Ripristino di emergenza a livello di area per cluster di Azure Databricks
Questo articolo descrive un'architettura di ripristino di emergenza per i cluster di Azure Databricks e illustra i passaggi per implementare l'architettura.
Architettura di Azure Databricks
Quando si crea un'area di lavoro di Azure Databricks dalla portale di Azure, un'applicazione gestita viene distribuita come risorsa di Azure nella sottoscrizione, nell'area di Azure scelta( ad esempio Stati Uniti occidentali). L'appliance viene distribuita in una rete virtuale di Azure con un gruppo di sicurezza di rete e un account di archiviazione di Azure, disponibile nella sottoscrizione. La rete virtuale fornisce la sicurezza a livello di perimetro all'area di lavoro di Databricks ed è protetta tramite il gruppo di sicurezza di rete. All'interno dell'area di lavoro si creano cluster Databricks fornendo il tipo di macchina virtuale di lavoro e driver e la versione del runtime di Databricks. I dati persistenti sono disponibili nell'account di archiviazione. Dopo aver creato il cluster, è possibile eseguire processi tramite notebook, API REST o endpoint ODBC/JDBC collegandoli a un cluster specifico.
Il piano di controllo di Databricks gestisce e monitora l'ambiente dell'area di lavoro di Databricks. Qualsiasi operazione di gestione, ad esempio create cluster, verrà avviata dal piano di controllo. Tutti i metadati, ad esempio i processi pianificati, vengono archiviati in un database di Azure e i backup del database vengono automaticamente replicati geograficamente per in aree abbinate in cui viene implementato.
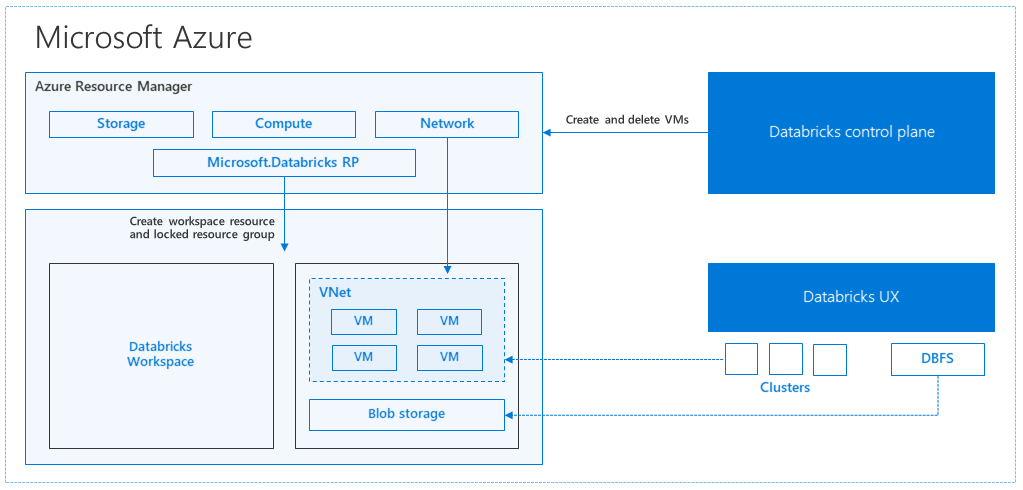
Uno dei vantaggi di questa architettura consiste nel fatto che gli utenti possono connettere Azure Databricks a qualsiasi risorsa di archiviazione nell'account. Un vantaggio significativo è che il calcolo (Azure Databricks) e l'archiviazione possono essere ridimensionati in modo indipendente.
Come creare una topologia di ripristino di emergenza a livello di area
Nella descrizione dell'architettura precedente sono disponibili diversi componenti usati per una pipeline di Big Data con Azure Databricks: Archiviazione di Azure, Database di Azure e altre origini dati. Azure Databricks è la risorsa di calcolo per la pipeline di Big Data. È temporaneo, ovvero mentre i dati sono ancora disponibili in Archiviazione di Azure, il calcolo (cluster Azure Databricks) può essere terminato per evitare di pagare per il calcolo quando non è necessario. Le origini di calcolo (Azure Databricks) e di archiviazione devono trovarsi nella stessa area in modo da evitare problemi di latenza elevata dei processi.
Per creare una topologia di ripristino di emergenza a livello di area, rispettare i requisiti seguenti:
Effettuare il provisioning di più aree di lavoro di Azure Databricks in aree di Azure separate. Ad esempio, creare l'area di lavoro primaria di Azure Databricks negli Stati Uniti orientali. Creare l'area di lavoro secondaria di Azure Databricks per il ripristino di emergenza in un'area separata, ad esempio Stati Uniti occidentali. Per un elenco delle aree di Azure abbinate, vedere Replica tra aree. Per informazioni dettagliate sulle aree di Azure Databricks, vedere Aree supportate.
Usare l'archiviazione con ridondanza geografica. Per impostazione predefinita, i dati associati ad Azure Databricks vengono archiviati in Archiviazione di Azure e i risultati dei processi di Databricks vengono archiviati in Archiviazione BLOB di Azure, in modo che i dati elaborati siano durevoli e rimangano a disponibilità elevata al termine del cluster. L'archiviazione cluster e l'archiviazione dei processi si trovano nella stessa zona di disponibilità. Per evitare la mancata disponibilità a livello di area, le aree di lavoro di Azure Databricks usano l'archiviazione con ridondanza geografica per impostazione predefinita. Con l'archiviazione con ridondanza geografica, i dati vengono replicati in un'area abbinata di Azure. Databricks consiglia di mantenere l'archiviazione con ridondanza geografica predefinita, ma se è necessario usare l'archiviazione con ridondanza locale, è possibile impostare su
storageAccountSkuNameStandard_LRSnel modello di Resource Manager per l'area di lavoro.Dopo aver creato l'area secondaria, è necessario eseguire la migrazione di utenti, cartelle degli utenti, notebook, configurazione di cluster, configurazione di processi, librerie, dati di archiviazione e script di inizializzazione e riconfigurare il controllo di accesso. Altri dettagli sono descritti nella sezione seguente.
Emergenza regionale
Per prepararsi alle emergenze a livello di area, è necessario gestire in modo esplicito un altro set di aree di lavoro di Azure Databricks in un'area secondaria. Vedere Ripristino di emergenza.
Gli strumenti consigliati per il ripristino di emergenza sono principalmente Terraform (per la replica Infra) e Delta Deep Clone (per la replica dei dati).
Passaggi dettagliati della migrazione
Installare l'interfaccia della riga di comando di Databricks
Gli esempi in questo articolo usano l'interfaccia della riga di comando di Databricks, un wrapper facile da usare tramite l'API REST di Azure Databricks.
Prima di eseguire qualsiasi procedura di migrazione, installare l'interfaccia della riga di comando di Databricks nel computer locale o nella macchina virtuale. Per altre informazioni, vedere Installare l'interfaccia della riga di comando di Databricks.
Nota
Gli script Python forniti in questo articolo funzionano con Python 2.7 e versioni successive.
Configurare due profili
Seguendo la procedura descritta in _, configurare due profili: uno per l'area di lavoro primaria e un altro per l'area di lavoro secondaria.
databricks configure --profile primary databricks configure --profile secondaryI blocchi di codice in questo articolo alternano i profili in ogni passaggio successivo usando il comando dell'area di lavoro corrispondente. Verificare che per i profili creati vengano sostituiti i nomi in ogni blocco di codice.
EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary"È possibile passare manualmente alla riga di comando, se necessario:
databricks workspace list --profile primary databricks workspace list --profile secondaryEseguire la migrazione degli utenti di Microsoft Entra ID (in precedenza Azure Active Directory)
Aggiungere manualmente lo stesso ID Microsoft Entra (in precedenza Azure Active Directory) all'area di lavoro secondaria esistente nell'area di lavoro primaria.
Eseguire la migrazione dei notebook e delle cartelle degli utenti
Usare il codice python seguente per eseguire la migrazione degli ambienti sandbox degli utenti, che includono la struttura di cartelle annidate e i notebook per ogni utente.
Nota
Le librerie non vengono copiate in questo passaggio poiché non sono supportate dall'API sottostante.
Copiare e salvare lo script Python seguente in un file ed eseguirlo nella riga di comando. Ad esempio:
python scriptname.py.import sys import os import subprocess from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get a list of all users user_list_out = check_output(["databricks", "workspace", "list", "/Users", "--profile", EXPORT_PROFILE]) user_list = (user_list_out.decode(encoding="utf-8")).splitlines() print (user_list) # Export sandboxed environment(folders, notebooks) for each user and import into new workspace. #Libraries are not included with these APIs / commands. for user in user_list: #print("Trying to migrate workspace for user ".decode() + user) print (("Trying to migrate workspace for user ") + user) subprocess.call(str("mkdir -p ") + str(user), shell = True) export_exit_status = call("databricks workspace export_dir /Users/" + str(user) + " ./" + str(user) + " --profile " + EXPORT_PROFILE, shell = True) if export_exit_status==0: print ("Export Success") import_exit_status = call("databricks workspace import_dir ./" + str(user) + " /Users/" + str(user) + " --profile " + IMPORT_PROFILE, shell=True) if import_exit_status==0: print ("Import Success") else: print ("Import Failure") else: print ("Export Failure") print ("All done")Eseguire la migrazione delle configurazioni di cluster
Dopo la migrazione dei notebook, è possibile eseguire facoltativamente la migrazione delle configurazioni di cluster nella nuova area di lavoro. È quasi un passaggio completamente automatizzato usando l'interfaccia della riga di comando di Databricks, a meno che non si voglia eseguire la migrazione selettiva della configurazione del cluster.
Nota
Non è presente alcun endpoint di configurazione del cluster e questo script tenta di creare immediatamente ogni cluster. Se nella sottoscrizione non sono disponibili core sufficienti, è possibile che la creazione del cluster non riesca. L'errore può essere ignorato, purché la configurazione venga trasferita correttamente.
Lo script seguente restituisce un mapping degli ID di cluster esistenti con quelli nuovi, che può essere usato per eseguire la migrazione dei processi in un secondo momento (per i processi configurati per l'uso di cluster esistenti).
Copiare e salvare lo script Python seguente in un file ed eseguirlo nella riga di comando. Ad esempio:
python scriptname.py.import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get all clusters info from old workspace clusters_out = check_output(["databricks", "clusters", "list", "--profile", EXPORT_PROFILE]) clusters_info_list = str(clusters_out.decode(encoding="utf-8")).splitlines() print("Printing Cluster info List") print(clusters_info_list) # Create a list of all cluster ids clusters_list = [] ##for cluster_info in clusters_info_list: clusters_list.append(cluster_info.split(None, 1)[0]) for cluster_info in clusters_info_list: if cluster_info != '': clusters_list.append(cluster_info.split(None, 1)[0]) # Optionally filter cluster ids out manually, so as to create only required ones in new workspace # Create a list of mandatory / optional create request elements cluster_req_elems = ["num_workers","autoscale","cluster_name","spark_version","spark_conf","node_type_id","driver_node_type_id","custom_tags","cluster_log_conf","spark_env_vars","autotermination_minutes","enable_elastic_disk"] print("Printing Cluster element List") print (cluster_req_elems) print(str(len(clusters_list)) + " clusters found in the primary site" ) print ("---------------------------------------------------------") # Try creating all / selected clusters in new workspace with same config as in old one. cluster_old_new_mappings = {} i = 0 for cluster in clusters_list: i += 1 print("Checking cluster " + str(i) + "/" + str(len(clusters_list)) + " : " +str(cluster)) cluster_get_out_f = check_output(["databricks", "clusters", "get", "--cluster-id", str(cluster), "--profile", EXPORT_PROFILE]) cluster_get_out=str(cluster_get_out_f.decode(encoding="utf-8")) print ("Got cluster config from old workspace") print (cluster_get_out) # Remove extra content from the config, as we need to build create request with allowed elements only cluster_req_json = json.loads(cluster_get_out) cluster_json_keys = cluster_req_json.keys() #Don't migrate Job clusters if cluster_req_json['cluster_source'] == u'JOB' : print ("Skipping this cluster as it is a Job cluster : " + cluster_req_json['cluster_id'] ) print ("---------------------------------------------------------") continue #cluster_req_json.pop(key, None) for key in cluster_json_keys: if key not in cluster_req_elems: print (cluster_req_json) #cluster_del_item=cluster_json_keys .keys() cluster_req_json.popitem(key, None) # Create the cluster, and store the mapping from old to new cluster ids #Create a temp file to store the current cluster info as JSON strCurrentClusterFile = "tmp_cluster_info.json" #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) fClusterJSONtmp = open(strCurrentClusterFile,"w+") fClusterJSONtmp.write(json.dumps(cluster_req_json)) fClusterJSONtmp.close() #cluster_create_out = check_output(["databricks", "clusters", "create", "--json", json.dumps(cluster_req_json), "--profile", IMPORT_PROFILE]) cluster_create_out = check_output(["databricks", "clusters", "create", "--json-file", strCurrentClusterFile , "--profile", IMPORT_PROFILE]) cluster_create_out_json = json.loads(cluster_create_out) cluster_old_new_mappings[cluster] = cluster_create_out_json['cluster_id'] print ("Cluster create request sent to secondary site workspace successfully") print ("---------------------------------------------------------") #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) print ("Cluster mappings: " + json.dumps(cluster_old_new_mappings)) print ("All done") print ("P.S. : Please note that all the new clusters in your secondary site are being started now!") print (" If you won't use those new clusters at the moment, please don't forget terminating your new clusters to avoid charges")Eseguire la migrazione della configurazione di processi
Se nel passaggio precedente sono state migrate configurazioni di cluster, è possibile decidere di eseguire anche la migrazione di configurazioni di processi nella nuova area di lavoro. Si tratta di un passaggio completamente automatizzato usando l'interfaccia della riga di comando di Databricks, a meno che non si voglia eseguire la migrazione selettiva della configurazione dei processi anziché eseguirla per tutti i processi.
Nota
La configurazione relativa a un processo pianificato contiene anche le informazioni di pianificazione, in modo che venga avviato in base al tempo configurato non appena è stata completata la migrazione. Di conseguenza, il blocco di codice seguente rimuove eventuali informazioni di pianificazione durante la migrazione (per evitare esecuzioni duplicate tra l'area di lavoro precedente e quella nuova). Configurare le pianificazioni per questi processi quando si è pronti per la migrazione completa.
Per la configurazione di un processo devono essere definite le impostazioni per un nuovo cluster o un cluster esistente. Se si usa un cluster esistente, lo script con codice seguente proverà a sostituire l'ID del cluster precedente con quello del nuovo cluster.
Copiare e salvare lo script python seguente in un file. Sostituire il valore per
old_cluster_idenew_cluster_idcon l'output risultante dalla migrazione del cluster eseguita nel passaggio precedente. Eseguirlo alla riga di comando,python scriptname.pyad esempio .import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Please replace the old to new cluster id mappings from cluster migration output cluster_old_new_mappings = {"0227-120427-tryst214": "0229-032632-paper88"} # Get all jobs info from old workspace try: jobs_out = check_output(["databricks", "jobs", "list", "--profile", EXPORT_PROFILE]) jobs_info_list = jobs_out.splitlines() except: print("No jobs to migrate") sys.exit(0) # Create a list of all job ids jobs_list = [] for jobs_info in jobs_info_list: jobs_list.append(jobs_info.split(None, 1)[0]) # Optionally filter job ids out manually, so as to create only required ones in new workspace # Create each job in the new workspace based on corresponding settings in the old workspace for job in jobs_list: print("Trying to migrate " + str(job)) job_get_out = check_output(["databricks", "jobs", "get", "--job-id", job, "--profile", EXPORT_PROFILE]) print("Got job config from old workspace") job_req_json = json.loads(job_get_out) job_req_settings_json = job_req_json['settings'] # Remove schedule information so job doesn't start before proper cutover job_req_settings_json.pop('schedule', None) # Replace old cluster id with new cluster id, if job configured to run against an existing cluster if 'existing_cluster_id' in job_req_settings_json: if job_req_settings_json['existing_cluster_id'] in cluster_old_new_mappings: job_req_settings_json['existing_cluster_id'] = cluster_old_new_mappings[job_req_settings_json['existing_cluster_id']] else: print("Mapping not available for old cluster id " + str(job_req_settings_json['existing_cluster_id'])) continue call(["databricks", "jobs", "create", "--json", json.dumps(job_req_settings_json), "--profile", IMPORT_PROFILE]) print("Sent job create request to new workspace successfully") print("All done")Eseguire la migrazione di librerie
Attualmente non è disponibile un modo semplice per eseguire la migrazione di librerie da un'area di lavoro a un'altra. Come soluzione alternativa, è possibile reinstallare le librerie nella nuova area di lavoro manualmente È possibile automatizzare questa operazione usando l'interfaccia della riga di comando di Databricks per caricare librerie personalizzate nell'area di lavoro.
Eseguire la migrazione dell'archiviazione BLOB di Azure e dei montaggi di Azure Data Lake Storage
Rimontare manualmente tutti i punti di montaggio di Archiviazione BLOB di Azure e Azure Data Lake Storage (Gen 2) usando una soluzione basata su notebook. Se le risorse di archiviazione sono state montate nell'area di lavoro primaria, questa operazione deve essere ripetuta nell'area di lavoro secondaria. Non è disponibile alcuna API esterna per le operazioni di montaggio.
Eseguire la migrazione degli script di inizializzazione dei cluster
È possibile eseguire la migrazione di qualsiasi script di inizializzazione del cluster dalla versione precedente alla nuova area di lavoro usando l'interfaccia della riga di comando di Databricks. Prima di tutto, copiare gli script necessari nel desktop locale o nella macchina virtuale. e successivamente copiarli nella nuova area di lavoro nello stesso percorso.
Nota
Se sono presenti script di inizializzazione archiviati in DBFS, eseguirne prima la migrazione a una posizione supportata. Vedere _.
// Primary to local databricks fs cp dbfs:/Volumes/my_catalog/my_schema/my_volume/ ./old-ws-init-scripts --profile primary // Local to Secondary workspace databricks fs cp old-ws-init-scripts dbfs:/Volumes/my_catalog/my_schema/my_volume/ --profile secondaryRiconfigurare e riapplicare manualmente il controllo di accesso
Se l'area di lavoro primaria esistente è configurata per l'uso del livello Premium o Enterprise (SKU), è probabile che si stia usando anche il controllo di accesso.
Se si usa il controllo di accesso, riapplicare manualmente il controllo di accesso alle risorse (notebook, cluster, processi, tabelle).
Ripristino di emergenza per l'ecosistema di Azure
Se si usano altri servizi di Azure, assicurarsi di implementare anche le procedure consigliate per il ripristino di emergenza per tali servizi. Ad esempio, se si sceglie di usare un'istanza del metastore Hive esterna, è consigliabile prendere in considerazione il ripristino di emergenza per database SQL di Azure, Azure HDInsight e/o Database di Azure per MySQL. Per informazioni generali sul ripristino di emergenza, vedere Ripristino di emergenza per le applicazioni Azure.
Passaggi successivi
Per altre informazioni, vedere la documentazione su Azure Databricks.