Creare un trigger che esegue una pipeline in risposta a un evento di archiviazione
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questo articolo descrive i trigger di eventi di archiviazione che è possibile creare nelle pipeline di Azure Data Factory o Azure Synapse Analytics.
Un'architettura guidata dagli eventi è un comune modello di integrazione dei dati che implica produzione, rilevamento, utilizzo e risposta agli eventi. Gli scenari di integrazione dei dati spesso richiedono ai clienti di attivare pipeline attivate da eventi in un account di Archiviazione di Azure, ad esempio l'arrivo o l'eliminazione di un file nell'account di Archiviazione BLOB di Azure. Le pipeline di Data Factory e Azure Synapse Analytics si integrano in modo nativo con Griglia di eventi di Azure, che consente di attivare pipeline su tali eventi.
Considerazioni sul trigger di eventi di archiviazione
Quando si usano trigger di eventi di archiviazione, tenere presente quanto segue:
- L'integrazione descritta in questo articolo dipende dalla Griglia di eventi di Azure. Verificare che la sottoscrizione sia registrata con il provider di risorse di Griglia di eventi. Per altre informazioni, vedere Provider e tipi di risorse. È necessario essere in grado di eseguire l'azione
Microsoft.EventGrid/eventSubscriptions/. Questa azione fa parte del ruolo predefinitoEventGrid EventSubscription Contributor. - Se si usa questa funzionalità in Azure Synapse Analytics, assicurarsi di registrare anche la sottoscrizione con il provider di risorse di Data Factory. In caso contrario, viene visualizzato un messaggio in cui si specifica che "la creazione di una sottoscrizione di eventi non è riuscita".
- Se l'account di archiviazione BLOB si trova dietro un endpoint privato e blocca l'accesso alla rete pubblica, è necessario configurare regole di rete per consentire le comunicazioni da Archiviazione BLOB a Griglia di eventi. È possibile concedere all'archiviazione l'accesso ai servizi di Azure attendibili, ad esempio Griglia di eventi, la documentazione di Archiviazione seguente o configurare endpoint privati per Griglia di eventi che eseguono il mapping allo spazio indirizzi di una rete virtuale, seguendo la documentazione di Griglia di eventi.
- Il trigger di eventi di archiviazione supporta attualmente solo gli account di archiviazione Azure Data Lake Storage Gen2 e per utilizzo generico versione 2. Se si lavora con eventi di archiviazione SFTP (Secure File Transfer Protocol), è necessario specificare anche l'API Dati SFTP nella sezione di filtro. A causa di una limitazione di Griglia di eventi, Data Factory supporta solo un massimo di 500 trigger di eventi di archiviazione per account di archiviazione.
- Per creare un trigger di eventi di archiviazione nuovo o modificarne uno esistente, l'account Azure usato per accedere al servizio e pubblicare il trigger di eventi di archiviazione deve disporre dell'autorizzazione appropriata per il controllo degli accessi in base al ruolo (Controllo degli accessi in base al ruolo di Azure) per l'account di archiviazione. Non sono necessarie altre autorizzazioni. L'entità servizio per Azure Data Factory e Azure Synapse Analytics non richiede autorizzazioni speciali per l'account di archiviazione o Griglia di eventi. Per altre informazioni sul controllo di accesso, vedere la sezione Controllo degli accessi in base al ruolo.
- Se è stato applicato un blocco Azure Resource Manager all'account di archiviazione, potrebbe influire sulla capacità del trigger BLOB di creare o eliminare file BLOB. Un blocco
ReadOnlyimpedisce sia la creazione che l'eliminazione, mentre un bloccoDoNotDeleteimpedisce l'eliminazione. Assicurarsi di tenere conto di queste restrizioni per evitare eventuali problemi con i trigger. - Non è consigliabile usare trigger di arrivo dei file come meccanismo di attivazione dai sink del flusso di dati. I flussi di dati eseguono una serie di attività di ridenominazione dei file e di partizione nella cartella di destinazione che possono attivare inavvertitamente un evento di arrivo del file prima del completamento dell'elaborazione dei dati.
Creare un trigger con l'interfaccia utente
Questa sezione illustra come creare un trigger di eventi di archiviazione all'interno dell'interfaccia utente della pipeline di Azure Data Factory e Azure Synapse Analytics.
Passare alla scheda Modifica in Data Factory o alla scheda Integra in Azure Synapse Analytics.
Scegliere Trigger dal menu e quindi selezionare Nuovo/Modifica.
Nella pagina Aggiungi trigger selezionare Scegli trigger e quindi Nuovo.
Selezionare il tipo di trigger Eventi di archiviazione.
Selezionare l'account di archiviazione nell'elenco a discesa della sottoscrizione di Azure o manualmente usando l'ID risorsa dell'account di archiviazione. Scegliere il contenitore in cui si desidera che si verifichino gli eventi. La selezione del contenitore è obbligatoria, ma tenere presente che, se si selezionano tutti i contenitori, il numero di eventi può essere elevato.
Le proprietà
Blob path begins witheBlob path ends withconsentono di specificare i contenitori, le cartelle e i nomi dei file BLOB per cui si vogliono ricevere eventi. Per il trigger di evento di archiviazione è necessario definire almeno una di queste proprietà. È possibile usare vari modelli per le proprietàBlob path begins witheBlob path ends with, come illustrato negli esempi descritti più avanti in questo articolo.-
Blob path begins with: il percorso del file BLOB deve iniziare con un percorso di cartella. I valori validi includono2018/e2018/april/shoes.csv. Se non è selezionato un contenitore, questo campo non è selezionabile. -
Blob path ends with: il percorso del file BLOB deve terminare con un nome file o un'estensione. I valori validi includonoshoes.csve.csv. I nomi del contenitore e della cartella, se specificati, devono essere separati da un segmento/blobs/. Il valore di un contenitore denominatoorders, ad esempio, può essere/orders/blobs/2018/april/shoes.csv. Per specificare una cartella in qualsiasi contenitore, omettere il carattere/iniziale. Ad esempio, conapril/shoes.csvsi attiva un evento in tutti i file denominatishoes.csvin una cartella denominataaprilpresente in qualsiasi contenitore.
Si noti che
Blob path begins witheBlob path ends withsono gli unici criteri di ricerca consentiti in un trigger di eventi di archiviazione. Altri tipi di ricerca con caratteri jolly non sono supportati per il tipo di trigger.-
Scegliere se il trigger deve rispondere a un evento BLOB creato, BLOB eliminato o entrambi. Nel percorso di archiviazione specificato, ogni evento attiva le pipeline di Data Factory e Azure Synapse Analytics associate al trigger.
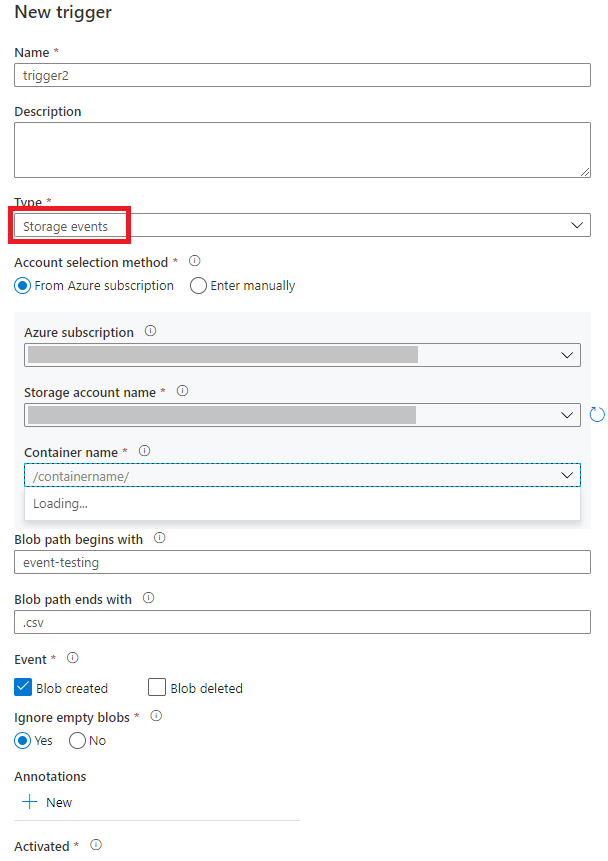
Scegliere se il trigger deve ignorare i BLOB con zero byte.
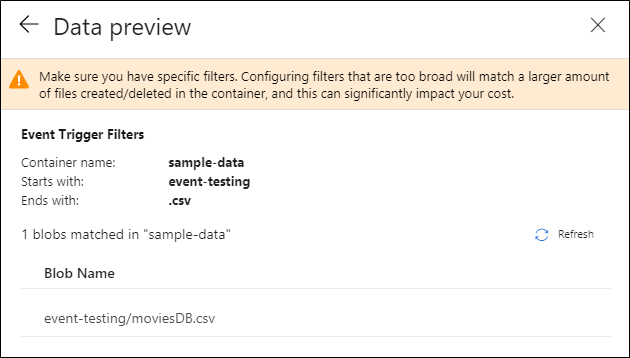
Dopo aver configurato il trigger, selezionare Avanti: Anteprima dati. Questa schermata mostra i BLOB esistenti corrispondenti alla configurazione del trigger di evento di archiviazione. Assicurarsi che siano presenti filtri specifici. La configurazione di filtri troppo generici può causare la creazione o l'eliminazione di un numero elevato di file e influire significativamente sui costi. Dopo aver verificato le condizioni di filtro, fare clic su Fine.
Per associare una pipeline a questo trigger, passare al canvas della pipeline e selezionare Trigger>Nuovo/Modifica. Quando viene visualizzato il riquadro laterale, fare clic sull'elenco a discesa Scegli trigger e selezionare il trigger creato. Selezionare Avanti: Anteprima dati per verificare che la configurazione sia corretta. Selezionare quindi Avanti per verificare che l'anteprima dei dati sia corretta.
Se alla pipeline sono associati parametri, è possibile specificarli nel riquadro laterale Parametri di esecuzione del trigger. Il trigger di evento di archiviazione acquisisce il nome file e il percorso della cartella del blob nelle proprietà
@triggerBody().folderPathe@triggerBody().fileName. Per usare i valori di queste proprietà in una pipeline, è necessario mappare le proprietà per i parametri della pipeline. Dopo il mapping delle proprietà per i parametri, è possibile accedere ai valori acquisiti dal trigger attraverso l'espressione@pipeline().parameters.parameterNameattraverso la pipeline. Per una spiegazione dettagliata, vedere Metadati dei trigger di riferimento nelle pipeline.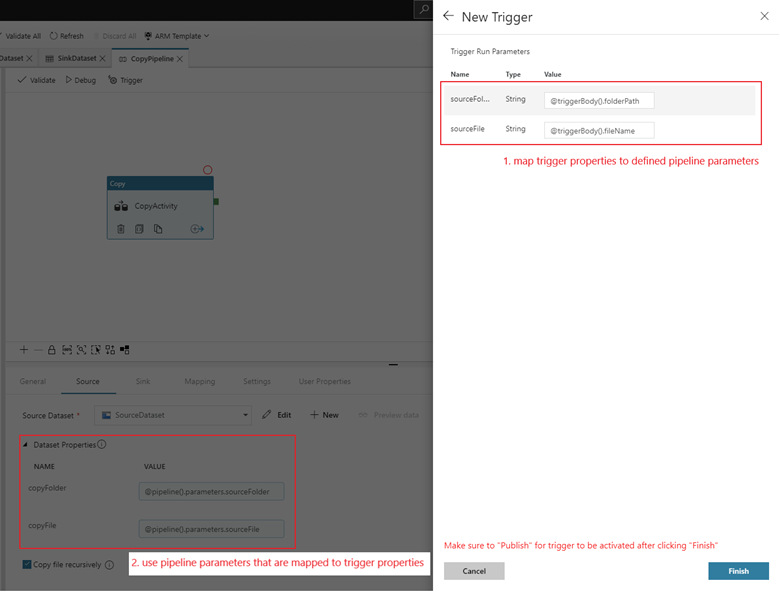
Nell'esempio precedente il trigger viene configurato in modo da essere attivato quando viene creato un percorso BLOB che termina con l'estensione csv nella cartella event-testing del contenitore sample-data. Le proprietà
folderPathefileNameacquisiscono il percorso del nuovo file BLOB. Ad esempio, quando si aggiunge MoviesDB.csv al percorso sample-data/event-testing, il valore di@triggerBody().folderPathèsample-data/event-testinge il valore di@triggerBody().fileNameèmoviesDB.csv. Nell'esempio, questi valori vengono associati ai parametri di pipelinesourceFolderesourceFile, che possono essere usati in tutta la pipeline, rispettivamente come@pipeline().parameters.sourceFoldere@pipeline().parameters.sourceFile.Al termine, fare clic su Fine.


Schema JSON
La tabella seguente offre una panoramica degli elementi dello schema correlati ai trigger di eventi di archiviazione.
| Elemento JSON | Descrizione | Tipo | Valori consentiti | Richiesto |
|---|---|---|---|---|
| ambito | ID risorsa di Azure Resource Manager dell'account di archiviazione. | String | ID Azure Resource Manager | Sì. |
| eventi | Tipo di eventi che provocano l'attivazione del trigger. | Matrice |
Microsoft.Storage.BlobCreated, Microsoft.Storage.BlobDeleted |
Sì, qualsiasi combinazione di questi valori. |
blobPathBeginsWith |
Il percorso del BLOB deve iniziare con il modello fornito per l'attivazione del trigger. Ad esempio, /records/blobs/december/ attiva il trigger solo per i BLOB nella cartella december nel contenitore records. |
String | Specificare un valore per almeno una di queste proprietà: blobPathBeginsWith o blobPathEndsWith. |
|
blobPathEndsWith |
Il percorso del BLOB deve terminare con il modello fornito per l'attivazione del trigger. Ad esempio, december/boxes.csv attiva il trigger solo per i BLOB denominati boxes in una cartella december. |
String | Specificare un valore per almeno una di queste proprietà: blobPathBeginsWith o blobPathEndsWith. |
|
ignoreEmptyBlobs |
Indica se con i BLOB a zero byte attiva un'esecuzione della pipeline. Per impostazione predefinita, il parametro è impostato su true. |
Booleano | true o false | No. |
Esempi di trigger di eventi di archiviazione
Questa sezione fornisce esempi di impostazioni del trigger di eventi di archiviazione.
Importante
È necessario includere il segmento /blobs/ del percorso, come illustrato negli esempi seguenti, ogni volta che si specifica il contenitore e la cartella, il contenitore e il file o il contenitore, la cartella e il file. Per blobPathBeginsWith, l'interfaccia utente aggiunte automaticamente /blobs/ tra il nome della cartella e quello del contenitore nel file JSON del trigger.
| Proprietà | Esempio | Descrizione |
|---|---|---|
Blob path begins with |
/containername/ |
Riceve gli eventi per qualsiasi BLOB nel contenitore. |
Blob path begins with |
/containername/blobs/foldername/ |
Riceve gli eventi per qualsiasi BLOB nel contenitore containername e nella cartella foldername. |
Blob path begins with |
/containername/blobs/foldername/subfoldername/ |
È anche possibile fare riferimento a una sottocartella. |
Blob path begins with |
/containername/blobs/foldername/file.txt |
Riceve gli eventi per un BLOB denominato file.txt nella cartella foldername nel contenitore containername. |
Blob path ends with |
file.txt |
Riceve gli eventi per un BLOB denominato file.txt in qualsiasi percorso. |
Blob path ends with |
/containername/blobs/file.txt |
Riceve gli eventi per un file BLOB denominato file.txt nel contenitore containername. |
Blob path ends with |
foldername/file.txt |
Riceve gli eventi per un file BLOB denominato file.txt nella cartella foldername di qualsiasi contenitore. |
Controllo degli accessi in base al ruolo
Data Factory and Azure Synapse Analytics usano il controllo degli accessi in base al ruolo di Azure per garantire che l'accesso non autorizzato sia in ascolto, sottoscriva gli aggiornamenti da e attivi pipeline collegate agli eventi BLOB, sia strettamente vietato.
- Per creare correttamente un nuovo trigger di eventi di archiviazione o aggiornarne uno esistente, l'account Azure connesso al servizio deve avere l'accesso appropriato all'account di archiviazione pertinente. In caso contrario, l'operazione ha esito negativo con il messaggio "Accesso negato".
- Data Factory e Azure Synapse Analytics non necessitano di autorizzazioni speciali per un'istanza di Griglia di eventi e non è necessario assegnare autorizzazioni di controllo degli accessi in base al ruolo speciali all'entità servizio di Data Factory o Azure Synapse Analytics per l'operazione.
Una delle seguenti impostazioni di controllo degli accessi in base al ruolo funziona per il trigger di eventi di archiviazione:
- Ruolo Proprietario per l'account di archiviazione
- Ruolo collaboratore per l'account di archiviazione
-
Microsoft.EventGrid/EventSubscriptions/Writeautorizzazione all'account di archiviazione/subscriptions/####/resourceGroups/####/providers/Microsoft.Storage/storageAccounts/storageAccountName
In particolare:
- Quando si crea nella data factory (ad esempio nell'ambiente di sviluppo), l'account Azure connesso deve avere l'autorizzazione precedente.
- Quando si esegue la pubblicazione tramite integrazione continua e recapito continuo, l'account usato per pubblicare il modello Azure Resource Manager nella factory di test o produzione deve avere l'autorizzazione precedente.
Per comprendere in che modo il servizio offre le due promesse, è possibile fare un passo indietro e dare un'occhiata dietro le quinte. Ecco i flussi di lavoro generici per l'integrazione tra Data Factory/Azure Synapse Analytics, Archiviazione e Griglia di eventi.
Creare un nuovo trigger di eventi di archiviazione
Questo flusso di lavoro generico descrive come Data Factory interagisce con Griglia di eventi per creare un trigger di eventi di archiviazione. Il flusso di dati è lo stesso in Azure Synapse Analytics, con le pipeline di Azure Synapse Analytics che assumono il ruolo di Data Factory nel diagramma seguente.
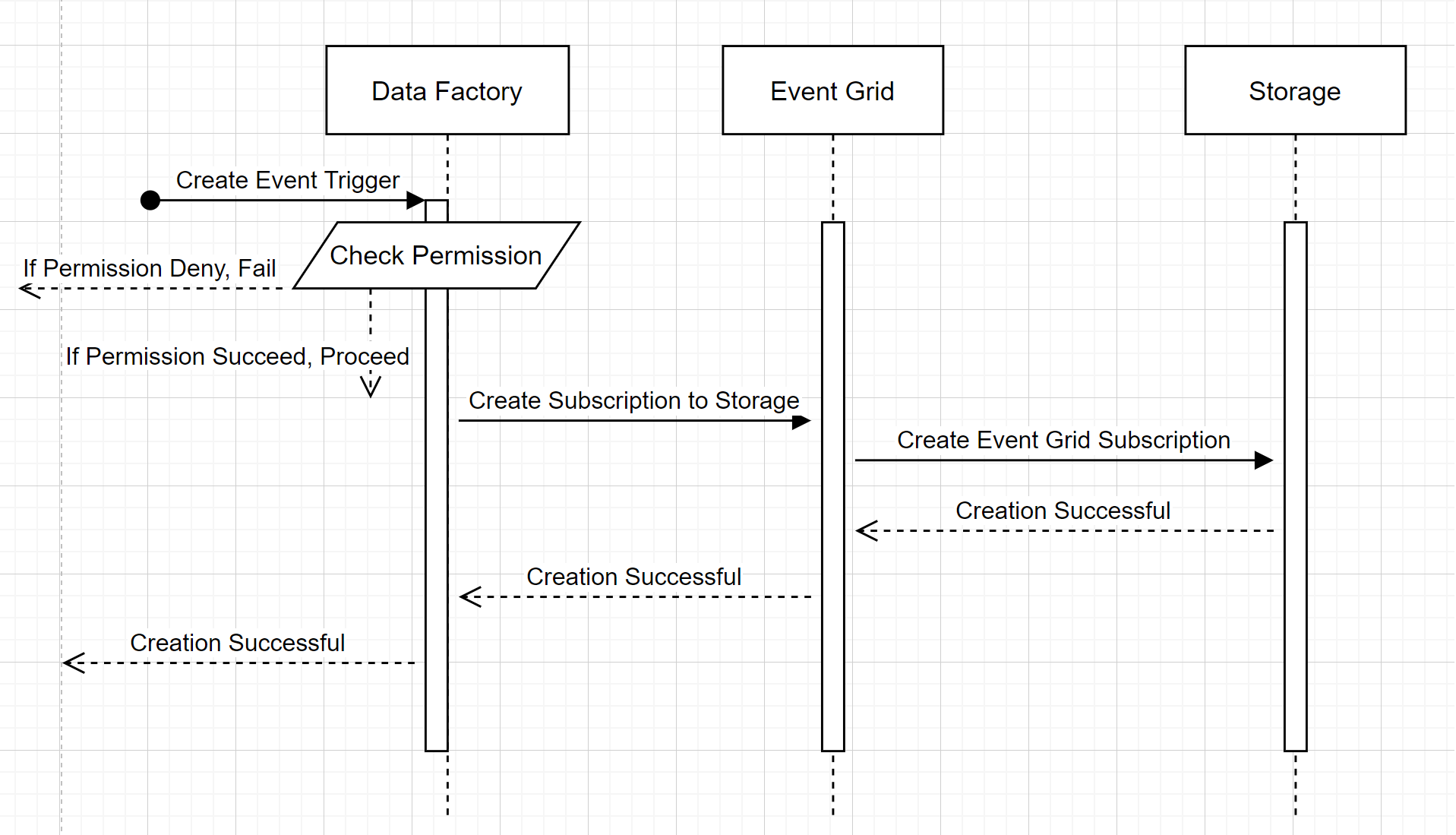
Due callout evidenti dai flussi di lavoro:
- Data Factory e Azure Synapse Analytics non hanno alcun contatto diretto con l'account di archiviazione. La richiesta di creazione di una sottoscrizione viene invece inoltrata ed elaborata da Griglia di eventi. In questo passaggio, il servizio non necessita dell'autorizzazione per accedere all'account di archiviazione.
- Il controllo di accesso e il controllo delle autorizzazioni vengono eseguiti all'interno del servizio. Prima che il servizio invii una richiesta di sottoscrizione all'evento di archiviazione, controlla l'autorizzazione per l'utente. In particolare, controlla se l'account Azure che ha eseguito l'accesso e tenta di creare il trigger di eventi di archiviazione dispone dei diritti di accesso all'account di archiviazione pertinente. Se il controllo delle autorizzazioni ha esito negativo, anche la creazione del trigger ha esito negativo.
Esecuzione della pipeline del trigger di eventi di archiviazione
Questo flusso di lavoro generico descrive il modo in cui le pipeline di trigger di eventi di archiviazione vengono eseguite tramite Griglia di eventi. In Azure Synapse Analytics, il flusso di dati è lo stesso, ma le pipeline assumono il ruolo di Data Factory, come illustrato nel diagramma seguente.
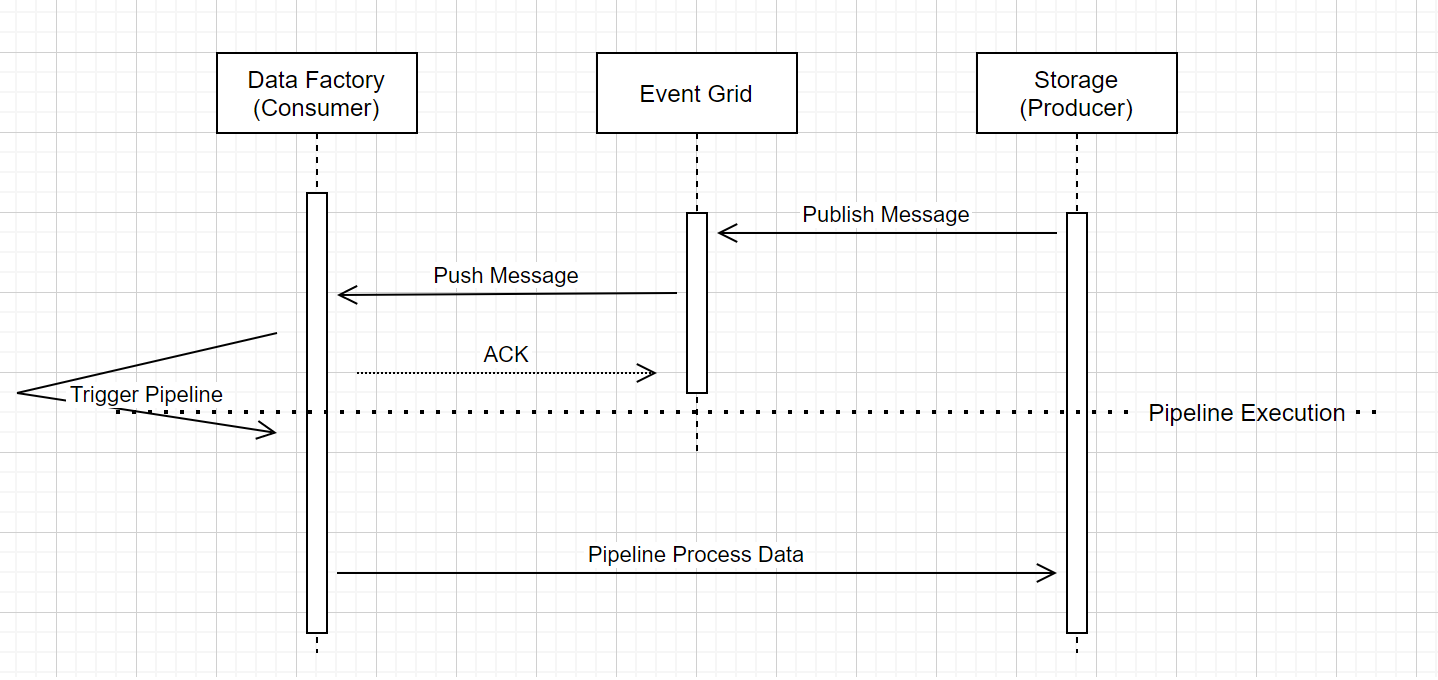
Nel flusso di lavoro è possibile identificare tre callout evidenti correlati alle pipeline di attivazione degli eventi all'interno del servizio:
Griglia di eventi usa un modello push che inoltra il messaggio il prima possibile quando l'archiviazione rilascia il messaggio nel sistema. Questo approccio è diverso dai sistemi di messaggistica, ad esempio Kafka, in cui viene usato un sistema pull.
Il trigger di eventi svolge la funzione di listener attivo per il messaggio in arrivo e attiva correttamente la pipeline associata.
Il trigger di eventi di archiviazione non ha alcun contatto diretto con l'account di archiviazione.
- Se si dispone di un'attività Copy o di altro tipo all'interno della pipeline per elaborare i dati nell'account di archiviazione, il servizio entra in diretto contatto con l'account di archiviazione usando le credenziali archiviate nel servizio collegato. Assicurarsi che il servizio collegato sia configurato in modo appropriato.
- Se non si fa riferimento all'account di archiviazione nella pipeline, non è necessario concedere l'autorizzazione al servizio per accedere all'account di archiviazione.
Contenuto correlato
- Per altre informazioni sui trigger, vedere Esecuzione e trigger di pipeline.
- Per informazioni su come fare riferimento ai metadati dei trigger nella pipeline, vedere Riferimenti ai metadati dei trigger nelle esecuzioni della pipeline.