Elaborazione del flusso con Apache Kafka e Azure Databricks
Questo articolo descrive come usare Apache Kafka come origine o sink durante l'esecuzione di carichi di lavoro Structured Streaming in Azure Databricks.
Per altre informazioni su Kafka, vedere la documentazione di Kafka.
Leggere dati da Kafka
Di seguito è riportato un esempio di streaming letto da Kafka:
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "latest")
.load()
)
Azure Databricks supporta anche la semantica di lettura batch per le origini dati Kafka, come illustrato nell'esempio seguente:
df = (spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "earliest")
.option("endingOffsets", "latest")
.load()
)
Per il caricamento batch incrementale, Databricks consiglia di usare Kafka con Trigger.AvailableNow. Si veda Configurazione dell'elaborazione batch incrementale.
In Databricks Runtime 13.3 LTS e versioni successive, Azure Databricks fornisce una funzione SQL per la lettura dei dati Kafka. Lo streaming con SQL è supportato solo in tabelle Live Delta o con tabelle di streaming in Databricks SQL. Vedere Funzione con valori di tabella read_kafka.
Configurare il lettore di streaming strutturato Kafka
Azure Databricks fornisce la parola chiave kafka come formato dati per configurare le connessioni a Kafka 0.10+.
Le seguenti sono configurazioni comuni per Kafka:
Esistono diversi modi per specificare gli argomenti da sottoscrivere. È consigliabile specificare solo uno di questi parametri:
| Opzione | valore | Descrizione |
|---|---|---|
| subscribe | Elenco di argomenti delimitati da virgole. | Elenco di argomenti a cui sottoscrivere. |
| subscribePattern | Stringa regex Java. | Modello utilizzato per sottoscrivere gli argomenti. |
| assign | Stringa JSON {"topicA":[0,1],"topic":[2,4]}. |
topicPartitions specifico da utilizzare. |
Altre configurazioni rilevanti:
| Opzione | Valore | Valore predefinito | Descrizione |
|---|---|---|---|
| kafka.bootstrap.servers | Elenco delimitato da virgole di host:port. | empty | [Necessario] Configurazione Kafka bootstrap.servers. Se non sono presenti dati da Kafka, controllare prima l'elenco di indirizzi del broker. Se l'elenco di indirizzi del broker non è corretto, potrebbero non esserci errori. Ciò è dovuto al fatto che il client Kafka presuppone che i broker diventino disponibili alla fine e, in caso di errori di rete, riprovare per sempre. |
| failOnDataLoss | true o false. |
true |
[Facoltativo] Indica se la query non riesce quando è possibile che i dati siano andato persi. Le query possono non riuscire a leggere in modo permanente i dati da Kafka a causa di molti scenari, ad esempio argomenti eliminati, troncamento degli argomenti prima dell'elaborazione e così via. Si tenta di stimare in modo conservativo se i dati sono stati probabilmente persi o meno. A volte questo può causare falsi allarmi. Impostare questa opzione su false se non funziona come previsto o si vuole che la query continui l'elaborazione nonostante la perdita di dati. |
| minPartitions | Intero >= 0, 0 = disabilitato. | 0 (disabilitata) | [Facoltativo] Numero minimo di partizioni da leggere da Kafka. È possibile configurare Spark per usare un minimo arbitrario di partizioni da leggere da Kafka usando l'opzione minPartitions. In genere Spark ha un mapping 1-1 di Kafka topicPartitions alle partizioni Spark che utilizzano da Kafka. Se si imposta l'opzione minPartitions su un valore maggiore di Kafka topicPartitions, Spark eseguirà il riepilogo delle partizioni Kafka di grandi dimensioni su parti più piccole. Questa opzione può essere impostata in momenti di picco di caricamento, sfasamento dei dati e man mano che il flusso è in ritardo per aumentare la velocità di elaborazione. Si tratta di un costo di inizializzazione dei consumer Kafka in ogni trigger, che può influire sulle prestazioni se si usa SSL durante la connessione a Kafka. |
| kafka.group.id | ID gruppo di consumer Kafka. | non impostato | [Facoltativo] ID gruppo da usare durante la lettura da Kafka. Usare con cautela. Per impostazione predefinita, ogni query genera un ID gruppo univoco per la lettura dei dati. In questo modo ogni query ha un proprio gruppo di consumer che non presenta interferenze da nessun altro consumer e pertanto può leggere tutte le partizioni degli argomenti sottoscritti. In alcuni scenari, ad esempio l'autorizzazione basata su gruppo Kafka, è possibile usare ID gruppo autorizzati specifici per leggere i dati. Facoltativamente, è possibile impostare l'ID gruppo. Tuttavia, eseguire questa operazione con estrema cautela perché può causare comportamenti imprevisti. - Le query eseguite simultaneamente (sia batch che streaming) con lo stesso ID gruppo interferiscono probabilmente tra loro, causando la sola lettura di parte dei dati da parte di ogni query. - Ciò può verificarsi anche quando le query vengono avviate/riavviate in rapida successione. Per ridurre al minimo questi problemi, impostare la configurazione session.timeout.ms del consumer Kafka in modo che sia molto piccola. |
| startingOffsets | meno recente , più recente | più recente | [Facoltativo] Punto iniziale all'avvio di una query, ovvero "meno recente" proveniente dai primi offset o da una stringa json che specifica un offset iniziale per ogni TopicPartition. Nel file json, -2 come offset può essere usato per fare riferimento alla prima versione, -1 alla versione più recente. Nota: per le query batch, la versione più recente (implicitamente o tramite -1 in json) non è consentita. Per le query di streaming, questo vale solo quando viene avviata una nuova query e che la ripresa riprenderà sempre da dove la query è stata interrotta. Le nuove partizioni individuate durante una query inizieranno al più presto. |
Per altre configurazioni facoltative, vedere Guida all'integrazione di Structured Streaming Kafka.
Schema per i record Kafka
Lo schema dei record Kafka è:
| Column | Type |
|---|---|
| key | binary |
| value | binary |
| argomento | string |
| denominata | int |
| offset | long |
| timestamp | long |
| timestampType | int |
key e value vengono sempre deserializzati come matrici di byte con ByteArrayDeserializer. Usare operazioni dataframe (ad esempio cast("string")) per deserializzare in modo esplicito le chiavi e i valori.
Scrivere dati in Kafka
Di seguito è riportato un esempio di scrittura di streaming in Kafka:
(df
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.start()
)
Azure Databricks supporta anche la semantica di scrittura batch nei sink di dati Kafka, come illustrato nell'esempio seguente:
(df
.write
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.save()
)
Configurare il writer di streaming strutturato Kafka
Importante
Databricks Runtime 13.3 LTS e versioni successive include una versione più recente della libreria kafka-clients che abilita le scritture idempotenti per impostazione predefinita. Se un sink Kafka usa la versione 2.8.0 o successiva con ACL configurati, ma senza IDEMPOTENT_WRITE abilitato, la scrittura non riesce con il messaggio di errore org.apache.kafka.common.KafkaException: Cannot execute transactional method because we are in an error state.
Risolvere questo errore eseguendo l'aggiornamento a Kafka versione 2.8.0 o successiva oppure impostando .option(“kafka.enable.idempotence”, “false”) durante la configurazione del writer Structured Streaming.
Lo schema fornito a DataStreamWriter interagisce con il sink Kafka. Puoi usare i seguenti campi:
| Nome colonna | Obbligatorio o facoltativo | Type |
|---|---|---|
key |
facoltative | STRING oppure BINARY |
value |
Obbligatorio | STRING oppure BINARY |
headers |
facoltative | ARRAY |
topic |
facoltativo (ignorato se topic è impostato come opzione writer) |
STRING |
partition |
facoltative | INT |
Di seguito sono riportate le opzioni comuni impostate durante la scrittura in Kafka:
| Opzione | Valore | Default value | Descrizione |
|---|---|---|---|
kafka.boostrap.servers |
Elenco delimitato da virgole di <host:port> |
Nessuno | [Necessario] Configurazione Kafka bootstrap.servers. |
topic |
STRING |
non impostato | [Facoltativo] Imposta l'argomento per tutte le righe da scrivere. Questa opzione esegue l'override di qualsiasi colonna di argomento presente nei dati. |
includeHeaders |
BOOLEAN |
false |
[Facoltativo] Indica se includere le intestazioni Kafka nella riga. |
Per altre configurazioni facoltative, vedere Guida all'integrazione di Structured Streaming Kafka.
Recuperare le metriche Kafka
È possibile ottenere la media, min e il numero massimo di offset che la query di streaming è dietro l'offset disponibile più recente tra tutti gli argomenti sottoscritti con le metriche avgOffsetsBehindLatest, maxOffsetsBehindLatest e minOffsetsBehindLatest. Vedere Lettura interattiva delle metriche.
Nota
Disponibile in Databricks Runtime 9.1 e versioni successive.
Ottenere il numero totale stimato di byte che il processo di query non ha utilizzato dagli argomenti sottoscritti esaminando il valore di estimatedTotalBytesBehindLatest. Questa stima è basata sui batch elaborati negli ultimi 300 secondi. L'intervallo di tempo su cui si basa la stima può essere modificato impostando l'opzione bytesEstimateWindowLength su un valore diverso. Ad esempio, per impostarlo su 10 minuti:
df = (spark.readStream
.format("kafka")
.option("bytesEstimateWindowLength", "10m") # m for minutes, you can also use "600s" for 600 seconds
)
Se si esegue il flusso in un notebook, è possibile visualizzare queste metriche nella scheda Dati non elaborati nel dashboard di stato della query di streaming:
{
"sources" : [ {
"description" : "KafkaV2[Subscribe[topic]]",
"metrics" : {
"avgOffsetsBehindLatest" : "4.0",
"maxOffsetsBehindLatest" : "4",
"minOffsetsBehindLatest" : "4",
"estimatedTotalBytesBehindLatest" : "80.0"
},
} ]
}
Usare SSL per connettere Azure Databricks a Kafka
Per abilitare le connessioni SSL a Kafka, seguire le istruzioni nella documentazione di Confluent Crittografia e autenticazione con SSL. È possibile specificare le configurazioni descritte, precedute da kafka., come opzioni. Ad esempio, si specifica il percorso dell'archivio attendibilità nella proprietà kafka.ssl.truststore.location.
Databricks consiglia:
- Archiviare i certificati nell'archiviazione di oggetti cloud. È possibile limitare l'accesso ai certificati solo ai cluster che possono accedere a Kafka. Vedere Governance dei dati con Catalogo Unity.
- Archiviare le password del certificato come segreti in un ambito segreto.
L'esempio seguente usa i percorsi di archiviazione degli oggetti e i segreti di Databricks per abilitare una connessione SSL:
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", ...)
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.ssl.truststore.location", <truststore-location>)
.option("kafka.ssl.keystore.location", <keystore-location>)
.option("kafka.ssl.keystore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<keystore-password-key-name>))
.option("kafka.ssl.truststore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<truststore-password-key-name>))
)
Connettere Kafka in HDInsight ad Azure Databricks
Creare un cluster Kafka in HDInsight.
Vedere Connettersi a Kafka in HDInsight tramite una rete virtuale di Azure per le istruzioni.
Configurare i broker Kafka per annunciare l'indirizzo corretto.
Seguire le istruzioni in Configurare Kafka per la pubblicità IP. Se si gestisce Kafka in Azure Macchine virtuali, assicurarsi che la configurazione
advertised.listenersdei broker sia impostata sull'indirizzo IP interno degli host.Creare un cluster di Azure Databricks.
Eseguire il peering del cluster Kafka al cluster Azure Databricks.
Seguire le istruzioni in Reti virtuali peer.
Autenticazione entità servizio con Microsoft Entra ID e Azure Event Hub
Azure Databricks supporta l'autenticazione dei processi Spark con i servizi di Hub eventi. Questa autenticazione viene eseguita tramite OAuth con Microsoft Entra ID.
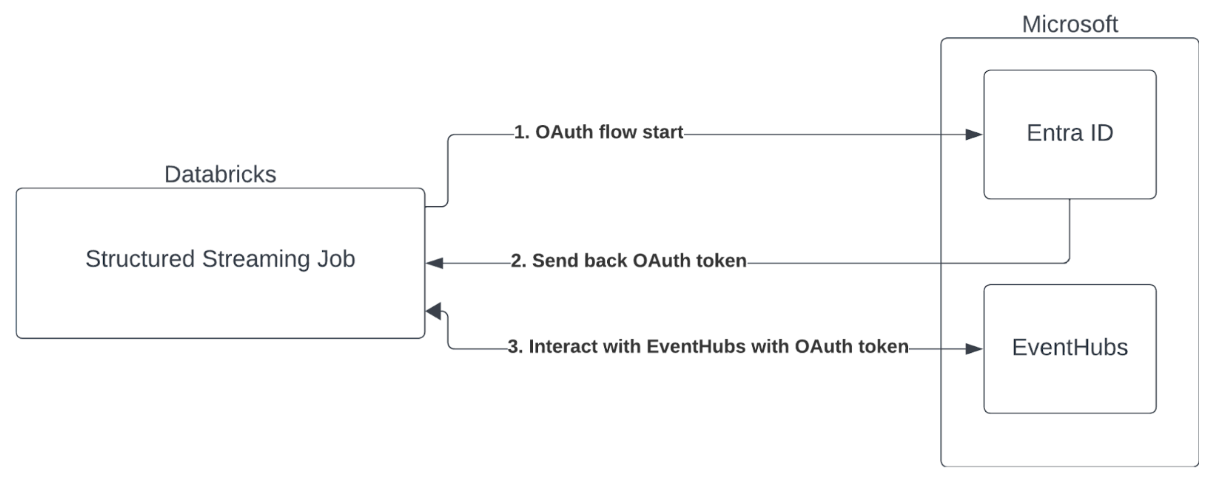
Azure Databricks supporta l'autenticazione con ID Microsoft Entra con un ID client e un segreto negli ambienti di calcolo seguenti:
- Databricks Runtime 12.2 LTS e versioni successive su un calcolo configurato con modalità di accesso utente singolo.
- Databricks Runtime 14.3 LTS e versioni successive su un calcolo configurato con modalità di accesso condiviso.
- Pipeline Delta Live Tables configurate senza catalogo Unity.
Azure Databricks non supporta l'autenticazione di Microsoft Entra ID con un certificato in qualsiasi ambiente di calcolo o nelle pipeline delta live tables configurate con catalogo Unity.
Questa autenticazione non funziona nei cluster condivisi o nelle tabelle Live Delta del catalogo Unity.
Configurazione del connettore Kafka Structured Streaming
Per eseguire l'autenticazione con Microsoft Entra ID, sono necessari i valori seguenti:
Un tenant ID. È possibile trovarla nella scheda Servizi Microsoft Entra ID.
ID client (noto anche come ID applicazione).
Segreto client. Una volta ottenuto questo, è necessario aggiungerlo come segreto all'area di lavoro di Databricks. Per aggiungere questo segreto, vedere Gestione dei segreti.
Argomento di EventHubs. È possibile trovare un elenco di argomenti nella sezione Hub eventi nella sezione Entità in una pagina specifica dello spazio dei nomi di Hub eventi. Per usare più argomenti, è possibile impostare il ruolo IAM a livello di Hub eventi.
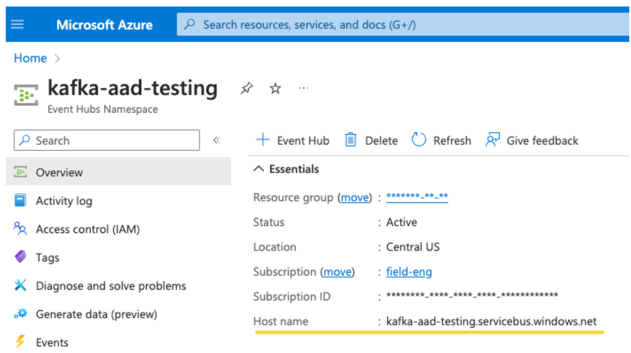
Un server EventHubs. È possibile trovarla nella pagina di panoramica dello spazio dei nomi di Hub eventi specifico:
Inoltre, per usare Entra ID, è necessario indicare a Kafka di usare il meccanismo SASL OAuth (SASL è un protocollo generico e OAuth è un tipo di "meccanismo" SASL):
kafka.security.protocoldeve essereSASL_SSLkafka.sasl.mechanismdeve essereOAUTHBEARERkafka.sasl.login.callback.handler.classdeve essere un nome completo della classe Java con un valore pari akafkashadedal gestore di callback di accesso della classe Kafka ombreggiata. Vedere l'esempio seguente per la classe esatta.
Esempio
Si esaminerà quindi un esempio in esecuzione:
Python
# This is the only section you need to modify for auth purposes!
# ------------------------------
tenant_id = "..."
client_id = "..."
client_secret = dbutils.secrets.get("your-scope", "your-secret-name")
event_hubs_server = "..."
event_hubs_topic = "..."
# -------------------------------
sasl_config = f'kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="{client_id}" clientSecret="{client_secret}" scope="https://{event_hubs_server}/.default" ssl.protocol="SSL";'
kafka_options = {
# Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers": f"{event_hubs_server}:9093",
"kafka.sasl.jaas.config": sasl_config,
"kafka.sasl.oauthbearer.token.endpoint.url": f"https://login.microsoft.com/{tenant_id}/oauth2/v2.0/token",
"subscribe": event_hubs_topic,
# You should not need to modify these
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class": "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
}
df = spark.readStream.format("kafka").options(**kafka_options)
display(df)
Scala
// This is the only section you need to modify for auth purposes!
// -------------------------------
val tenantId = "..."
val clientId = "..."
val clientSecret = dbutils.secrets.get("your-scope", "your-secret-name")
val eventHubsServer = "..."
val eventHubsTopic = "..."
// -------------------------------
val saslConfig = s"""kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="$clientId" clientSecret="$clientSecret" scope="https://$eventHubsServer/.default" ssl.protocol="SSL";"""
val kafkaOptions = Map(
// Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers" -> s"$eventHubsServer:9093",
"kafka.sasl.jaas.config" -> saslConfig,
"kafka.sasl.oauthbearer.token.endpoint.url" -> s"https://login.microsoft.com/$tenantId/oauth2/v2.0/token",
"subscribe" -> eventHubsTopic,
// You should not need to modify these
"kafka.security.protocol" -> "SASL_SSL",
"kafka.sasl.mechanism" -> "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class" -> "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
)
val scalaDF = spark.readStream
.format("kafka")
.options(kafkaOptions)
.load()
display(scalaDF)
Gestione degli errori potenziali
Le opzioni di streaming non sono supportate.
Se si tenta di usare questo meccanismo di autenticazione in una pipeline delta live tables configurata con catalogo Unity, è possibile che venga visualizzato l'errore seguente:
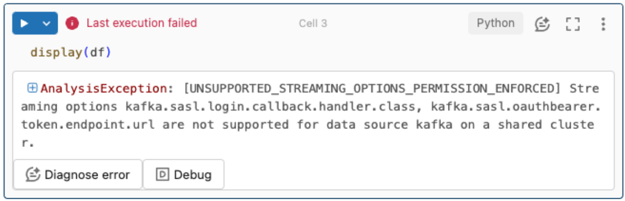
Per risolvere questo errore, usare una configurazione di calcolo supportata. Vedere Autenticazione entità servizio con Microsoft Entra ID e Azure Event Hub.
Impossibile creare una nuova
KafkaAdminClient.Si tratta di un errore interno che Kafka genera se una delle opzioni di autenticazione seguenti non è corretta:
- ID client (detto anche ID applicazione)
- ID tenant
- Server EventHubs
Per risolvere l'errore, verificare che i valori siano corretti per queste opzioni.
Inoltre, è possibile che venga visualizzato questo errore se si modificano le opzioni di configurazione fornite per impostazione predefinita nell'esempio (a cui è stato chiesto di non modificare), ad esempio
kafka.security.protocol.Non vengono restituiti record
Se si sta tentando di visualizzare o elaborare il dataframe ma non si ottengono risultati, nell'interfaccia utente verrà visualizzato quanto segue.
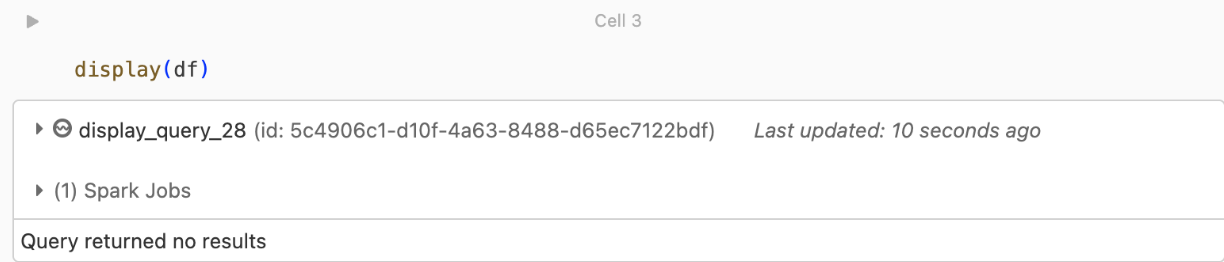
Questo messaggio indica che l'autenticazione ha avuto esito positivo, ma EventHubs non ha restituito dati. Alcuni possibili motivi (anche se non esaustivi) sono:
- È stato specificato l'argomento EventHubs errato.
- L'opzione di configurazione Kafka predefinita per
startingOffsetsèlateste attualmente non si ricevono dati tramite l'argomento. È possibile impostarestartingOffsetstoearliestper iniziare a leggere i dati a partire dai primi offset di Kafka.