questa operazione nell'applicazione oppure usando trigger lato server o stored procedure in Azure Cosmos DB.
Quando fare riferimento
In generale, usare i modelli di dati normalizzati quando:
- Si rappresentano relazioni uno a molti .
- Si rappresentano relazioni molti a molti .
- I dati correlati cambiano spesso.
- È possibile che i dati a cui si fa riferimento non siamo limitati.
Nota
La normalizzazione offre di solito migliori prestazioni di scrittura .
Dove inserire le relazioni
La crescita della relazione aiuta a determinare in quale documento archiviare il riferimento.
Se osserviamo il codice JSON che modella editori e libri.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press",
"books": [ 1, 2, 3, ..., 100, ..., 1000]
}
Book documents:
{"id": "1", "name": "Azure Cosmos DB 101" }
{"id": "2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "3", "name": "Taking over the world one JSON doc at a time" }
...
{"id": "100", "name": "Learn about Azure Cosmos DB" }
...
{"id": "1000", "name": "Deep Dive into Azure Cosmos DB" }
Se il numero di libri per editore è piccolo e ha una crescita limitata, può essere utile archiviare il riferimento ai libri nel documento dell'editore. Se invece il numero di libri per editore è illimitato, questo modello di dati darà origine a matrici modificabili e in costante crescita, come nel documento dell'editore di esempio.
Cambiando un po' le cose, si ottiene un modello che rappresenta sempre gli stessi dati, ma che ora evita queste grandi raccolte modificabili.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press"
}
Book documents:
{"id": "1","name": "Azure Cosmos DB 101", "pub-id": "mspress"}
{"id": "2","name": "Azure Cosmos DB for RDBMS Users", "pub-id": "mspress"}
{"id": "3","name": "Taking over the world one JSON doc at a time", "pub-id": "mspress"}
...
{"id": "100","name": "Learn about Azure Cosmos DB", "pub-id": "mspress"}
...
{"id": "1000","name": "Deep Dive into Azure Cosmos DB", "pub-id": "mspress"}
In questo esempio, la raccolta illimitata nel documento dell'editore è stata eliminata. Ora abbiamo solo un riferimento all'editore nel documento di ogni libro.
Come modellare le relazioni molti-a-molti?
In un database relazionale le relazioni molti a molti vengono spesso modellate con le tabelle di join, che creano join tra i record delle altre tabelle.
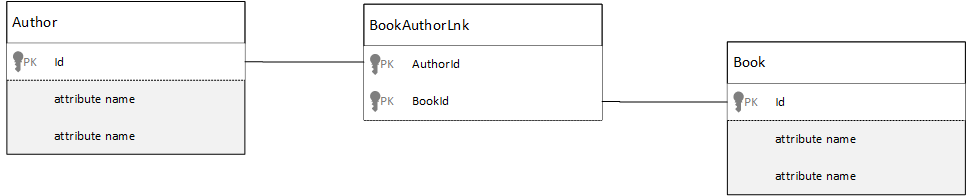
Si potrebbe essere tentati di replicare la stessa cosa con i documenti e di generare un modello di dati simile al seguente.
Author documents:
{"id": "a1", "name": "Thomas Andersen" }
{"id": "a2", "name": "William Wakefield" }
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101" }
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "b3", "name": "Taking over the world one JSON doc at a time" }
{"id": "b4", "name": "Learn about Azure Cosmos DB" }
{"id": "b5", "name": "Deep Dive into Azure Cosmos DB" }
Joining documents:
{"authorId": "a1", "bookId": "b1" }
{"authorId": "a2", "bookId": "b1" }
{"authorId": "a1", "bookId": "b2" }
{"authorId": "a1", "bookId": "b3" }
Funzionerebbe, ma, per caricare un autore con i suoi libri o un libro con il suo autore, sarebbero sempre necessarie almeno altre due query sul database; una query per creare un join del documento e quindi un'altra query per recuperare il documento effettivo di cui viene creato il join.
Se il join si limita a incollare insieme due parti di dati, allora perché non eliminarlo del tutto? Si consideri l'esempio seguente.
Author documents:
{"id": "a1", "name": "Thomas Andersen", "books": ["b1", "b2", "b3"]}
{"id": "a2", "name": "William Wakefield", "books": ["b1", "b4"]}
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101", "authors": ["a1", "a2"]}
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users", "authors": ["a1"]}
{"id": "b3", "name": "Learn about Azure Cosmos DB", "authors": ["a1"]}
{"id": "b4", "name": "Deep Dive into Azure Cosmos DB", "authors": ["a2"]}
Nel caso di un autore, si potrebbero conoscere immediatamente i libri che ha scritto e, al contrario, se fosse stato caricato un documento relativo ai libri, si conoscerebbero gli ID degli autori. Questo evita la query intermedia sulla tabella join riducendo il numero di round trip al server che l'applicazione deve eseguire.
Modelli di dati ibridi
Fino ad ora sono stati esaminati l'incorporamento (o la denormalizzazione) e il riferimento (o normalizzazione) dei dati. Ogni approccio presenta vantaggi e compromessi.
Ma non è sempre necessario scegliere uno dei due. È anche possibile mischiare un po' le cose.
In base ai modelli di utilizzo e ai carichi di lavoro specifici dell'applicazione, in certi casi potrebbe avere senso unire i dati incorporati e quelli a cui si fa riferimento per ottenere una logica dell'applicazione più semplice con meno round trip al server, mantenendo ugualmente un buon livello di prestazioni.
Si consideri il codice JSON seguente.
Author documents:
{
"id": "a1",
"firstName": "Thomas",
"lastName": "Andersen",
"countOfBooks": 3,
"books": ["b1", "b2", "b3"],
"images": [
{"thumbnail": "https://....png"}
{"profile": "https://....png"}
{"large": "https://....png"}
]
},
{
"id": "a2",
"firstName": "William",
"lastName": "Wakefield",
"countOfBooks": 1,
"books": ["b1"],
"images": [
{"thumbnail": "https://....png"}
]
}
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
{"id": "a2", "name": "William Wakefield", "thumbnailUrl": "https://....png"}
]
},
{
"id": "b2",
"name": "Azure Cosmos DB for RDBMS Users",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
]
}
Qui abbiamo per lo più seguito il modello incorporato, in cui i dati delle altre entità vengono incorporati nel documento di primo livello, ma viene fatto riferimento agli altri dati.
Se si osserva il documento dei libri, si possono vedere alcuni campi interessanti quando si considera la matrice degli autori. È presente un campo id che viene usato per fare riferimento al documento di un autore (procedura standard in un modello normalizzato), ma sono presenti anche i campi name e thumbnailUrl. È possibile fermarsi a id e lasciare che l'applicazione recuperi le altre informazioni necessarie dal documento dell'autore corrispondente usando il "collegamento", ma, dal momento che l'applicazione mostra il nome e un'immagine di anteprima dell'autore con ogni libro visualizzato, è possibile evitare un round trip al server per ogni libro di un elenco denormalizzando alcuni dati dell'autore.
Se l'autore cambia nome o se la foto deve essere aggiornata, naturalmente, è necessario eseguire un aggiornamento per ogni libro pubblicato, ma per questa applicazione, che si basa sul presupposto che gli autori non cambino nome molto spesso, questa è una decisione di progettazione accettabile.
Nell'esempio sono presenti valori di aggregazioni precalcolate, che consentono di evitare l'elaborazione di costose operazioni di lettura. Nell'esempio, alcuni dati incorporati nel documento dell'autore vengono calcolati in fase di esecuzione. Ogni volta che viene pubblicato un nuovo libro, viene creato un documento per il libro e il campo countOfBooks viene impostato su un valore calcolato in base al numero di documenti dei libri esistenti per un determinato autore. Questa ottimizzazione andrebbe bene nei sistemi che eseguono un'intensa attività di lettura, in cui si è disposti a effettuare calcoli nelle scritture per ottimizzare le letture.
Azure Cosmos DB supporta le transazioni in più documenti e consente quindi di usare transazioni su più documenti. Molti archivi NoSQL non possono eseguire le transazioni tra documenti e, a causa di questa limitazione, inducono a prendere decisioni di progettazione, ad esempio "incorporare sempre tutto". Con Azure Cosmos DB è possibile usare trigger lato server, o stored procedure, che inseriscono i libri e aggiornano gli autori in una sola transazione ACID. Ora non è necessario incorporare tutto in un unico documento solo per essere sicuri che i dati rimangano coerenti.
Distinzione tra tipi di documento diversi
In alcuni scenari, è possibile combinare tipi di documento diversi nella stessa raccolta: è tipicamente il caso in cui si desidera che più documenti correlati si trovino nella stessa partizione. Ad esempio, è possibile inserire sia i libri che le relative recensioni nella stessa raccolta e partizionarla per bookId. In questo caso, in genere si aggiunge un campo ai documenti che ne identifica il tipo per differenziarli.
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"bookId": "b1",
"type": "book"
}
Review documents:
{
"id": "r1",
"content": "This book is awesome",
"bookId": "b1",
"type": "review"
},
{
"id": "r2",
"content": "Best book ever!",
"bookId": "b1",
"type": "review"
}
Modellazione dei dati per Collegamento ad Azure Synapse e archivio analitico di Azure Cosmos DB
Collegamento ad Azure Synapse per Azure Cosmos DB è una funzionalità HTAP (Hybrid Transactional and Analytical Processing) nativa del cloud che consente di eseguire analisi in modalità near real-time su dati operativi in Azure Cosmos DB. Collegamento ad Azure Synapse crea una stretta integrazione tra Azure Cosmos DB e Azure Synapse Analytics.
Questa integrazione avviene tramite l'archivio analitico di Azure Cosmos DB, una rappresentazione a colonne dei dati transazionali che consente l'analisi su larga scala senza alcun impatto sui carichi di lavoro transazionali. Questo archivio analitico è indicato per eseguire query rapide e a costi contenuti su set di dati operativi di grandi dimensioni, senza copiare i dati e senza influire sulle prestazioni dei carichi di lavoro transazionali. Quando si crea un contenitore in cui è abilitata l'archiviazione analitica o quando si abilita l'archiviazione analitica in un contenitore esistente, tutti gli inserimenti transazionali, gli aggiornamenti e le eliminazioni vengono sincronizzati con l'archiviazione analitica in modalità near real time, non sono necessari processi del feed di modifiche o ETL.
Con Collegamento ad Azure Synapse è ora possibile connettersi direttamente ai contenitori di Azure Cosmos DB da Azure Synapse Analytics e accedere all'archivio analitico senza usare unità richiesta. Azure Synapse Analytics attualmente supporta Collegamento ad Azure Synapse con i pool Apache Spark per Synapse e i pool SQL serverless. Se si ha un account Azure Cosmos DB distribuito a livello globale, un archivio analitico abilitato per un contenitore sarà disponibile in tutte le aree per tale account.
Inferenza automatica dello schema dell'archivio analitico
Mentre i dati dell'archivio transazionale di Azure Cosmos DB sono considerati dati semistrutturati orientati alle righe, l'archivio analitico ha un formato a colonne e strutturato. Questa conversione viene eseguita automaticamente per i clienti, usando le regole di inferenza dello schema per l'archivio analitico. Il processo di conversione ha dei limiti: numero massimo di livelli annidati, numero massimo di proprietà, tipi di dati non supportati e altro ancora.
Nota
Nel contesto dell'archivio analitico le strutture seguenti vengono considerate come proprietà:
- "elementi" JSON o "coppie stringa-valore separate da
:". - Oggetti JSON, delimitati da
{e}. - Matrici JSON, delimitati da
[e].
È possibile ridurre al minimo l'impatto delle conversioni di inferenza dello schema e ottimizzare le funzionalità analitiche usando le tecniche seguenti.
Normalizzazione
La normalizzazione perde il proprio valore perché con Collegamento ad Azure Synapse è possibile creare un join tra i contenitori, usando T-SQL o Spark SQL. I vantaggi previsti della normalizzazione sono:
- Footprint ridotto dei dati sull'archivio transazionale e analitico.
- Transazioni più piccole.
- Numero inferiore di proprietà per documento.
- Strutture di dati con un numero inferiori di livelli annidati.
Questi ultimi due fattori, numero inferiore di proprietà e di livelli, contribuiscono a migliorare le prestazioni delle query analitiche, ma riducono anche le probabilità che parti dei dati non vengano rappresentate nell'archivio analitico. Come descritto nell'articolo sulle regole di inferenza automatica dello schema, c'è un limite al numero di livelli e proprietà che sono rappresentati nell'archivio analitico.
Un altro fattore importante per la normalizzazione è che i pool SQL serverless in Azure Synapse supportano i set di risultati con un massimo di 1.000 colonne e anche l'esposizione di colonne annidate viene conteggiata per tale limite. In altre parole, sia l'archivio analitico che i pool serverless di Synapse SQL hanno un limite di 1.000 proprietà.
Ma cosa fare considerato che la denormalizzazione è una tecnica di modellazione dei dati importante per Azure Cosmos DB? La risposta è che è necessario trovare il giusto equilibrio per i carichi di lavoro transazionali e analitici.
Partition Key (Chiave partizione)
La chiave di partizione di Azure Cosmos DB non viene usata nell'archivio analitico. È ora possibile usare il partizionamento personalizzato dell'archivio analitico per le copie dell'archivio analitico usando qualsiasi chiave di partizione desiderata. A causa di questo isolamento, è possibile scegliere una chiave di partizione per i dati transazionali con particolare attenzione all'inserimento dei dati e alle letture dei punti, mentre è possibile eseguire query tra partizioni con Collegamento ad Azure Synapse. Di seguito viene illustrato un esempio:
In un ipotetico scenario IoT globale, device id è una buona chiave di partizione perché tutti i dispositivi hanno un volume di dati simile e in questo modo non si avrà un problema di partizione ad accesso frequente. Tuttavia, se si vogliono analizzare i dati di più dispositivi, ad esempio "tutti i dati di ieri" o "i totali per città", potrebbero verificarsi problemi poiché si tratta di query tra partizioni. Queste query possono compromettere le prestazioni transazionali perché usano parte della velocità effettiva nelle unità richiesta per l'esecuzione. Con Collegamento ad Azure Synapse, tuttavia, è possibile eseguire queste query analitiche senza usare unità richiesta. Il formato a colonne dell'archivio analitico è ottimizzato per le query analitiche e Collegamento ad Azure Synapse applica questa caratteristica per offrire prestazioni ottimali con i runtime di Azure Synapse Analytics.
Nomi di proprietà e tipi di dati
L'articolo sulle regole di inferenza automatica dello schema elenca i tipi di dati supportati. Mentre il tipo di dati non supportato blocca la rappresentazione nell'archivio analitico, i tipi di dati supportati potrebbero essere elaborati in modo diverso dai runtime di Azure Synapse. Ecco un esempio: quando si usano stringhe DateTime che seguono lo standard UTC ISO 8601, i pool Spark in Azure Synapse rappresentano le colonne come stringa e i pool SQL serverless in Azure Synapse le rappresentano come varchar(8000).
Un'altra difficoltà è che non tutti i caratteri vengono accettati da Spark per Azure Synapse. Mentre gli spazi vuoti sono accettati, i caratteri come i due punti, l'accento grave e la virgola non lo sono. Si supponga che il documento abbia una proprietà denominata "Nome, Cognome". Questa proprietà viene rappresentata nell'archivio analitico e il pool serverless di Synapse SQL può leggerla senza problemi. Tuttavia, poiché si trova nell'archivio analitico, Spark per Azure Synapse non può leggere i dati dell'archivio analitico, incluse tutte le altre proprietà. Al termine della giornata, non sarà possibile usare Spark per Azure Synapse se una proprietà usa i caratteri non supportati nel proprio nome.
Rendere flat i dati
Tutte le proprietà nel livello radice dei dati di Azure Cosmos DB verranno rappresentate nell'archivio analitico come colonna e tutti gli altri elementi che si trovano nei livelli più profondi del modello di dati del documento verranno rappresentati come JSON, anche nelle strutture annidate. Le strutture annidate richiedono un'elaborazione aggiuntiva da parte dei runtime di Azure Synapse per rendere flat i dati in formato strutturato, cosa che potrebbe risultare complessa negli scenari di Big Data.
Il documento include solo due colonne nell'archivio analitico, id e contactDetails. Tutti gli altri dati, email e phone, richiedono l'elaborazione aggiuntiva tramite funzioni SQL per essere letti singolarmente.
{
"id": "1",
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555"}
]
}
Il documento include tre colonne nell'archivio analitico, id, email e phone. Tutti i dati sono direttamente accessibili come colonne.
{
"id": "1",
"email": "thomas@andersen.com",
"phone": "+1 555 555-5555"
}
Suddivisione in livelli dei dati
Collegamento ad Azure Synapse consente di ridurre i costi per quanto riguarda gli aspetti seguenti:
- Numero inferiore di query in esecuzione nel database transazionale.
- Chiave di partizione ottimizzata per l'inserimento dei dati e le letture dei punti, con conseguente riduzione del footprint dei dati, degli scenari di partizione ad accesso frequente e delle suddivisioni in partizioni.
- La suddivisione in livelli dei dati dalla durata analitica è indipendente dalla durata transazionale. È possibile mantenere i dati transazionali nell'archivio transazionale per alcuni giorni, settimane, mesi e conservare i dati nell'archivio analitico per anni o per sempre. Il formato a colonne dell'archivio analitico comporta una compressione naturale dei dati, dal 50% al 90%. E il suo costo per GB è circa il 10% del prezzo attuale dell'archivio transazionale. Per altre informazioni sulle limitazioni correnti del backup, consultare la panoramica dell'archivio analitico.
- Nessun processo ETL in esecuzione nell'ambiente, questo significa che non è necessario effettuare il provisioning delle unità richiesta per i processi.
Ridondanza controllata
Questa è un'ottima alternativa per le situazioni in cui esiste già un modello di dati e non è possibile modificarlo. Inoltre il modello di dati esistente non è adatto all'archivio analitico a causa delle proprie regole di inferenza automatica dello schema, ad esempio il limite di livelli annidati o il numero massimo di proprietà. In questo caso, è possibile usare il feed di modifiche di Azure Cosmos DB per replicare i dati in un altro contenitore, applicando le trasformazioni necessarie per un modello di dati adatto a Collegamento ad Azure Synapse. Di seguito viene illustrato un esempio:
Scenario
Il contenitore CustomersOrdersAndItems viene usato per archiviare gli ordini on-line, inclusi i dettagli dei clienti e degli articoli: indirizzo di fatturazione, indirizzo di consegna, metodo di consegna, stato di consegna, prezzo degli articoli e così via. Sono rappresentate solo le prime 1.000 proprietà e le informazioni chiave non sono incluse nell'archivio analitico, bloccando così l'utilizzo di Collegamento ad Azure Synapse. Il contenitore include molti PB di record e non è possibile modificare l'applicazione e rimodellare i dati.
Un'altra prospettiva del problema è il volume di Big Data. Miliardi di righe vengono usate costantemente dal reparto di analisi, cosa impedisce di usare la durata transazionale per l'eliminazione di dati obsoleti. La conservazione dell'intera cronologia dei dati nel database transazionale per esigenze analitiche impone di aumentare costantemente il provisioning delle unità richiesta, con un impatto sui costi. I carichi di lavoro transazionali e analitici competono contemporaneamente per le stesse risorse.
Cosa fare?
Soluzione con il feed di modifiche
- Il team di progettazione ha deciso di usare il feed di modifiche per popolare tre nuovi contenitori:
Customers,OrderseItems. Con il feed di modifiche i dati vengono normalizzati e resi flat. Le informazioni non necessarie vengono rimosse dal modello di dati e ogni contenitore ha quasi 100 proprietà, evitando la perdita di dati a causa dei limiti di inferenza automatica dello schema. - In questi nuovi contenitori è abilitato l'archivio analitico e ora il reparto di analisi usa Synapse Analytics per leggere i dati, riducendo l'utilizzo delle unità richiesta, perché le query analitiche vengono eseguite nei pool di Apache Spark per Synapse e nei pool SQL serverless.
- Nel contenitore
CustomersOrdersAndItemsè ora impostata la durata transazionale per mantenere i dati solo per sei mesi, il che consente un'ulteriore riduzione nell'utilizzo delle unità richiesta, perché in Azure Cosmos DB c'è almeno 1 unità richiesta per GB. Meno dati, meno unità richiesta.
Risultati
Il concetto principale espresso in questo articolo è che la modellazione dei dati in un ambiente senza schema è più importante che mai.
Come non esiste un solo modo per rappresentare i dati in una schermata, così non esiste un solo modo per modellare i dati. È necessario conoscere l'applicazione e come genera, usa ed elabora i dati. Quindi, applicando alcune delle linee guida presentate qui, è possibile iniziare a creare un modello che risponda alle esigenze immediate dell'applicazione. Quando le applicazioni devono essere modificate, è possibile usare la flessibilità di un database senza schema per accettare la modifica e far evolvere facilmente il modello di dati.