Trasformare i dati eseguendo una definizione di processo Synapse Spark
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
L'attività di definizione del processo Spark di Azure Synapse in una pipeline esegue una definizione di processo Synapse Spark nell'area di lavoro di Azure Synapse Analytics. Questo articolo si basa sull'articolo relativo alle attività di trasformazione dei dati che presenta una panoramica generale della trasformazione dei dati e le attività di trasformazione supportate.
Impostare il canvas della definizione del processo Apache Spark
Per usare un'attività di definizione del processo Spark per Synapse in una pipeline, seguire questa procedura:
Impostazioni generali
Cercare la definizione del processo Spark nel riquadro Attività pipeline e trascinare un'attività di definizione del processo Spark nell'area di disegno della pipeline.
Selezionare la nuova attività di definizione del processo Spark nell'area di disegno, se non è già selezionata.
Nella scheda Generale immettere l'esempio per Nome.
(Facoltativo) È anche possibile immettere una descrizione.
Timeout: tempo massimo di esecuzione di un'attività. Il valore predefinito è sette giorni, ovvero la quantità massima di tempo consentita. Il formato è in D.HH:MM:SS.
Retry: il numero massimo di tentativi.
Intervallo tra tentativi: numero di secondi tra ogni tentativo.
Output sicuro: quando selezionato, l'output dell'attività non verrà acquisito nella registrazione.
Input sicuro: se selezionato, l'input dell'attività non verrà acquisito nella registrazione.
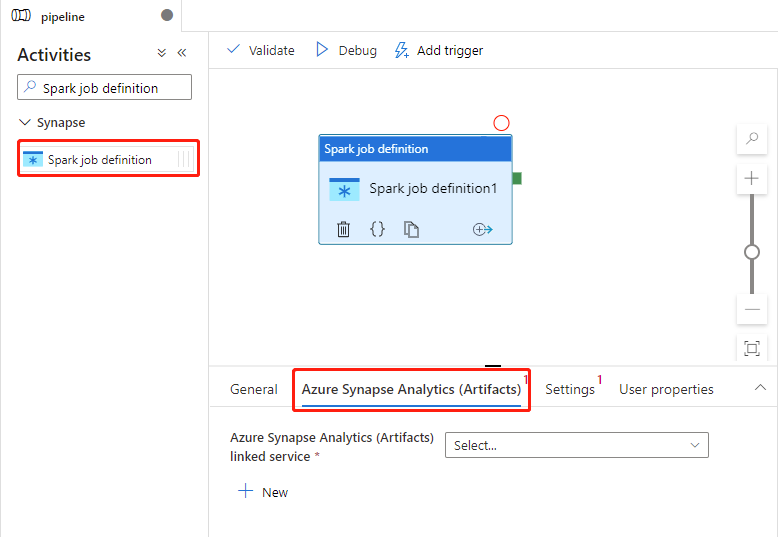
Impostazioni di Azure Synapse Analytics (Artifacts)
Selezionare la nuova attività di definizione del processo Spark nell'area di disegno, se non è già selezionata.
Selezionare la scheda Azure Synapse Analytics (Artefatti) per selezionare o creare un nuovo servizio collegato di Azure Synapse Analytics che eseguirà l'attività di definizione del processo Spark.
Scheda Impostazioni
Selezionare la nuova attività di definizione del processo Spark nell'area di disegno, se non è già selezionata.
Seleziona la scheda Impostazioni.
Espandere l'elenco delle definizioni di processo Spark, è possibile selezionare una definizione di processo Apache Spark esistente nell'area di lavoro di Azure Synapse Analytics collegata.
(Facoltativo) È possibile immettere le informazioni per la definizione di processo Apache Spark. Se le impostazioni seguenti sono vuote, le impostazioni della definizione del processo Spark verranno usate per l'esecuzione; se le impostazioni seguenti non sono vuote, queste impostazioni sostituiranno le impostazioni della definizione del processo Spark stessa.
Proprietà Descrizione File di definizione principale File principale usato per il processo. Selezionare un file PY/JAR/ZIP dalla risorsa di archiviazione. È possibile selezionare Carica file per caricare il file in un account di archiviazione.
Esempio:abfss://…/path/to/wordcount.jarRiferimenti da sottocartelle L'analisi delle sottocartelle dalla cartella radice del file di definizione principale; questi file verranno aggiunti come file di riferimento. Le cartelle denominate "jars", "pyFiles", "files" o "archives" verranno analizzate; il nome delle cartelle fa distinzione tra maiuscole e minuscole. Nome della classe principale Identificatore completo o classe principale inclusa nel file di definizione principale.
Esempio:WordCountArgomenti della riga di comando È possibile aggiungere argomenti della riga di comando facendo clic sul pulsante Nuovo. Si noti che l'aggiunta di argomenti della riga di comando sostituirà gli argomenti della riga di comando definiti dalla definizione del processo Spark.
Esempio:abfss://…/path/to/shakespeare.txtabfss://…/path/to/resultPool di Apache Spark È possibile selezionare il pool di Apache Spark dall'elenco. Informazioni di riferimento sul codice Python File di codice Python aggiuntivi usati per riferimento nel file di definizione principale.
Supporta il passaggio di file (.py, py3 .zip) alla proprietà "pyFiles". Eseguirà l'override della proprietà "pyFiles" definita nella definizione del processo Spark.File di riferimento File aggiuntivi usati come riferimento nel file di definizione principale. Pool di Apache Spark È possibile selezionare il pool di Apache Spark dall'elenco. Allocare dinamicamente gli executor Questa impostazione esegue il mapping alla proprietà di allocazione dinamica nella configurazione Spark per l'allocazione degli executor dell'applicazione Spark. Numero minimo di executor Numero minimo di executor da allocare nel pool di Spark specificato per il processo. Numero massimo di executor Numero massimo di executor da allocare nel pool di Spark specificato per il processo. Dimensioni driver Numero di core e memoria da usare per il driver indicato nel pool di Apache Spark specificato per il processo. Configurazione di Spark Specificare i valori delle proprietà di configurazione di Spark elencati nell'argomento: Configurazione di SparK: proprietà dell'applicazione. Gli utenti possono usare la configurazione predefinita e quella personalizzata. 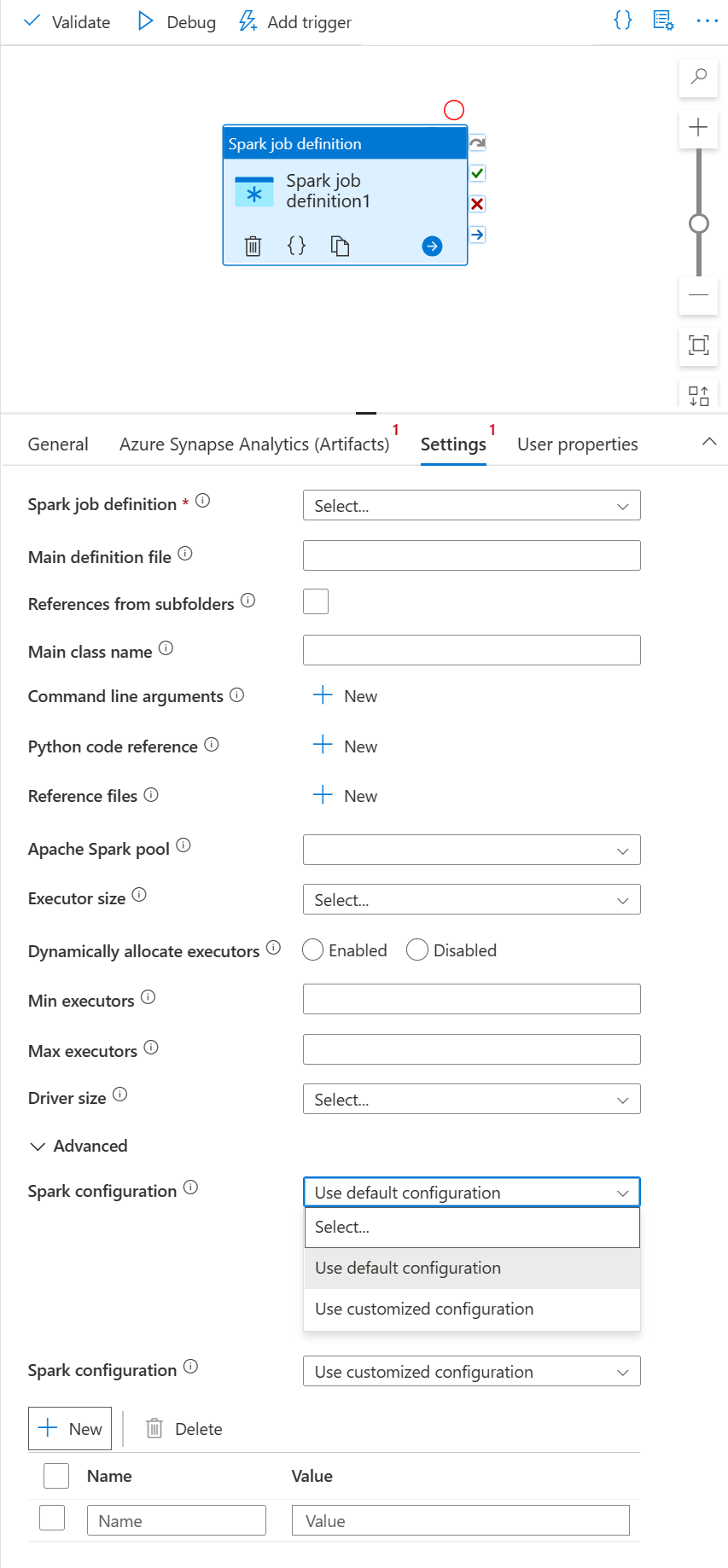
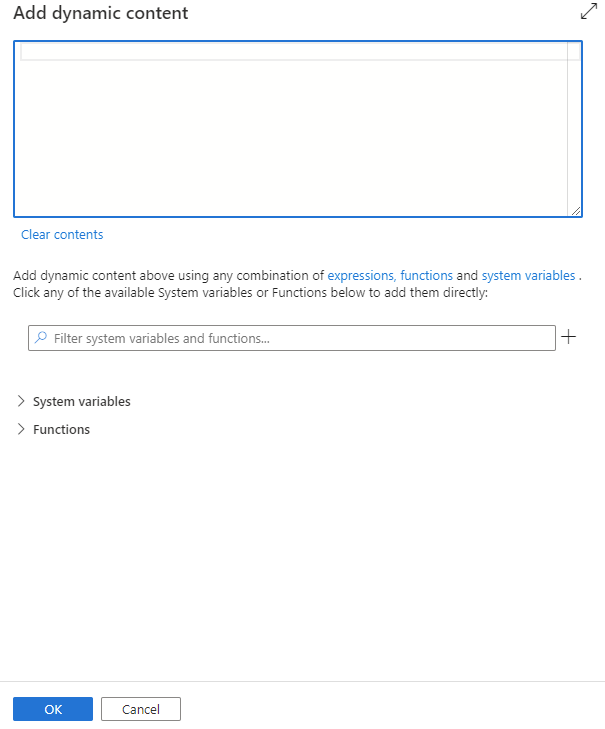
È possibile aggiungere contenuto dinamico facendo clic sul pulsante Aggiungi contenuto dinamico o premendo il tasto di scelta rapida Alt+Maiusc+D. Nella pagina Aggiungi contenuto dinamico è possibile usare qualsiasi combinazione di espressioni, funzioni e variabili di sistema da aggiungere al contenuto dinamico.
Scheda Proprietà utente
In questo pannello è possibile aggiungere proprietà per l'attività di definizione del processo Apache Spark.
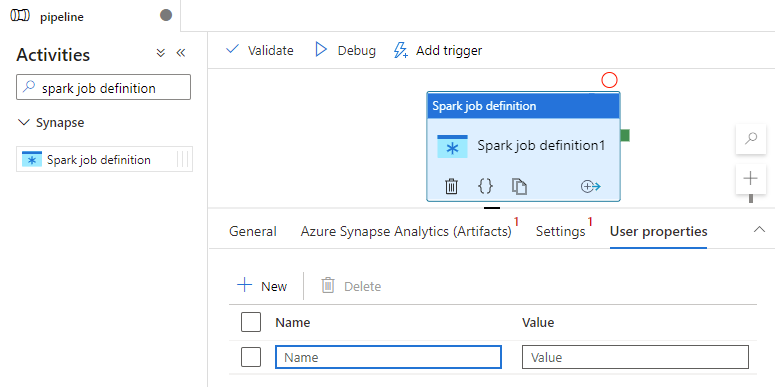
Definizione dell'attività di definizione del processo Spark di Azure Synapse
Ecco la definizione JSON di esempio di un'attività notebook di Azure Synapse Analytics:
{
"activities": [
{
"name": "Spark job definition1",
"type": "SparkJob",
"dependsOn": [],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"typeProperties": {
"sparkJob": {
"referenceName": {
"value": "Spark job definition 1",
"type": "Expression"
},
"type": "SparkJobDefinitionReference"
}
},
"linkedServiceName": {
"referenceName": "AzureSynapseArtifacts1",
"type": "LinkedServiceReference"
}
}
],
}
Proprietà della definizione del processo Spark di Azure Synapse
La tabella seguente fornisce le descrizioni delle proprietà JSON usate nella definizione JSON:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| name | Nome dell'attività nella pipeline. | Sì |
| description | Testo che descrive l'attività. | No |
| type | Per l'attività di definizione del processo Spark di Azure Synapse, il tipo di attività è SparkJob. | Sì |
Vedere cronologia di esecuzione dell'attività di definizione del processo Spark di Azure Synapse
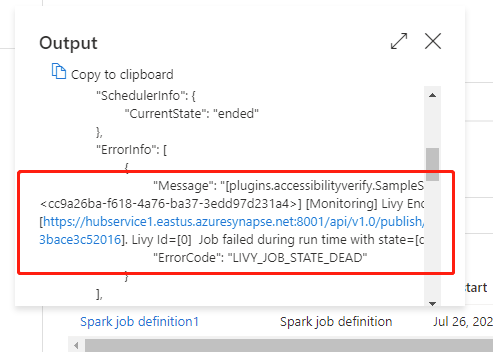
Passare a Esecuzioni della pipeline nella scheda Monitoraggio . Verrà visualizzata la pipeline attivata. Aprire la pipeline che contiene l'attività di definizione del processo Spark di Azure Synapse per visualizzare la cronologia di esecuzione.
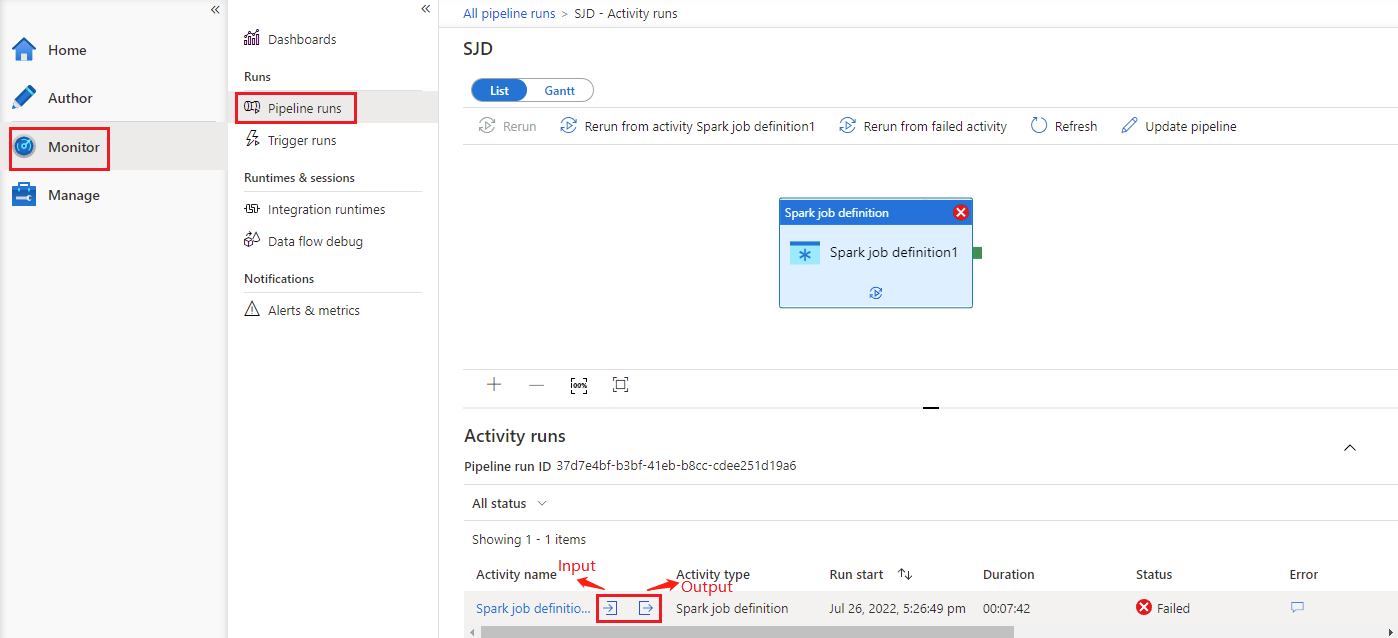
È possibile visualizzare l'input o l'output dell'attività del notebook selezionando il pulsante Input o Output. Se la pipeline non è riuscita a causa di un errore utente, selezionare l'output per controllare il campo del risultato e visualizzare il traceback dettagliato dell'errore utente.