Copiare i dati e inviare notifiche tramite posta elettronica in caso di esito positivo e negativo
SI APPLICA A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi completa per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come avviare gratuitamente una nuova versione di valutazione .
In questa esercitazione si crea una pipeline di Data Factory che illustra alcune funzionalità del flusso di controllo. La pipeline esegue una semplice copia da un contenitore nell'archivio BLOB di Azure a un altro contenitore nello stesso account di archiviazione. Se l'attività di copia ha esito positivo, la pipeline invia i dettagli dell'operazione di copia completata (ad esempio, la quantità di dati scritti) in un messaggio di posta elettronica di operazione riuscita. Se l'attività di copia ha esito negativo, la pipeline invia i dettagli dell'errore di copia (ad esempio, il messaggio di errore) in un messaggio di posta elettronica di operazione non riuscita. Nel corso dell'esercitazione verrà illustrato come passare i parametri.
Panoramica generale dello scenario: 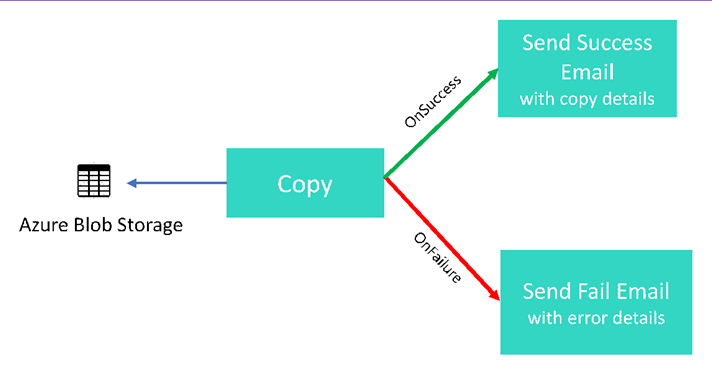
In questa esercitazione vengono completati i passaggi seguenti:
- Creare una data factory.
- Creare un servizio collegato Archiviazione di Azure
- Creare un set di dati del BLOB di Azure
- Creare una pipeline contenente un'attività Copia e un'attività Web
- Inviare gli output delle attività alle attività successive
- Utilizzare il passaggio di parametri e le variabili di sistema
- Avviare un'esecuzione della pipeline
- Monitorare le esecuzioni di pipeline e attività
Questa esercitazione usa il portale di Azure. È possibile usare altri meccanismi per interagire con Azure Data Factory. Vedere "Guide introduttive" nel sommario.
Prerequisiti
- Sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
- Account di archiviazione di Azure. Usare l'archivio BLOB come archivio dati di origine. Se non si ha un account di archiviazione di Azure, vedere l'articolo Creare un account di archiviazione per informazioni su come crearne uno.
- Database SQL di Azure. Usare il database come archivio dati sink. Se non si ha un database nel database SQL di Azure, vedere la procedura per crearne uno nell'articolo Creare un database nel database SQL di Azure.
Creare la tabella BLOB
Avviare il Blocco note. Copiare il testo seguente e salvarlo come file input.txt sul disco.
John,Doe Jane,DoeUsare strumenti come Azure Storage Explorer per seguire questa procedura:
- Creare il contenitore adfv2branch.
- Creare la cartella di input nel contenitore adfv2branch.
- Caricare il file input.txt nel contenitore.
Creare gli endpoint del flusso di lavoro del messaggio di posta elettronica
Per attivare l'invio di un messaggio di posta elettronica dalla pipeline, usare App per la logica di Azure per definire il flusso di lavoro. Per altre informazioni sulla creazione di un flusso di lavoro dell'app per la logica, vedere Creare un flusso di lavoro di app per la logica a consumo di esempio.
Flusso di lavoro del messaggio di posta elettronica di operazione riuscita
Creare un flusso di lavoro dell'app per la logica a consumo denominato CopySuccessEmail. Aggiungere il trigger richiesta denominato Quando viene ricevuta una richiesta HTTP e aggiungere l'azione di Office 365 Outlook denominata Invia un messaggio di posta elettronica. Se richiesto, accedere all'account di Office 365 Outlook.
Per il trigger Richiesta, compilare la casella Request Body JSON Schema (Schema JSON del corpo della richiesta) con il codice JSON seguente:
{
"properties": {
"dataFactoryName": {
"type": "string"
},
"message": {
"type": "string"
},
"pipelineName": {
"type": "string"
},
"receiver": {
"type": "string"
}
},
"type": "object"
}
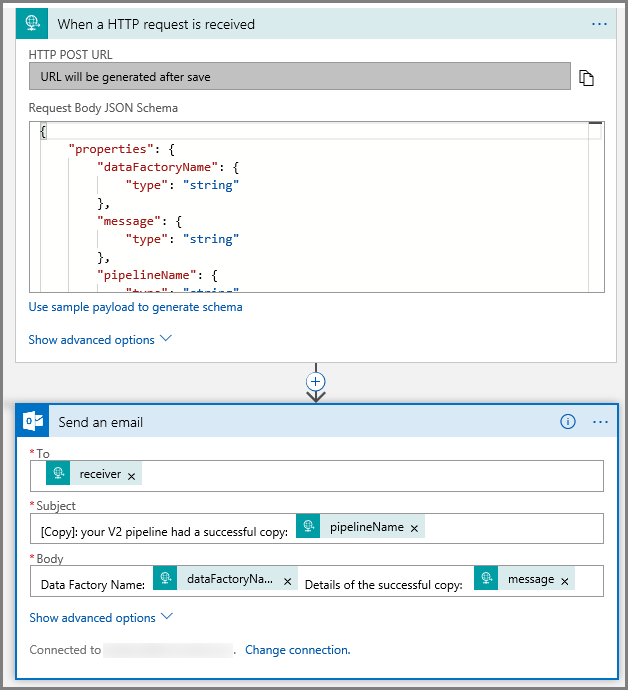
Il trigger Richiesta nella finestra di progettazione del flusso di lavoro dovrebbe essere simile all'immagine seguente:
Per l'azione Invia un messaggio di posta elettronica , personalizzare la modalità di formattazione del messaggio di posta elettronica, usando le proprietà passate nello schema JSON del corpo della richiesta. Ecco un esempio:
Salvare il flusso di lavoro. Prendere nota dell'URL della richiesta HTTP Post per il flusso di lavoro del messaggio di posta elettronica di operazione riuscita:
//Success Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
Flusso di lavoro del messaggio di posta elettronica di operazione non riuscita
Seguire la stessa procedura per creare un altro flusso di lavoro dell'app per la logica denominato CopyFailEmail. Nel trigger Richiesta il valore dello schema JSON del corpo della richiesta è lo stesso. Modificare la formattazione del messaggio di posta elettronica, ad esempio Subject, per adattarlo a un messaggio di posta elettronica di operazione non riuscita. Ecco un esempio:
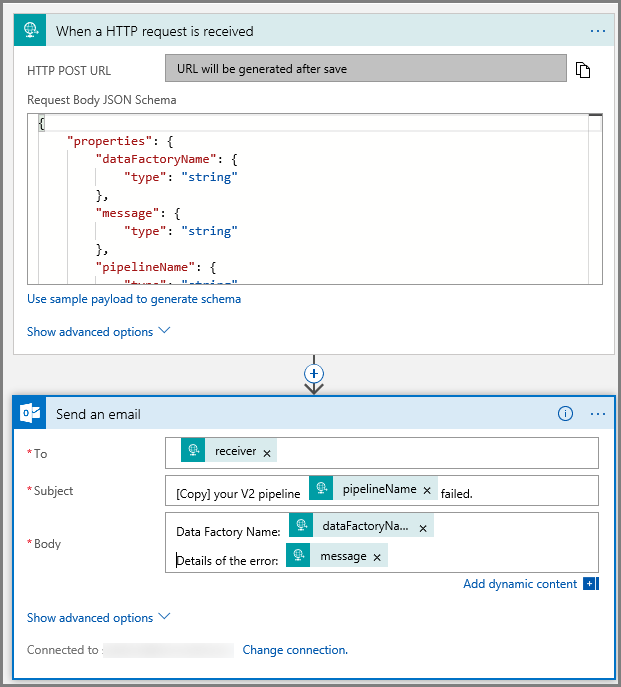
Salvare il flusso di lavoro. Prendere nota dell'URL della richiesta HTTP Post per il flusso di lavoro del messaggio di posta elettronica di operazione non riuscita:
//Fail Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
Si avranno ora due URL di flusso di lavoro:
//Success Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
//Fail Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
Creare una data factory
Avviare il Web browser Microsoft Edge o Google Chrome. L'interfaccia utente di Data Factory è attualmente supportata solo nei Web browser Microsoft Edge e Google Chrome.
Espandere il menu in alto a sinistra e selezionare Crea una risorsa. Selezionare quindi Integration Data Factory:Then select >Integration>Data Factory:

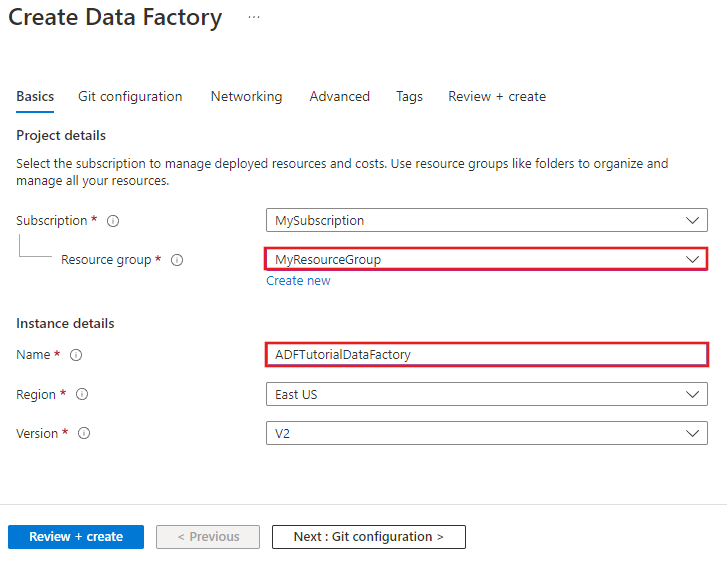
Nella pagina Nuova data factory immettere ADFTutorialDataFactory per Nome.
Il nome della data factory di Azure deve essere univoco a livello globale. Se viene visualizzato l'errore seguente, modificare il nome della data factory, ad esempio, nomeutenteADFTutorialDataFactory, e provare di nuovo a crearla. Per informazioni sulle regole di denominazione per gli elementi di Data Factory, vedere l'articolo Data Factory - Regole di denominazione.
Il nome della data factory "ADFTutorialDataFactory" non è disponibile.
Selezionare la sottoscrizione di Azure in cui creare la data factory.
Per il gruppo di risorse, eseguire una di queste operazioni:
Selezionare Usa esistentee scegliere un gruppo di risorse esistente dall'elenco a discesa.
Selezionare Crea nuovoe immettere un nome per il gruppo di risorse.
Per informazioni sui gruppi di risorse, vedere l'articolo relativo all'uso di gruppi di risorse per la gestione delle risorse di Azure.
Selezionare V2 per version.
Selezionare la località per la data factory. Nell'elenco a discesa vengono mostrate solo le località supportate. Gli archivi dati (Archiviazione di Azure, database SQL di Azure e così via) e le risorse di calcolo (HDInsight e così via) usati dalla data factory possono trovarsi in altre aree.
Selezionare Aggiungi al dashboard.
Fai clic su Crea.
Al termine della creazione verrà visualizzata la pagina Data factory, come illustrato nell'immagine.
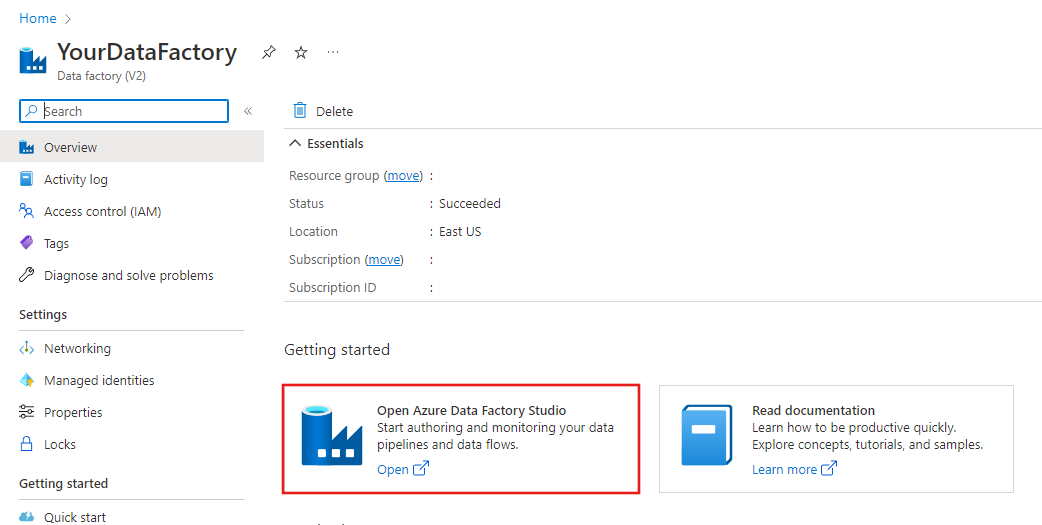
Fare clic sul riquadro Apri Azure Data Factory Studio per avviare l'interfaccia utente di Azure Data Factory in una scheda separata.
Creare una pipeline
In questo passaggio viene creata una pipeline con un'attività Copia e due attività Web. Vengono usate le funzionalità seguenti per creare la pipeline:
- Parametri per la pipeline a cui accedono i set di dati.
- Attività Web per richiamare i flussi di lavoro delle app per la logica per inviare messaggi di posta elettronica di operazione riuscita o non riuscita.
- Connessione di un'attività con un'altra attività (in caso di esito positivo e negativo)
- Uso dell'output di un'attività come input per l'attività successiva
Nella home page dell'interfaccia utente di Data Factory fare clic sul riquadro Orchestrate .In the home page of Data Factory UI, click the Orchestrate tile.
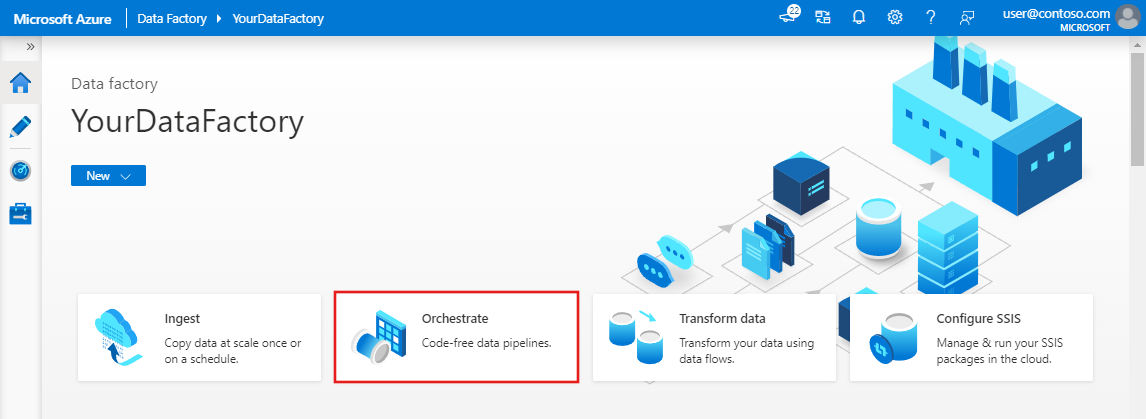
Nella finestra delle proprietà per la pipeline passare alla scheda Parametri e usare il pulsante Nuovo per aggiungere i tre parametri seguenti di tipo String: sourceBlobContainer, sinkBlobContainer e receiver.
- sourceBlobContainer: parametro nella pipeline utilizzato dal set di dati del BLOB di origine.
- sinkBlobContainer : parametro nella pipeline utilizzata dal set di dati del BLOB sink
- receiver : questo parametro viene usato dalle due attività Web nella pipeline che inviano messaggi di posta elettronica di esito positivo o negativo al ricevitore il cui indirizzo di posta elettronica è specificato da questo parametro.
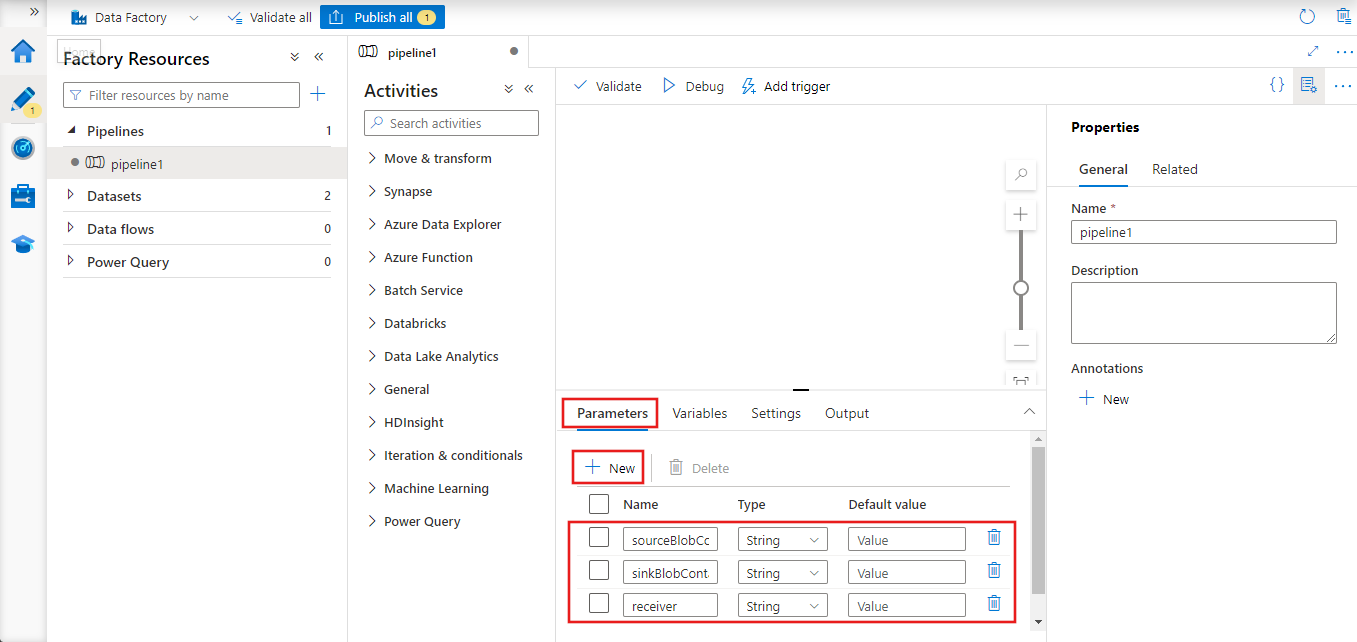
Nella casella degli strumenti Attività cercare Copia e trascinare l'attività Copia nell'area di progettazione della pipeline.
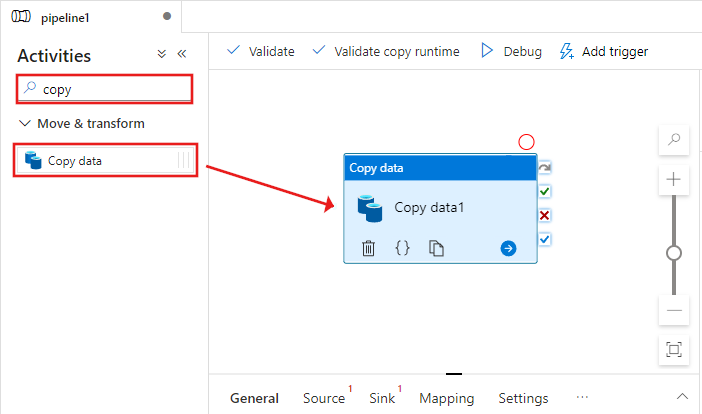
Selezionare l'attività Copia trascinata nell'area di progettazione della pipeline. Nella finestra Proprietà per l'attività Copia nella parte inferiore passare alla scheda Origine e fare clic su + Nuovo. In questa attività viene creato un set di dati di origine per l'attività di copia.
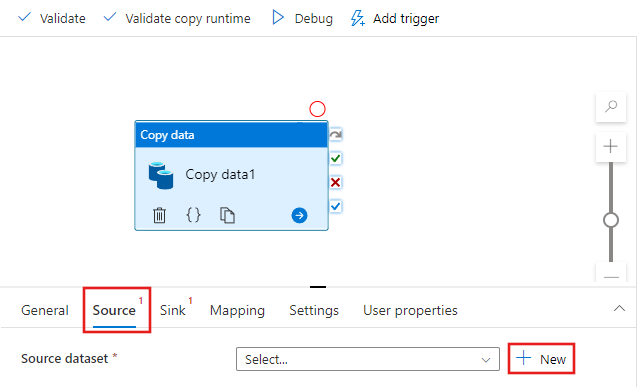
Nella finestra Nuovo set di dati selezionare la scheda Azure nella parte superiore, quindi scegliere Archiviazione BLOB di Azure e selezionare Continua.
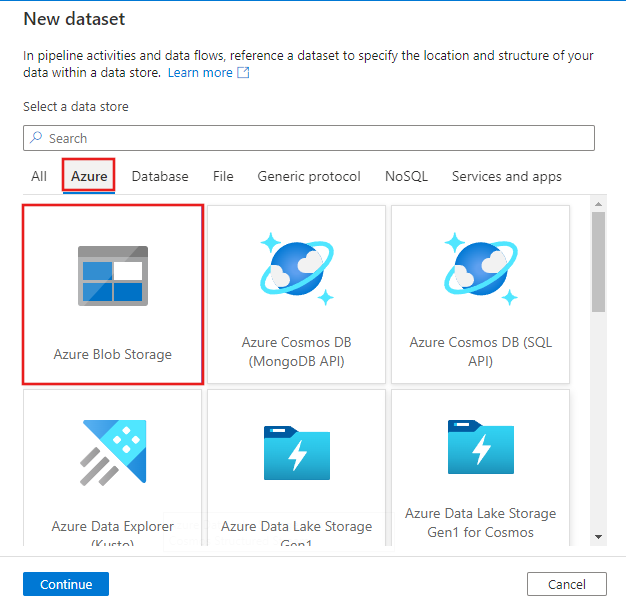
Nella finestra Seleziona formato scegliere DelimitedText e selezionare Continua.

Verrà visualizzata una nuova scheda denominata Imposta proprietà. Modificare il nome del set di dati in SourceBlobDataset. Selezionare l'elenco a discesa Servizio collegato e scegliere +Nuovo per creare un nuovo servizio collegato nel set di dati di origine.
Verrà visualizzata la finestra Nuovo servizio collegato in cui è possibile compilare le proprietà necessarie per il servizio collegato.
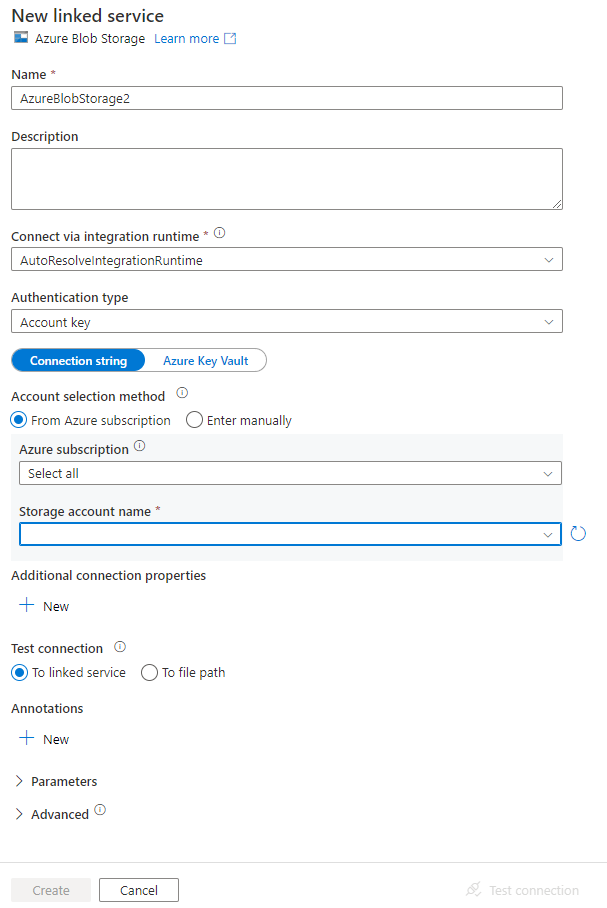
Nella finestra New Linked Service (Nuovo servizio collegato) completare questa procedura:
- Immettere AzureStorageLinkedService per Nome.
- Selezionare l'account di archiviazione di Azure per Nome account di archiviazione.
- Fai clic su Crea.
Nella finestra Imposta proprietà visualizzata successivamente selezionare Apri questo set di dati per immettere un valore con parametri per il nome del file.
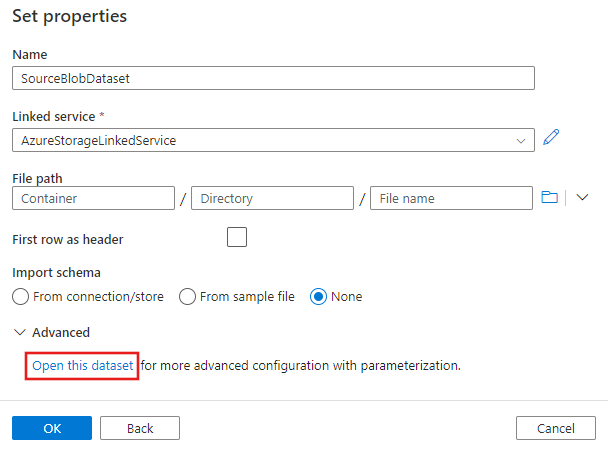
Immettere
@pipeline().parameters.sourceBlobContainerper la cartella eemp.txtper il nome file.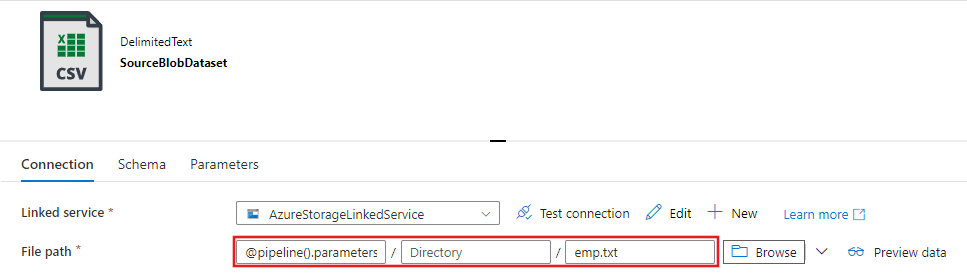
Tornare alla scheda della pipeline (o fare clic sulla pipeline nella visualizzazione albero a sinistra) e selezionare l'attività Copia nella finestra di progettazione. Verificare che il nuovo set di dati sia selezionato per Set di dati di origine.
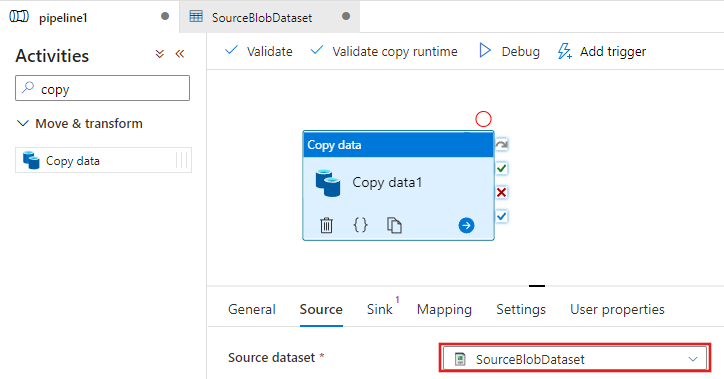
Nella finestra delle proprietà passare alla scheda Sink e fare clic su + Nuovo per Sink Dataset (Set di dati sink). In questo passaggio viene creato un set di dati sink per l'attività di copia con una procedura simile a quella per il set di dati di origine.
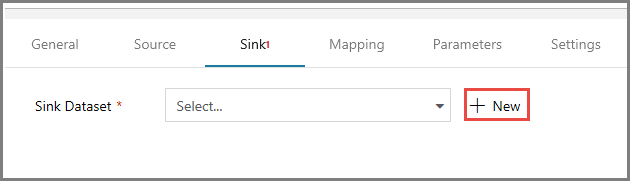
Nella finestra Nuovo set di dati selezionare Archiviazione BLOB di Azure e fare clic su Continua, quindi selezionare di nuovo DelimitedText nella finestra Seleziona formato e fare di nuovo clic su Continua.
Nella pagina Imposta proprietà per il set di dati immettere SinkBlobDataset per Nome e selezionare Azure Archiviazione LinkedService per LinkedService.
Espandere la sezione Avanzate della pagina delle proprietà e selezionare Apri questo set di dati.
Nella scheda Connessione ion del set di dati modificare il percorso file. Immettere
@pipeline().parameters.sinkBlobContainerper la cartella e@concat(pipeline().RunId, '.txt')per il nome del file. L'espressione usa l'ID dell'esecuzione attuale della pipeline per il nome del file. Per l'elenco delle variabili di sistema e delle espressioni supportate, vedere Variabili di sistema e Linguaggio delle espressioni.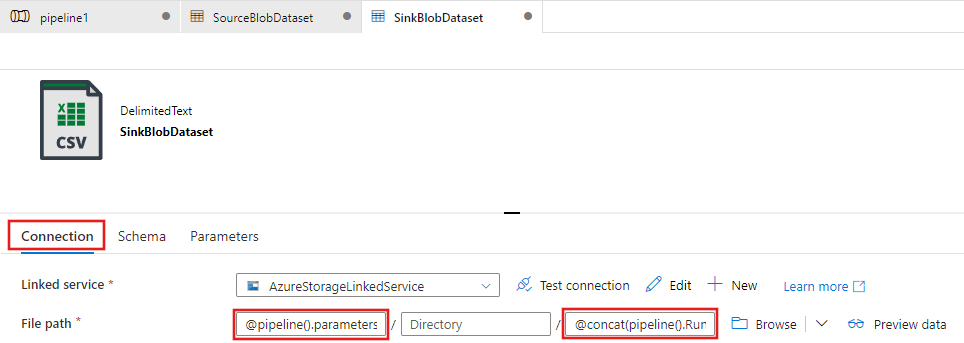
Tornare alla scheda pipeline nella parte superiore. Cercare Web nella casella di ricerca e trascinare un'attività Web nell'area di progettazione della pipeline. Impostare il nome dell'attività su SendSuccessEmailActivity. L'attività Web consente una chiamata a qualsiasi endpoint REST. Per altre informazioni sull'attività, vedere l'articolo relativo all'attività Web. Questa pipeline usa un'attività Web per chiamare il flusso di lavoro di app per la logica per il messaggio di posta elettronica.
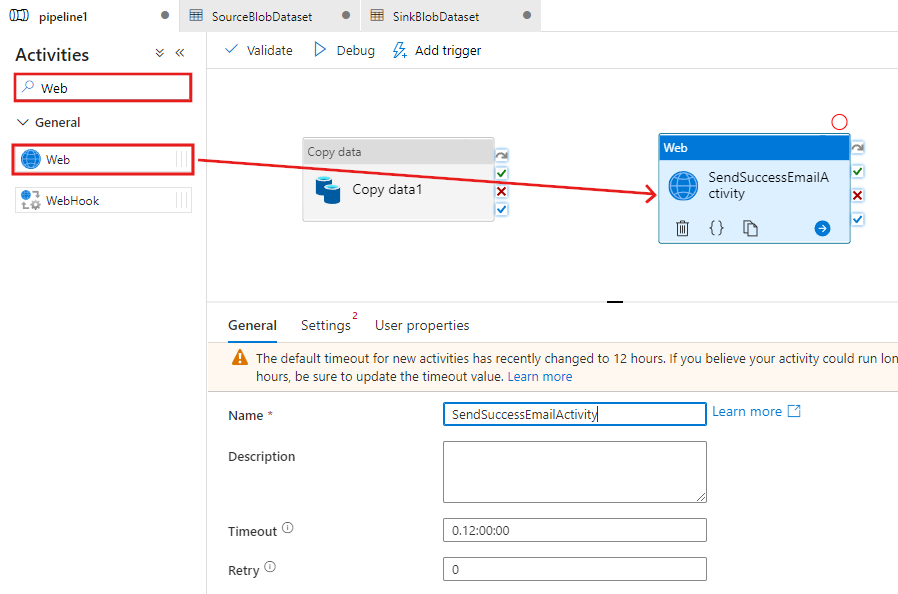
Passare alla scheda Impostazioni dalla scheda Generale e seguire questa procedura:
Per URL specificare l'URL per il flusso di lavoro di app per la logica che invia il messaggio di posta elettronica di operazione riuscita.
Selezionare POST per Metodo.
Fare clic sul collegamento + Aggiungi intestazione nella sezione Intestazioni.
Aggiungere un'intestazione Tipo contenuto e impostarla su application/json.
Specificare il codice JSON seguente per Corpo.
{ "message": "@{activity('Copy1').output.dataWritten}", "dataFactoryName": "@{pipeline().DataFactory}", "pipelineName": "@{pipeline().Pipeline}", "receiver": "@pipeline().parameters.receiver" }Il corpo del messaggio contiene le proprietà seguenti:
Message - Passaggio del valore di
@{activity('Copy1').output.dataWritten. Accede a una proprietà della precedente attività di copia e passa il valore di dataWritten. In caso di esito negativo, passa invece l'output di errore di@{activity('CopyBlobtoBlob').error.message.Nome data factory: passaggio del valore di Si tratta di una variabile di
@{pipeline().DataFactory}sistema che consente di accedere al nome della data factory corrispondente. Per un elenco delle variabili di sistema, vedere l'articolo relativo alle variabili di sistema.Nome pipeline: passaggio del valore di
@{pipeline().Pipeline}. È anche questa una variabile di sistema, che consente di accedere al nome di pipeline corrispondente.Ricevitore : passaggio del valore "@pipeline().parameters.receiver"). per l'accesso ai parametri della pipeline.
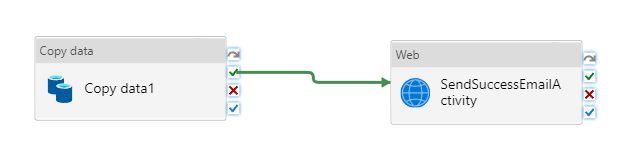
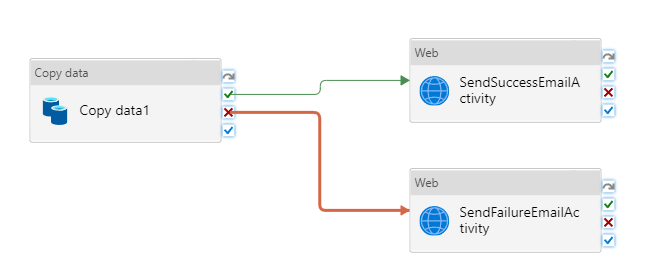
ConnessioneCopiare l'attività nell'attività Web trascinando il pulsante della casella di controllo verde accanto al attività Copy e rilasciando l'attività Web.
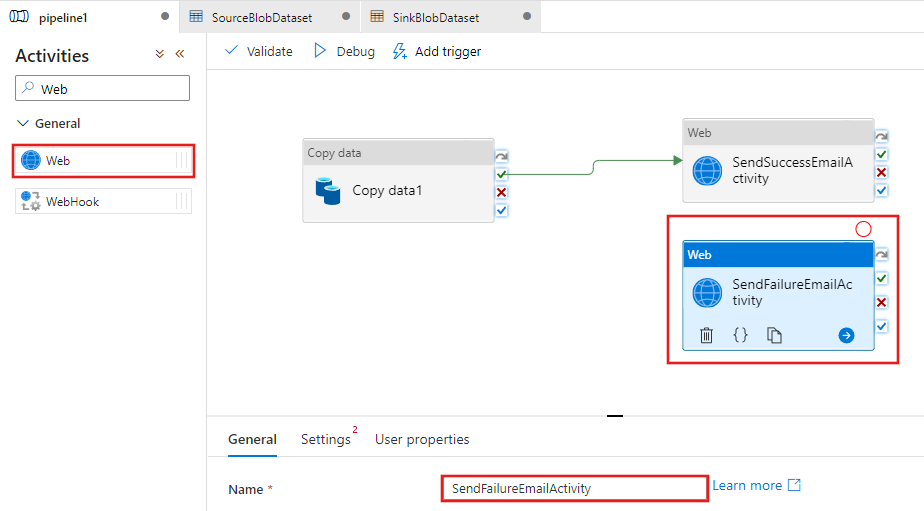
Trascinare un'altra attività Web dalla casella degli strumenti Attività all'area di progettazione della pipeline e impostare nome su SendFailureEmailActivity.
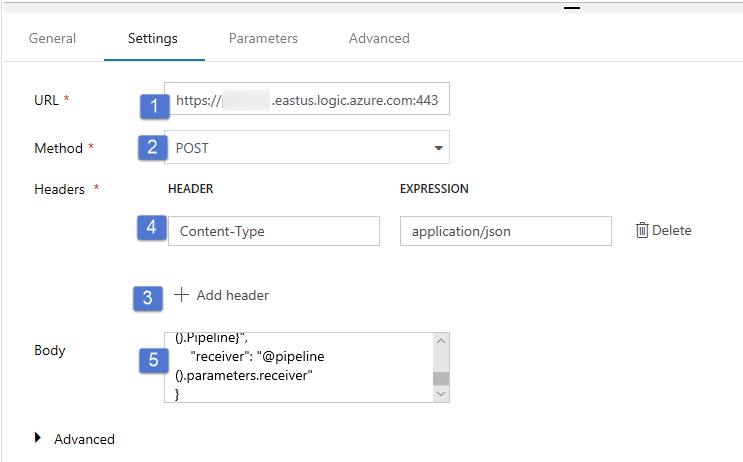
Passare alla scheda Impostazioni e seguire questa procedura:
Per URL specificare l'URL per il flusso di lavoro di app per la logica che invia il messaggio di posta elettronica di operazione non riuscita.
Selezionare POST per Metodo.
Fare clic sul collegamento + Aggiungi intestazione nella sezione Intestazioni.
Aggiungere un'intestazione Tipo contenuto e impostarla su application/json.
Specificare il codice JSON seguente per Corpo.
{ "message": "@{activity('Copy1').error.message}", "dataFactoryName": "@{pipeline().DataFactory}", "pipelineName": "@{pipeline().Pipeline}", "receiver": "@pipeline().parameters.receiver" }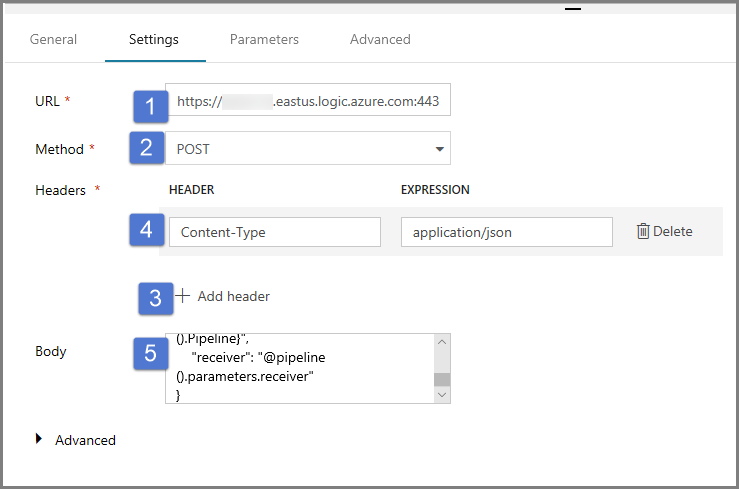
Selezionare il pulsante X rosso sul lato destro dell'attività Copia nella finestra di progettazione della pipeline e trascinarlo nell'oggetto SendFailureEmailActivity appena creato.
Per convalidare la pipeline, fare clic sul pulsante Convalida sulla barra degli strumenti. Chiudere la finestra Pipeline Validation Output (Output di convalida della pipeline) facendo clic sul pulsante >>.
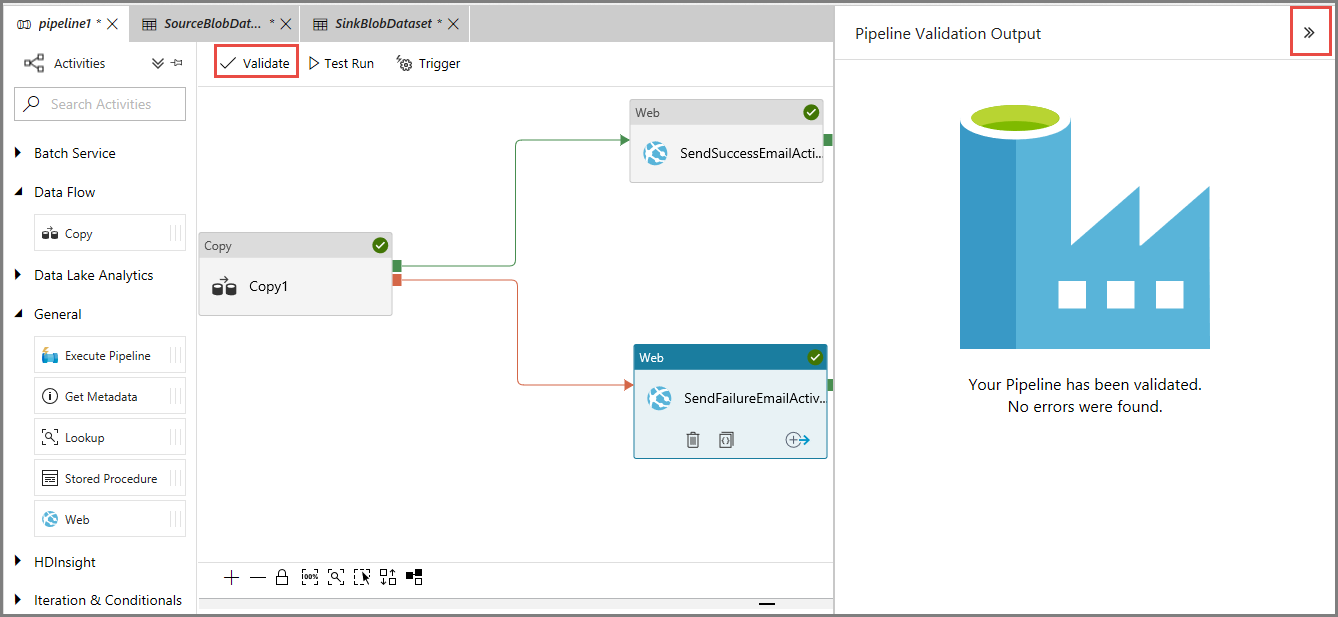
Per pubblicare le entità (set di dati, pipeline e così via) nel servizio Data Factory, selezionare Pubblica tutti. Attendere fino alla visualizzazione del messaggio Pubblicazione riuscita.

Attivare un'esecuzione della pipeline con esito positivo
Per attivare un'esecuzione della pipeline, fare clic su Trigger sulla barra degli strumenti e quindi su Trigger Now (Attiva adesso).
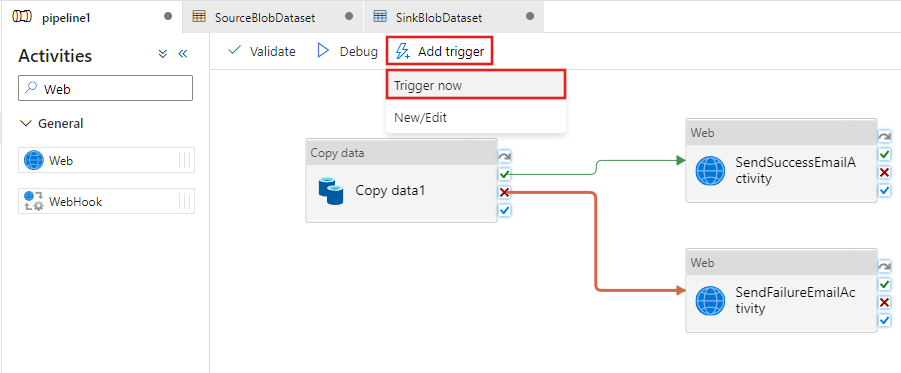
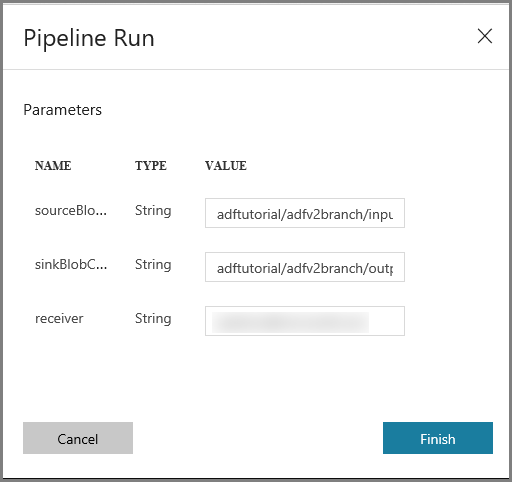
Nella finestra Pipeline Run (Esecuzioni di pipeline) seguire questa procedura:
Immettere adftutorial/adfv2branch/input per il parametro sourceBlobContainer.
Immettere adftutorial/adfv2branch/output per il parametro sinkBlobContainer.
Immettere un indirizzo di posta elettronica per receiver.
Fare clic su Fine
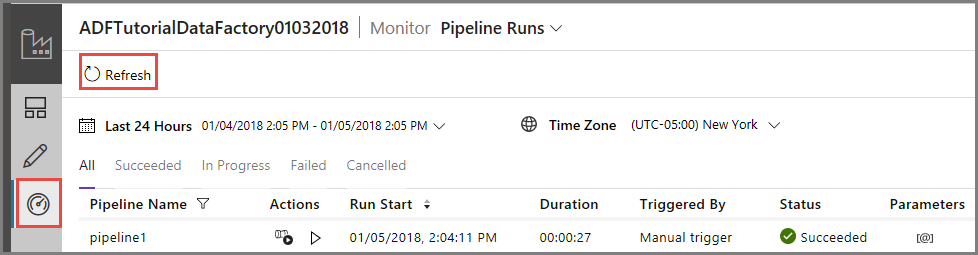
Monitorare l'esecuzione della pipeline con esito positivo
Per monitorare l'esecuzione della pipeline passare alla scheda Monitoraggio a sinistra. Viene visualizzata l'esecuzione della pipeline attivata manualmente in precedenza. Usare il pulsante Aggiorna per aggiornare l'elenco.
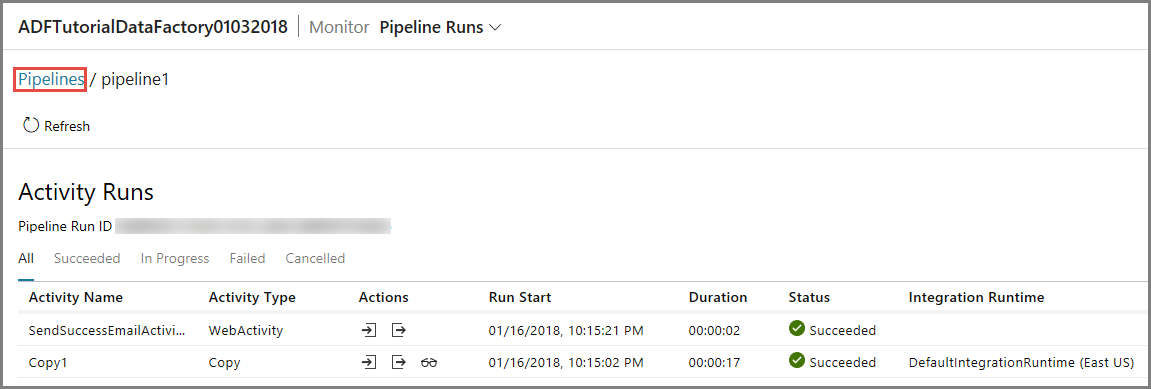
Per visualizzare le esecuzioni attività associate a questa esecuzione della pipeline, fare clic sul primo collegamento nella colonna Azioni. È possibile tornare alla visualizzazione precedente facendo clic su Pipeline in alto. Usare il pulsante Aggiorna per aggiornare l'elenco.
Attivare un'esecuzione della pipeline con esito negativo
Passare alla scheda Modifica a sinistra.
Per attivare un'esecuzione della pipeline, fare clic su Trigger sulla barra degli strumenti e quindi su Trigger Now (Attiva adesso).
Nella finestra Pipeline Run (Esecuzioni di pipeline) seguire questa procedura:
- Immettere adftutorial/dummy/input per il parametro sourceBlobContainer. Assicurarsi che la cartella fittizia non esista nel contenitore adftutorial.
- Immettere adftutorial/dummy/output per il parametro sinkBlobContainer.
- Immettere un indirizzo di posta elettronica per receiver.
- Fare clic su Fine.
Monitorare l'esecuzione della pipeline non riuscita
Per monitorare l'esecuzione della pipeline passare alla scheda Monitoraggio a sinistra. Viene visualizzata l'esecuzione della pipeline attivata manualmente in precedenza. Usare il pulsante Aggiorna per aggiornare l'elenco.
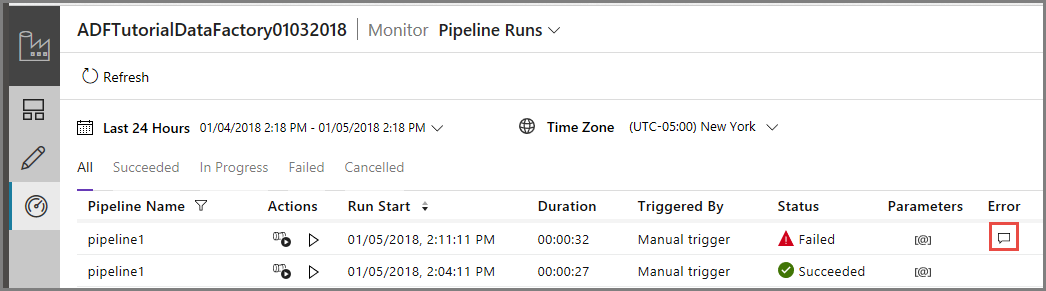
Fare clic sul collegamento Errore per l'esecuzione della pipeline per visualizzare i dettagli dell'errore.

Per visualizzare le esecuzioni attività associate a questa esecuzione della pipeline, fare clic sul primo collegamento nella colonna Azioni. Usare il pulsante Aggiorna per aggiornare l'elenco. Si noti che l'attività Copia nella pipeline ha avuto esito negativo. L'attività Web è riuscita a inviare il messaggio di posta elettronica di errore al destinatario specificato.
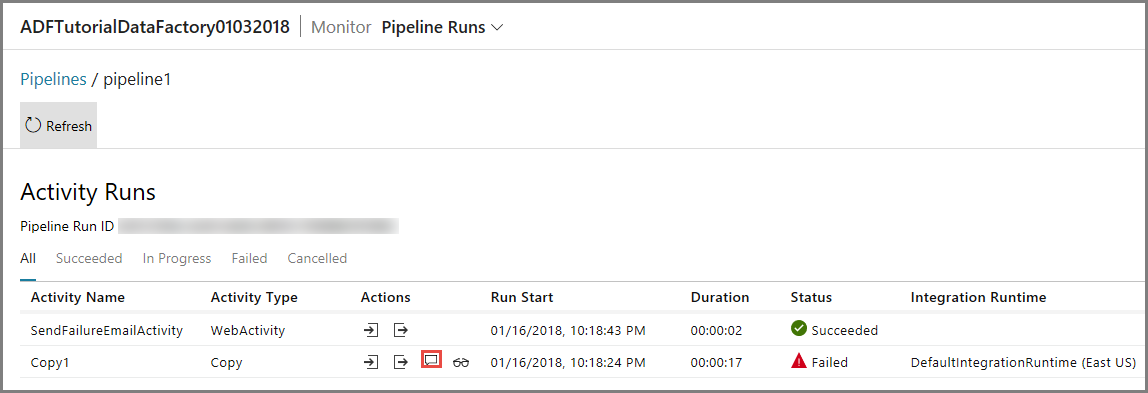
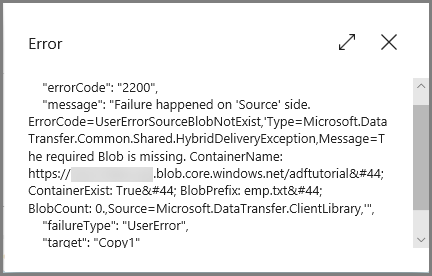
Fare clic sul collegamento Errore nella colonna Azioni per visualizzare informazioni dettagliate sull'errore.
Contenuto correlato
In questa esercitazione sono stati eseguiti i passaggi seguenti:
- Creare una data factory.
- Creare un servizio collegato Archiviazione di Azure
- Creare un set di dati del BLOB di Azure
- Creare una pipeline contenente un'attività di copia e un'attività Web
- Inviare gli output delle attività alle attività successive
- Utilizzare il passaggio di parametri e le variabili di sistema
- Avviare un'esecuzione della pipeline
- Monitorare le esecuzioni di pipeline e attività
È ora possibile passare alla sezione Concetti per altre informazioni su Azure Data Factory.