Scegliere la distribuzione delle colonne in Azure Cosmos DB for PostgreSQL
SI APPLICA A: ![]() Azure Cosmos DB for PostgreSQL (con tecnologia basata sull'estensione di database Citus per PostgreSQL)
Azure Cosmos DB for PostgreSQL (con tecnologia basata sull'estensione di database Citus per PostgreSQL)
La scelta della colonna di distribuzione per ogni tabella è una delle decisioni più importanti da prendere per la modellazione. Azure Cosmos DB for PostgreSQL archivia le righe in partizioni in base al valore della colonna di distribuzione delle righe.
La scelta corretta raggruppa i dati correlati sugli stessi nodi fisici, che rende le query veloci e aggiunge il supporto per tutte le funzionalità SQL. Una scelta errata comporta l'esecuzione lenta del sistema.
Suggerimenti generali
Ecco quattro criteri per scegliere la colonna di distribuzione ideale per le tabelle distribuite.
Scegliere una colonna che rappresenta una parte centrale del carico di lavoro dell'applicazione.
Questa colonna può essere considerata come "cuore", il "pezzo centrale" o la "dimensione naturale" per il partizionamento dei dati.
Esempi:
device_idin un carico di lavoro IoTsecurity_idper un'app finanziaria che tiene traccia dei titoliuser_idnell'analisi utentetenant_idper un'applicazione SaaS multi-tenant
Scegliere una colonna con una cardinalità accettabile e una distribuzione statistica uniforme.
La colonna deve avere molti valori ed eseguire una distribuzione accurata e uniforme tra tutte le partizioni.
Esempi:
- Cardinalità superiore a 1000
- Non scegliere una colonna con lo stesso valore in una percentuale elevata di righe (asimmetria dei dati)
- In un carico di lavoro SaaS, avere un tenant molto più grande del resto può causare un'asimmetria dei dati. Per questa situazione, è possibile usare l'isolamento del tenant per creare una partizione dedicata per gestire il tenant.
Scegliere una colonna che trae vantaggio dalle query esistenti.
Per un carico di lavoro transazionale od operativo (in cui la maggior parte delle query richiede solo pochi millisecondi), selezionare una colonna visualizzata come filtro nelle clausole
WHEREper almeno l'80% delle query. Ad esempio, la colonnadevice_idinSELECT * FROM events WHERE device_id=1.Per un carico di lavoro analitico (in cui la maggior parte delle query richiede 1-2 secondi), selezionare una colonna che consente la parallelizzazione delle query tra i nodi di lavoro. Ad esempio, una colonna che si verifica spesso nelle clausole GROUP BY o su cui è eseguita una query su più valori contemporaneamente.
Scegliere una colonna presente nella maggior parte delle tabelle di grandi dimensioni.
Le tabelle di oltre 50 GB devono essere distribuite. La scelta della stessa colonna di distribuzione per tutti gli elementi consente di coubicare i dati per tale colonna nei nodi di lavoro. La coubicazione rende efficiente l'esecuzione di JOIN e rollup e l'applicazione di chiavi esterne.
Le altre tabelle (più piccole) possono essere tabelle locali o di riferimento. Se la tabella più piccola deve essere JOIN con tabelle distribuite, impostarla come tabella di riferimento.
Esempi di casi d'uso
Sono stati visualizzati criteri generali per la scelta della colonna di distribuzione. Vediamo ora come si applicano ai casi d'uso comuni.
App multi-tenant
L'architettura multi-tenant usa una forma di modellazione gerarchica del database per distribuire query tra i nodi del cluster. La parte superiore della gerarchia dei dati è nota come ID tenant e deve essere archiviata in una colonna in ogni tabella.
Azure Cosmos DB for PostgreSQL esamina le query per vedere quale ID tenant coinvolge e trova la partizione della tabella corrispondente. Instrada la query a un singolo nodo di lavoro che contiene la partizione. L'esecuzione di una query con tutti i dati pertinenti posizionati nello stesso nodo viene definita coubicazione.
Il diagramma seguente illustra la coubicazione nel modello di dati multi-tenant. Contiene due tabelle, Account e Campagne, ciascuna distribuita da account_id. Le caselle ombreggiate rappresentano le partizioni. Le partizioni verdi vengono archiviate insieme in un nodo di lavoro e le partizioni azzurre vengono archiviate in un altro nodo di lavoro. Si noti che una query di join tra Account e Campagne include tutti i dati necessari in un nodo quando entrambe le tabelle sono limitate allo stesso account_id.
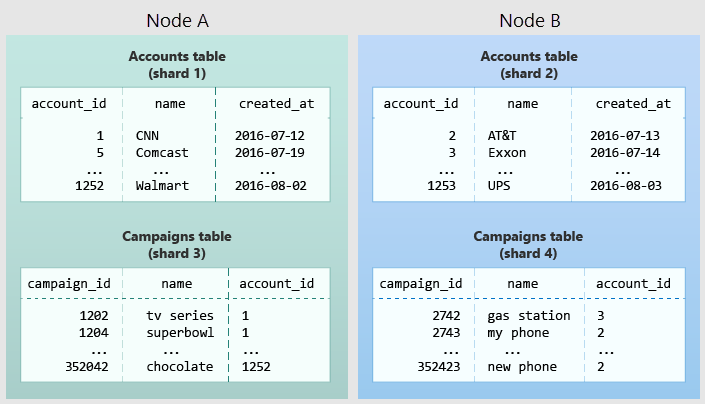
Per applicare questa progettazione nello schema personalizzato, identificare ciò che costituisce un tenant nell'applicazione. Le istanze comuni includono società, account, organizzazione o cliente. Il nome della colonna sarà simile a company_id o customer_id. Esaminare ognuna delle query e chiedersi se abbia più clausole WHERE per limitare tutte le tabelle coinvolte alle righe con lo stesso ID tenant. Le query nel modello multi-tenant hanno come ambito un tenant. Ad esempio, le query sulle vendite o sull'inventario hanno come ambito un determinato negozio.
Procedure consigliate
- Distribuire le tabelle in base a una colonna tenant_id comune. Ad esempio, in un'applicazione SaaS in cui i tenant sono aziende, è probabile che il tenant_id sia il company_id.
- Convertire tabelle tra tenant di piccole dimensioni in tabelle di riferimento. Quando più tenant condividono una piccola tabella di informazioni, distribuirla come tabella di riferimento.
- Limitare il filtro di tutte le query dell'applicazione in base al tenant_id. Ogni query deve richiedere informazioni per un tenant alla volta.
Leggere l'esercitazione multi-tenant per un esempio di come compilare questo tipo di applicazione.
App in tempo reale
L'architettura multi-tenant introduce una struttura gerarchica e usa la coubicazione dei dati per instradare le query per ogni tenant. Al contrario, le architetture in tempo reale dipendono da proprietà di distribuzione specifiche dei dati per ottenere un'elaborazione altamente parallela.
Lo "ID entità" viene usato come termine per le colonne di distribuzione nel modello in tempo reale. Le entità tipiche sono utenti, host o dispositivi.
Le query in tempo reale richiedono in genere aggregazioni numeriche raggruppate per data o categoria. Azure Cosmos DB for PostgreSQL invia queste query a ogni partizione per ottenere risultati parziali e assembla la risposta finale nel nodo coordinatore. Le query vengono eseguite più velocemente quando il maggior numero possibile di nodi contribuisce e quando nessun nodo singolo deve eseguire una quantità sproporzionata di lavoro.
Procedure consigliate
- Scegliere una colonna con cardinalità elevata come colonna di distribuzione. Per un confronto, un campo Stato in una tabella degli ordini con valori Nuovi, Pagati e Spediti rappresenta una scelta non ottimale della colonna di distribuzione. Presuppone solo quei pochi valori, che limitano il numero di partizioni che possono contenere i dati e il numero di nodi che possono elaborarli. Tra le colonne con cardinalità elevata, è anche consigliabile scegliere le colonne usate di frequente nelle clausole di filtro di raggruppamento o come chiavi di join.
- Scegliere una colonna con distribuzione uniforme. Se si distribuisce una tabella in una colonna asimmetrica a determinati valori comuni, i dati nella tabella tendono ad accumularsi in date partizioni. I nodi che contengono tali partizioni finiscono per eseguire più operazioni rispetto ad altri nodi.
- Distribuire tabelle dei fatti e delle dimensioni nelle colonne comuni. La tabella dei fatti può avere una sola chiave di distribuzione. Le tabelle che si uniscono a un'altra chiave non verranno raggruppate con la tabella dei fatti. Scegliere una dimensione da coubicare in base alla frequenza con cui viene unita e alle dimensioni delle righe di join.
- Modificare alcune tabelle delle dimensioni in tabelle di riferimento. Se non è possibile coubicare una tabella delle dimensioni con la tabella dei fatti, è possibile migliorare le prestazioni delle query distribuendo copie della tabella delle dimensioni in tutti i nodi sotto forma di tabella di riferimento.
Leggere l'esercitazione sul dashboard in tempo reale per un esempio di come compilare questo tipo di applicazione.
Dati di serie temporali
In un carico di lavoro di serie temporali, le applicazioni eseguono query sulle informazioni recenti mentre archiviano le informazioni precedenti.
L'errore più comune nella modellazione delle informazioni sulle serie temporali in Azure Cosmos DB for PostgreSQL consiste nell'usare il timestamp stesso come colonna di distribuzione. Una distribuzione hash basata sul tempo distribuisce i tempi apparentemente in modo casuale in partizioni diverse, anziché mantenere gli intervalli di tempo insieme nelle partizioni. Query correlate al tempo generalmente fanno riferimento a intervalli, ad esempio i dati più recenti. Questo tipo di distribuzione hash comporta un sovraccarico di rete.
Procedure consigliate
- Non scegliere un timestamp come colonna di distribuzione. Scegliere una colonna di distribuzione diversa. In un'app multi-tenant usare l'ID tenant, o in un'app in tempo reale usare l'ID entità.
- Usare invece il partizionamento delle tabelle PostgreSQL per il tempo. Usare il partizionamento delle tabelle per suddividere una tabella di grandi dimensioni di dati ordinati in più tabelle ereditate in cui ogni tabella contiene intervalli di tempo diversi. La distribuzione di una tabella partizionata postgres crea partizioni per le tabelle ereditate.
Passaggi successivi
- Apprendere a eseguire la coubicazione tra i dati distribuiti consente l'esecuzione rapida delle query.
- Individuare la colonna di distribuzione di una tabella distribuita e altre query di diagnostica utili.