Esplorare e creare tabelle in DBFS
Importante
Questa documentazione è stata ritirata e potrebbe non essere aggiornata. I prodotti, i servizi o le tecnologie menzionati in questo contenuto non sono più supportati. Vedere Caricare file in Azure Databricks, Creare o modificare una tabella usando il caricamento di file e Che cos'è Esplora cataloghi?.
Accedere all'interfaccia utente di caricamento e creazione di tabelle del file DBFS legacy tramite l'interfaccia utente di aggiunta dei dati. Fare clic su ![]() Nuovo > file DBFS dati.>
Nuovo > file DBFS dati.>
È anche possibile accedere all'interfaccia utente dai notebook facendo clic su Aggiungi dati.>
Databricks consiglia di usare Esplora cataloghi per un'esperienza migliorata per la visualizzazione degli oggetti dati e la gestione degli elenchi di controllo di accesso e la pagina Crea o modifica tabella dal caricamento di file per inserire facilmente file di piccole dimensioni in Delta Lake.
Nota
La disponibilità di alcuni elementi descritti in questo articolo varia in base alle configurazioni dell'area di lavoro. Contattare l'amministratore dell'area di lavoro o il team dell'account di Azure Databricks.
Importare dati
Se nel computer locale sono presenti file di dati di piccole dimensioni da analizzare con Azure Databricks, è possibile importarli in DBFS usando l'interfaccia utente.
Nota
Gli amministratori dell'area di lavoro possono disabilitare questa funzionalità. Per altre informazioni, vedere Gestire il caricamento dei dati.
Creare una tabella
È possibile avviare l'interfaccia utente della tabella di creazione DBFS facendo clic su ![]() Nuovo nella barra laterale o sul pulsante DBFS nell'interfaccia utente aggiungi dati. È possibile popolare una tabella da file in DBFS o caricare file.
Nuovo nella barra laterale o sul pulsante DBFS nell'interfaccia utente aggiungi dati. È possibile popolare una tabella da file in DBFS o caricare file.
Con l'interfaccia utente è possibile creare solo tabelle esterne.
Scegliere un'origine dati e seguire i passaggi nella sezione corrispondente per configurare la tabella.
Se un amministratore dell'area di lavoro di Azure Databricks ha disabilitato l'opzione Carica file, non è possibile caricare file. È possibile creare tabelle usando una delle altre origini dati.
Istruzioni per il caricamento di file
- Trascinare i file nella zona di rilascio File o fare clic sulla zona di rilascio per esplorare e scegliere i file. Dopo il caricamento, viene visualizzato un percorso per ogni file. Il percorso sarà simile
/FileStore/tables/<filename>-<integer>.<file-type>a . È possibile usare questo percorso in un notebook per leggere i dati. - Fare clic su Crea tabella con l'interfaccia utente.
- Nell'elenco a discesa Cluster scegliere un cluster.
Istruzioni per DBFS
- Seleziona un file.
- Fare clic su Crea tabella con l'interfaccia utente.
- Nell'elenco a discesa Cluster scegliere un cluster.
- Trascinare i file nella zona di rilascio File o fare clic sulla zona di rilascio per esplorare e scegliere i file. Dopo il caricamento, viene visualizzato un percorso per ogni file. Il percorso sarà simile
Fare clic su Anteprima tabella per visualizzare la tabella.
Nel campo Nome tabella sostituire facoltativamente il nome predefinito della tabella. Un nome di tabella può contenere solo caratteri alfanumerici minuscoli e caratteri di sottolineatura e deve iniziare con una lettera minuscola o un carattere di sottolineatura.
Nel campo Crea nel database sostituire facoltativamente il database selezionato
default.Nel campo Tipo di file, facoltativamente, eseguire l'override del tipo di file dedotto.
Se il tipo di file è CSV:
- Nel campo Delimitatore di colonna selezionare se eseguire l'override del delimitatore dedotto.
- Indicare se utilizzare la prima riga come titoli di colonna.
- Indicare se dedurre lo schema.
Se il tipo di file è JSON, indicare se il file è su più righe.
Fare clic su Crea tabella.
Visualizzare database e tabelle
Nota
Le aree di lavoro con Esplora cataloghi abilitate non hanno accesso al comportamento legacy descritto di seguito.
Fare clic su ![]() Catalogo nella barra laterale. Azure Databricks seleziona un cluster in esecuzione a cui si ha accesso. Nella cartella Database viene visualizzato l'elenco dei database con il
Catalogo nella barra laterale. Azure Databricks seleziona un cluster in esecuzione a cui si ha accesso. Nella cartella Database viene visualizzato l'elenco dei database con il default database selezionato. Nella cartella Tabelle viene visualizzato l'elenco delle tabelle nel default database.
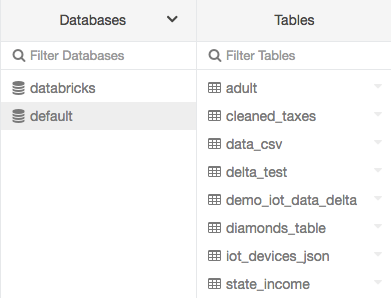
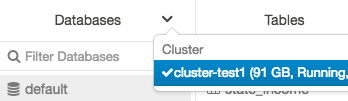
È possibile modificare il cluster dal menu Database, creare l'interfaccia utente della tabella o visualizzare l'interfaccia utente della tabella. Ad esempio, dal menu Database:
Fare clic sulla
 freccia giù nella parte superiore della cartella Database.
freccia giù nella parte superiore della cartella Database.Selezionare un cluster.
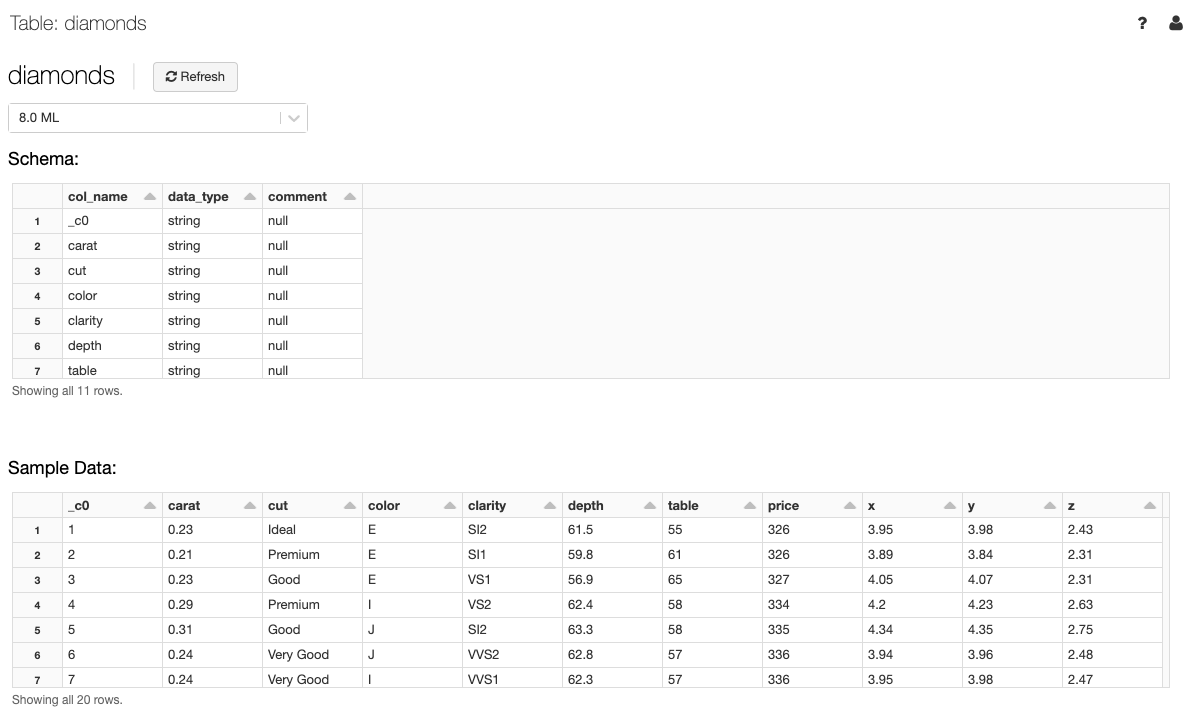
Visualizzare i dettagli della tabella
La vista dettagli tabella mostra lo schema della tabella e i dati di esempio.
Fare clic su
 Catalogo nella barra laterale.
Catalogo nella barra laterale.Nella cartella Database fare clic su un database.
Nella cartella Tabelle fare clic sul nome della tabella.
Nell'elenco a discesa Cluster selezionare facoltativamente un altro cluster per eseguire il rendering dell'anteprima della tabella.
Nota
Per visualizzare l'anteprima della tabella, viene eseguita una query Spark SQL nel cluster selezionato nell'elenco a discesa Cluster . Se nel cluster è già in esecuzione un carico di lavoro, l'anteprima della tabella potrebbe richiedere più tempo per il caricamento.
Eliminare una tabella usando l'interfaccia utente
- Fare clic su Catalogo nella barra laterale.
- Fare clic sul
 accanto al nome della tabella e selezionare Elimina.
accanto al nome della tabella e selezionare Elimina.