Formato testo delimitato in Azure Data Factory e Azure Synapse Analytics
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Seguire questo articolo quando si desidera analizzare i file di testo delimitati o scrivere i dati in formato testo delimitato.
Il formato testo delimitato è supportato per i connettori seguenti:
- Amazon S3
- Archiviazione compatibile con Amazon S3
- BLOB di Azure
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- File di Azure
- File system
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Archiviazione in Oracle Cloud
- SFTP
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione dei set di dati, vedere l'articolo Set di dati. In questa sezione viene fornito un elenco delle proprietà supportate dal set di dati di testo delimitato.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà Tipo del set di dati deve essere impostata su DelimitedText. | Sì |
| location | Impostazioni di posizione dei file. Ogni connettore basato su file ha il proprio tipo di percorso e le proprietà supportate in location. |
Sì |
| columnDelimiter | I caratteri usati per separare le colonne in un file. Il valore predefinito è la virgola ,. Quando il delimitatore di colonna è definito come stringa vuota, ovvero nessun delimitatore, l'intera riga viene considerata come una singola colonna.Attualmente, il delimitatore di colonna come stringa vuota è supportato solo per il flusso di dati di mapping, ma non per l'attività Copy. |
No |
| rowDelimiter | Per l'attività Copy, il carattere singolo o "\r\n" usato per separare le righe in un file. Sono consentiti i seguenti valori in lettura: ["\r\n", "\r", "\n"]; "\r\n" in scrittura. "\r\n" è supportato solo nel comando di copia. Per Flusso di dati di mapping, i caratteri singoli o due usati per separare le righe in un file. Sono consentiti i seguenti valori in lettura: ["\r\n", "\r", "\n"]; "\n" in scrittura. Quando il delimitatore di riga è impostato su nessun delimitatore (stringa vuota), anche il delimitatore di colonna deve essere impostato come nessun delimitatore (stringa vuota), il che significa trattare l'intero contenuto come un singolo valore. Attualmente, il delimitatore di riga come stringa vuota è supportato solo per il flusso di dati di mapping, ma non per l'attività Copy. |
No |
| quoteChar | Carattere singolo da racchiudere i valori di colonna tra virgolette se contiene il delimitatore di colonna. Il valore predefinito è doppie virgolette ". Quando quoteChar viene definita come stringa vuota, significa che non vi sono char virgolette e il valore della colonna non è racchiuso tra virgolette e escapeChar viene usato per eseguire l'escape del delimitatore di colonna e stesso. |
No |
| escapeChar | Carattere singolo per saltare le virgolette all'interno di un valore tra virgolette. Il valore predefinito è barra rovesciata \. Quando escapeChar è definito come stringa vuota, quoteChar deve essere impostato anche come stringa vuota, nel qual caso assicurarsi che tutti i valori di colonna non contengano delimitatori. |
No |
| firstRowAsHeader | Specifica se trattare o impostare la prima riga come riga di intestazione con nomi di colonne. I valori consentiti sono True e False (predefinito). Quando la prima riga come intestazione è false, si noti che l'anteprima dei dati dell'interfaccia utente e l'output dell'attività di ricerca generano automaticamente nomi di colonna come Prop_{n} (a partire da 0), l'attività Copy richiede il mapping esplicito dall'origine al sink e individua le colonne in base all’ordinale (a partire da 1) e gli elenchi dei flussi di dati per mapping e individua le colonne dal nome Colonna_{n} (a partire da 1). |
No |
| nullValue | Specifica la rappresentazione di stringa del valore Null. Il valore predefinito è stringa vuota. |
No |
| encodingName | Tipo di codifica usato per leggere/scrivere file di test. I valori consentiti sono i seguenti: "UTF-8","UTF-8 senza BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258". Si noti che il flusso di dati per mapping non supporta la codifica UTF-7. Si noti che il flusso di dati per mapping non supporta la codifica UTF-8 con byte Order Mark (BOM). |
No |
| compressionCodec | Codec di compressione usato per leggere/scrivere file di testo. I valori consentiti sono bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappyo lz4. Il valore predefinito non è compresso. Nota attualmente l'attività Copy non supporta "snappy" & "lz4" e il flusso di dati di mapping non supporta "ZipDeflate", "TarGzip" e "Tar". Nota quando si usa l'attività Copy per decomprimere i file ZipDeflate/TarGzip/Tar e scrivere nell'archivio dati sink basato su file, per impostazione predefinita i file vengono estratti nella cartella: <path specified in dataset>/<folder named as source compressed file>/, usare preserveZipFileNameAsFolder/preserveCompressionFileNameAsFolder su origine attività Copy per controllare se mantenere il nome dei file compressi come struttura di cartelle. |
No |
| compressionLevel | Rapporto di compressione. I valori consentiti sono ottimale o più veloce. - Fastest: l'operazione di compressione deve essere completata il più rapidamente possibile, anche se il file risultante non viene compresso in modo ottimale. - Optimal: l'operazione di compressione deve comprimere il file in modo ottimale, anche se il completamento richiede più tempo. Per maggiori informazioni, vedere l'argomento relativo al livello di compressione . |
No |
Di seguito è riportato un esempio di set di dati di testo delimitato in Archiviazione BLOB di Azure:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"columnDelimiter": ",",
"quoteChar": "\"",
"escapeChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Proprietà dell'attività di copia
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere l'articolo sulle pipeline. In questa sezione viene fornito un elenco di proprietà supportate dall'origine e dal sink di testo delimitati.
Testo delimitato come origine
Nella sezione *source* dell'attività Copy sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà Tipo dell'origine dell'attività Copy deve essere impostata su DelimitedTextSource. | Sì |
| formatSettings | Gruppo di proprietà. Fare riferimento alla tabella Impostazioni di lettura testo delimitato di seguito. | No |
| storeSettings | Gruppo di proprietà su come leggere i dati da un archivio dati. Ogni connettore basato su file dispone di impostazioni di lettura proprie supportate in storeSettings. |
No |
Impostazioni di lettura testo delimitato supportate in formatSettings:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | Il tipo di formatSettings deve essere impostato su DelimitedTextReadSettings. | Sì |
| skipLineCount | Indica il numero di righe non vuote da ignorare durante la lettura di dati da file di input. Se vengono specificati sia skipLineCount che firstRowAsHeader, le righe vengono ignorate e quindi le informazioni dell'intestazione vengono lette dal file di input. |
No |
| compressionProperties | Gruppo di proprietà su come decomprimere i dati per un determinato codec di compressione. | No |
| preserveZipFileNameAsFolder (in compressionProperties->type come ZipDeflateReadSettings) |
Si applica quando il set di dati di input è configurato con compressione ZipDeflate. Indica se mantenere il nome del file ZIP di origine come struttura di cartelle durante la copia. - Se impostato su true (impostazione predefinita), il servizio scrive i file decompressi in <path specified in dataset>/<folder named as source zip file>/.- Se impostato su false, il servizio scrive i file decompressi direttamente in <path specified in dataset>. Assicurarsi di non avere nomi di file duplicati in file ZIP di origine diversi per evitare corse o comportamenti imprevisti. |
No |
| preserveCompressionFileNameAsFolder (in compressionProperties->type come TarGZipReadSettings o TarReadSettings) |
Si applica quando il set di dati di input è configurato con compressione TarGzip/Tar. Indica se mantenere il nome del file compresso di origine come struttura delle cartelle durante la copia. - Se impostato su true (impostazione predefinita), il servizio scrive i file decompressi in <path specified in dataset>/<folder named as source compressed file>/. - Se impostato su false, il servizio scrive i file decompressi direttamente in <path specified in dataset>. Assicurarsi di non avere nomi di file duplicati in file di origine diversi per evitare corse o comportamenti imprevisti. |
No |
"activities": [
{
"name": "CopyFromDelimitedText",
"type": "Copy",
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
},
"formatSettings": {
"type": "DelimitedTextReadSettings",
"skipLineCount": 3,
"compressionProperties": {
"type": "ZipDeflateReadSettings",
"preserveZipFileNameAsFolder": false
}
}
},
...
}
...
}
]
Testo delimitato come sink
Nella sezione *sink* dell'attività Copy sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà Tipo dell'origine dell'attività Copy deve essere impostata su DynamicsAXSource. | Sì |
| formatSettings | Gruppo di proprietà. Fare riferimento alla tabella Impostazioni di scrittura testo delimitato di seguito. | No |
| storeSettings | Gruppo di proprietà su come scrivere i dati in un archivio dati. Ogni connettore basato su file dispone di impostazioni di scrittura supportate in storeSettings. |
No |
Impostazioni di scrittura testo delimitato supportate in formatSettings:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | Il tipo di formatSettings deve essere impostato su DelimitedTextWriteSettings. | Sì |
| fileExtension | Estensione di file usata per denominare i file di output, ad esempio, .csv .txt. Deve essere specificato quando fileName non è specificato nel set di dati DelimitedText di output. Quando il nome file è configurato nel set di dati di output, verrà usato come nome file sink e l'impostazione dell'estensione file verrà ignorata. |
Sì quando il nome file non è specificato nel set di dati di output |
| maxRowsPerFile | Quando si scrivono dati in una cartella, è possibile scegliere di scrivere in più file e specificare il numero massimo di righe per file. | No |
| fileNamePrefix | Applicabile quando maxRowsPerFile è configurato.Specificare il prefisso del nome file durante la scrittura di dati in più file ha dato luogo a questo motivo: <fileNamePrefix>_00000.<fileExtension>. Se non specificato, il prefisso del nome file verrà generato automaticamente. Questa proprietà non si applica quando l'origine è l'archivio basato su file o archivio dati abilitato per l'opzione di partizione. |
No |
Proprietà del flusso di dati per mapping
In flussi di dati di mapping è possibile leggere e scrivere in formato testo delimitato negli archivi dati seguenti: Archiviazione BLOB di Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 e SFTP, ed è possibile leggere il formato testo delimitato in Amazon S3.
Set di dati inline
I flussi di dati di mapping supportano "set di dati inline" come opzione per definire l'origine e il sink. Un set di dati delimitato inline viene definito direttamente all'interno delle trasformazioni di origine e sink e non viene condiviso al di fuori del flusso di dati definito. È utile per la parametrizzazione delle proprietà del set di dati direttamente all'interno del flusso di dati e può trarre vantaggio da prestazioni migliorate dai set di dati di ADF condivisi.
Quando si legge un numero elevato di cartelle e file di origine, è possibile migliorare le prestazioni dell'individuazione dei file del flusso di dati impostando l'opzione "Schema proiettato dall'utente" all'interno della proiezione | Finestra di dialogo Opzioni schema. Questa opzione disattiva l'individuazione automatica dello schema predefinito di ADF e migliorerà notevolmente le prestazioni dell'individuazione dei file. Prima di impostare questa opzione, assicurarsi di importare la proiezione in modo che ADF abbia uno schema esistente per la proiezione. Questa opzione non funziona con lo spostamento schema.
Proprietà di origine
Nella tabella seguente sono elencate le proprietà supportate da un'origine testo delimitata. È possibile modificare queste proprietà nella scheda Opzioni origine.
| Nome | Descrizione | Richiesto | Valori consentiti | Proprietà script del flusso di dati |
|---|---|---|---|---|
| Percorsi con caratteri jolly | Verranno elaborati tutti i file corrispondenti al percorso con caratteri jolly. Esegue l'override della cartella e del percorso del file impostato nel set di dati. | no | String[] | wildcardPaths |
| Partition Root Path (Percorso radice partizione) | Per i dati dei file partizionati, è possibile immettere un percorso radice della partizione per leggere le cartelle partizionate come colonne | no | String | partitionRootPath |
| Elenco di file | Indica se l'origine punta a un file di testo che elenca i file da elaborare | no | true oppure false |
fileList |
| Su più righe | Il file di origine contiene righe che si estendono su più righe. I valori su più righe devono essere tra virgolette. | no true o false |
multiLineRow | |
| Colonna in cui archiviare il nome del file | Creare una nuova colonna con il nome e il percorso del file di origine | no | String | rowUrlColumn |
| Dopo il completamento | Eliminare o spostare i file dopo l'elaborazione. Il percorso del file inizia dalla radice del contenitore | no | Eliminare: true o false Spostare: ['<from>', '<to>'] |
purgeFiles moveFiles |
| Filtra per data ultima modifica | Scegliere di filtrare i file in base all'ultima modifica | no | Timestamp: | modifiedAfter modifiedBefore |
| Consenti nessun file trovato | Se true, un errore non viene generato se non vengono trovati file | no | true oppure false |
ignoreNoFilesFound |
| Numero massimo di colonne | Il valore predefinito è 20480. Personalizzare questo valore quando il numero di colonna è superiore a 20480 | no | Intero | maxColumns |
Nota
Il supporto delle origini del flusso di dati per l'elenco dei file è limitato a 1024 voci nel file. Per includere più file, usare caratteri jolly nell'elenco di file.
Esempio di origine
L'immagine seguente è un esempio di configurazione di origine testo delimitata nei flussi di dati di mapping.
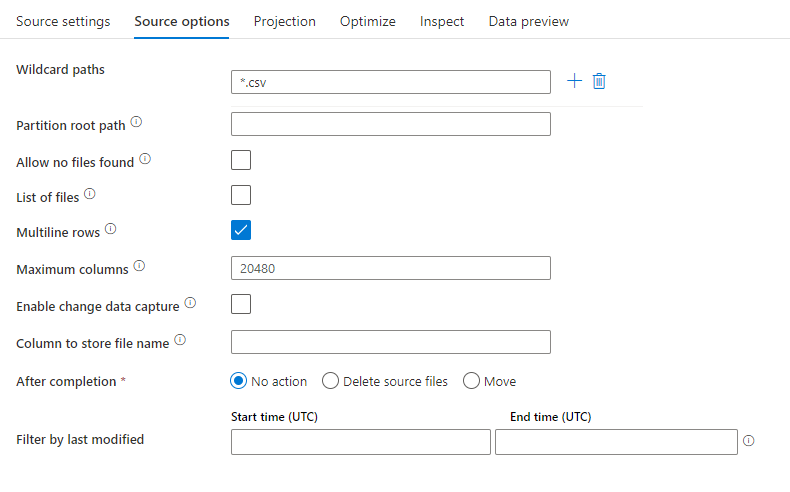
Lo script del flusso di dati associato è:
source(
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
multiLineRow: true,
wildcardPaths:['*.csv']) ~> CSVSource
Nota
Le origini del flusso di dati supportano un set limitato di caratteri jolly di Linux supportato dai file system Hadoop
Proprietà sink
Nella tabella seguente sono elencate le proprietà supportate da un sink di testo delimitato. È possibile modificare queste proprietà nella scheda Impostazioni.
| Nome | Descrizione | Richiesto | Valori consentiti | Proprietà script del flusso di dati |
|---|---|---|---|---|
| Cancellare la cartella | Se la cartella di destinazione viene cancellata prima della scrittura | no | true oppure false |
truncate |
| Opzione Nome file | Formato di denominazione dei dati scritti. Per impostazione predefinita, un file per partizione in formato part-#####-tid-<guid> |
no | Motivo: Stringa Per partizione: Stringa[] Assegna nome al file come dati di colonna: stringa Output in un singolo file: ['<fileName>'] Assegna nome alla cartella come dati di colonna: stringa |
filePattern partitionFileNames rowUrlColumn partitionFileNames rowFolderUrlColumn |
| Racchiudi tutto tra virgolette | Racchiudere tutti i valori tra virgolette | no | true oppure false |
quoteAll |
| Intestazione | Aggiungere intestazioni dei clienti ai file di output | no | [<string array>] |
di autorizzazione |
Esempio di sink
L'immagine seguente è un esempio di configurazione del sink di testo delimitato nei flussi di dati di mapping.
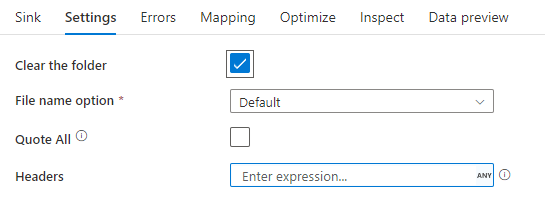
Lo script del flusso di dati associato è:
CSVSource sink(allowSchemaDrift: true,
validateSchema: false,
truncate: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CSVSink
Connettori e formati correlati
Ecco alcuni connettori e formati comuni correlati al formato di testo delimitato:
- Archiviazione BLOB di Azure
- Formato binario
- Dataverse
- Formato Delta
- Formato Excel
- File system
- FTP
- HTTP
- Formato JSON
- Formato Parquet