Copiare dati in un indice di Azure AI Search usando Azure Data Factory o Synapse Analytics
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questo articolo illustra come usare l'attività Copy in una pipeline di Azure Data Factory o Synapse Analytics per copiare i dati nell'indice di Azure AI Search. Si basa sull'articolo di panoramica dell'attività di copia che presenta una panoramica generale sull'attività di copia.
Funzionalità supportate
Questo connettore di Azure AI Search è supportato per le funzionalità seguenti:
| Funzionalità supportate | IR | Endpoint privato gestito |
|---|---|---|
| Attività Copy: (-/sink) | ① ② | ✓ |
① Runtime di integrazione di Azure ② Runtime di integrazione self-hosted
È possibile copiare dati da qualsiasi archivio dati di origine supportato nell'indice di ricerca. Per un elenco degli archivi dati supportati come origini/sink dall'attività di copia, vedere la tabella relativa agli archivi dati supportati.
Introduzione
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o SDK seguenti:
- Strumento Copia dati
- Il portale di Azure
- .NET SDK
- SDK di Python
- Azure PowerShell
- API REST
- Modello di Azure Resource Manager
Creare un servizio collegato a Ricerca di Azure usando l'interfaccia utente
Usare la procedura seguente per creare un servizio collegato a Ricerca di Azure nell'interfaccia utente del portale di Azure.
Passare alla scheda Gestisci nell'area di lavoro di Azure Data Factory o Synapse e selezionare Servizi collegati, quindi fare clic su Nuovo:
Cercare Ricerca e selezionare il connettore Ricerca di Azure.
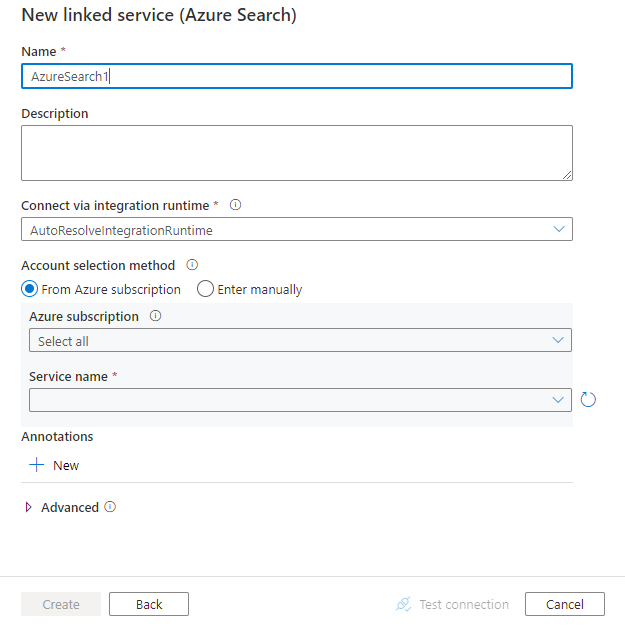
Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
Dettagli di configurazione del connettore
Le sezioni seguenti forniscono informazioni dettagliate sulle proprietà usate per definire entità di Data Factory specifiche del connettore di Azure AI Search.
Proprietà del servizio collegato
Per il servizio collegato di Azure AI Search sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type deve essere impostata su AzureSearch | Sì |
| URL. | URL per il servizio di ricerca. | Sì |
| key | Chiave amministratore del servizio ricerca. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro oppure fare riferimento a un segreto archiviato in Azure Key Vault. | Sì |
| connectVia | Il runtime di integrazione da usare per la connessione all'archivio dati. È possibile usare il runtime di integrazione di Azure o il runtime di integrazione self-hosted (se l'archivio dati si trova in una rete privata). Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | No |
Importante
Quando si copiano dati da un archivio dati cloud nell'indice di ricerca, nel servizio collegato di Azure AI Search è necessario fare riferimento a un runtime di integrazione di Azure con area esplicita in connactVia. Impostare l'area come quella in cui risiede il servizio di ricerca. Altre informazioni da Azure Integration Runtime.
Esempio:
{
"name": "AzureSearchLinkedService",
"properties": {
"type": "AzureSearch",
"typeProperties": {
"url": "https://<service>.search.windows.net",
"key": {
"type": "SecureString",
"value": "<AdminKey>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione di set di dati, vedere l'articolo sui set di dati. Questa sezione presenta un elenco delle proprietà supportate dal set di dati Azure AI Search.
Per copiare i dati in Azure AI Search, sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del set di dati deve essere impostata su: AzureSearchIndex | Sì |
| indexName | Nome dell'indice di ricerca. Il servizio non crea l'indice. L'indice deve essere presente in Azure AI Search. | Sì |
Esempio:
{
"name": "AzureSearchIndexDataset",
"properties": {
"type": "AzureSearchIndex",
"typeProperties" : {
"indexName": "products"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Azure AI Search linked service name>",
"type": "LinkedServiceReference"
}
}
}
Proprietà dell'attività di copia
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere l'articolo sulle pipeline. Questa sezione fornisce un elenco delle proprietà supportate dall'origine Azure AI Search.
Azure AI Search come sink
Per copiare dati in Azure AI Search, impostare il tipo di origine nell'attività Copy su AzureSearchIndexSink. Nella sezione sink dell'attività di copia sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type dell'origine dell'attività di copia deve essere impostata su: AzureSearchIndexSink | Sì |
| writeBehavior | Specifica se eseguire un'unione o una sostituzione quando nell'indice esiste già un documento. Vedere la proprietà WriteBehavior. I valori consentiti sono: Merge (predefinito) e Carica. |
No |
| writeBatchSize | Consente di caricare dati nell'indice di ricerca quando le dimensioni del buffer raggiungono il valore indicato da writeBatchSize. Per informazioni dettagliate, vedere la proprietà WriteBatchSize. I valori consentiti sono: integer da 1 a 1.000; il valore predefinito è 1000. |
No |
| maxConcurrentConnections | Limite massimo di connessioni simultanee stabilite all'archivio dati durante l'esecuzione dell'attività. Specificare un valore solo quando si desidera limitare le connessioni simultanee. | No |
Proprietà WriteBehavior
Durante la scrittura di dati, AzureSearchSink esegue operazioni di upsert. In altre parole, quando si scrive un documento il servizio ricerca aggiorna il documento esistente anziché generare un'eccezione di conflitto se la chiave relativa esiste già nell'indice di Azure AI Search.
Le operazioni di upsert eseguite da AzureSearchSink sono le seguenti (con AzureSearch SDK):
- Merge: le colonne del nuovo documento vengono unite con quelle del documento esistente. Per le colonne del nuovo documento con valore Null, viene mantenuto il valore del documento esistente.
- Upload: il nuovo documento sostituisce quello esistente. Per le colonne del nuovo documento non specificate, il valore è impostato su Null indipendentemente dalla presenza o meno di un valore diverso da Null nel documento esistente.
L'operazione predefinita è Merge.
Proprietà WriteBatchSize
Il servizio Azure AI Search supporta la scrittura di documenti come batch. Un batch può contenere da 1 a 1000 azioni e un'azione gestisce un documento per eseguire l'operazione di caricamento/unione.
Esempio:
"activities":[
{
"name": "CopyToAzureSearch",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure AI Search output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSearchIndexSink",
"writeBehavior": "Merge"
}
}
}
]
Supporto dei tipi di dati
La tabella seguente indica se un tipo di dati di Azure AI Search è supportato o meno.
| Tipo di dati di Azure AI Search | Supportato nel sink di Azure AI Search |
|---|---|
| String | Y |
| Int32 | Y |
| Int64 | Y |
| Double | Y |
| Booleano | Y |
| DataTimeOffset | Y |
| String Array | N |
| GeographyPoint | N |
Attualmente non sono supportati altri tipi di dati, ad esempio ComplexType. Per un elenco completo dei tipi di dati supportati da Azure AI Search, vedere Tipi di dati supportati (Azure AI Search).
Contenuto correlato
Per un elenco degli archivi dati supportati come origini e sink dall'attività Copy, vedere Archivi dati supportati.