Come inserire dati usando Azure Data Factory in Azure Cosmos DB for PostgreSQL
SI APPLICA A: ![]() Azure Cosmos DB for PostgreSQL (con tecnologia basata sull'estensione di database Citus per PostgreSQL)
Azure Cosmos DB for PostgreSQL (con tecnologia basata sull'estensione di database Citus per PostgreSQL)
Azure Data Factory è un servizio ETL e di integrazione dati basato sul cloud. Consente di creare flussi di lavoro basati sui dati per spostare e trasformare i dati su larga scala.
Con Data Factory, è possibile creare e pianificare flussi di lavoro basati sui dati (detti pipeline) che inseriscono dati provenienti da archivi diversi. Le pipeline possono essere eseguite in locale, in Azure o in altri provider di servizi cloud per l'analisi e la creazione di report.
Data Factory ha un sink di dati per Azure Cosmos DB for PostgreSQL. Il sink di dati consente di trasferire i dati (relazionali, NoSQL, file data lake) nelle tabelle di Azure Cosmos DB for PostgreSQL per l'archiviazione, l'elaborazione e la creazione di report.
Importante
Attualmente, Data Factory non supporta gli endpoint privati per Azure Cosmos DB for PostgreSQL.
Data Factory per l'inserimento dati in tempo reale
Ecco le ragioni principali per cui scegliere Azure Data Factory per l'inserimento dati in Azure Cosmos DB for PostgreSQL:
- Facile da usare: offre un ambiente visivo senza codice per dirigere e automatizzare lo spostamento dei dati.
- Potente: usa l’intera capacità della larghezza di banda di rete sottostante, fino a 5 GiB/s di velocità effettiva.
- Connettori incorporati: integra tutte le origini dati, con più di 90 connettori incorporati.
- Conveniente: supporta un servizio cloud senza server completamente gestito, con pagamento in base al consumo, ridimensionato su richiesta.
Passaggi per l'uso di Data Factory
In questo articolo verrà creata una pipeline di dati usando l'interfaccia utente di Data Factory. La pipeline in questa data factory copia i dati da un archivio BLOB di Azure a un database. Per un elenco degli archivi dati supportati come origini e sink, vedere la tabella degli archivi dati supportati.
In Data Factory, è possibile usare l'attività Copia per copiare dati tra gli archivi dati che si trovano in locale e nel cloud in Azure Cosmos DB for PostgreSQL. Se non si ha familiarità con Data Factory, ecco una guida rapida su come iniziare:
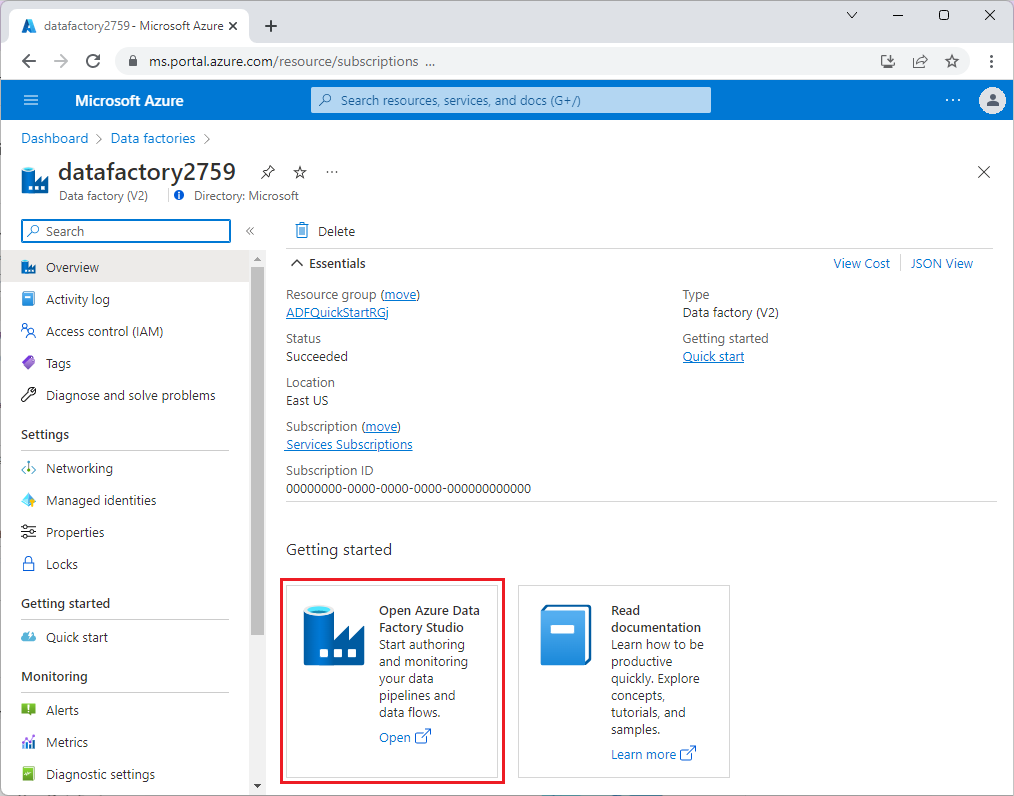
Dopo il provisioning di Data Factory, passare alla data factory e avviare Azure Data Factory Studio. Verrà visualizzata la home page Data factory, come mostrato nell'immagine seguente:
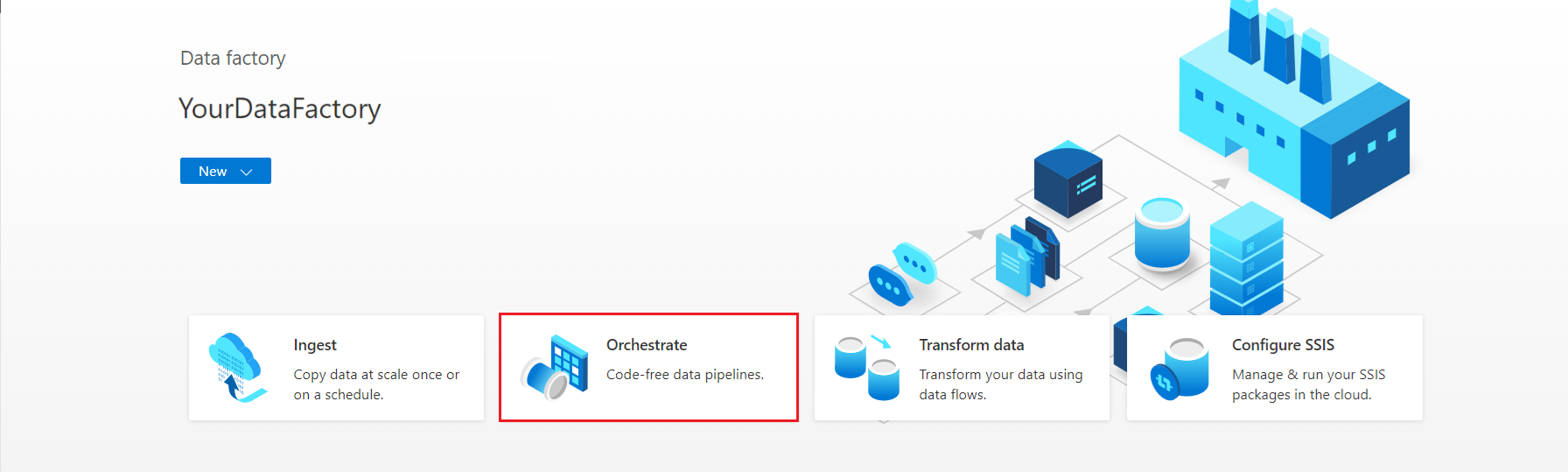
Nella home page di Azure Data Factory Studio, selezionare Dirigi.
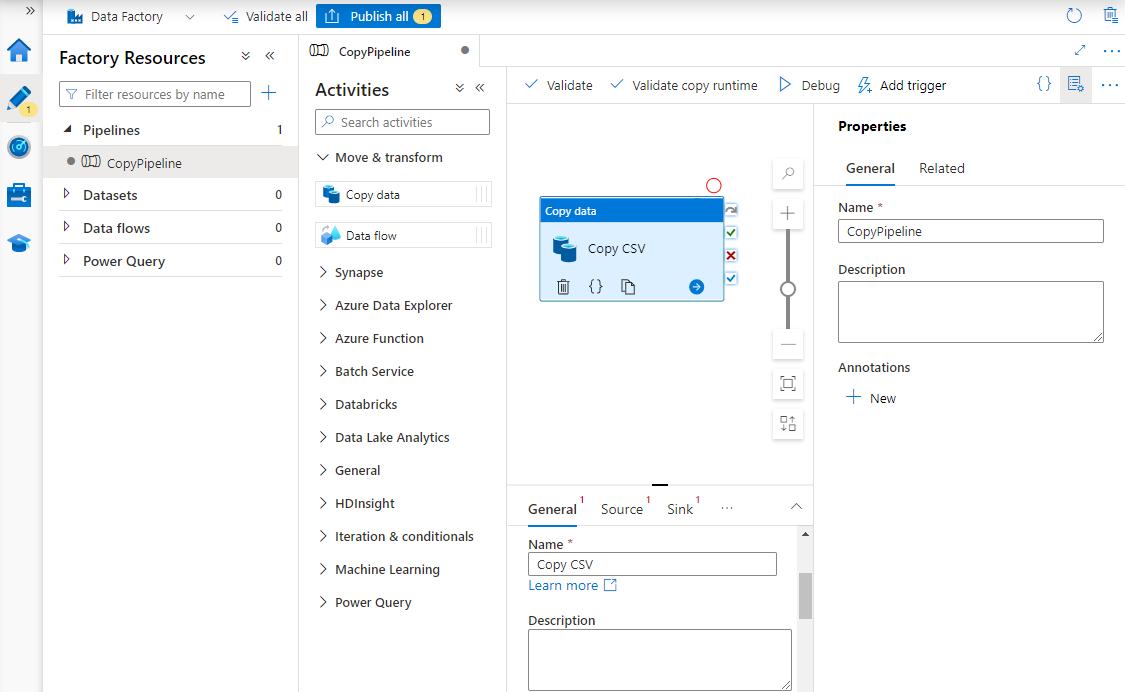
In Proprietà, immettere un nome per la pipeline.
Nella casella degli strumenti Attività. espandere la categoria Sposta e trasforma e trascinare l'attività Copia dati nell'area di progettazione della pipeline. Nella parte inferiore del riquadro della finestra di progettazione, nella scheda Generale, immettere un nome per l'attività di copia.
Configurare Origine.
Nella pagina Attività selezionare la scheda Origine . Selezionare Nuovo per creare un set di dati di origine.
Nella finestra di dialogo Nuovo set di dati selezionare Archiviazione BLOB di Azure e quindi Continua.
Scegliere il tipo di formato dei dati, quindi selezionare Continua.
Nella pagina Imposta proprietà, in Servizio collegato, selezionare Nuovo.
Nella pagina Nuovo servizio collegato, immettere un nome per il servizio collegato e selezionare l'account di archiviazione dall'elenco Nome account di archiviazione.
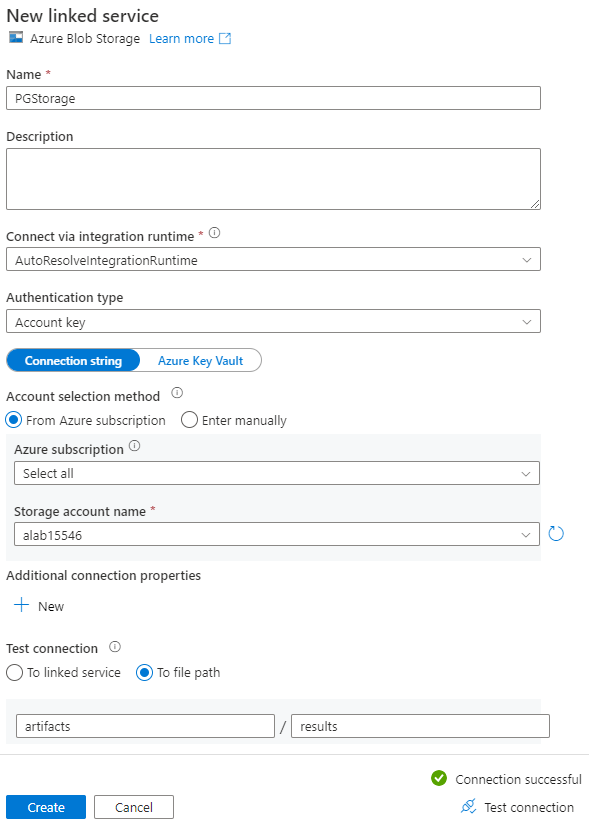
In Connessione di test, selezionare Percorso file, immettere il contenitore e la directory a cui connettersi e quindi selezionare Connessione di test.
Selezionare Crea per salvare la configurazione.
Nella schermata Imposta proprietà, selezionare OK.
Configurare Sink.
Nella pagina Attività. selezionare la scheda Sink. Selezionare Nuovo per creare un set di dati sink.
Nella finestra di dialogo Nuovo set di dati, selezionare Database di Azure for PostgreSQL e quindi Continua .
Nella pagina Imposta proprietà, in Servizio collegato, selezionare Nuovo.
Nella pagina Nuovo servizio collegato, immettere un nome per il servizio collegato e selezionare Immetti manualmente nel Metodo di selezione account.
Immettere il nome coordinatore del cluster nel campo Nome di dominio completo. È possibile copiare il nome del coordinatore dalla pagina Panoramica del cluster Azure Cosmos DB for PostgreSQL.
Lasciare la porta predefinita 5432 nel campo Porta per la connessione diretta al coordinatore o sostituirla con la porta 6432 per connettersi alla porta PgBouncer gestita.
Immettere il nome del database nel cluster e specificare le credenziali per la connessione.
Selezionare SSL nell'elenco a discesa Metodo di crittografia.
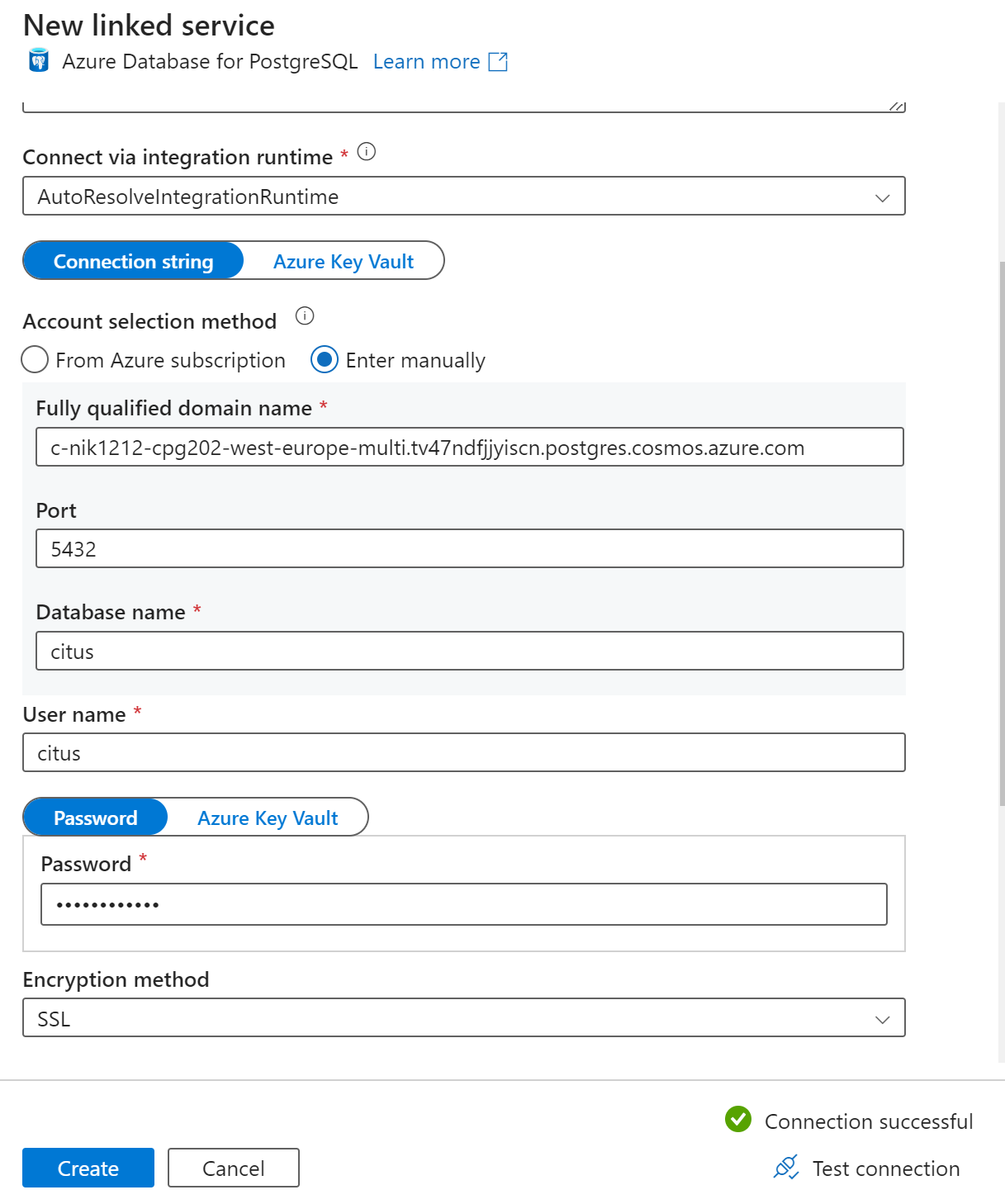
Selezionare Test connessione nella parte inferiore del pannello per convalidare la configurazione del sink.
Selezionare Crea per salvare la configurazione.
Nella schermata Imposta proprietà, selezionare OK.
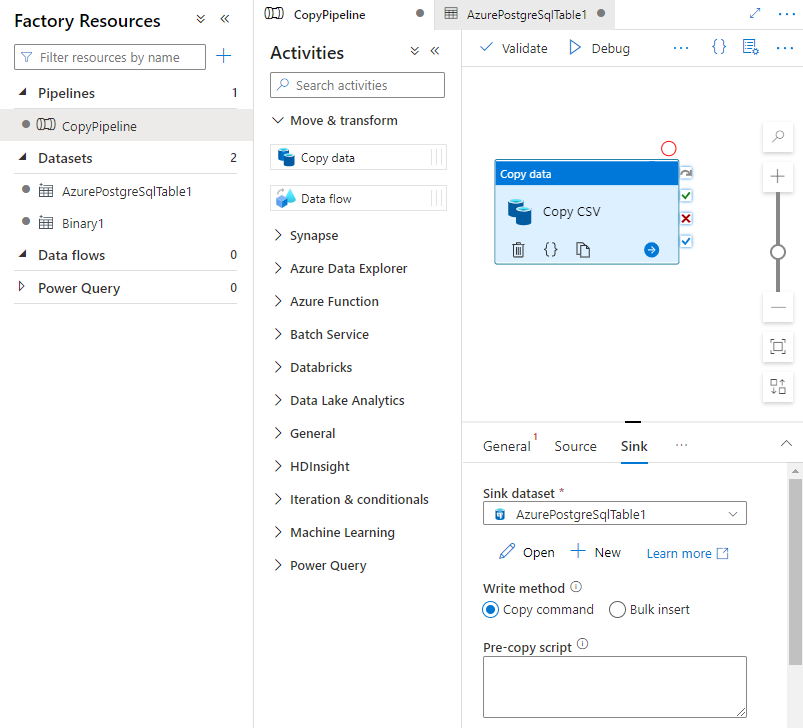
Nella scheda Sink nella pagina Attività, selezionare Apri accanto all'elenco a discesa Set di dati sink e selezionare il nome della tabella nel cluster di destinazione in cui si desidera inserire i dati.
In Metodo di scrittura, selezionare Copia comando.
Sulla barra degli strumenti sopra il pannello Canvas, selezionare Convalida per convalidare le impostazioni della pipeline. Correggere eventuali errori, riconvalidare e verificare che la pipeline sia stata convalidata correttamente.
Selezionare Debug sulla barra degli strumenti per eseguire la pipeline.
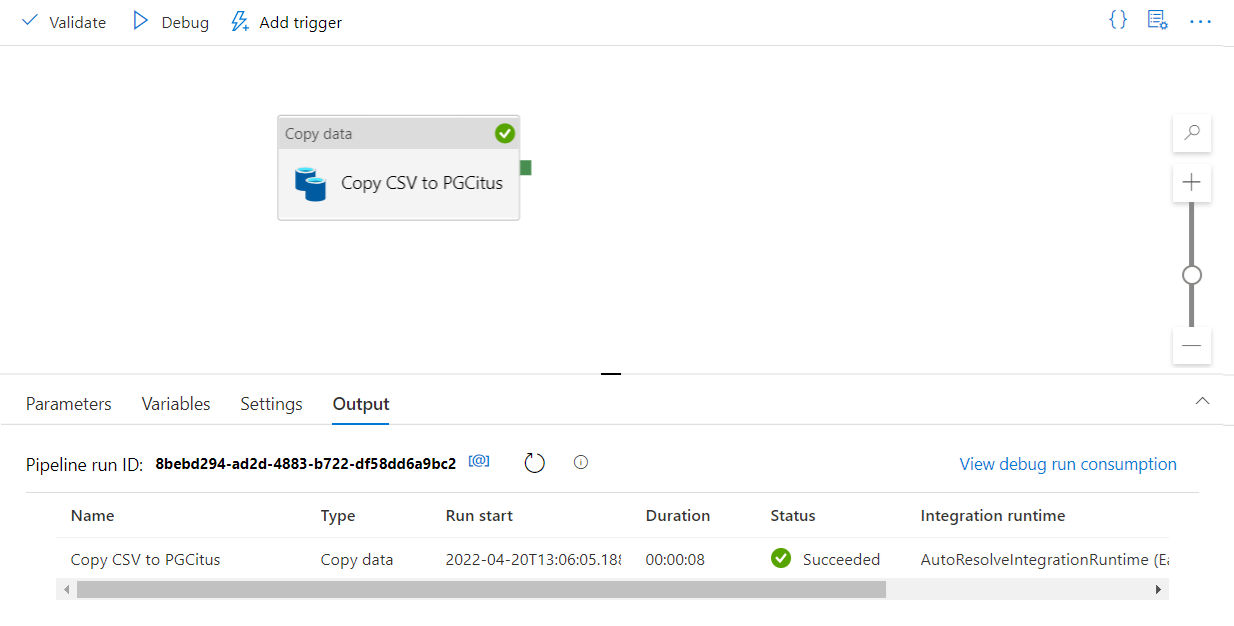
Quando è possibile eseguire correttamente la pipeline, nella barra degli strumenti superiore selezionare Pubblica tutto. Questa azione pubblica le entità create (set di dati e pipeline) in Data Factory.
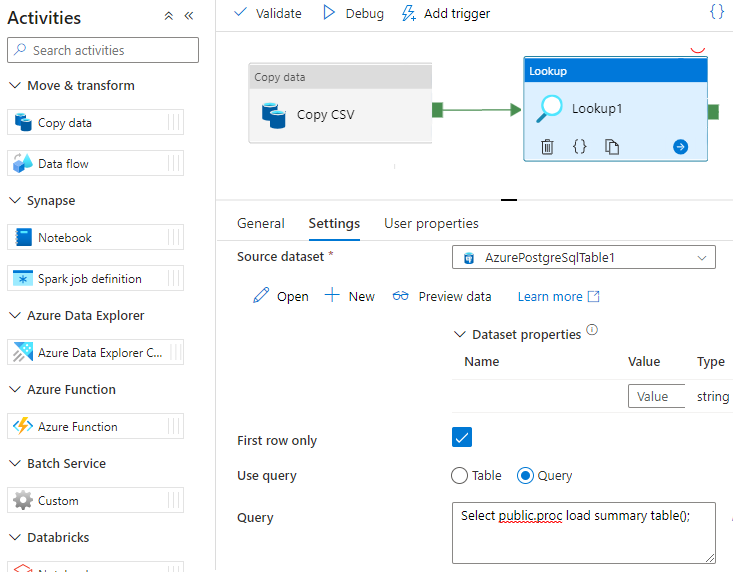
Chiamare una stored procedure in Data Factory
In alcuni scenari specifici, è possibile chiamare una stored procedure o una funzione per eseguire il push dei dati aggregati dalla tabella di staging alla tabella di riepilogo. Data Factory non offre un'attività stored procedure per Azure Cosmos DB for PostgreSQL, ma come soluzione alternativa è possibile usare l'attività Lookup con una query per chiamare una stored procedure, come illustrato di seguito:
Passaggi successivi
- Informazioni su come creare dashboard in tempo reale con Azure Cosmos DB for PostgreSQL.
- Informazioni su come spostare il carico di lavoro in Azure Cosmos DB for PostgreSQL