Esecuzione adattiva di query
L'esecuzione di query adattive è la riottimizzazione delle query che si verifica durante l'esecuzione delle query.
La motivazione per la riottimizzazione del runtime è che Azure Databricks ha le statistiche più aggiornate accurate alla fine di uno scambio casuale e di trasmissione (detto fase di query in AQE). Di conseguenza, Azure Databricks può scegliere una strategia fisica migliore, scegliere una dimensione e un numero di partizioni post-shuffle ottimali oppure eseguire ottimizzazioni usate per richiedere suggerimenti, ad esempio la gestione dell'asimmetria dei join.
Ciò può essere molto utile quando la raccolta delle statistiche non è attivata o quando le statistiche non sono aggiornate. È utile anche in posizioni in cui le statistiche derivate in modo statico sono imprecise, ad esempio al centro di una query complessa o dopo l'occorrenza di asimmetrie dei dati.
Funzionalità
AQE è abilitato per impostazione predefinita. Ha 4 funzionalità principali:
- Modifica dinamicamente l'ordinamento del merge join in broadcast hash join.
- Unisce dinamicamente le partizioni (combinano partizioni di piccole dimensioni in partizioni ragionevolmente ridimensionate) dopo lo scambio casuale. Le attività molto piccole hanno una velocità effettiva di I/O peggiore e tendono a soffrire di più dalla pianificazione del sovraccarico e dall'overhead di configurazione delle attività. La combinazione di attività di piccole dimensioni consente di risparmiare risorse e migliorare la velocità effettiva del cluster.
- Gestisce dinamicamente l'asimmetria nell'ordinamento del join di tipo merge e il join hash casuale suddividendo (e replicando, se necessario) attività asimmetrica in attività di dimensioni approssimative.
- Rileva e propaga dinamicamente le relazioni vuote.
Applicazione
AQE si applica a tutte le query che sono:
- Non in streaming
- Contiene almeno uno scambio (in genere quando è presente un join, un'aggregazione o una finestra), una sottoquery o entrambe.
Non tutte le query applicate a AQE sono necessariamente ottimizzate di nuovo. La riottimizzazione potrebbe o non essere disponibile con un piano di query diverso da quello compilato in modo statico. Per determinare se il piano di una query è stato modificato da AQE, vedere la sezione Seguente, Piani di query.
Piani di query
In questa sezione viene illustrato come esaminare i piani di query in modi diversi.
Contenuto della sezione:
Interfaccia utente di Spark
Nodo AdaptiveSparkPlan
Le query applicate aQE contengono uno o più AdaptiveSparkPlan nodi, in genere come nodo radice di ogni query principale o sottoquery.
Prima dell'esecuzione della query o quando è in esecuzione, il isFinalPlan flag del nodo corrispondente AdaptiveSparkPlan viene visualizzato come false; al termine dell'esecuzione della query, il isFinalPlan flag viene modificato in true.
Piano in evoluzione
Il diagramma del piano di query si evolve man mano che l'esecuzione avanza e riflette il piano più recente in esecuzione. I nodi che sono già stati eseguiti (in cui sono disponibili le metriche) non cambiano, ma quelli che non possono cambiare nel tempo in seguito alle riottimizzazione.
Di seguito è riportato un esempio di diagramma del piano di query:
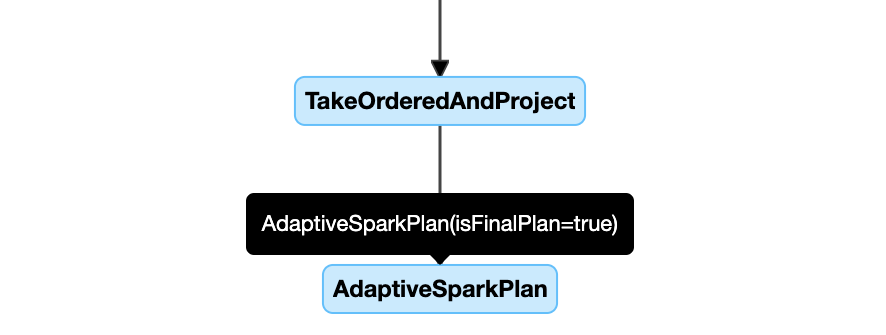
DataFrame.explain()
Nodo AdaptiveSparkPlan
Le query applicate aQE contengono uno o più AdaptiveSparkPlan nodi, in genere come nodo radice di ogni query principale o sottoquery. Prima dell'esecuzione della query o quando è in esecuzione, il isFinalPlan flag del nodo corrispondente AdaptiveSparkPlan viene visualizzato come false; al termine dell'esecuzione della query, il isFinalPlan flag viene modificato in true.
Piano corrente e iniziale
In ogni AdaptiveSparkPlan nodo sarà presente sia il piano iniziale (il piano prima di applicare eventuali ottimizzazioni AQE) sia il piano corrente o finale, a seconda che l'esecuzione sia stata completata. Il piano corrente si evolverà man mano che l'esecuzione procede.
Statistiche di runtime
Ogni fase di riproduzione casuale e broadcast contiene statistiche dei dati.
Prima dell'esecuzione della fase o dell'esecuzione della fase, le statistiche sono stime in fase di compilazione e il flag isRuntime è false, ad esempio: Statistics(sizeInBytes=1024.0 KiB, rowCount=4, isRuntime=false);
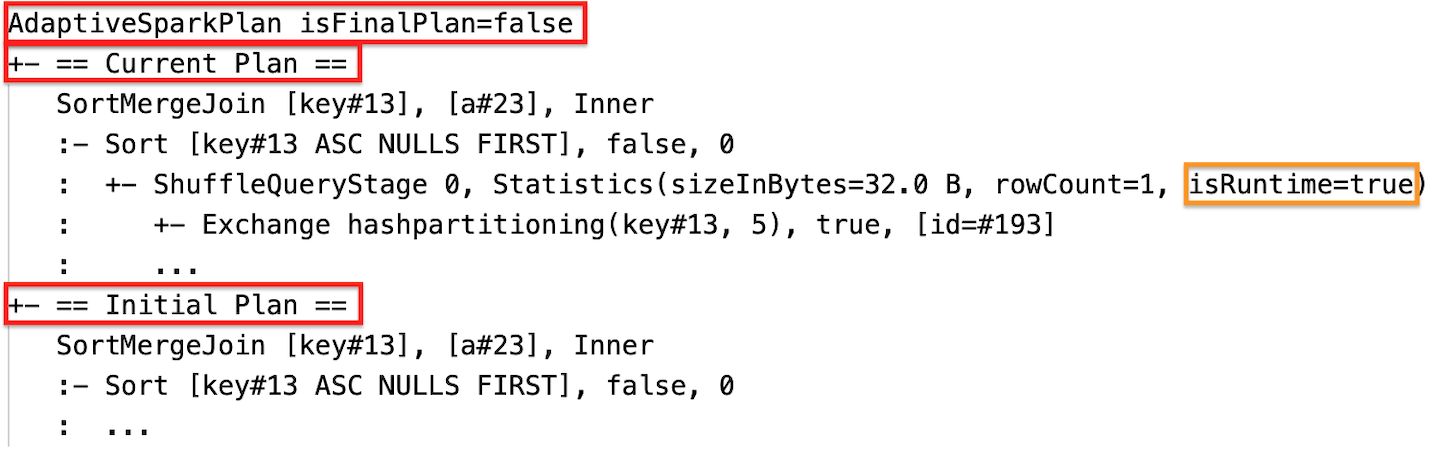
Al termine dell'esecuzione della fase, le statistiche vengono raccolte in fase di esecuzione e il flag isRuntime diventerà true, ad esempio: Statistics(sizeInBytes=658.1 KiB, rowCount=2.81E+4, isRuntime=true)
Di seguito è riportato un DataFrame.explain esempio:
Prima dell'esecuzione
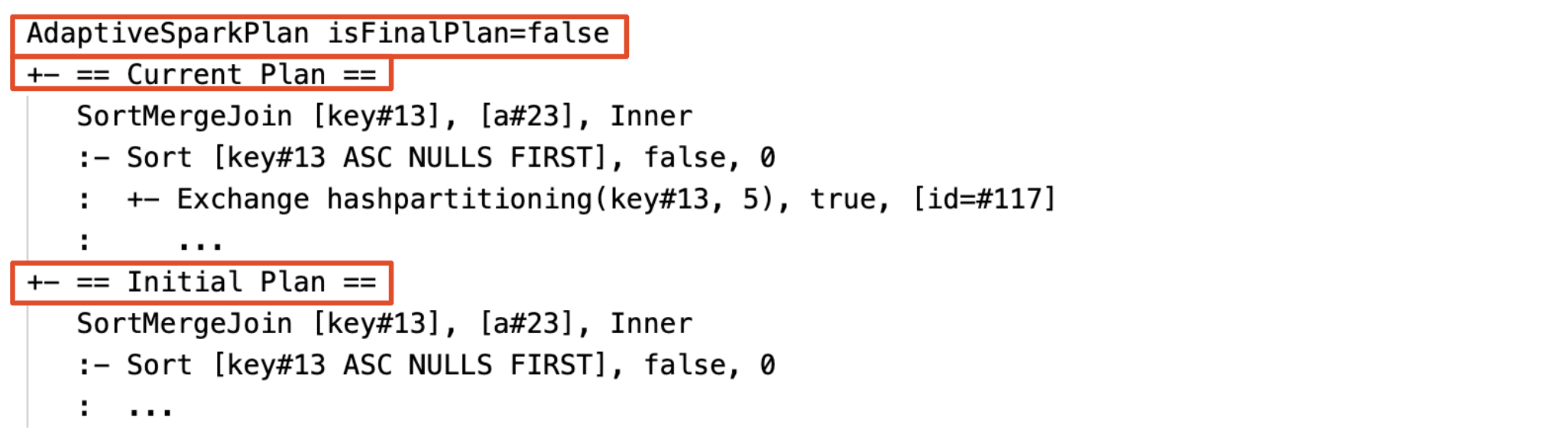
Durante l'esecuzione
Dopo l'esecuzione
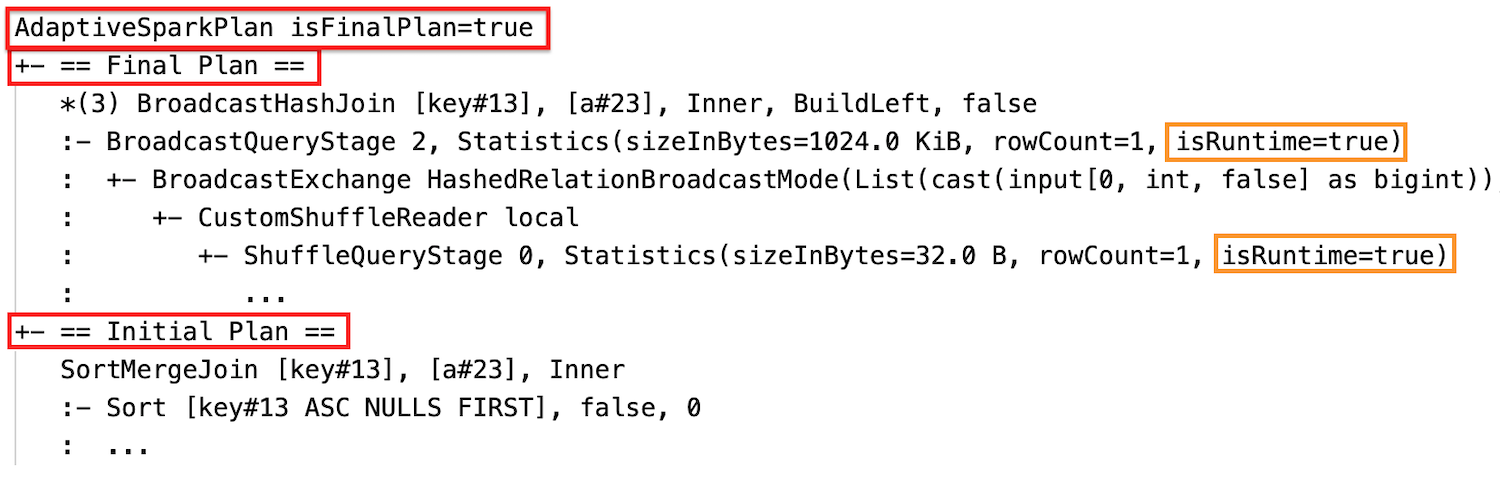
SQL EXPLAIN
Nodo AdaptiveSparkPlan
Le query applicate aQE contengono uno o più nodi AdaptiveSparkPlan, in genere come nodo radice di ogni query principale o sottoquery.
Nessun piano corrente
Come SQL EXPLAIN non esegue la query, il piano corrente è sempre uguale al piano iniziale e non riflette ciò che alla fine verrebbe eseguito da AQE.
Di seguito è riportato un esempio di spiegazione DI SQL:

Efficacia
Il piano di query cambierà se una o più ottimizzazioni di AQE diventano effettive. L'effetto di queste ottimizzazioni AQE è dimostrato dalla differenza tra i piani correnti e finali e il piano iniziale e i nodi di piano specifici nei piani correnti e finali.
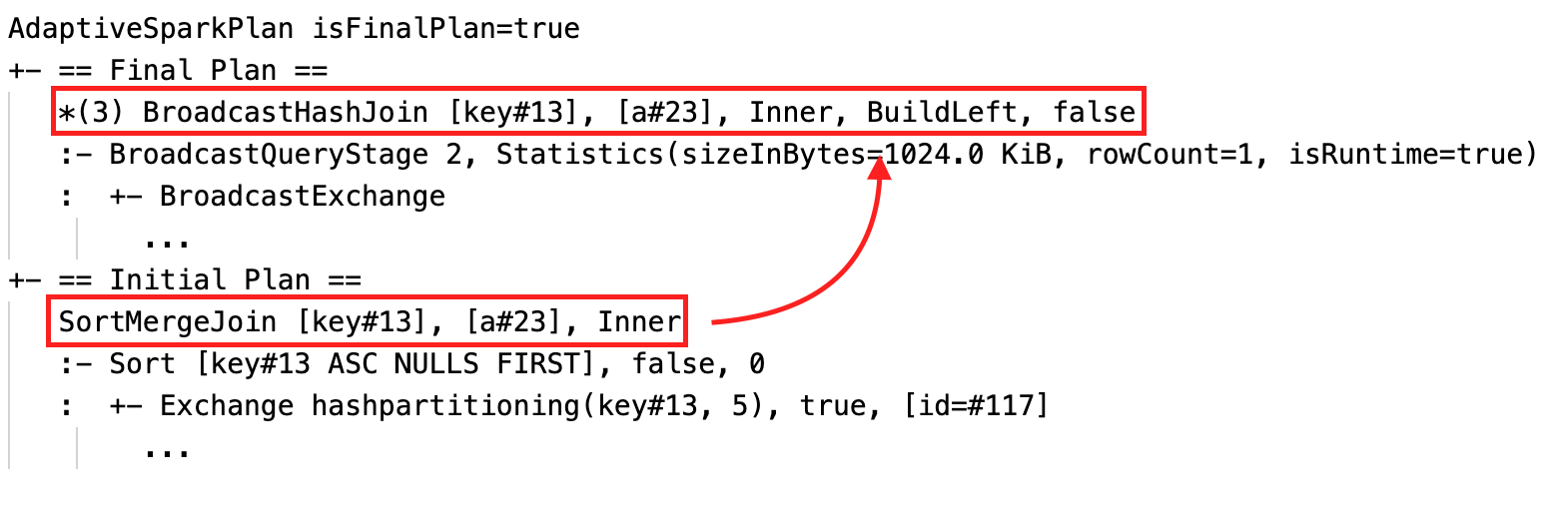
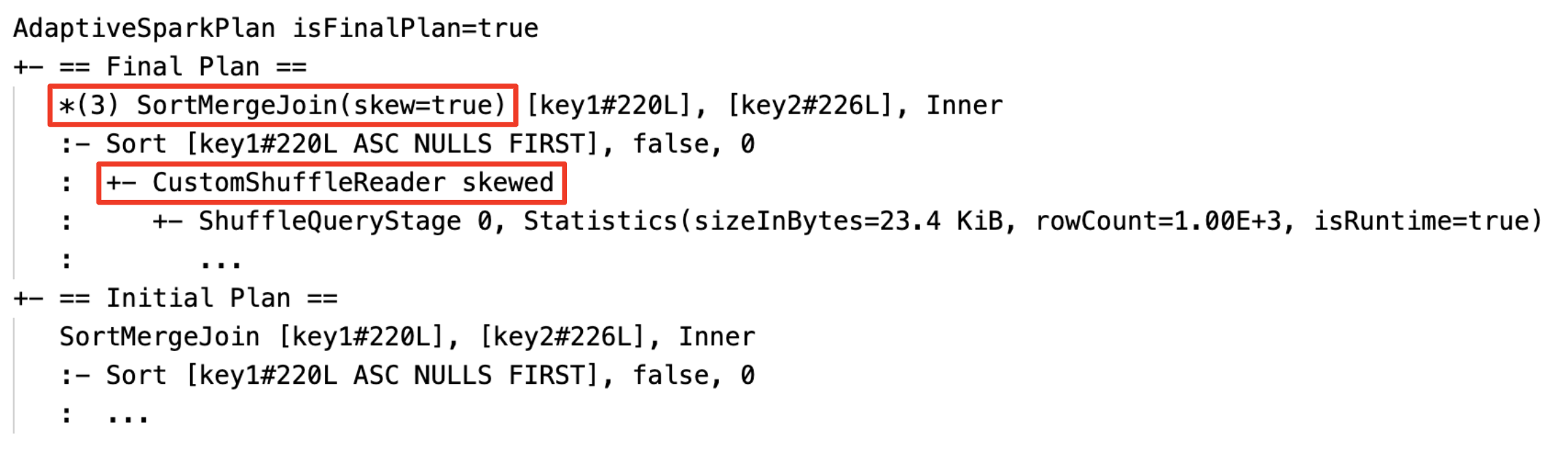
Modificare dinamicamente l'unione di ordinamento in broadcast hash join: nodi di join fisici diversi tra il piano corrente/finale e il piano iniziale
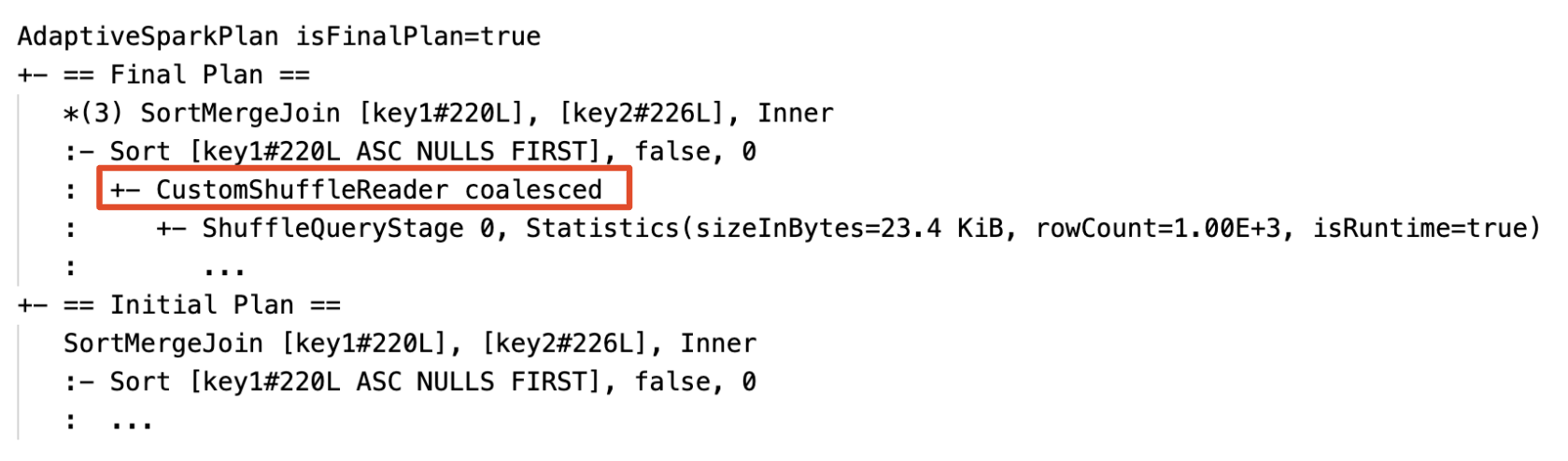
Unire dinamicamente le partizioni: nodo
CustomShuffleReadercon proprietàCoalesced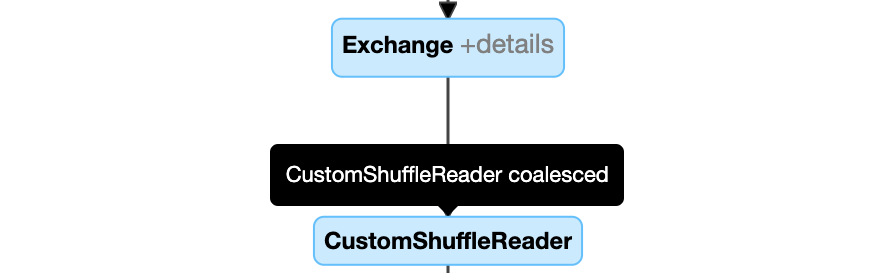
Gestire dinamicamente l'asimmetria join: nodo
SortMergeJoincon campoisSkewtrue.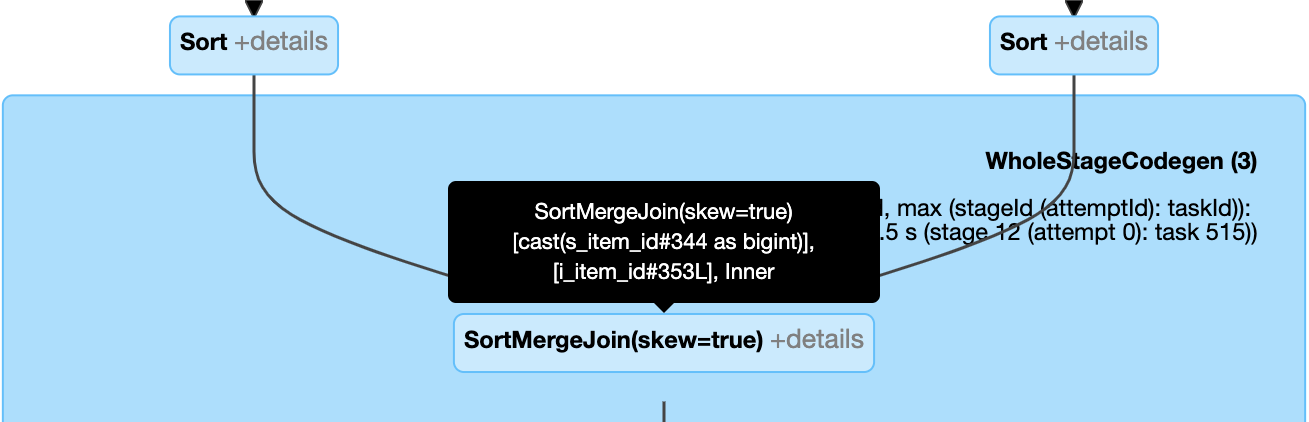
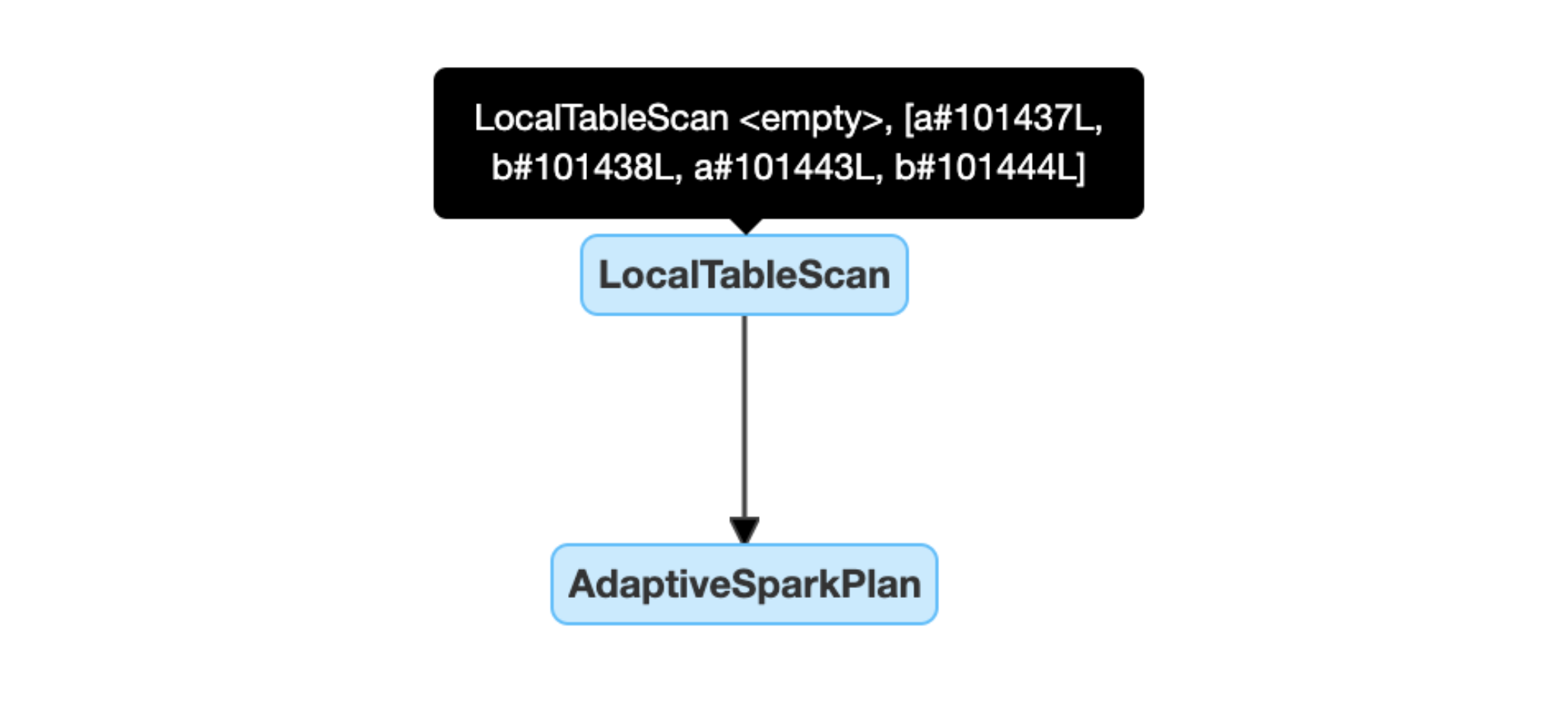
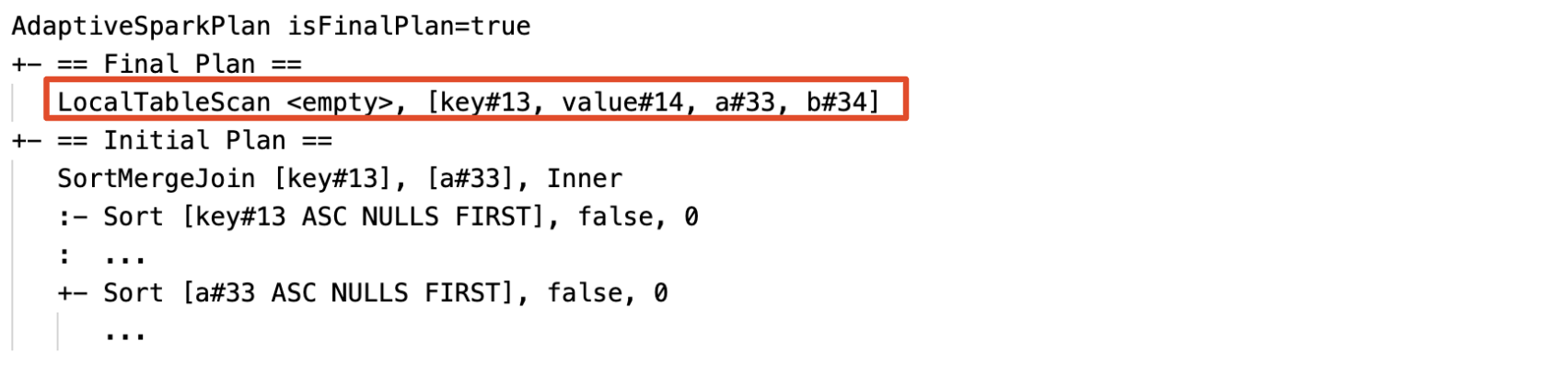
Rilevare e propagare dinamicamente le relazioni vuote: parte di (o intero) il piano viene sostituito dal nodo LocalTableScan con il campo relazione come vuoto.
Configurazione
Contenuto della sezione:
- Abilitare e disabilitare l'esecuzione di query adattive
- Abilitare la sequenza casuale ottimizzata automaticamente
- Modificare dinamicamente l'unione di ordinamento in broadcast hash join
- Unire dinamicamente le partizioni
- Gestire dinamicamente il join di asimmetria
- Rilevare e propagare dinamicamente le relazioni vuote
Abilitare e disabilitare l'esecuzione di query adattive
| Proprietà |
|---|
| spark.databricks.optimizer.adaptive.enabled Tipo: BooleanSe abilitare o disabilitare l'esecuzione di query adattive. Valore predefinito: true |
Abilitare la sequenza casuale ottimizzata automaticamente
| Proprietà |
|---|
| spark.sql.shuffle.partitions Tipo: IntegerNumero predefinito di partizioni da usare per la riproduzione casuale dei dati per join o aggregazioni. L'impostazione del valore auto abilita lo shuffle ottimizzato automaticamente, che determina automaticamente questo numero in base al piano di query e alle dimensioni dei dati di input della query.Nota: per Structured Streaming, questa configurazione non può essere modificata tra i riavvii della query dalla stessa posizione del checkpoint. Valore predefinito: 200 |
Modificare dinamicamente l'unione di ordinamento in broadcast hash join
| Proprietà |
|---|
| spark.databricks.adaptive.autoBroadcastJoinThreshold Tipo: Byte StringSoglia per attivare il passaggio al join di trasmissione in fase di esecuzione. Valore predefinito: 30MB |
Unire dinamicamente le partizioni
| Proprietà |
|---|
| spark.sql.adaptive.coalescePartitions.enabled Tipo: BooleanSe abilitare o disabilitare la unione delle partizioni. Valore predefinito: true |
| spark.sql.adaptive.advisoryPartitionSizeInBytes Tipo: Byte StringDimensioni della destinazione dopo l'unione. Le dimensioni delle partizioni coalesce saranno vicine, ma non superiori a quelle di questa destinazione. Valore predefinito: 64MB |
| spark.sql.adaptive.coalescePartitions.minPartitionSize Tipo: Byte StringDimensioni minime delle partizioni dopo l'unione. Le dimensioni delle partizioni coalesce non saranno inferiori a quelle di questa dimensione. Valore predefinito: 1MB |
| spark.sql.adaptive.coalescePartitions.minPartitionNum Tipo: IntegerNumero minimo di partizioni dopo l'unione. Non consigliato, perché l'impostazione esegue l'override esplicito spark.sql.adaptive.coalescePartitions.minPartitionSize.Valore predefinito: 2x no. di core del cluster |
Gestire dinamicamente il join di asimmetria
| Proprietà |
|---|
| spark.sql.adaptive.skewJoin.enabled Tipo: BooleanSe abilitare o disabilitare la gestione dell'asimmetria dei join. Valore predefinito: true |
| spark.sql.adaptive.skewJoin.skewedPartitionFactor Tipo: IntegerFattore che, se moltiplicato per le dimensioni della partizione mediano, contribuisce a determinare se una partizione è asimmetrica. Valore predefinito: 5 |
| spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes Tipo: Byte StringSoglia che contribuisce a determinare se una partizione è asimmetrica. Valore predefinito: 256MB |
Una partizione viene considerata asimmetrica quando e (partition size > skewedPartitionFactor * median partition size) (partition size > skewedPartitionThresholdInBytes) sono true.
Rilevare e propagare dinamicamente le relazioni vuote
| Proprietà |
|---|
| spark.databricks.adaptive.emptyRelationPropagation.enabled Tipo: BooleanSe abilitare o disabilitare la propagazione dinamica delle relazioni vuote. Valore predefinito: true |
Domande frequenti
Contenuto della sezione:
- Perché AQE non ha trasmesso una piccola tabella join?
- È comunque consigliabile usare un hint per la strategia di join broadcast con AQE abilitato?
- Qual è la differenza tra l'hint di join asimmetria e l'ottimizzazione dell'asimmetria dei join AQE? Quale è più indicato usare?
- Perché AQE non ha modificato automaticamente l'ordinamento dei join?
- Perché AQE non ha rilevato un'asimmetria dei dati?
Perché AQE non ha trasmesso una piccola tabella join?
Se la dimensione della relazione prevista per la trasmissione scende al di sotto di questa soglia, ma non è ancora trasmessa:
- Controllare il tipo di join. La trasmissione non è supportata per determinati tipi di join, ad esempio la relazione sinistra di un
LEFT OUTER JOINoggetto non può essere trasmessa. - Può anche essere che la relazione contiene molte partizioni vuote, nel qual caso la maggior parte delle attività può terminare rapidamente con il merge join di ordinamento o può essere potenzialmente ottimizzata con la gestione del join asimmetria. AQE evita di modificare tali join di ordinamento per trasmettere join hash se la percentuale di partizioni non vuote è inferiore a
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin.
È comunque consigliabile usare un hint per la strategia di join broadcast con AQE abilitato?
Sì. Un join di trasmissione pianificato in modo statico è in genere più efficiente di quello pianificato dinamicamente da AQE, perché AQE potrebbe non passare al join broadcast fino a quando non si esegue shuffle per entrambi i lati del join (entro il quale vengono ottenute le dimensioni effettive delle relazioni). Pertanto, l'uso di un hint di trasmissione può comunque essere una buona scelta se si conosce bene la query. AQE rispetterà gli hint di query allo stesso modo dell'ottimizzazione statica, ma può comunque applicare ottimizzazioni dinamiche non interessate dagli hint.
Qual è la differenza tra l'hint di join asimmetria e l'ottimizzazione dell'asimmetria dei join AQE? Quale è più indicato usare?
È consigliabile basarsi sulla gestione dell'asimmetria del join AQE anziché usare l'hint di join asimmetria, perché il join asimmetria di AQE è completamente automatico e in generale offre prestazioni migliori rispetto alla controparte hint.
Perché AQE non ha modificato automaticamente l'ordinamento dei join?
Il riordinamento del join dinamico non fa parte di AQE.
Perché AQE non ha rilevato un'asimmetria dei dati?
Esistono due condizioni di dimensione che devono essere soddisfatte affinché AQE rilevi una partizione come partizione asimmetrica:
- Le dimensioni della
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytespartizione sono maggiori di (impostazione predefinita 256 MB) - Le dimensioni della partizione sono maggiori delle dimensioni mediano di tutte le partizioni volte il fattore
spark.sql.adaptive.skewJoin.skewedPartitionFactordi partizione asimmetrico (impostazione predefinita 5)
Inoltre, il supporto per la gestione delle asimmetrie è limitato per determinati tipi di join, ad esempio in LEFT OUTER JOIN, è possibile ottimizzare solo l'asimmetria sul lato sinistro.
Legacy
Il termine "Esecuzione adattiva" esiste da Spark 1.6, ma il nuovo AQE in Spark 3.0 è fondamentalmente diverso. In termini di funzionalità, Spark 1.6 esegue solo la parte "unione dinamica delle partizioni". In termini di architettura tecnica, il nuovo AQE è un framework di pianificazione dinamica e riorganizzazione delle query in base alle statistiche di runtime, che supporta un'ampia gamma di ottimizzazioni, ad esempio quelle descritte in questo articolo e può essere esteso per consentire un maggior numero di ottimizzazioni potenziali.