Monitorare l'utilizzo con i tag
Per monitorare i costi e attribuire con precisione l'utilizzo di Azure Databricks alle business unit e ai team dell'organizzazione (ad esempio, per i chargeback), è possibile contrassegnare le aree di lavoro (gruppi di risorse) e le risorse di calcolo. Questi tag vengono propagati ai report di analisi dei costi dettagliati a cui è possibile accedere nel portale di Azure.
Di seguito è riportato un report dei dettagli della fattura di analisi dei costi nel portale di Azure che descrive in dettaglio il costo in base al clusterid tag in un periodo di un mese:
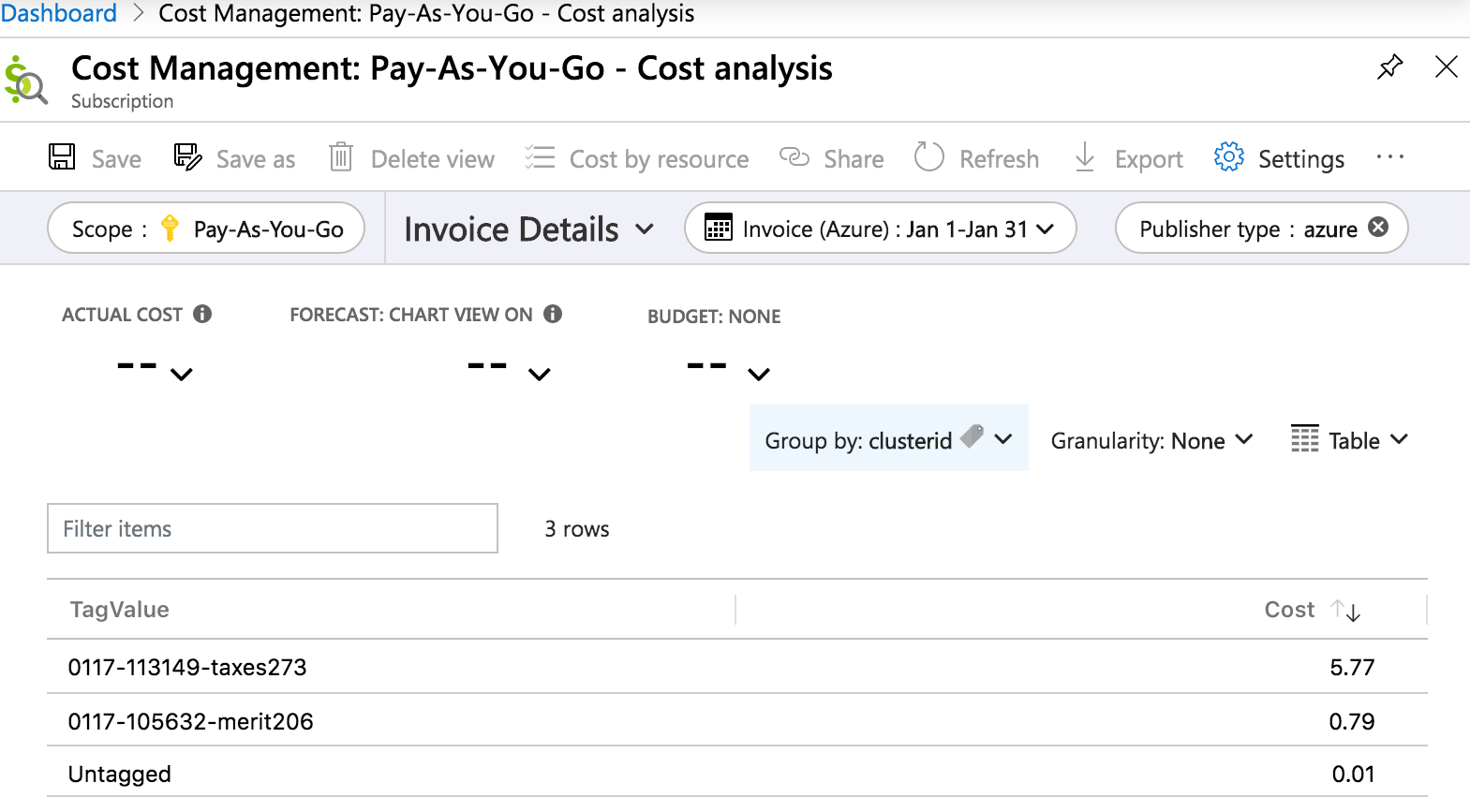
Risorse e oggetti con tag
| Object | Interfaccia di assegnazione di tag | Interfaccia di assegnazione di tag (API) |
|---|---|---|
| Area di lavoro | Portale di Azure | API risorse di Azure |
| Pool | Interfaccia utente dei pool nell'area di lavoro di Azure Databricks | API pool di istanze |
| Calcolo di tutti gli scopi e processi | Interfaccia utente di calcolo nell'area di lavoro di Azure Databricks | API per cluster |
| Warehouse SQL | Interfaccia utente di SQL Warehouse nell'area di lavoro di Azure Databricks | Warehouses API |
Avviso
Non assegnare un tag personalizzato con la chiave Name a un cluster. Ogni cluster ha un tag Name il cui valore è impostato da Azure Databricks. Se si modifica il valore associato alla chiave Name, il cluster non può più essere rilevato da Azure Databricks. Di conseguenza, il cluster potrebbe non essere terminato dopo essere diventato inattiva e continuerà a comportare costi di utilizzo.
Tag predefiniti
Azure Databricks aggiunge i tag predefiniti seguenti al calcolo all-purpose:
| Tasto tag | Valore |
|---|---|
Vendor |
Valore costante: Databricks |
ClusterId |
ID interno di Azure Databricks del cluster |
ClusterName |
Nome del cluster |
Creator |
Nome utente (indirizzo di posta elettronica) dell'utente che ha creato il cluster |
Nei cluster di processo, Azure Databricks applica anche i tag predefiniti seguenti:
| Tasto tag | Valore |
|---|---|
RunName |
Nome processo |
JobId |
ID processo |
Azure Databricks aggiunge i tag predefiniti seguenti a tutti i pool:
| Tasto tag | Valore |
|---|---|
Vendor |
Valore costante: Databricks |
DatabricksInstancePoolCreatorId |
ID interno di Azure Databricks dell'utente che ha creato il pool |
DatabricksInstancePoolId |
ID interno di Azure Databricks del pool |
Nel calcolo usato da Lakehouse Monitoring, Azure Databricks applica anche i tag seguenti:
| Tasto tag | Valore |
|---|---|
LakehouseMonitoring |
true |
LakehouseMonitoringTableId |
ID della tabella monitorata |
LakehouseMonitoringWorkspaceId |
ID dell'area di lavoro in cui è stato creato il monitoraggio |
LakehouseMonitoringMetastoreId |
ID del metastore in cui esiste la tabella monitorata |
Propagazione tag
I tag dell'area di lavoro, del pool e del cluster vengono aggregati da Azure Databricks e propagati alle macchine virtuali di Azure per la creazione di report di analisi dei costi. Ma i tag del pool e del cluster vengono propagati in modo diverso l'uno dall'altro.
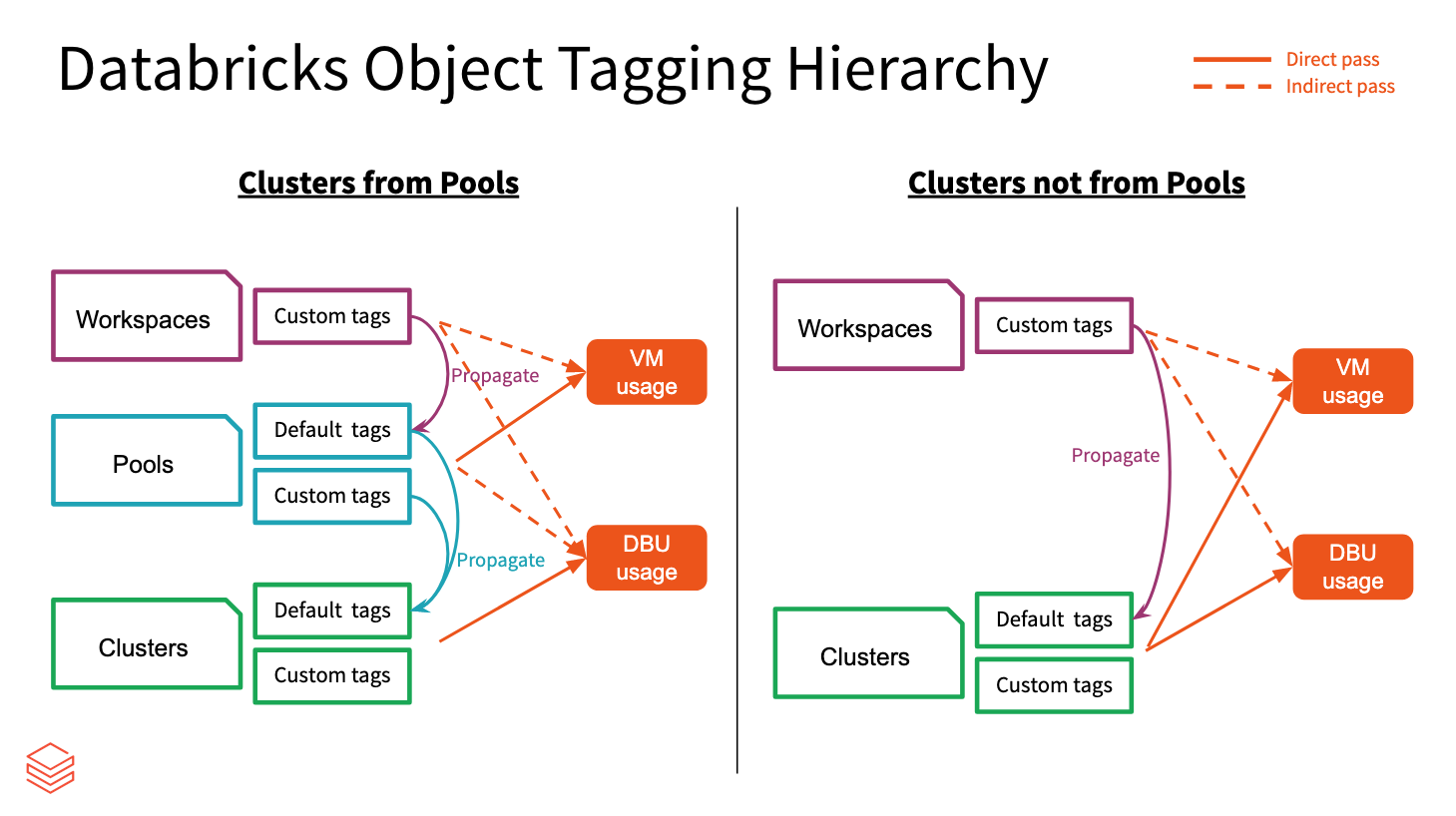
I tag dell'area di lavoro e del pool vengono aggregati e assegnati come tag di risorsa delle macchine virtuali di Azure che ospitano i pool.
I tag dell'area di lavoro e del cluster vengono aggregati e assegnati come tag di risorsa delle macchine virtuali di Azure che ospitano i cluster.
Quando i cluster vengono creati dai pool, solo i tag dell'area di lavoro e i tag del pool vengono propagati alle macchine virtuali. I tag del cluster non vengono propagati per mantenere le prestazioni di avvio del cluster del pool.
Risoluzione dei conflitti di tag
Se un tag del cluster personalizzato, un tag del pool o un tag dell'area di lavoro ha lo stesso nome di un cluster o un tag pool predefinito di Azure Databricks, il tag personalizzato viene preceduto da un x_ prefisso quando viene propagato.
Ad esempio, se un'area di lavoro è contrassegnata con vendor = Azure Databricks, tale tag sarà in conflitto con il tag vendor = Databrickscluster predefinito . I tag verranno quindi propagati come x_vendor = Azure Databricks e vendor = Databricks.
Limiti
- I tag personalizzati dell’area di lavoro possono richiedere fino a un'ora per essere propagati ad Azure Databricks dopo qualsiasi modifica.
- Non è possibile assegnare più di 50 tag a una risorsa di Azure. Se il numero complessivo di tag aggregati supera questo limite, i tag con prefisso
x_vengono valutati in ordine alfabetico e quelli che superano il limite vengono ignorati. Se tutti i tag con prefissox_vengono ignorati e il conteggio non supera il limite, i tag rimanenti vengono valutati in ordine alfabetico e quelli che superano il limite vengono ignorati. - Le chiavi e i valori dei tag possono contenere solo lettere, spazi, numeri o caratteri
+,=_.:-, ./@I tag contenenti altri caratteri non sono validi. - Se si modificano i nomi o i valori delle chiavi tag, queste modifiche si applicano solo dopo il riavvio del cluster o l'espansione del pool.
- Se i tag personalizzati del cluster sono in conflitto con i tag personalizzati di un pool, il cluster non può essere creato.
Applicazione di tag con criteri
È possibile applicare tag ai cluster usando i criteri di calcolo. Per altre informazioni, vedere Applicazione di tag personalizzati.