Usare i parametri personalizzati con il modello di Resource Manager
SI APPLICA A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Se l'istanza di sviluppo ha un repository Git associato, è possibile eseguire l'override dei parametri predefiniti del modello di Resource Manager generato pubblicando o esportando il modello. È possibile eseguire l'override della configurazione predefinita dei parametri di Resource Manager in questi scenari:
Si usano CI/CD automatizzati e si desidera modificare alcune proprietà durante la distribuzione di Resource Manager, ma le proprietà non sono parametrizzate per impostazione predefinita.
La factory è talmente grande che il modello di Resource Manager predefinito non è valido perché contiene più del numero massimo di parametri consentito (256).
Per gestire il limite personalizzato del parametro 256, sono disponibili tre opzioni:
- Usare il file di parametri personalizzato e rimuovere le proprietà che non richiedono parametrizzazione, ovvero le proprietà che possono mantenere un valore predefinito e quindi ridurre il numero di parametri.
- La logica di refactoring nel flusso di dati per ridurre i parametri, ad esempio i parametri della pipeline hanno tutti lo stesso valore. È invece possibile usare i parametri globali.
- Dividere una data factory in più data factory.
Per eseguire l'override della configurazione predefinita dei parametri di Resource Manager, passare all'hub di gestione e selezionare il modello arm nella sezione "Controllo del codice sorgente". Nella sezione Configurazione dei parametri arm selezionare l'icona Modifica in "Modifica configurazione dei parametri" per aprire l'editor del codice di configurazione dei parametri di Resource Manager.
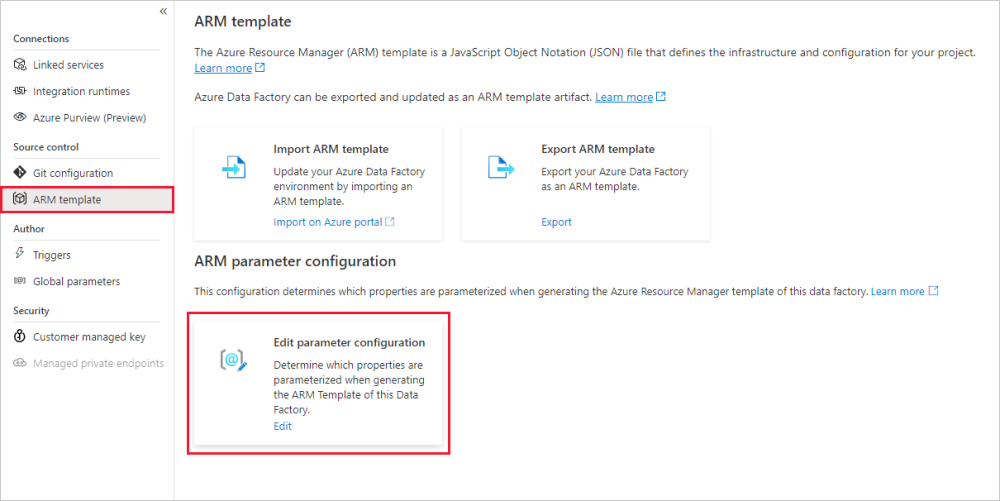
Nota
La configurazione dei parametri ARM è abilitata solo in "modalità GIT". Attualmente è disabilitato in modalità "live" o "Data Factory".
La creazione di una configurazione personalizzata dei parametri di Resource Manager crea un file denominato arm-template-parameters-definition.json nella cartella radice del ramo Git. È necessario usare il nome file esatto.
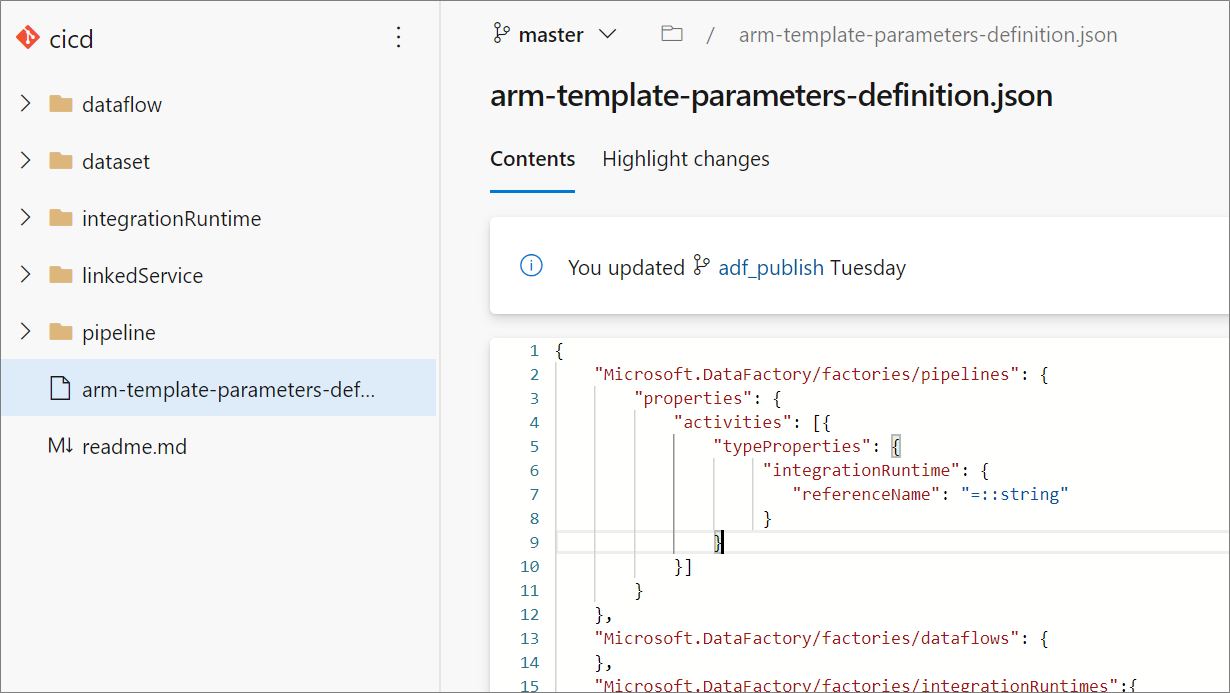
Quando si esegue la pubblicazione dal ramo di collaborazione, Data Factory legge questo file e usa la configurazione per generare quali proprietà vengono parametrizzate. Se non viene trovato alcun file, viene usato il modello predefinito.
Quando si esporta un modello di Resource Manager, Data Factory legge questo file da qualsiasi ramo in cui ci si trova attualmente e non dal ramo di collaborazione. È possibile creare o modificare il file da un ramo privato, in cui è possibile testare le modifiche selezionando Esporta modello ARM nell'interfaccia utente. È quindi possibile unire il file nel ramo di collaborazione.
Nota
Una configurazione personalizzata dei parametri di Resource Manager non modifica il limite di parametri del modello di Resource Manager pari a 256. Consente di scegliere e diminuire il numero di proprietà con parametri.
Sintassi dei parametri personalizzata
Di seguito sono riportate alcune linee guida da seguire quando si crea il file di parametri personalizzati arm-template-parameters-definition.json. Il file è costituito da una sezione per ogni tipo di entità: trigger, pipeline, servizio collegato, set di dati, runtime di integrazione e flusso di dati.
- Immettere il percorso della proprietà nel tipo di entità pertinente.
- L'impostazione di un nome di proprietà su
*indica che si vogliono parametrizzare tutte le proprietà al suo interno (solo fino al primo livello, non in modo ricorsivo). È anche possibile fornire eccezioni a questa configurazione. - Quando si imposta il valore di una proprietà come stringa, si indica che si vuole parametrizzare la proprietà. Usare il formato
<action>:<name>:<stype>.-
<action>può essere uno di questi caratteri:-
=specifica di mantenere il valore corrente come valore predefinito per il parametro. -
-specifica di non mantenere il valore predefinito per il parametro. -
|è un caso speciale per i segreti di Azure Key Vault per stringhe di connessione o chiavi.
-
-
<name>è il nome del parametro. Se è vuoto, viene usato il nome della proprietà. Se il valore inizia con un carattere-, il nome viene abbreviato. Ad esempio,AzureStorage1_properties_typeProperties_connectionStringviene abbreviato inAzureStorage1_connectionString. -
<stype>è il tipo di parametro. Se<stype>è vuoto e il tipo predefinito èstring. Valori supportati:string,securestring,int,bool,object,secureobjectearray.
-
- Quando si specifica una matrice nel file di definizione, si indica che la proprietà corrispondente nel modello è una matrice. Data Factory esegue l'iterazione tra tutti gli oggetti della matrice usando la definizione specificata nell'oggetto runtime di integrazione della matrice. Il secondo oggetto, una stringa, diventa il nome della proprietà, che viene usato come nome per il parametro per ogni iterazione.
- Una definizione non può essere specifica di un'istanza di risorsa. Qualunque definizione viene applicata a tutte le risorse di quel tipo.
- Per impostazione predefinita, vengono parametrizzate tutte le stringhe sicure, ad esempio i segreti di Key Vault, e le stringhe sicure, ad esempio le stringhe di connessione, le chiavi e i token.
Modello di parametrizzazione di esempio
Di seguito è riportato un esempio dell'aspetto di una configurazione dei parametri di Resource Manager. Contiene esempi di molti possibili utilizzi, tra cui la parametrizzazione delle attività annidate all'interno di una pipeline e la modifica del valore defaultValue di un parametro del servizio collegato.
{
"Microsoft.DataFactory/factories/pipelines": {
"properties": {
"activities": [{
"typeProperties": {
"waitTimeInSeconds": "-::int",
"headers": "=::object",
"activities": [
{
"typeProperties": {
"url": "-:-webUrl:string"
}
}
]
}
}]
}
},
"Microsoft.DataFactory/factories/integrationRuntimes": {
"properties": {
"typeProperties": {
"*": "="
}
}
},
"Microsoft.DataFactory/factories/triggers": {
"properties": {
"typeProperties": {
"recurrence": {
"*": "=",
"interval": "=:triggerSuffix:int",
"frequency": "=:-freq"
},
"maxConcurrency": "="
}
}
},
"Microsoft.DataFactory/factories/linkedServices": {
"*": {
"properties": {
"typeProperties": {
"accountName": "=",
"username": "=",
"connectionString": "|:-connectionString:secureString",
"secretAccessKey": "|"
}
}
},
"AzureDataLakeStore": {
"properties": {
"typeProperties": {
"dataLakeStoreUri": "="
}
}
},
"AzureKeyVault": {
"properties": {
"typeProperties": {
"baseUrl": "|:baseUrl:secureString"
},
"parameters": {
"KeyVaultURL": {
"type": "=",
"defaultValue": "|:defaultValue:secureString"
}
}
}
}
},
"Microsoft.DataFactory/factories/datasets": {
"*": {
"properties": {
"typeProperties": {
"folderPath": "=",
"fileName": "="
}
}
}
},
"Microsoft.DataFactory/factories/credentials" : {
"properties": {
"typeProperties": {
"resourceId": "="
}
}
}
}
Di seguito è riportata una spiegazione del modo in cui viene costruito il modello precedente, suddiviso per tipo di risorsa.
Pipeline
- Qualunque proprietà nel percorso
activities/typeProperties/waitTimeInSecondsè parametrizzata. Qualunque attività in una pipeline che dispone di una proprietà a livello di codice denominatawaitTimeInSeconds(ad esempio, l'attivitàWait) viene parametrizzata come numero, con un nome predefinito. Non avrà tuttavia un valore predefinito nel modello di Resource Manager. È un input obbligatorio durante la distribuzione di Resource Manager. - Analogamente, una proprietà denominata
headers(ad esempio, in un'attivitàWeb) viene parametrizzata con il tipoobject(JObject). Ha un valore predefinito, che è lo stesso valore di quello della factory di origine.
IntegrationRuntimes
- Tutte le proprietà nel percorso
typePropertiesvengono parametrizzate con i rispettivi valori predefiniti. Esistono ad esempio due proprietà nelle proprietà del tipoIntegrationRuntimes:computePropertiesessisProperties. Entrambi i tipi di proprietà vengono creati con i rispettivi valori e tipi predefiniti (oggetto).
Trigger
- In
typeProperties, sono parametrizzate due proprietà. La prima èmaxConcurrency, che è specificata per avere un valore predefinito ed è di tipostring. Ha il nome di parametro predefinito<entityName>_properties_typeProperties_maxConcurrency. - Anche la proprietà
recurrenceè parametrizzata. Al suo interno, tutte le proprietà a tale livello vengono specificate per essere parametrizzate come stringhe, con valori predefiniti e nomi di parametro. Un'eccezione è la proprietàinterval, che è parametrizzata come tipoint. Il nome del parametro ha il suffisso<entityName>_properties_typeProperties_recurrence_triggerSuffix. Analogamente, la proprietàfreqè una stringa e viene parametrizzata come stringa. Tuttavia, la proprietàfreqè parametrizzata senza un valore predefinito. Il nome viene abbreviato e seguito da un suffisso. Ad esempio:<entityName>_freq.
LinkedServices
- I servizi collegati sono univoci. Poiché i servizi collegati e i set di dati hanno un'ampia gamma di tipi, è possibile fornire una personalizzazione specifica del tipo. In questo esempio, per tutti i servizi collegati di tipo
AzureDataLakeStore, viene applicato un modello specifico. Per tutti gli altri (tramite*), viene applicato un modello diverso. - La proprietà
connectionStringviene parametrizzata come valoresecurestring. Non avrà un valore predefinito. Ha un nome di parametro abbreviato suffisso conconnectionString. - La proprietà
secretAccessKeyè unAzureKeyVaultSecret, ad esempio in un servizio collegato Amazon S3. Viene parametrizzata automaticamente come segreto di Azure Key Vault e recuperata dall'insieme di credenziali delle chiavi configurato. È anche possibile parametrizzare l'insieme di credenziali delle chiavi stesso.
Set di dati
- Sebbene la personalizzazione specifica del tipo sia disponibile per i set di dati, è possibile fornire la configurazione senza avere in modo esplicito una configurazione a livello di *. Nell'esempio precedente, vengono parametrizzate tutte le proprietà del set di dati in
typeProperties.
Nota
Se gli avvisi e le matrici di Azure sono configurati per una pipeline, non sono attualmente supportati come parametri per le distribuzioni di modelli di Resource Manager. Per riapplicare gli avvisi e le matrici in un nuovo ambiente, seguire Monitoraggio, Avvisi e Matrici di Data Factory.
Modello di parametrizzazione predefinito
Di seguito è riportato il modello di parametrizzazione predefinito corrente. Se è necessario aggiungere solo alcuni parametri, la modifica diretta di questo modello potrebbe essere opportuna, perché non si perderà la struttura di parametrizzazione esistente.
{
"Microsoft.DataFactory/factories": {
"properties": {
"globalParameters": {
"*": {
"value": "="
}
}
},
"location": "="
},
"Microsoft.DataFactory/factories/globalparameters": {
"properties": {
"*": {
"value": "="
}
}
},
"Microsoft.DataFactory/factories/pipelines": {
},
"Microsoft.DataFactory/factories/dataflows": {
},
"Microsoft.DataFactory/factories/integrationRuntimes":{
"properties": {
"typeProperties": {
"ssisProperties": {
"catalogInfo": {
"catalogServerEndpoint": "=",
"catalogAdminUserName": "=",
"catalogAdminPassword": {
"value": "-::secureString"
}
},
"customSetupScriptProperties": {
"sasToken": {
"value": "-::secureString"
}
}
},
"linkedInfo": {
"key": {
"value": "-::secureString"
},
"resourceId": "="
},
"computeProperties": {
"dataFlowProperties": {
"externalComputeInfo": [{
"accessToken": "-::secureString"
}
]
}
}
}
}
},
"Microsoft.DataFactory/factories/triggers": {
"properties": {
"pipelines": [{
"parameters": {
"*": "="
}
}
],
"pipeline": {
"parameters": {
"*": "="
}
},
"typeProperties": {
"scope": "="
}
}
},
"Microsoft.DataFactory/factories/linkedServices": {
"*": {
"properties": {
"typeProperties": {
"accountName": "=",
"username": "=",
"userName": "=",
"accessKeyId": "=",
"servicePrincipalId": "=",
"userId": "=",
"host": "=",
"clientId": "=",
"clusterUserName": "=",
"clusterSshUserName": "=",
"hostSubscriptionId": "=",
"clusterResourceGroup": "=",
"subscriptionId": "=",
"resourceGroupName": "=",
"tenant": "=",
"dataLakeStoreUri": "=",
"baseUrl": "=",
"database": "=",
"serviceEndpoint": "=",
"batchUri": "=",
"poolName": "=",
"databaseName": "=",
"systemNumber": "=",
"server": "=",
"url":"=",
"functionAppUrl":"=",
"environmentUrl": "=",
"aadResourceId": "=",
"sasUri": "|:-sasUri:secureString",
"sasToken": "|",
"connectionString": "|:-connectionString:secureString",
"hostKeyFingerprint": "="
}
}
},
"Odbc": {
"properties": {
"typeProperties": {
"userName": "=",
"connectionString": {
"secretName": "="
}
}
}
}
},
"Microsoft.DataFactory/factories/datasets": {
"*": {
"properties": {
"typeProperties": {
"folderPath": "=",
"fileName": "="
}
}
}
},
"Microsoft.DataFactory/factories/managedVirtualNetworks/managedPrivateEndpoints": {
"properties": {
"*": "="
}
}
}
Esempio: Parametrizzazione di un ID cluster interattivo di Azure Databricks esistente
L'esempio seguente illustra come aggiungere un singolo valore al modello di parametrizzazione predefinito. Si vuole aggiungere solo un ID cluster interattivo Azure Databricks esistente per un servizio collegato Databricks al file dei parametri. Questo file è uguale al file precedente, ad eccezione dell'aggiunta di existingClusterId nel campo delle proprietà di Microsoft.DataFactory/factories/linkedServices.
{
"Microsoft.DataFactory/factories": {
"properties": {
"globalParameters": {
"*": {
"value": "="
}
}
},
"location": "="
},
"Microsoft.DataFactory/factories/pipelines": {
},
"Microsoft.DataFactory/factories/dataflows": {
},
"Microsoft.DataFactory/factories/integrationRuntimes":{
"properties": {
"typeProperties": {
"ssisProperties": {
"catalogInfo": {
"catalogServerEndpoint": "=",
"catalogAdminUserName": "=",
"catalogAdminPassword": {
"value": "-::secureString"
}
},
"customSetupScriptProperties": {
"sasToken": {
"value": "-::secureString"
}
}
},
"linkedInfo": {
"key": {
"value": "-::secureString"
},
"resourceId": "="
}
}
}
},
"Microsoft.DataFactory/factories/triggers": {
"properties": {
"pipelines": [{
"parameters": {
"*": "="
}
}
],
"pipeline": {
"parameters": {
"*": "="
}
},
"typeProperties": {
"scope": "="
}
}
},
"Microsoft.DataFactory/factories/linkedServices": {
"*": {
"properties": {
"typeProperties": {
"accountName": "=",
"username": "=",
"userName": "=",
"accessKeyId": "=",
"servicePrincipalId": "=",
"userId": "=",
"clientId": "=",
"clusterUserName": "=",
"clusterSshUserName": "=",
"hostSubscriptionId": "=",
"clusterResourceGroup": "=",
"subscriptionId": "=",
"resourceGroupName": "=",
"tenant": "=",
"dataLakeStoreUri": "=",
"baseUrl": "=",
"database": "=",
"serviceEndpoint": "=",
"batchUri": "=",
"poolName": "=",
"databaseName": "=",
"systemNumber": "=",
"server": "=",
"url":"=",
"aadResourceId": "=",
"connectionString": "|:-connectionString:secureString",
"existingClusterId": "-"
}
}
},
"Odbc": {
"properties": {
"typeProperties": {
"userName": "=",
"connectionString": {
"secretName": "="
}
}
}
}
},
"Microsoft.DataFactory/factories/datasets": {
"*": {
"properties": {
"typeProperties": {
"folderPath": "=",
"fileName": "="
}
}
}}
}
Contenuto correlato
- Panoramica dell’integrazione e del recapito continuo
- Automatizzare l'integrazione continua usando le versioni di Azure Pipelines
- Alzare di livello manualmente un modello di Resource Manager per ogni ambiente
- Modelli di Resource Manager collegati
- Uso di un ambiente di produzione hotfix
- Esempio di script di pre-distribuzione e post-distribuzione