Creazione di sistemi avanzati di generazione aumentata
L'articolo precedente ha illustrato due opzioni per la creazione di un'applicazione "chat over your data", uno dei casi d'uso principali per l'intelligenza artificiale generativa nelle aziende:
- Generazione aumentata di recupero (RAG) che integra il training LLM (Large Language Model) con un database di articoli ricercabili che possono essere recuperati in base alla somiglianza con le query degli utenti e passate all'LLM per il completamento.
- Ottimizzazione, che espande il training dell'LLM per comprendere meglio il dominio del problema.
L'articolo precedente ha anche illustrato quando usare ogni approccio, pro e contro di ogni approccio e diverse altre considerazioni.
Questo articolo esplora la rag in modo più approfondito, in particolare, tutto il lavoro necessario per creare una soluzione pronta per la produzione.
L'articolo precedente illustra i passaggi o le fasi di Rag usando il diagramma seguente.
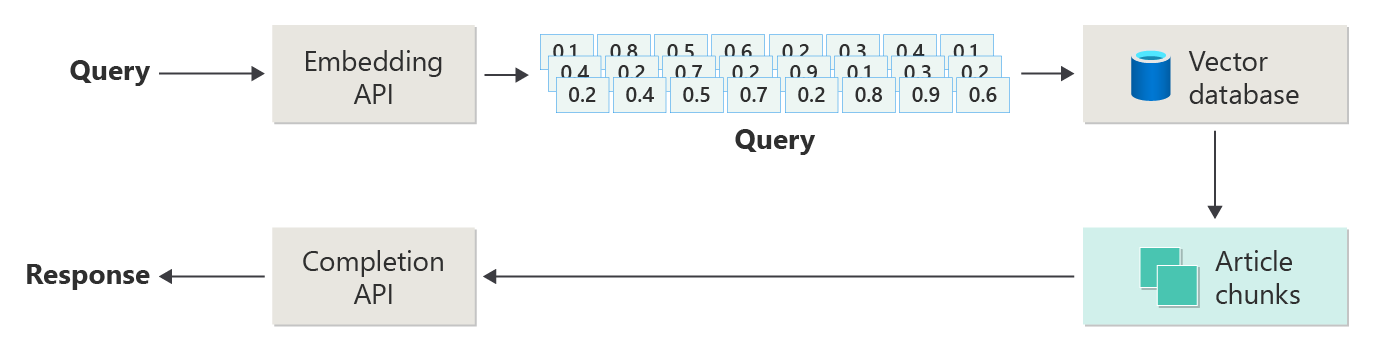
Questa rappresentazione è stata definita "rag ingenua" ed è un modo utile per comprendere prima i meccanismi, i ruoli e le responsabilità necessari per implementare un sistema di chat basato su RAG.
Tuttavia, un'implementazione più reale include molti altri passaggi di pre-elaborazione e post-elaborazione per preparare gli articoli, le query e le risposte da usare. Il diagramma seguente è una rappresentazione più realistica di un rag, talvolta definito "RAG avanzato".

Questo articolo fornisce un framework concettuale per comprendere i tipi di problemi di pre-elaborazione e post-elaborazione in un sistema di chat basato su RAG reale, organizzato come segue:
- Fase di inserimento
- Fase della pipeline di inferenza
- Fase di valutazione
Come panoramica concettuale, le parole chiave e le idee vengono fornite come contesto e un punto di partenza per un'ulteriore esplorazione e ricerca.
Inserimento
L'inserimento riguarda principalmente l'archiviazione dei documenti dell'organizzazione in modo che possano essere facilmente recuperati per rispondere alla domanda di un utente. La sfida consiste nel garantire che le parti dei documenti che meglio corrispondano alla query dell'utente vengano posizionate e utilizzate durante l'inferenza. La corrispondenza viene eseguita principalmente tramite incorporamenti vettoriali e una ricerca di somiglianza coseno. Tuttavia, è facilitato dalla comprensione della natura del contenuto (modelli, moduli e così via) e della strategia dell'organizzazione dei dati (la struttura dei dati quando vengono archiviati nel database vettoriale).
A tale scopo, gli sviluppatori devono considerare quanto segue:
- Pre-elaborazione ed estrazione del contenuto
- Strategia di suddivisione in blocchi
- Organizzazione di suddivisione in blocchi
- Strategia di aggiornamento
Pre-elaborazione ed estrazione del contenuto
Il contenuto pulito e accurato è uno dei modi migliori per migliorare la qualità complessiva di un sistema di chat basato su RAG. A tale scopo, gli sviluppatori devono iniziare analizzando la forma e la forma dei documenti da indicizzare. I documenti sono conformi ai modelli di contenuto specificati, ad esempio la documentazione? In caso contrario, quali tipi di domande potrebbero rispondere ai documenti?
Come minimo, gli sviluppatori devono creare passaggi nella pipeline di inserimento per:
- Standardizzare i formati di testo
- Gestire caratteri speciali
- Rimuovere contenuto non correlato e obsoleto
- Account per il contenuto con controllo delle versioni
- Account per l'esperienza di contenuto (schede, immagini, tabelle)
- Estrarre i metadati
Alcune di queste informazioni, ad esempio metadati, potrebbero essere utili per essere mantenute con il documento nel database vettoriale da usare durante il processo di recupero e valutazione nella pipeline di inferenza o combinate con il blocco di testo per convincere l'incorporamento del vettore del blocco.
Strategia di suddivisione in blocchi
Gli sviluppatori devono decidere come suddividere un documento più lungo in blocchi più piccoli. In questo modo è possibile migliorare la pertinenza del contenuto supplementare inviato in LLM per rispondere con precisione alla query dell'utente. Inoltre, gli sviluppatori devono considerare come usare i blocchi al momento del recupero. Si tratta di un'area in cui i progettisti di sistemi devono eseguire alcune ricerche sulle tecniche usate nel settore ed eseguire alcune sperimentazioni, anche testandola in una capacità limitata nell'organizzazione.
Gli sviluppatori devono prendere in considerazione:
- Ottimizzazione delle dimensioni dei blocchi: determinare qual è la dimensione ideale del blocco e come designare un blocco. Per sezione? Per paragrafo? Per frase?
- Blocchi di finestra sovrapposti e scorrevoli : determinare come dividere il contenuto in blocchi discreti. O i blocchi si sovrappongono? O entrambi (finestra scorrevole)?
- Small2Big : quando si crea una suddivisione in blocchi a un livello granulare come una singola frase, il contenuto verrà organizzato in modo tale che sia facile trovare le frasi adiacenti o contenere il paragrafo? Vedere "Organizzazione di suddivisione in blocchi". Il recupero di queste informazioni aggiuntive e la relativa fornitura all'LLM potrebbero fornire più contesto quando si risponde alla query dell'utente.
Organizzazione di suddivisione in blocchi
In un sistema RAG, l'organizzazione dei dati nel database vettoriale è fondamentale per il recupero efficiente delle informazioni pertinenti per aumentare il processo di generazione. Ecco i tipi di indicizzazione e strategie di recupero che gli sviluppatori possono prendere in considerazione:
- Indici gerarchici: questo approccio prevede la creazione di più livelli di indici, in cui un indice di primo livello (indice di riepilogo) restringe rapidamente lo spazio di ricerca a un subset di blocchi potenzialmente rilevanti e un indice di secondo livello (indice blocchi) fornisce puntatori più dettagliati ai dati effettivi. Questo metodo può velocizzare notevolmente il processo di recupero in quanto riduce il numero di voci da analizzare nell'indice dettagliato filtrando prima l'indice di riepilogo.
- Indici specializzati: è possibile usare indici specializzati come database relazionali o basati su grafo a seconda della natura dei dati e delle relazioni tra blocchi. Per esempio:
- Gli indici basati su grafo sono utili quando i blocchi hanno informazioni o relazioni interconnesse che possono migliorare il recupero, ad esempio reti di citazione o grafici delle conoscenze.
- I database relazionali possono essere efficaci se i blocchi sono strutturati in un formato tabulare in cui è possibile usare query SQL per filtrare e recuperare i dati in base a attributi o relazioni specifici.
- Indici ibridi: un approccio ibrido combina più strategie di indicizzazione per sfruttare i punti di forza di ognuno di essi. Ad esempio, gli sviluppatori possono usare un indice gerarchico per il filtro iniziale e un indice basato su grafo per esplorare le relazioni tra blocchi in modo dinamico durante il recupero.
Ottimizzazione dell'allineamento
Per migliorare la pertinenza e l'accuratezza dei blocchi recuperati, può essere utile allinearli più strettamente con i tipi di domande o query a cui sono destinati a rispondere. Una strategia per eseguire questa operazione consiste nel generare e inserire una domanda ipotetica per ogni blocco che rappresenta la domanda che il blocco è più adatto per rispondere. Ciò consente in diversi modi:
- Miglioramento della corrispondenza: durante il recupero, il sistema può confrontare la query in ingresso con queste domande ipotetiche per trovare la corrispondenza migliore, migliorando la pertinenza dei blocchi recuperati.
- Dati di training per i modelli di Machine Learning: queste associazioni di domande e blocchi possono fungere da dati di training per migliorare i modelli di Machine Learning sottostanti il sistema RAG, consentendo di apprendere quali tipi di domande sono meglio risposte da quali blocchi.
- Gestione delle query dirette: se una query utente reale corrisponde a una domanda ipotetica, il sistema può recuperare e usare rapidamente il blocco corrispondente, accelerando il tempo di risposta.
Ogni domanda ipotetica di ogni blocco agisce come una sorta di "etichetta" che guida l'algoritmo di recupero, rendendolo più mirato e contestualmente consapevole. Ciò è utile negli scenari in cui i blocchi coprono un'ampia gamma di argomenti o tipi di informazioni.
Strategie di aggiornamento
Se l'organizzazione deve indicizzare i documenti che vengono aggiornati di frequente, è essenziale mantenere un corpus aggiornato per garantire che il componente retriever (la logica nel sistema responsabile dell'esecuzione della query sul database vettoriale e la restituzione dei risultati) possa accedere alle informazioni più aggiornate. Ecco alcune strategie per aggiornare il database vettoriale in tali sistemi:
- Aggiornamenti incrementali:
- Intervalli regolari: pianificare gli aggiornamenti a intervalli regolari (ad esempio, giornaliero, settimanale) a seconda della frequenza delle modifiche del documento. Questo metodo garantisce che il database venga aggiornato periodicamente.
- Aggiornamenti basati su trigger: implementare un sistema in cui gli aggiornamenti attivano la reindicizzazione. Ad esempio, qualsiasi modifica o aggiunta di un documento potrebbe avviare automaticamente una reindicizzazione delle sezioni interessate.
- Aggiornamenti parziali:
- Reindicizzazione selettiva: invece di reindicizzare nuovamente l'intero database, aggiornare in modo selettivo solo le parti del corpus che sono state modificate. Questa operazione può essere più efficiente rispetto alla reindicizzazione completa, soprattutto per set di dati di grandi dimensioni.
- Codifica differenziale: archiviare solo le differenze tra i documenti esistenti e le versioni aggiornate. Questo approccio riduce il carico di elaborazione dei dati evitando la necessità di elaborare dati non modificati.
- Controllo delle versioni:
- Creazione di snapshot: mantenere le versioni del corpus di documenti in momenti diversi. Ciò consente al sistema di ripristinare o fare riferimento alle versioni precedenti, se necessario e fornisce un meccanismo di backup.
- Controllo della versione del documento: usare un sistema di controllo della versione per tenere traccia delle modifiche nei documenti sistematicamente. Ciò consente di mantenere la cronologia delle modifiche e di semplificare il processo di aggiornamento.
- Aggiornamenti in tempo reale:
- Elaborazione del flusso: usare le tecnologie di elaborazione del flusso per aggiornare il database vettoriale in tempo reale man mano che vengono apportate modifiche ai documenti. Questo può essere fondamentale per le applicazioni in cui la tempestività delle informazioni è fondamentale.
- Query in tempo reale: invece di basarsi esclusivamente su vettori pre-indicizzati, implementare un meccanismo per eseguire query sui dati in tempo reale per le risposte più aggiornate, eventualmente combinando questo con i risultati memorizzati nella cache per ottenere un'efficienza.
- Tecniche di ottimizzazione:
- Elaborazione batch: accumulare modifiche ed elaborarle in batch per ottimizzare l'uso delle risorse e ridurre il sovraccarico causato da aggiornamenti frequenti.
- Approcci ibridi: combinare diverse strategie, ad esempio l'uso di aggiornamenti incrementali per modifiche minime e la reindicizzazione completa per aggiornamenti importanti o modifiche strutturali nel corpus dei documenti.
La scelta della giusta strategia di aggiornamento o combinazione di strategie dipende da requisiti specifici, ad esempio le dimensioni del corpus dei documenti, la frequenza degli aggiornamenti, la necessità di dati in tempo reale e la disponibilità delle risorse. Ogni approccio presenta compromessi in termini di complessità, costo e latenza di aggiornamento, quindi è essenziale valutare questi fattori in base alle esigenze specifiche dell'applicazione.
Pipeline di inferenza
Ora che gli articoli sono stati suddivisi in blocchi, vettorializzati e archiviati in un database vettoriale, lo stato attivo si concentra sui problemi di completamento.
- La query dell'utente viene scritta in modo da ottenere i risultati dal sistema che l'utente sta cercando?
- La query dell'utente viola uno dei criteri?
- Come si riscrive la query dell'utente per migliorare le probabilità di trovare corrispondenze più vicine nel database vettoriale?
- Come si valutano i risultati della query per assicurarsi che i blocchi dell'articolo siano allineati alla query?
- Come si valutano e si modificano i risultati della query prima di passarli in LLM per assicurarsi che i dettagli più rilevanti siano inclusi nel completamento dell'LLM?
- Come si valuta la risposta dell'LLM per garantire che il completamento dell'LLM risponda alla query originale dell'utente?
- Come si garantisce che la risposta dell'LLM sia conforme ai criteri?
Come si può notare, ci sono molte attività che gli sviluppatori devono tenere in considerazione, principalmente sotto forma di:
- Input di pre-elaborazione per ottimizzare la probabilità di ottenere i risultati desiderati
- Output post-elaborazione per garantire i risultati desiderati
Tenere presente che l'intera pipeline di inferenza è in esecuzione in tempo reale. Anche se non esiste un modo giusto per progettare la logica che esegue i passaggi di pre-elaborazione e post-elaborazione, è probabile che si tratti di una combinazione di logica di programmazione e chiamate aggiuntive a un LLM. Una delle considerazioni più importanti è quindi il compromesso tra la compilazione della pipeline più accurata e conforme possibile e il costo e la latenza necessari per farlo accadere.
Esaminiamo ogni fase per identificare strategie specifiche.
Eseguire query sui passaggi di pre-elaborazione
La pre-elaborazione delle query si verifica immediatamente dopo che l'utente ha inviato la query, come illustrato in questo diagramma:

L'obiettivo di questi passaggi è quello di assicurarsi che l'utente stia ponendo domande nell'ambito del nostro sistema (e non cercando di "jailbreak" il sistema per farlo fare qualcosa di imprevisto) e preparare la query dell'utente per aumentare la probabilità che individua i blocchi di articoli migliori possibili usando la ricerca coseno simile /"vicino più vicino".
Controllo dei criteri: questo passaggio può comportare la logica che identifica, rimuove, contrassegna o rifiuta determinati contenuti. Alcuni esempi possono includere la rimozione di informazioni personali, la rimozione di espletive e l'identificazione di tentativi di "jailbreak". Il jailbreaking si riferisce ai metodi che gli utenti potrebbero impiegare per aggirare o manipolare le linee guida operative, etiche o di sicurezza predefinite del modello.
Riscrittura delle query: potrebbe trattarsi di qualsiasi cosa, dall'espansione degli acronimi e dalla rimozione dello slang alla ripetizione della formulazione della domanda per porla in modo più astratto per estrarre concetti e principi di alto livello ("richiesta di istruzioni dettagliate").
Una variante del prompt dei passaggi indietro è l'ipotetica incorporamento di documenti (HyDE) che usa LLM per rispondere alla domanda dell'utente, crea un incorporamento per tale risposta (l'ipotetico incorporamento del documento) e usa tale incorporamento per eseguire una ricerca sul database vettoriale.
Subqueries (Sottoquery)
Questo passaggio di elaborazione riguarda la query originale. Se la query originale è lunga e complessa, può essere utile suddividerla a livello di codice in diverse query più piccole, quindi combinare tutte le risposte.
Si consideri, ad esempio, una domanda relativa alle scoperte scientifiche, in particolare nel campo della fisica. La query dell'utente potrebbe essere: "Chi ha apportato contributi più significativi alla fisica moderna, Albert Einstein o Niels Bohr?"
Questa query può essere complessa da gestire direttamente perché i "contributi significativi" possono essere soggettivi e multifatta. Suddividerlo in sottoquery può renderlo più gestibile:
- Sottoquery 1: "Quali sono i principali contributi di Albert Einstein alla fisica moderna?"
- Sottoquery 2: "Quali sono i principali contributi di Niels Bohr alla fisica moderna?"
I risultati di queste sottoquery descrivono in dettaglio le principali teorie e scoperte da ogni fisico. Ad esempio:
- Per Einstein, i contributi potrebbero includere la teoria della relatività, l'effetto fotocoloni e E=mc^2.
- Per Bohr, i contributi potrebbero includere il suo modello dell'atomo di idrogeno, il suo lavoro sulla meccanica quantistica e il suo principio di complementarità.
Una volta delineati questi contributi, possono essere valutati per determinare:
- Sottoquery 3: "In che modo le teorie di Einstein hanno influenzato lo sviluppo della fisica moderna?"
- Sottoquery 4: "In che modo le teorie di Bohr hanno influenzato lo sviluppo della fisica moderna?"
Queste sottoquery esplorano l'influenza del lavoro di ogni scienziato sul campo, ad esempio il modo in cui le teorie di Einstein hanno portato a progressi nella astronomia e nella teoria quantistica, e come il lavoro di Bohr ha contribuito alla comprensione della struttura atomica e della meccanica quantistica.
La combinazione dei risultati di queste sottoquery può aiutare il modello linguistico a formare una risposta più completa riguardo a chi ha apportato contributi più significativi alla fisica moderna, in base alla portata e all'impatto dei loro progressi teorici. Questo metodo semplifica la query complessa originale gestendo componenti più specifici e rispondebili e quindi sintetizzando tali risultati in una risposta coerente.
Router di query
È possibile che l'organizzazione decida di suddividere il proprio insieme di contenuti in più archivi vettoriali o in interi sistemi di recupero. In tal caso, gli sviluppatori possono usare un router di query, che è un meccanismo che determina in modo intelligente quali indici o motori di recupero usare in base alla query fornita. La funzione primaria di un router di query consiste nell'ottimizzare il recupero delle informazioni selezionando il database o l'indice più appropriato in grado di fornire le risposte migliori a una query specifica.
Il router di query funziona in genere in un punto dopo che la query è stata formulata dall'utente, ma prima che venga inviata a qualsiasi sistema di recupero. Ecco un flusso di lavoro semplificato:
- Analisi query: LLM o un altro componente analizza la query in ingresso per comprendere il contenuto, il contesto e il tipo di informazioni probabilmente necessarie.
- Selezione indice: in base all'analisi, il router di query seleziona uno o più indici potenzialmente diversi disponibili. Ogni indice può essere ottimizzato per diversi tipi di dati o query, ad esempio alcuni potrebbero essere più adatti alle query effettive, mentre altri potrebbero eccellere nel fornire opinioni o contenuti soggettivi.
- Invio query: la query viene quindi inviata all'indice selezionato.
- Aggregazione risultati: le risposte dagli indici selezionati vengono recuperate e possibilmente aggregate o ulteriormente elaborate per formare una risposta completa.
- Generazione di risposte: il passaggio finale prevede la generazione di una risposta coerente in base alle informazioni recuperate, eventualmente integrando o sintetizzando il contenuto da più origini.
L'organizzazione potrebbe usare più motori di recupero o indici per i casi d'uso seguenti:
- Specializzazione tipo di dati: alcuni indici possono essere specializzati in articoli di notizie, altri in documenti accademici e altri ancora in contenuti Web generali o database specifici come quelli per informazioni mediche o legali.
- Ottimizzazione dei tipi di query: alcuni indici potrebbero essere ottimizzati per ricerche pratiche rapide (ad esempio date, eventi), mentre altri potrebbero essere migliori per attività o query complesse che richiedono una conoscenza approfondita del dominio.
- Differenze algoritmiche: è possibile usare algoritmi di recupero diversi in motori diversi, ad esempio ricerche di somiglianza basate su vettori, ricerche tradizionali basate su parole chiave o modelli di comprensione semantica più avanzati.
Si immagini un sistema basato su RAG usato in un contesto di consulenza medica. Il sistema ha accesso a più indici:
- Indice di un documento di ricerca medica ottimizzato per spiegazioni dettagliate e tecniche.
- Indice di case study clinico che fornisce esempi reali di sintomi e trattamenti.
- Indice generale delle informazioni sull'integrità per query di base e informazioni sull'integrità pubblica.
Se un utente pone una domanda tecnica sugli effetti biochimici di un nuovo farmaco, il router di query potrebbe dare priorità all'indice della carta di ricerca medica a causa della sua profondità e della sua attenzione tecnica. Per una domanda sui sintomi tipici di una malattia comune, tuttavia, l'indice di salute generale potrebbe essere scelto per il suo contenuto ampio e facilmente comprensibile.
Passaggi di elaborazione post-recupero
L'elaborazione post-recupero si verifica dopo che il componente retriever recupera i blocchi di contenuto pertinenti dal database vettoriale, come illustrato nel diagramma:

Con i blocchi di contenuto candidati recuperati, i passaggi successivi consentono di verificare che i blocchi dell'articolo siano utili quando si aumenta il prompt LLM e quindi iniziano a preparare la richiesta da presentare all'LLM.
Gli sviluppatori devono prendere in considerazione diversi aspetti della richiesta. Una richiesta che include troppe informazioni supplementari e alcune (probabilmente le informazioni più importanti) potrebbero essere ignorate. Analogamente, una richiesta che include informazioni irrilevanti potrebbe influire eccessivamente sulla risposta.
Un'altra considerazione è l'ago in un problema dello stack di fieno , un termine che si riferisce a una stranetta nota di alcune VM in cui il contenuto all'inizio e alla fine di una richiesta ha un peso maggiore per l'LLM rispetto al contenuto al centro.
Infine, è necessario considerare la lunghezza massima della finestra di contesto dell'LLM e il numero di token necessari per completare richieste straordinariemente lunghe (soprattutto quando si gestiscono query su larga scala).
Per risolvere questi problemi, una pipeline di elaborazione post-recupero potrebbe includere i passaggi seguenti:
- Filtro dei risultati : in questo passaggio gli sviluppatori assicurano che i blocchi dell'articolo restituiti dal database vettoriale siano rilevanti per la query. In caso contrario, il risultato viene ignorato durante la composizione del prompt per LLM.
- Rivalutazione : classifica i blocchi dell'articolo recuperati dall'archivio vettoriale per garantire che i dettagli pertinenti siano presenti vicino ai bordi (inizio e fine) della richiesta.
- Compressione prompt: uso di un modello di piccole dimensioni e poco costoso progettato per combinare e riepilogare più blocchi di articolo in un unico prompt compresso prima di inviarlo all'LLM.
Passaggi di elaborazione post-completamento
L'elaborazione post-completamento viene eseguita dopo che la query dell'utente e tutti i blocchi di contenuto sono stati inviati al file LLM, come illustrato nel diagramma seguente:

Una volta completata la richiesta da LLM, è il momento di convalidare il completamento per assicurarsi che la risposta sia accurata. Una pipeline di elaborazione post-completamento potrebbe includere i passaggi seguenti:
- Verifica dei fatti : questo potrebbe assumere molte forme, ma lo scopo è identificare attestazioni specifiche effettuate nell'articolo che vengono presentate come fatti e quindi per verificare la precisione di tali fatti. Se il passaggio di verifica dei fatti ha esito negativo, potrebbe essere opportuno eseguire nuovamente una query sull'LLM sperando di ottenere una risposta migliore o restituire un messaggio di errore all'utente.
- Controllo dei criteri: questa è l'ultima linea di difesa per garantire che le risposte non contengano contenuto dannoso, sia per l'utente che per l'organizzazione.
Valutazione
La valutazione dei risultati di un sistema non deterministico non è semplice, ad esempio unit test o di integrazione con cui la maggior parte degli sviluppatori ha familiarità. Esistono diversi fattori da considerare:
- Gli utenti sono soddisfatti dei risultati ottenuti?
- Gli utenti ricevono risposte accurate alle loro domande?
- Come si acquisiscono i commenti e suggerimenti degli utenti? Sono presenti criteri che limitano i dati che è possibile raccogliere sui dati utente?
- Per la diagnosi sulle risposte insoddisfacenti, abbiamo visibilità su tutto il lavoro che è andato a rispondere alla domanda? Si mantiene un log di ogni fase nella pipeline di inferenza di input e output in modo da poter eseguire l'analisi della causa radice?
- Come è possibile apportare modifiche al sistema senza regressione o riduzione dei risultati?
Acquisizione e azione di feedback da parte degli utenti
Come accennato in precedenza, gli sviluppatori potrebbero dover collaborare con il team di privacy dell'organizzazione per progettare meccanismi di acquisizione dei commenti e dati di telemetria, registrazione e così via per abilitare l'analisi forense e della causa radice in una determinata sessione di query.
Il passaggio successivo consiste nello sviluppare una pipeline di valutazione. La necessità di una pipeline di valutazione deriva dalla complessità e dalla natura a elevato utilizzo di tempo dell'analisi del feedback dettagliato e delle cause radice delle risposte fornite da un sistema di intelligenza artificiale. Questa analisi è fondamentale perché implica l'analisi di ogni risposta per comprendere come la query di intelligenza artificiale ha prodotto i risultati, verificando l'adeguatezza dei blocchi di contenuto usati dalla documentazione e le strategie usate per suddividere questi documenti.
Inoltre, prevede la possibilità di prendere in considerazione eventuali passaggi aggiuntivi di pre-elaborazione o post-elaborazione che potrebbero migliorare i risultati. Questo esame dettagliato spesso rivela lacune nel contenuto, in particolare quando non esiste alcuna documentazione appropriata in risposta alla query di un utente.
La creazione di una pipeline di valutazione, pertanto, diventa essenziale per gestire in modo efficace la scalabilità di queste attività. Una pipeline efficiente usa strumenti personalizzati per valutare le metriche che approssimano la qualità delle risposte fornite dall'intelligenza artificiale. Questo sistema semplifica il processo di determinazione del motivo per cui è stata data una risposta specifica alla domanda di un utente, quali documenti sono stati usati per generare tale risposta e l'efficacia della pipeline di inferenza che elabora le query.
Set di dati golden
Una strategia per valutare i risultati di un sistema non deterministico come un sistema rag-chat consiste nell'implementare un "set di dati golden". Un set di dati golden è un set curato di domande con risposte approvate, metadati (ad esempio argomento e tipo di domanda), riferimenti ai documenti di origine che possono fungere da verità di base per le risposte e anche variazioni (formulazioni diverse per acquisire la diversità di come gli utenti potrebbero porre le stesse domande).
Il "set di dati golden" rappresenta lo "scenario migliore" e consente agli sviluppatori di valutare il livello di prestazioni del sistema e di eseguire test di regressione durante l'implementazione di nuove funzionalità o aggiornamenti.
Valutazione del danno
La modellazione dei danni è una metodologia volta a prevedere potenziali danni, individuare le carenze in un prodotto che potrebbe rappresentare rischi per gli individui e sviluppare strategie proattive per attenuare tali rischi.
Lo strumento progettato per valutare l'impatto della tecnologia, in particolare i sistemi di IA, include diversi componenti chiave in base ai principi della modellazione dei danni, come descritto nelle risorse fornite.
Le funzionalità principali di uno strumento di valutazione dei danni possono includere:
Identificazione degli stakeholder: lo strumento aiuterà gli utenti a identificare e classificare vari stakeholder interessati dalla tecnologia, inclusi utenti diretti, parti interessate indirettamente e altre entità come generazioni future o fattori non umani, ad esempio problemi ambientali (.
Categorie e descrizioni dei danni: includerebbe un elenco completo di potenziali danni, ad esempio perdita di privacy, disagio emotivo o sfruttamento economico. Lo strumento potrebbe guidare l'utente attraverso vari scenari che illustrano come la tecnologia potrebbe causare questi danni, contribuendo a valutare le conseguenze intenzionali e impreviste.
Gravità e valutazioni delle probabilità: lo strumento consente agli utenti di valutare la gravità e la probabilità di ogni danno identificato, consentendo loro di classificare in ordine di priorità i problemi da risolvere per primi. Ciò può includere valutazioni qualitative e può essere supportato dai dati, se disponibili.
Strategie di mitigazione: quando si identificano e valutano i danni, lo strumento suggerisce potenziali strategie di mitigazione. Ciò può includere modifiche alla progettazione del sistema, misure di sicurezza o soluzioni tecnologiche alternative che riducono al minimo i rischi identificati.
Meccanismi di feedback: lo strumento deve incorporare meccanismi per raccogliere feedback dagli stakeholder, assicurandosi che il processo di valutazione dei danni sia dinamico e reattivo alle nuove informazioni e prospettive.
Documentazione e creazione di report: per facilitare la trasparenza e la responsabilità, lo strumento faciliterebbe la creazione di report dettagliati che documentino il processo di valutazione dei danni, i risultati e le azioni intraprese per attenuare i potenziali rischi.
Queste funzionalità non solo aiutano a identificare e mitigare i rischi, ma anche a progettare sistemi di IA più etici e responsabili considerando un'ampia gamma di impatti fin dall'inizio.
Per altre informazioni, vedi:
Test e verifica delle misure di sicurezza
Questo articolo ha descritto diversi processi volti a ridurre la possibilità che il sistema di chat basato su RAG possa essere sfruttato o compromesso. Il red-teaming svolge un ruolo fondamentale per garantire che le mitigazioni siano efficaci. Il red-teaming implica la simulazione delle azioni di un antagonista volte all'applicazione per individuare potenziali punti deboli o vulnerabilità. Questo approccio è particolarmente vitale per affrontare il rischio significativo di jailbreaking.
Per testare e verificare in modo efficace le misure di sicurezza di un sistema di chat basato su RAG, gli sviluppatori devono valutare rigorosamente questi sistemi in vari scenari in cui queste linee guida potrebbero essere testate. Ciò non solo garantisce robustezza, ma aiuta anche a ottimizzare le risposte del sistema per rispettare rigorosamente gli standard etici definiti e le procedure operative.
Considerazioni finali che potrebbero influenzare le decisioni di progettazione dell'applicazione
Ecco un breve elenco di aspetti da considerare e altre considerazioni di questo articolo che influiscono sulle decisioni di progettazione delle applicazioni:
- Riconoscere la natura non deterministica dell'intelligenza artificiale generativa nella progettazione, pianificare la variabilità negli output e configurare meccanismi per garantire coerenza e pertinenza nelle risposte.
- Valutare i vantaggi della pre-elaborazione delle richieste degli utenti rispetto al potenziale aumento della latenza e dei costi. Semplificare o modificare le richieste prima dell'invio potrebbe migliorare la qualità della risposta, ma potrebbe aggiungere complessità e tempo al ciclo di risposta.
- Analizzare le strategie per parallelizzare le richieste LLM per migliorare le prestazioni. Questo approccio potrebbe ridurre la latenza, ma richiede un'attenta gestione per evitare una maggiore complessità e potenziali implicazioni in termini di costi.
Se si vuole iniziare subito a sperimentare la creazione di una soluzione di intelligenza artificiale generativa, è consigliabile esaminare Introduzione alla chat usando un esempio di dati personalizzato per Python. Sono disponibili versioni dell'esercitazione anche in .NET, Java e JavaScript.