Esercitazione: Eseguire la migrazione del server applicazioni WebSphere ad Azure Macchine virtuali con disponibilità elevata e ripristino di emergenza
Questa esercitazione illustra un modo semplice ed efficace per implementare la disponibilità elevata e il ripristino di emergenza (HA/DR) per Java usando WebSphere Application Server in Azure Macchine virtuali (VM). La soluzione illustra come ottenere un obiettivo del tempo di recupero ridotto (RTO) e un obiettivo del punto di ripristino (RPO) usando una semplice applicazione Jakarta EE basata su database in esecuzione nel server applicazioni WebSphere. Disponibilità elevata/ripristino di emergenza è un argomento complesso, con molte possibili soluzioni. La soluzione migliore dipende dai requisiti specifici. Per altri modi per implementare disponibilità elevata/ripristino di emergenza, vedere le risorse alla fine di questo articolo.
In questa esercitazione apprenderai a:
- Usare le procedure consigliate ottimizzate per Azure per ottenere disponibilità elevata e ripristino di emergenza.
- Configurare un gruppo di failover database SQL di Microsoft Azure in aree abbinate.
- Configurare il cluster WebSphere primario nelle macchine virtuali di Azure.
- Configurare il ripristino di emergenza per il cluster usando Azure Site Recovery.
- Configurare un Gestione traffico di Azure.
- Failover di test da primario a secondario.
Il diagramma seguente illustra l'architettura compilata:

Gestione traffico di Azure controlla l'integrità delle aree e indirizza il traffico di conseguenza al livello applicazione. L'area primaria ha una distribuzione completa del cluster WebSphere. Dopo che l'area primaria è protetta da Azure Site Recovery, è possibile ripristinare l'area secondaria durante il failover. Di conseguenza, l'area primaria esegue attivamente la manutenzione delle richieste di rete degli utenti, mentre l'area secondaria è passiva e attivata per ricevere traffico solo quando l'area primaria subisce un'interruzione del servizio.
Gestione traffico di Azure rileva l'integrità dell'app distribuita in IBM HTTP Server per implementare il routing condizionale. L'RTO di failover geografico del livello applicazione dipende dal tempo necessario per arrestare il cluster primario, ripristinare il cluster secondario, avviare le macchine virtuali ed eseguire il cluster WebSphere secondario. L'RPO dipende dai criteri di replica di Azure Site Recovery e database SQL di Azure. Questa dipendenza è dovuta al fatto che i dati del cluster vengono archiviati e replicati nella risorsa di archiviazione locale delle macchine virtuali e i dati dell'applicazione vengono mantenuti e replicati nel gruppo di failover database SQL di Azure.
Il diagramma precedente mostra l'area primaria e l'area secondaria come due aree che comprendono l'architettura di disponibilità elevata/ripristino di emergenza. Queste aree devono essere aree abbinate di Azure. Per altre informazioni sulle aree abbinate, vedere Replica tra aree di Azure. L'articolo usa Stati Uniti orientali e Stati Uniti occidentali come due aree, ma possono essere tutte le aree abbinate che hanno senso per lo scenario in uso. Per l'elenco delle associazioni di aree, vedere la sezione Aree abbinate di Azure della replica tra aree di Azure.
Il livello di database è costituito da un gruppo di failover database SQL di Azure con un server primario e un server secondario. L'endpoint del listener di lettura/scrittura punta sempre al server primario ed è connesso al cluster WebSphere in ogni area. Un failover geografico passa tutti i database secondari del gruppo al ruolo primario. Per rpo di failover geografico e RTO di database SQL di Azure, vedere Panoramica della continuità aziendale con database SQL di Azure.
Questa esercitazione è stata scritta con Azure Site Recovery e il servizio database SQL di Azure perché l'esercitazione si basa sulle funzionalità a disponibilità elevata di questi servizi. Sono possibili altre opzioni di database, ma è necessario considerare le funzionalità a disponibilità elevata di qualsiasi database scelto.
Prerequisiti
- Una sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
- Assicurarsi di avere il
Contributorruolo nella sottoscrizione. È possibile verificare l'assegnazione seguendo la procedura descritta in Elencare le assegnazioni di ruolo di Azure usando il portale di Azure. - Preparare un computer locale con Windows, Linux o macOS installato.
- Installare e configurare Git.
- Installare un'implementazione java SE, versione 17 o successiva, ad esempio la build Microsoft di OpenJDK.
- Installare Maven, versione 3.9.3 o successiva.
Configurare un gruppo di failover database SQL di Azure in aree abbinate
In questa sezione viene creato un gruppo di failover database SQL di Azure in aree abbinate da usare con i cluster e l'app WebSphere. In una sezione successiva si configura WebSphere per archiviare i dati della sessione in questo database. Questa procedura fa riferimento alla creazione di una tabella per la persistenza della sessione.
Creare prima di tutto il database SQL di Azure primario seguendo la procedura portale di Azure descritta in Avvio rapido: Creare un database singolo - database SQL di Azure. Seguire i passaggi fino a, ma non includere, la sezione "Pulire le risorse". Usare le istruzioni seguenti durante l'articolo, quindi tornare a questo articolo dopo aver creato e configurato il database SQL di Azure:
Quando si raggiunge la sezione Creare un database singolo, seguire questa procedura:
- Nel passaggio 4 per la creazione di un nuovo gruppo di risorse salvare il valore del nome del gruppo di risorse,
myResourceGroupad esempio . - Nel passaggio 5 per il nome del database salvare il valore Nome database,
mySampleDatabasead esempio . - Nel passaggio 6 per la creazione del server, seguire questa procedura:
- Immettere un nome di server univoco,
sqlserverprimary-mjg022624ad esempio . - In Località selezionare (USA) Stati Uniti orientali.
- Per Metodo di autenticazione selezionare Usa autenticazione SQL.
- Salvare a parte il valore di account di accesso amministratore del server,
azureuserad esempio . - Salvare il valore password .
- Immettere un nome di server univoco,
- Nel passaggio 8, per Ambiente del carico di lavoro, selezionare Sviluppo. Esaminare la descrizione e prendere in considerazione altre opzioni per il carico di lavoro.
- Nel passaggio 11, per Ridondanza dell'archiviazione di backup, selezionare Archiviazione di backup con ridondanza locale. Prendere in considerazione altre opzioni per i backup. Per altre informazioni, vedere la sezione Ridondanza dell'archiviazione di backup in Backup automatici in database SQL di Azure.
- Nel passaggio 14, nella configurazione delle regole del firewall, per Consenti ai servizi e alle risorse di Azure di accedere a questo server, selezionare Sì.
- Nel passaggio 4 per la creazione di un nuovo gruppo di risorse salvare il valore del nome del gruppo di risorse,
Quando si raggiunge la sezione Eseguire una query sul database, seguire questa procedura:
Nel passaggio 3 immettere le informazioni di accesso dell'amministratore del server di autenticazione SQL per l'accesso .
Nota
Se l'accesso non riesce con un messaggio di errore simile al client con indirizzo IP 'xx.xx.xx.xx.xx' non è autorizzato ad accedere al server, selezionare Allowlist IP xx.xx.xx.xx nel server <your-sqlserver-name> alla fine del messaggio di errore. Attendere il completamento dell'aggiornamento delle regole del firewall del server, quindi selezionare di nuovo OK .
Dopo aver eseguito la query di esempio nel passaggio 5, deselezionare l'editor e immettere la query seguente, quindi selezionare di nuovo Esegui :
CREATE TABLE sessions ( ID VARCHAR(128) NOT NULL, PROPID VARCHAR(128) NOT NULL, APPNAME VARCHAR(128) NOT NULL, LISTENERCNT SMALLINT, LASTACCESS BIGINT, CREATIONTIME BIGINT, MAXINACTIVETIME INT, USERNAME VARCHAR(256), SMALL VARBINARY(MAX), MEDIUM VARCHAR(MAX), LARGE VARBINARY(MAX) );Dopo un'esecuzione riuscita, verrà visualizzato il messaggio Query completata: Righe interessate: 0.
La tabella
sessionsdi database viene usata per archiviare i dati di sessione per l'app WebSphere. I dati del cluster WebSphere, inclusi i log delle transazioni, vengono salvati in modo permanente nell'archiviazione locale delle macchine virtuali in cui viene distribuito il cluster.
Creare quindi un gruppo di failover database SQL di Azure seguendo la procedura portale di Azure descritta in Configurare un gruppo di failover per database SQL di Azure. Sono necessarie solo le sezioni seguenti: Creare un gruppo di failover e Testare il failover pianificato. Usare la procedura seguente durante l'articolo, quindi tornare a questo articolo dopo aver creato e configurato il gruppo di failover database SQL di Azure:
Nella sezione Creare un gruppo di failover seguire questa procedura:
- Nel passaggio 5 per la creazione del gruppo di failover immettere e salvare il nome univoco del gruppo di failover,
failovergroup-mjg022624ad esempio . - Nel passaggio 5 per la configurazione del server selezionare l'opzione per creare un nuovo server secondario e quindi seguire questa procedura:
- Immettere un nome univoco del server,
sqlserversecondary-mjg022624ad esempio . - Immettere lo stesso amministratore del server e la stessa password del server primario.
- Per Località selezionare (Stati Uniti) Stati Uniti occidentali.
- Assicurarsi che l'opzione Consenti ai servizi di Azure di accedere al server sia selezionata.
- Immettere un nome univoco del server,
- Nel passaggio 5 per la configurazione dei database all'interno del gruppo selezionare il database creato nel server primario,
mySampleDatabasead esempio .
- Nel passaggio 5 per la creazione del gruppo di failover immettere e salvare il nome univoco del gruppo di failover,
Dopo aver completato tutti i passaggi nella sezione Testare il failover pianificato, tenere aperta la pagina del gruppo di failover e usarla per il test di failover dei cluster WebSphere in un secondo momento.
Configurare il cluster WebSphere primario nelle macchine virtuali di Azure
In questa sezione vengono creati i cluster WebSphere primari nelle macchine virtuali di Azure usando l'offerta IBM WebSphere Application Server Cluster in macchine virtuali di Azure. Il cluster secondario viene ripristinato dal cluster primario durante il failover usando Azure Site Recovery in un secondo momento.
Distribuire il cluster WebSphere primario
Aprire prima di tutto l'offerta IBM WebSphere Application Server Cluster in macchine virtuali di Azure nel browser e selezionare Crea. Verrà visualizzato il riquadro Informazioni di base dell'offerta.
Per compilare il riquadro Informazioni di base, seguire questa procedura:
- Assicurarsi che il valore visualizzato per Subscription sia lo stesso che include i ruoli elencati nella sezione prerequisiti.
- È necessario distribuire l'offerta in un gruppo di risorse vuoto. Nel campo Gruppo di risorse selezionare Crea nuovo e compilare un valore univoco per il gruppo di risorse,
was-cluster-eastus-mjg022624ad esempio . - In Dettagli istanza selezionare Stati Uniti orientali in Area.
- Per Distribuisci con diritto WebSphere esistente o con licenza di valutazione? selezionare Valutazione per questa esercitazione. È anche possibile selezionare Diritto e fornire le credenziali IBMid.
- Selezionare Ho letto e accettato il Contratto di licenza IBM.
- Lasciare le impostazioni predefinite per gli altri campi.
- Selezionare Avanti per passare al riquadro Configurazione cluster.

Per compilare il riquadro Configurazione cluster, seguire questa procedura:
- Per Password per l'amministratore della macchina virtuale specificare una password.
- Per Password per l'amministratore di WebSphere, specificare una password. Salvare il nome utente e la password per l'amministratore di WebSphere.
- Lasciare le impostazioni predefinite per gli altri campi.
- Selezionare Avanti per passare al riquadro Bilanciamento del carico.

Per compilare il riquadro Bilanciamento del carico , seguire questa procedura:
- Per Password per l'amministratore della macchina virtuale specificare una password.
- Per Password per l'amministratore di IBM HTTP Server, specificare una password.
- Lasciare le impostazioni predefinite per gli altri campi.
- Selezionare Avanti per passare al riquadro Rete .

Verranno visualizzati tutti i campi prepopolati con le impostazioni predefinite nel riquadro Rete . Selezionare Avanti per passare al riquadro Database .

I passaggi seguenti illustrano come compilare il riquadro Database :
- Per Connetti al database? selezionare Sì.
- Per Scegliere il tipo di database selezionare Microsoft SQL Server .
- Per Nome JNDI immettere jdbc/WebSphereCafeDB.
- Per Data source stringa di connessione (jdbc:sqlserver://<host>:<port>; database=<database>), sostituire i segnaposto con i valori salvati nella sezione precedente per il gruppo di failover per il database SQL di Azure,
jdbc:sqlserver://failovergroup-mjg022624.database.windows.net:1433;database=mySampleDatabasead esempio . - Per Nome utente database immettere il nome di accesso dell'amministratore del server e il nome del gruppo di failover salvato nella sezione precedente,
azureuser@failovergroup-mjg022624ad esempio .Nota
Prestare particolare attenzione all'uso del nome host del server di database e del nome utente del database corretti per il gruppo di failover, anziché il nome host e il nome utente del server dal database primario o di backup. Usando i valori del gruppo di failover, si indica, in effetti, a WebSphere di comunicare con il gruppo di failover. Tuttavia, per quanto riguarda WebSphere, si tratta solo di una normale connessione di database.
- Immettere la password di accesso dell'amministratore del server salvata in precedenza per Password database. Immettere lo stesso valore per Conferma password.
- Lasciare le impostazioni predefinite per gli altri campi.
- Selezionare Rivedi e crea.
- Attendere il completamento dell'esecuzione della convalida finale e quindi selezionare Crea.

Dopo un po', verrà visualizzata la pagina Distribuzione in cui è in corso la distribuzione.
Nota
Se si verificano problemi durante l'esecuzione della convalida finale, correggerli e riprovare.
A seconda delle condizioni di rete e di altre attività nell'area selezionata, il completamento della distribuzione può richiedere fino a 25 minuti. Successivamente, verrà visualizzato il testo La distribuzione è stata completata nella pagina di distribuzione.
Verificare la distribuzione del cluster
Nel cluster sono stati distribuiti un SERVER HTTP IBM (IHS) e un WebSphere Deployment Manager (Dmgr). IHS funge da servizio di bilanciamento del carico per tutti i server applicazioni nel cluster. Dmgr fornisce una console Web per la configurazione del cluster.
Seguire questa procedura per verificare se la console IHS e Dmgr funzionano prima di passare al passaggio successivo:
Tornare alla pagina Distribuzione e quindi selezionare Output.
Copiare il valore della proprietà ihsConsole. Aprire l'URL in una nuova scheda del browser. Si noti che in questo esempio non viene usato
httpsper IHS. Verrà visualizzata una pagina iniziale di IHS senza alcun messaggio di errore. In caso contrario, è necessario risolvere il problema prima di continuare. Mantenere aperta la console e usarla per verificare la distribuzione dell'app del cluster in un secondo momento.
Copiare e salvare il valore dell'amministratore della proprietàSecuredConsole. Aprirlo in una nuova scheda del browser. Accettare l'avviso del browser per il certificato TLS autofirmato. Non passare all'ambiente di produzione usando un certificato TLS autofirmato.
Verrà visualizzata la pagina di accesso di WebSphere Integrated Solutions Console. Accedere alla console con il nome utente e la password per l'amministratore di WebSphere salvati in precedenza. Se non è possibile accedere, è necessario risolvere il problema prima di continuare. Mantenere aperta la console e usarla per un'ulteriore configurazione del cluster WebSphere in un secondo momento.

Usare la procedura seguente per ottenere il nome dell'indirizzo IP pubblico dell'IHS. Viene usato quando si configura il Gestione traffico di Azure in un secondo momento.
- Aprire il gruppo di risorse in cui viene distribuito il cluster, ad esempio selezionare Panoramica per tornare al riquadro Panoramica della pagina di distribuzione e quindi selezionare Vai al gruppo di risorse.
- Nella tabella delle risorse trovare la colonna Tipo . Selezionarlo per ordinare in base al tipo di risorsa.
- Trovare la risorsa indirizzo IP pubblico preceduta da
ihs, quindi copiare e salvare il nome.
Configurare il cluster
Prima di tutto, usare la procedura seguente per abilitare l'opzione Sincronizza modifiche con nodi in modo che qualsiasi configurazione possa essere sincronizzata automaticamente con tutti i server applicazioni:
- Tornare alla console delle soluzioni integrate WebSphere e accedere di nuovo se si è disconnessi.
- Nel riquadro di spostamento selezionare Preferenze della console di amministrazione>del sistema.
- Nel riquadro Preferenze console selezionare Synchronize changes with Nodes (Sincronizza modifiche con nodi) e quindi selezionare Applica. Verrà visualizzato il messaggio Le preferenze sono state modificate.
Usare quindi la procedura seguente per configurare le sessioni distribuite del database per tutti i server applicazioni:
- Nel riquadro di spostamento selezionare Server Tipi di>server Server Application Servers>.
- Nel riquadro Server applicazioni dovrebbero essere elencati 3 server applicazioni. Per ogni server applicazioni, usare le istruzioni seguenti per configurare le sessioni distribuite del database:
- Nella tabella sotto il testo È possibile amministrare le risorse seguenti, selezionare il collegamento ipertestuale per il server applicazioni, che inizia con
MyCluster. - Nella sezione Impostazioni contenitore selezionare Gestione sessione.
- Nella sezione Proprietà aggiuntive selezionare Impostazioni ambiente distribuito.
- Per Sessioni distribuite selezionare Database (supportato solo per contenitore Web).
- Selezionare Database e seguire questa procedura:
- Per Nome JNDI dell'origine dati immettere jdbc/WebSphereCafeDB.
- Per ID utente immettere il nome di accesso dell'amministratore del server e il nome del gruppo di failover salvato nella sezione precedente,
azureuser@failovergroup-mjg022624ad esempio . - Immettere la password di accesso amministratore di Azure SQL Server salvata in precedenza per Password.
- Per Nome spazio tabella immettere sessioni.
- Selezionare Usa schema a più righe.
- Seleziona OK. Si viene indirizzati di nuovo al riquadro Impostazioni ambiente distribuito.
- Nella sezione Proprietà aggiuntive selezionare Parametri di ottimizzazione personalizzati.
- Per Livello di ottimizzazione selezionare Basso (ottimizzazione per il failover).
- Seleziona OK.
- In Messaggi selezionare Salva. Attendere il completamento.
- Selezionare Server applicazioni nella barra di navigazione superiore. Si viene indirizzati di nuovo al riquadro Server applicazioni .
- Nella tabella sotto il testo È possibile amministrare le risorse seguenti, selezionare il collegamento ipertestuale per il server applicazioni, che inizia con
- Nel riquadro di spostamento selezionare Server Clusters WebSphere application server clusters> (Cluster>server applicazioni WebSphere).
- Nel riquadro Cluster server applicazioni WebSphere dovrebbe essere visualizzato l'elenco del cluster
MyCluster. Selezionare la casella di controllo accanto a MyCluster. - Selezionare Ripplestart.
- Attendere il riavvio del cluster. È possibile selezionare l'icona Stato e, se la nuova finestra non viene visualizzata, tornare alla console e aggiornare la pagina Web dopo un po'. Ripetere l'operazione fino a quando non viene visualizzato Avviato. È possibile che venga visualizzato inizio parziale prima di raggiungere lo stato Avviato
Mantenere aperta la console e usarla per la distribuzione di app in un secondo momento.
Distribuire un'app di esempio
Questa sezione illustra come distribuire ed eseguire un'applicazione CRUD Java/Jakarta EE di esempio in un cluster WebSphere per il test di failover di ripristino di emergenza in un secondo momento.
I server applicazioni sono stati configurati per l'uso dell'origine jdbc/WebSphereCafeDB dati per archiviare i dati di sessione in precedenza, consentendo il failover e il bilanciamento del carico in un cluster di server applicazioni WebSphere. L'app di esempio configura anche uno schema di persistenza per rendere persistenti i dati coffee dell'applicazione nella stessa origine jdbc/WebSphereCafeDBdati.
Usare prima di tutto i comandi seguenti per scaricare, compilare e creare il pacchetto dell'esempio:
git clone https://github.com/Azure-Samples/websphere-cafe
cd websphere-cafe
git checkout 20240326
mvn clean package
Se viene visualizzato un messaggio relativo all'essere in Detached HEAD uno stato, questo messaggio è sicuro da ignorare.
Il pacchetto deve essere generato correttamente e situato in parent-path-to-your-local-clone>/websphere-café/websphere-café-application/target/websphere-café.ear.< Se il pacchetto non viene visualizzato, è necessario risolvere il problema prima di continuare.
Usare quindi la procedura seguente per distribuire l'app di esempio nel cluster:
- Tornare alla console delle soluzioni integrate WebSphere e accedere di nuovo se si è disconnessi.
- Nel riquadro di spostamento selezionare Applicazioni>Tipi di>applicazione Applicazioni
- Nel riquadro Applicazioni aziendali selezionare Installa>Scegli file. Trovare quindi il pacchetto disponibile in parent-path-to-your-local-clone>/websphere-café/websphere-café-application/target/websphere-café.ear e selezionare Apri.< Selezionare Avanti>successivo.>
- Nel riquadro Mappa moduli ai server premere CTRL e selezionare tutti gli elementi elencati in Cluster e server. Selezionare la casella di controllo accanto a websphere-café.war. Selezionare Applica. Selezionare Avanti fino a visualizzare il pulsante Fine.
- Selezionare Fine>salvataggio, quindi attendere il completamento. Seleziona OK.
- Selezionare l'applicazione
websphere-cafeinstallata e quindi selezionare Avvia. Attendere che vengano visualizzati messaggi che indicano che l'applicazione è stata avviata correttamente. Se non è possibile visualizzare il messaggio con esito positivo, è necessario risolvere il problema prima di continuare.
A questo scopo, seguire questa procedura per verificare che l'app sia in esecuzione come previsto:
Tornare alla console IHS. Aggiungere la radice
/websphere-cafe/del contesto dell'app distribuita alla barra degli indirizzi,http://ihs70685e.eastus.cloudapp.azure.com/websphere-cafe/ad esempio , e quindi premere INVIO. Verrà visualizzata la pagina iniziale dell'app di esempio.Creare un nuovo caffè con un nome e un prezzo, ad esempio Coffee 1 con prezzo $10 , che viene salvato in modo permanente nella tabella dati dell'applicazione e nella tabella di sessione del database. L'interfaccia utente visualizzata dovrebbe essere simile alla schermata seguente:
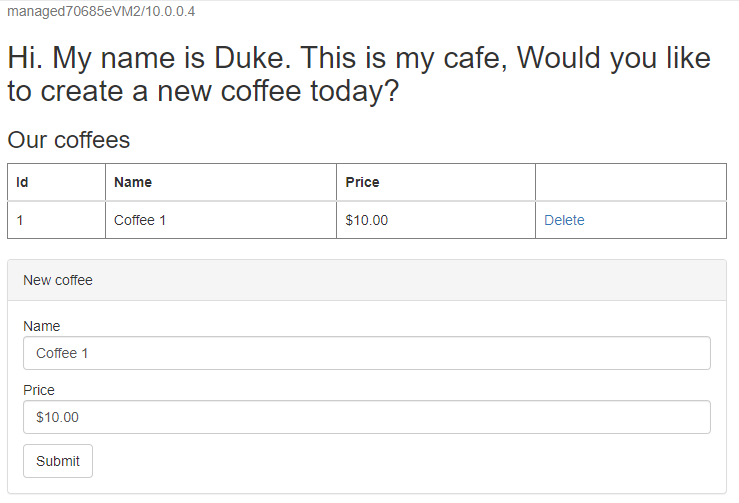

Se l'interfaccia utente non è simile, risolvere e risolvere il problema che si continua.
Configurare il ripristino di emergenza per il cluster usando Azure Site Recovery
In questa sezione viene configurato il ripristino di emergenza per le macchine virtuali di Azure nel cluster primario usando Azure Site Recovery seguendo la procedura descritta in Esercitazione: Configurare il ripristino di emergenza per le macchine virtuali di Azure. Sono necessarie solo le sezioni seguenti: Creare un insieme di credenziali di Servizi di ripristino e Abilitare la replica. Prestare attenzione ai passaggi seguenti man mano che si esegue l'articolo, quindi tornare a questo articolo dopo la protezione del cluster primario:
Nella sezione Creare un insieme di credenziali di Servizi di ripristino seguire questa procedura:
Nel passaggio 5 per Gruppo di risorse creare un nuovo gruppo di risorse con un nome univoco nella sottoscrizione,
was-cluster-westus-mjg022624ad esempio .Nel passaggio 6 per Nome insieme di credenziali specificare un nome dell'insieme di credenziali,
recovery-service-vault-westus-mjg022624ad esempio .Nel passaggio 7 per Area selezionare Stati Uniti occidentali.
Prima di selezionare Rivedi e crea nel passaggio 8, selezionare Avanti: Ridondanza. Nel riquadro Ridondanza selezionare Ridondanza geografica per Ridondanza archiviazione backup e Abilita per il ripristino tra aree.
Nota
Assicurarsi di selezionare Ridondanza geografica per Ridondanza archiviazione di backup e Abilita per il ripristino tra aree nel riquadro Ridondanza. In caso contrario, l'archiviazione del cluster primario non può essere replicata nell'area secondaria.
Abilitare Site Recovery seguendo la procedura descritta nella sezione Abilitare Site Recovery.
Quando si raggiunge la sezione Abilitare la replica, seguire questa procedura:
- Nella sezione Selezionare le impostazioni di origine seguire questa procedura:
In Area selezionare Stati Uniti orientali.
In Gruppo di risorse selezionare la risorsa in cui viene distribuito il cluster primario,
was-cluster-eastus-mjg022624ad esempio .Nota
Se il gruppo di risorse desiderato non è elencato, è possibile selezionare Stati Uniti occidentali per l'area e quindi tornare agli Stati Uniti orientali.
Lasciare le impostazioni predefinite per gli altri campi. Selezionare Avanti.
- Nella sezione Selezionare le macchine virtuali, per Macchine virtuali, selezionare tutte e cinque le macchine virtuali elencate e quindi selezionare Avanti.
- Nella sezione Esaminare le impostazioni di replica seguire questa procedura:
- Per Località di destinazione selezionare Stati Uniti occidentali.
- In Gruppo di risorse di destinazione selezionare il gruppo di risorse in cui viene distribuito l'insieme di credenziali di ripristino del servizio,
was-cluster-westus-mjg022624ad esempio . - Prendere nota della nuova rete virtuale di failover e della subnet di failover, mappate da quelle nell'area primaria.
- Lasciare le impostazioni predefinite per gli altri campi.
- Selezionare Avanti.
- Nella sezione Gestisci seguire questa procedura:
- Per Criteri di replica, usare i criteri predefiniti 24 ore-retention-policy. È anche possibile creare un nuovo criterio per l'azienda.
- Lasciare le impostazioni predefinite per gli altri campi.
- Selezionare Avanti.
- Nella sezione Rivedi seguire questa procedura:
Dopo aver selezionato Abilita replica, si noti il messaggio Creazione di risorse di Azure. Non chiudere questo pannello. visualizzato nella parte inferiore della pagina. Non eseguire alcuna operazione e attendere che il riquadro venga chiuso automaticamente. Si viene reindirizzati alla pagina Site Recovery .
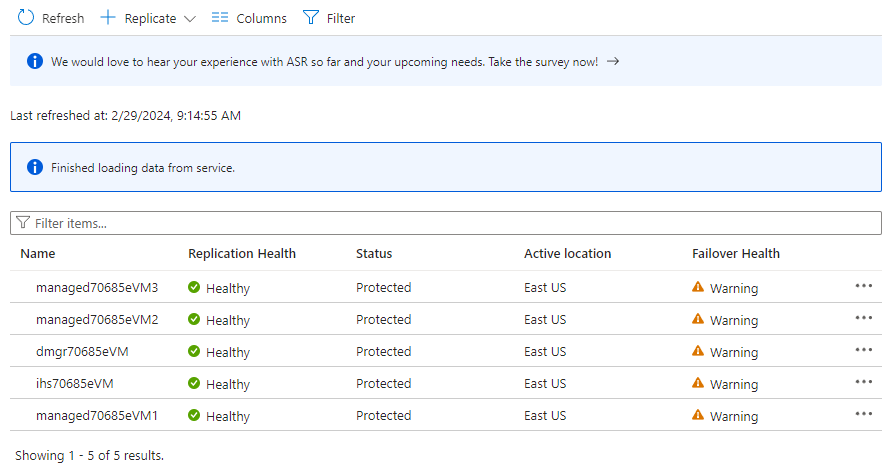
In Elementi protetti selezionare Elementi replicati. Inizialmente non sono elencati elementi perché la replica è ancora in corso. Il completamento della replica richiede circa un'ora. Aggiornare periodicamente la pagina finché non si noterà che tutte le macchine virtuali si trovano nello stato Protected , come illustrato nello screenshot di esempio seguente:
- Nella sezione Selezionare le impostazioni di origine seguire questa procedura:

Creare quindi un piano di ripristino per includere tutti gli elementi replicati in modo che possano eseguire il failover insieme. Usare le istruzioni in Creare un piano di ripristino con le personalizzazioni seguenti:
- Nel passaggio 2 immettere un nome per il piano,
recovery-plan-mjg022624ad esempio . - Nel passaggio 3, per Origine, selezionare Stati Uniti orientali e per Destinazione selezionare Stati Uniti occidentali.
- Nel passaggio 4 per Selezionare gli elementi selezionare tutte e cinque le macchine virtuali protette per questa esercitazione.
Successivamente, si crea un piano di ripristino. Mantenere aperta la pagina in modo da poterla usare per i test di failover in un secondo momento.
Ulteriore configurazione di rete per l'area secondaria
È anche necessaria un'ulteriore configurazione di rete per abilitare e proteggere l'accesso esterno all'area secondaria in un evento di failover. Per questa configurazione, seguire questa procedura:
Creare un indirizzo IP pubblico per Dmgr nell'area secondaria seguendo le istruzioni riportate in Avvio rapido: Creare un indirizzo IP pubblico usando il portale di Azure, con le personalizzazioni seguenti:
- In Gruppo di risorse selezionare il gruppo di risorse in cui viene distribuito l'insieme di credenziali di ripristino del servizio,
was-cluster-westus-mjg022624ad esempio . - In Area selezionare (Stati Uniti) Stati Uniti occidentali.
- In Nome immettere un valore,
dmgr-public-ip-westus-mjg022624ad esempio . - Per etichetta del nome DNS immettere un valore univoco,
dmgrmjg022624ad esempio .
- In Gruppo di risorse selezionare il gruppo di risorse in cui viene distribuito l'insieme di credenziali di ripristino del servizio,
Creare un altro indirizzo IP pubblico per IHS nell'area secondaria seguendo la stessa guida, con le personalizzazioni seguenti:
- In Gruppo di risorse selezionare il gruppo di risorse in cui viene distribuito l'insieme di credenziali di ripristino del servizio,
was-cluster-westus-mjg022624ad esempio . - In Area selezionare (Stati Uniti) Stati Uniti occidentali.
- In Nome immettere un valore,
ihs-public-ip-westus-mjg022624ad esempio . Annotarlo. - Per etichetta del nome DNS immettere un valore univoco,
ihsmjg022624ad esempio .
- In Gruppo di risorse selezionare il gruppo di risorse in cui viene distribuito l'insieme di credenziali di ripristino del servizio,
Creare un gruppo di sicurezza di rete nell'area secondaria seguendo le istruzioni nella sezione Creare un gruppo di sicurezza di rete di Creare, modificare o eliminare un gruppo di sicurezza di rete, con le personalizzazioni seguenti:
- In Gruppo di risorse selezionare il gruppo di risorse in cui viene distribuito l'insieme di credenziali di ripristino del servizio,
was-cluster-westus-mjg022624ad esempio . - In Nome immettere un valore,
nsg-westus-mjg022624ad esempio . - Per Area selezionare Stati Uniti occidentali.
- In Gruppo di risorse selezionare il gruppo di risorse in cui viene distribuito l'insieme di credenziali di ripristino del servizio,
Creare una regola di sicurezza in ingresso per il gruppo di sicurezza di rete seguendo le istruzioni nella sezione Creare una regola di sicurezza dello stesso articolo, con le personalizzazioni seguenti:
- Nel passaggio 2 selezionare il gruppo di sicurezza di rete creato,
nsg-westus-mjg022624ad esempio . - Nel passaggio 3 selezionare Regole di sicurezza in ingresso.
- Nel passaggio 4 personalizzare le impostazioni seguenti:
- In Intervalli di porte di destinazione immettere 9060.9080.9043.9443.80.
- In Protocollo selezionare TCP.
- In Nome immettere ALLOW_HTTP_ACCESS.
- Nel passaggio 2 selezionare il gruppo di sicurezza di rete creato,
Associare il gruppo di sicurezza di rete a una subnet seguendo le istruzioni riportate nella sezione Associare o annullare l'associazione di un gruppo di sicurezza di rete a o da una subnet dello stesso articolo, con le personalizzazioni seguenti:
- Nel passaggio 2 selezionare il gruppo di sicurezza di rete creato,
nsg-westus-mjg022624ad esempio . - Selezionare Associa per associare il gruppo di sicurezza di rete alla subnet di failover annotata in precedenza.
- Nel passaggio 2 selezionare il gruppo di sicurezza di rete creato,
Configurare un Gestione traffico di Azure
In questa sezione viene creato un Gestione traffico di Azure per distribuire il traffico alle applicazioni pubbliche nelle aree di Azure globali. L'endpoint primario punta all'indirizzo IP pubblico del servizio IHS nell'area primaria. L'endpoint secondario punta all'indirizzo IP pubblico del servizio IHS nell'area secondaria.
Creare un profilo Gestione traffico di Azure seguendo le istruzioni riportate in Avvio rapido: Creare un profilo Gestione traffico usando il portale di Azure. Sono necessarie solo le sezioni seguenti: Creare un profilo di Gestione traffico e Aggiungere endpoint Gestione traffico. È necessario ignorare le sezioni in cui si viene indirizzati a creare servizio app risorse. Usare la procedura seguente durante l'esecuzione di queste sezioni, quindi tornare a questo articolo dopo aver creato e configurato il Gestione traffico di Azure.
Nella sezione Creare un profilo di Gestione traffico, nel passaggio 2, per Creare un profilo Gestione traffico, seguire questa procedura:
- Salvare il nome univoco del profilo di Gestione traffico per Nome,
tmprofile-mjg022624ad esempio . - Salvare il nuovo nome del gruppo di risorse per Gruppo di risorse,
myResourceGroupTM1ad esempio .
- Salvare il nome univoco del profilo di Gestione traffico per Nome,
Quando si raggiunge la sezione Aggiungere endpoint Gestione traffico, seguire questa procedura:
- Dopo aver aperto il profilo di Gestione traffico nel passaggio 2, nella pagina Configurazione seguire questa procedura:
- Per durata (TTL) dns immettere 10.
- In Impostazioni monitoraggio endpoint immettere /websphere-café/, che è la radice del contesto dell'app di esempio distribuita.
- In Impostazioni di failover rapido dell'endpoint usare i valori seguenti:
- Per Ricerca interna selezionare 10.
- Per Numero tollerato di errori, immettere 3.
- Per il timeout probe, usare 5.
- Seleziona Salva. Attendere il completamento.
- Nel passaggio 4 per aggiungere l'endpoint
myPrimaryEndpointprimario, seguire questa procedura:- In Tipo di risorsa di destinazione selezionare Indirizzo IP pubblico.
- Selezionare l'elenco a discesa Scegli indirizzo IP pubblico e immettere il nome dell'indirizzo IP pubblico dell'IHS nell'area Stati Uniti orientali salvata in precedenza. Dovrebbe essere visualizzata una voce corrispondente. Selezionarlo per Indirizzo IP pubblico.
- Nel passaggio 6 per l'aggiunta di un endpoint
myFailoverEndpointdi failover/secondario, seguire questa procedura:- In Tipo di risorsa di destinazione selezionare Indirizzo IP pubblico.
- Selezionare l'elenco a discesa Scegli indirizzo IP pubblico e immettere il nome dell'indirizzo IP pubblico dell'IHS nell'area Stati Uniti occidentali salvata in precedenza. Dovrebbe essere visualizzata una voce corrispondente. Selezionarlo per Indirizzo IP pubblico.
- Aspetta un po' di tempo. Selezionare Aggiorna fino a quando lo stato di monitoraggio per l'endpoint
myPrimaryEndpointè Online e Lo stato di monitoraggio per l'endpointmyFailoverEndpointnon è danneggiato.
- Dopo aver aperto il profilo di Gestione traffico nel passaggio 2, nella pagina Configurazione seguire questa procedura:
Usare quindi la procedura seguente per verificare che l'app di esempio distribuita nel cluster WebSphere primario sia accessibile dal profilo Gestione traffico:
Selezionare Panoramica per il profilo Gestione traffico creato.
Selezionare e copiare il nome DNS (Domain Name System) del profilo di Gestione traffico, quindi aggiungerlo con
/websphere-cafe/,http://tmprofile-mjg022624.trafficmanager.net/websphere-cafe/ad esempio .Aprire l'URL in una nuova scheda del browser. Nella pagina dovrebbe essere visualizzato il caffè creato in precedenza.
Creare un altro caffè con un nome e un prezzo diversi, ad esempio Coffee 2 con prezzo 20, che viene salvato in modo permanente nella tabella dati dell'applicazione e nella tabella di sessione del database. L'interfaccia utente visualizzata dovrebbe essere simile alla schermata seguente:
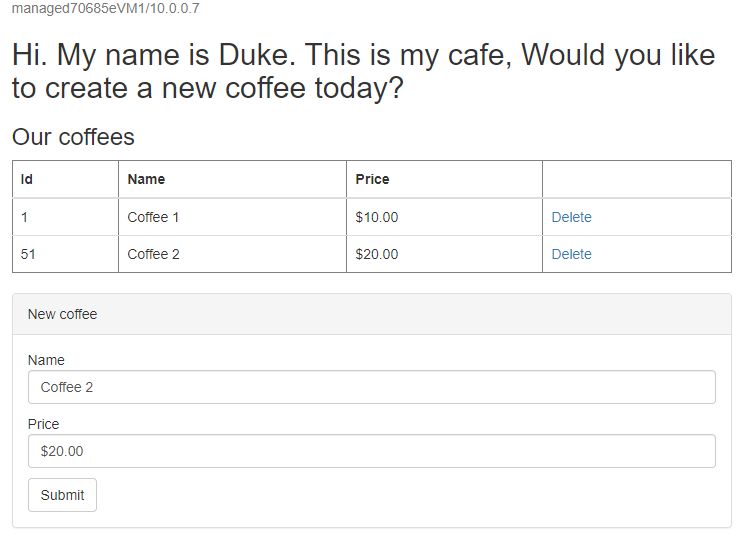

Se l'interfaccia utente non è simile, risolvere e risolvere il problema prima di continuare. Mantenere aperta la console e usarla per il test di failover in un secondo momento.
Ora si configura il profilo di Gestione traffico. Mantenere aperta la pagina e usarla per monitorare la modifica dello stato dell'endpoint in un evento di failover in un secondo momento.
Failover di test da primario a secondario
Per testare il failover, eseguire manualmente il failover del server e del cluster database SQL di Azure e quindi eseguire il failback usando il portale di Azure.
Failover nel sito secondario
Prima di tutto, usare la procedura seguente per eseguire il failover del database SQL di Azure dal server primario al server secondario:
- Passare alla scheda del browser del gruppo di failover database SQL di Azure,
failovergroup-mjg022624ad esempio . - Selezionare Failover>Sì.
- Attendere il completamento.
Usare quindi i passaggi seguenti per eseguire il failover del cluster WebSphere con il piano di ripristino:
Nella casella di ricerca nella parte superiore del portale di Azure immettere insiemi di credenziali di Servizi di ripristino e quindi selezionare Insiemi di credenziali di Servizi di ripristino nei risultati della ricerca.
Selezionare il nome dell'insieme di credenziali di Servizi di ripristino,
recovery-service-vault-westus-mjg022624ad esempio .In Gestione selezionare Piani di ripristino (Site Recovery). Selezionare il piano di ripristino creato,
recovery-plan-mjg022624ad esempio .Selezionare Failover. Selezionare Capisco il rischio. Ignorare il failover di test. Lasciare i valori predefiniti per gli altri campi e selezionare OK.
Nota
Facoltativamente, è possibile eseguire failover di test e pulizia del failover di test per assicurarsi che tutto funzioni come previsto prima del failover di test. Per altre informazioni, vedere Esercitazione: Eseguire un'esercitazione sul ripristino di emergenza per le macchine virtuali di Azure. In questa esercitazione viene eseguito il failover direttamente per semplificare l'esercizio.

Monitorare il failover nelle notifiche fino al completamento. L'esercizio in questa esercitazione richiede circa 10 minuti.
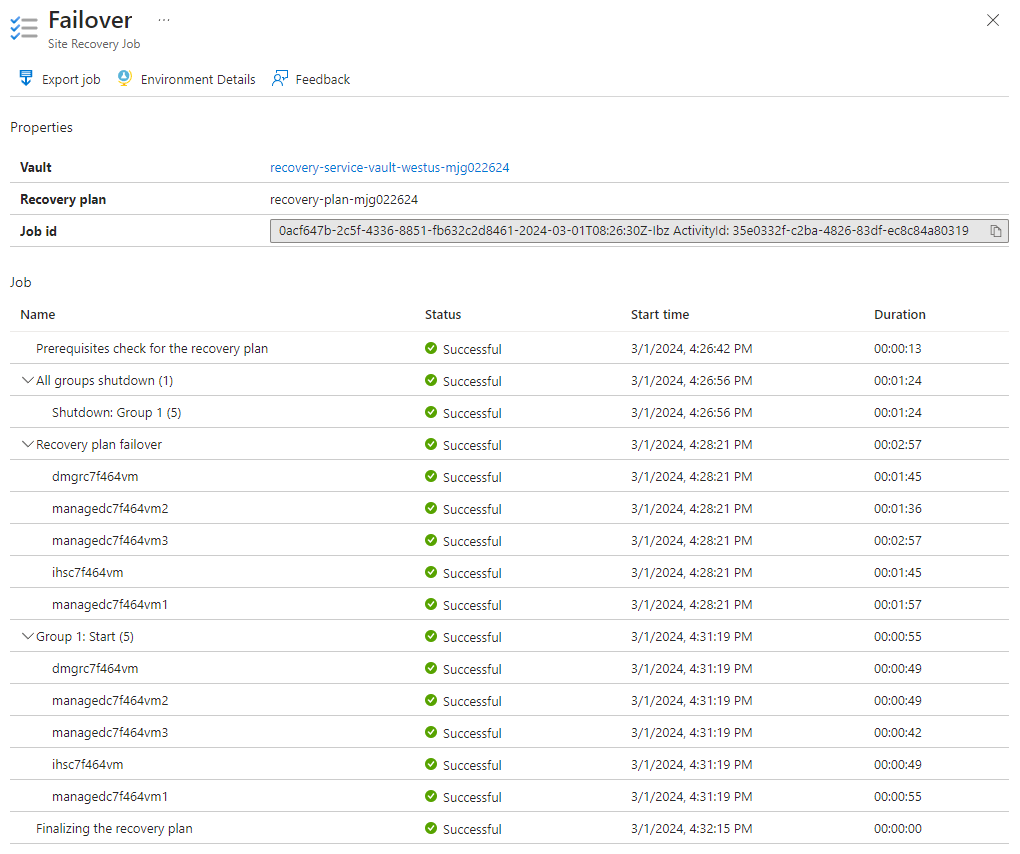
Facoltativamente, è possibile visualizzare i dettagli del processo di failover selezionando l'evento di failover, ad esempio Failover di 'recovery-plan-mjg0222624' in corso... - dalle notifiche.




Usare quindi la procedura seguente per abilitare l'accesso esterno alla console di soluzioni integrate WebSphere e all'app di esempio nell'area secondaria:
- Nella casella di ricerca nella parte superiore della portale di Azure immettere Gruppi di risorse e quindi selezionare Gruppi di risorse nei risultati della ricerca.
- Selezionare il nome del gruppo di risorse per l'area secondaria,
was-cluster-westus-mjg022624ad esempio . Ordinare gli elementi in base al tipo nella pagina Gruppo di risorse. - Selezionare Interfaccia di rete preceduta da
dmgr. Selezionare Configurazioni>IP ipconfig1. Selezionare Associa indirizzo IP pubblico. In Indirizzo IP pubblico selezionare l'indirizzo IP pubblico preceduto dadmgr. Questo indirizzo è quello creato in precedenza. In questo articolo l'indirizzo è denominatodmgr-public-ip-westus-mjg022624. Selezionare Salva e quindi attendere il completamento. - Tornare al gruppo di risorse e selezionare l'interfaccia di rete preceduta da
ihs. Selezionare Configurazioni>IP ipconfig1. Selezionare Associa indirizzo IP pubblico. In Indirizzo IP pubblico selezionare l'indirizzo IP pubblico preceduto daihs. Questo indirizzo è quello creato in precedenza. In questo articolo l'indirizzo è denominatoihs-public-ip-westus-mjg022624. Selezionare Salva e quindi attendere il completamento.
A questo scopo, seguire questa procedura per verificare che il failover funzioni come previsto:
Trovare l'etichetta del nome DNS per l'indirizzo IP pubblico di Dmgr creato in precedenza. Aprire l'URL di Dmgr WebSphere Integrated Solutions Console in una nuova scheda del browser. Non dimenticare di usare
https. Ad esempio:https://dmgrmjg022624.westus.cloudapp.azure.com:9043/ibm/console. Aggiornare la pagina finché non viene visualizzata la pagina iniziale per l'accesso.Accedere alla console con il nome utente e la password per l'amministratore di WebSphere salvato in precedenza e quindi seguire questa procedura:
Nel riquadro di spostamento selezionare Server>Tutti i server. Nel riquadro Server middleware dovrebbero essere elencati 4 server, inclusi 3 server applicazioni WebSphere costituiti da cluster
MyClusterWebSphere e 1 server Web che è un IHS. Aggiornare la pagina fino a quando non viene visualizzato l'avvio di tutti i server.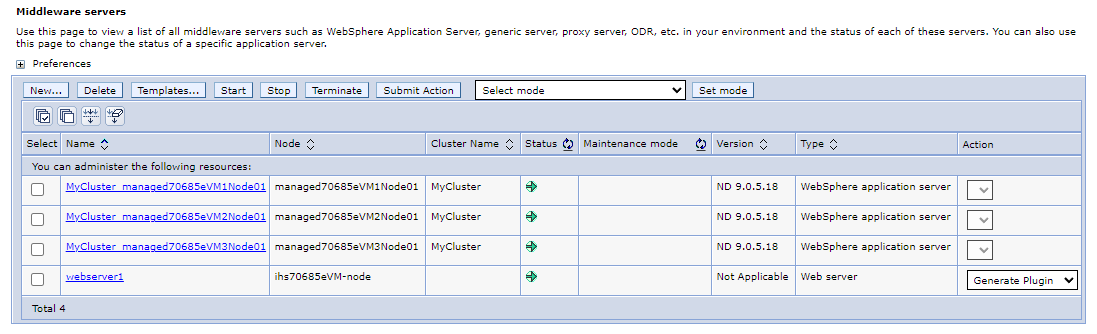
Nel riquadro di spostamento selezionare Applicazioni>Tipi di>applicazione Applicazioni Nel riquadro Applicazioni aziendali dovrebbe essere visualizzata 1 applicazione ,
websphere-cafeelencata e avviata.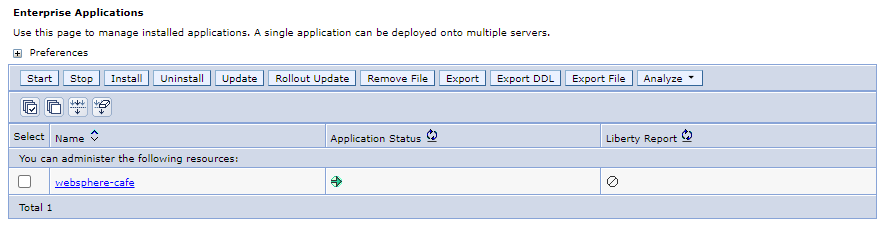
Per convalidare la configurazione del cluster nell'area secondaria, seguire la procedura descritta nella sezione Configurare il cluster . Si noterà che le impostazioni per Sincronizzare le modifiche con nodi e sessioni distribuite vengono replicate nel cluster di failover, come illustrato negli screenshot seguenti:

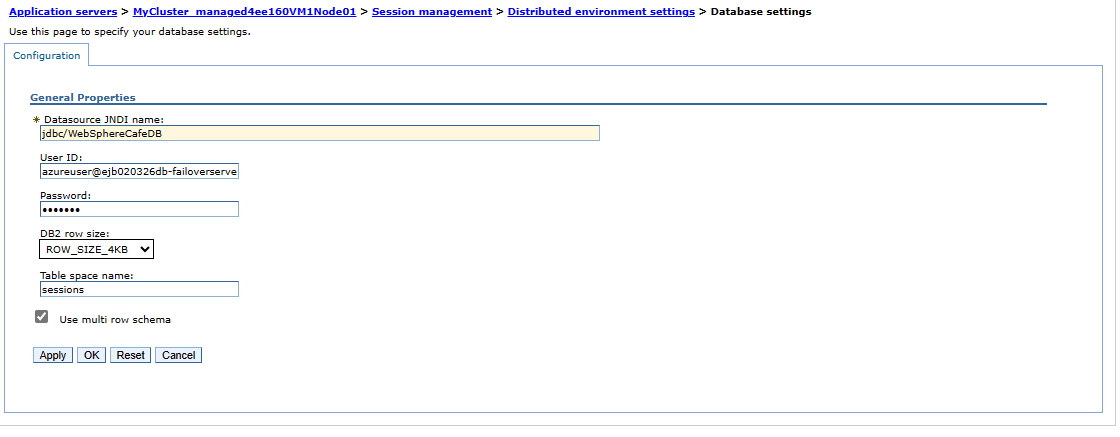
Trovare l'etichetta del nome DNS per l'indirizzo IP pubblico dell'IHS creato in precedenza. Aprire l'URL della console IHS aggiunto con il contesto
/websphere-cafe/radice . Si noti che non è necessario usarehttps. Questo esempio non usahttpsper IHS,http://ihsmjg022624.westus.cloudapp.azure.com/websphere-cafe/ad esempio . Nella pagina verranno visualizzati due caffè creati in precedenza.Passare alla scheda del browser del profilo di Gestione traffico, quindi aggiornare la pagina fino a quando non viene visualizzato il valore Stato monitoraggio dell'endpoint
myFailoverEndpointdiventa Online e il valore di stato Monitoraggio dell'endpointmyPrimaryEndpointdiventa Danneggiato.Passare alla scheda del browser con il nome DNS del profilo Gestione traffico,
http://tmprofile-mjg022624.trafficmanager.net/websphere-cafe/ad esempio . Aggiornare la pagina e verranno visualizzati gli stessi dati salvati in modo permanente nella tabella dei dati dell'applicazione e nella tabella della sessione visualizzata. L'interfaccia utente visualizzata dovrebbe essere simile alla schermata seguente:
Se non si osserva questo comportamento, la Gestione traffico richiede tempo per aggiornare IL DNS in modo che punti al sito di failover. Il problema potrebbe anche essere che il browser ha memorizzato nella cache il risultato della risoluzione dei nomi DNS che punta al sito non riuscito. Attendere un po' e aggiornare di nuovo la pagina.





Eseguire il commit del failover
Seguire questa procedura per eseguire il commit del failover dopo aver soddisfatto il risultato del failover:
Nella casella di ricerca nella parte superiore del portale di Azure immettere insiemi di credenziali di Servizi di ripristino e quindi selezionare Insiemi di credenziali di Servizi di ripristino nei risultati della ricerca.
Selezionare il nome dell'insieme di credenziali di Servizi di ripristino,
recovery-service-vault-westus-mjg022624ad esempio .In Gestione selezionare Piani di ripristino (Site Recovery). Selezionare il piano di ripristino creato,
recovery-plan-mjg022624ad esempio .Selezionare Commit>OK.
Monitorare il commit nelle notifiche fino al completamento.

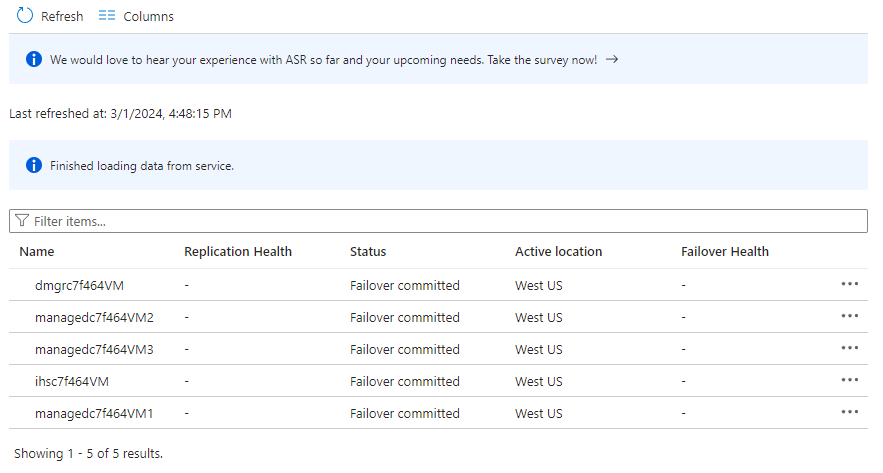
Selezionare Elementi nel piano di ripristino. Verranno visualizzati 5 elementi elencati come Failover di cui è stato eseguito il commit.



Disabilitare la replica
Usare la procedura seguente per disabilitare la replica per gli elementi nel piano di ripristino e quindi eliminare il piano di ripristino:
Per ogni elemento in Elementi nel piano di ripristino, selezionare il pulsante con i puntini di sospensione (...) e quindi selezionare Disabilita replica.
Se viene richiesto di specificare un motivo per disabilitare la protezione per questa macchina virtuale, selezionare una scelta preferita, ad esempio ho completato la migrazione dell'applicazione. Seleziona OK.
Ripetere il passaggio 1 fino a quando non si disabilita la replica per tutti gli elementi.
Monitorare il processo nelle notifiche fino al completamento.

Selezionare Panoramica>Elimina. Selezionare Sì per confermare l'eliminazione.

Preparare il failback: riproteggere il sito di failover
L'area secondaria è ora il sito di failover e attivo. È consigliabile riproteggerlo nell'area primaria.
Prima di tutto, usare la procedura seguente per pulire le risorse inutilizzate e che il servizio Azure Site Recovery verrà replicato nell'area primaria in un secondo momento. Non è possibile eliminare solo il gruppo di risorse, perché site recovery ripristina le risorse nel gruppo di risorse esistente.
- Nella casella di ricerca nella parte superiore della portale di Azure immettere Gruppi di risorse e quindi selezionare Gruppi di risorse nei risultati della ricerca.
- Selezionare il nome del gruppo di risorse per l'area primaria,
was-cluster-eastus-mjg022624ad esempio . Ordinare gli elementi in base al tipo nella pagina Gruppo di risorse. - Per eliminare le macchine virtuali, seguire questa procedura:
- Selezionare il filtro Tipo, quindi selezionare Macchina virtuale dall'elenco a discesa Valore.
- Selezionare Applica.
- Selezionare tutte le macchine virtuali, selezionare Elimina e quindi immettere elimina per confermare l'eliminazione.
- Selezionare Elimina.
- Monitorare il processo nelle notifiche fino al completamento.
- Per eliminare i dischi, seguire questa procedura:
- Selezionare il filtro Tipo, quindi selezionare Dischi dall'elenco a discesa Valore.
- Selezionare Applica.
- Selezionare tutti i dischi, selezionare Elimina, quindi immettere elimina per confermare l'eliminazione.
- Selezionare Elimina.
- Monitorare il processo nelle notifiche e attendere il completamento.
- Per eliminare gli endpoint, seguire questa procedura:
- Selezionare il filtro Tipo, selezionare Endpoint privato nell'elenco a discesa Valore.
- Selezionare Applica.
- Selezionare tutti gli endpoint privati, selezionare Elimina, quindi immettere elimina per confermare l'eliminazione.
- Selezionare Elimina.
- Monitorare il processo nelle notifiche fino al completamento. Ignorare questo passaggio se il tipo Endpoint privato non è elencato.
- Per eliminare le interfacce di rete, seguire questa procedura:
- Selezionare il filtro Tipo selezionare Interfaccia di rete dall'elenco a discesa Valore. >
- Selezionare Applica.
- Selezionare tutte le interfacce di rete, selezionare Elimina, quindi immettere elimina per confermare l'eliminazione.
- Selezionare Elimina. Monitorare il processo nelle notifiche fino al completamento.
- Per eliminare gli account di archiviazione, seguire questa procedura:
- Selezionare il filtro > Tipo selezionare Account di archiviazione nell'elenco a discesa Valore.
- Selezionare Applica.
- Selezionare tutti gli account di archiviazione, selezionare Elimina, quindi immettere delete per confermare l'eliminazione.
- Selezionare Elimina. Monitorare il processo nelle notifiche fino al completamento.
Successivamente, usare gli stessi passaggi nella sezione Configurare il ripristino di emergenza per il cluster usando Azure Site Recovery per l'area primaria, ad eccezione delle differenze seguenti:
- Per la sezione Creare un insieme di credenziali di Servizi di ripristino, seguire questa procedura:
- Selezionare il gruppo di risorse distribuito nell'area primaria,
was-cluster-eastus-mjg022624ad esempio . - Immettere un nome diverso per l'insieme di credenziali dei servizi,
recovery-service-vault-eastus-mjg022624ad esempio . - In Area selezionare Stati Uniti orientali.
- Selezionare il gruppo di risorse distribuito nell'area primaria,
- Per Abilitare la replica, seguire questa procedura:
- Per Area in Origine selezionare Stati Uniti occidentali.
- Per Le impostazioni di replica, seguire questa procedura:
- Per Gruppo di risorse di destinazione selezionare il gruppo di risorse esistente distribuito nell'area primaria,
was-cluster-eastus-mjg022624ad esempio . - In Rete virtuale di failover selezionare la rete virtuale esistente nell'area primaria.
- Per Gruppo di risorse di destinazione selezionare il gruppo di risorse esistente distribuito nell'area primaria,
- Per Crea un piano di ripristino, per Origine, selezionare Stati Uniti occidentali e in Destinazione selezionare Stati Uniti orientali.
- Ignorare i passaggi nella sezione Altre configurazioni di rete per l'area secondaria perché sono state create e configurate in precedenza.
Nota
È possibile notare che Azure Site Recovery supporta la riprotezione delle macchine virtuali quando la macchina virtuale di destinazione esiste. Per altre informazioni, vedere la sezione Riproteggere la macchina virtuale di Esercitazione: Eseguire il failover di macchine virtuali di Azure in un'area secondaria. A causa dell'approccio adottato per WebSphere, questa funzionalità non funziona. Il motivo è che le uniche modifiche tra il disco di origine e il disco di destinazione vengono sincronizzate per il cluster WebSphere, in base al risultato della verifica. Per sostituire la funzionalità della funzionalità di riprotezione della macchina virtuale, questa esercitazione stabilisce una nuova replica dal sito secondario al sito primario dopo il failover. L'intero disco viene copiato dall'area di failover all'area primaria. Per altre informazioni, vedere la sezione Cosa accade durante la riprotezione? di Riprotezione di cui è stato eseguito il failover nelle macchine virtuali di Azure nell'area primaria.
Eseguire il failback nel sito primario
Usare gli stessi passaggi della sezione Failover nel sito secondario per eseguire il failback nel sito primario, incluso il server di database e il cluster, ad eccezione delle differenze seguenti:
- Selezionare l'insieme di credenziali del servizio di ripristino distribuito nell'area primaria,
recovery-service-vault-eastus-mjg022624ad esempio . - Selezionare il gruppo di risorse distribuito nell'area primaria,
was-cluster-eastus-mjg022624ad esempio . - Dopo aver abilitato l'accesso esterno alla Console soluzioni integrate WebSphere e all'app di esempio nell'area primaria, rivedere le schede del browser per WebSphere Integrated Solutions Console e l'app di esempio per il cluster primario aperto in precedenza. Verificare che funzionino come previsto. A seconda del tempo impiegato per il failback, è possibile che i dati della sessione non vengano visualizzati nella sezione Nuovo caffè dell'interfaccia utente dell'app di esempio se sono scaduti più di un'ora in precedenza.
- Nella sezione Eseguire il commit del failover selezionare l'insieme di credenziali di Servizi di ripristino distribuito nel database primario,
recovery-service-vault-eastus-mjg022624ad esempio . - Nel profilo di Gestione traffico si noterà che l'endpoint diventa Online e l'endpoint
myFailoverEndpointmyPrimaryEndpointdiventa Danneggiato. - Nella sezione Preparare il failback: riproteggere il sito di failover seguire questa procedura:
- L'area primaria è il sito di failover ed è attiva, quindi è consigliabile riproteggerla nell'area secondaria.
- Pulire la risorsa distribuita nell'area secondaria, ad esempio le risorse distribuite in
was-cluster-westus-mjg022624. - Usare gli stessi passaggi nella sezione Configurare il ripristino di emergenza per il cluster usando Azure Site Recovery per proteggere l'area primaria nell'area secondaria, ad eccezione delle modifiche seguenti:
- Ignorare i passaggi nella sezione Creare un insieme di credenziali di Servizi di ripristino perché ne è stato creato uno in precedenza,
recovery-service-vault-westus-mjg022624ad esempio . - Per Enable replication>Replication settings Failover virtual network (Abilita impostazioni>replica replica rete virtuale di failover), selezionare la rete virtuale esistente nell'area secondaria.
- Ignorare i passaggi nella sezione Altre configurazioni di rete per l'area secondaria perché sono state create e configurate in precedenza.
- Ignorare i passaggi nella sezione Creare un insieme di credenziali di Servizi di ripristino perché ne è stato creato uno in precedenza,
Pulire le risorse
Se non si intende continuare a usare i cluster WebSphere e altri componenti, seguire questa procedura per eliminare i gruppi di risorse per pulire le risorse usate in questa esercitazione:
- Immettere il nome del gruppo di risorse dei server database SQL di Azure, ad esempio,
myResourceGroupnella casella di ricerca nella parte superiore del portale di Azure e selezionare il gruppo di risorse corrispondente nei risultati della ricerca. - Selezionare Elimina gruppo di risorse.
- In Immettere il nome del gruppo di risorse per confermare l'eliminazione immettere il nome del gruppo di risorse.
- Selezionare Elimina.
- Ripetere i passaggi da 1 a 4 per il gruppo di risorse del Gestione traffico,
myResourceGroupTM1ad esempio . - Nella casella di ricerca nella parte superiore del portale di Azure immettere insiemi di credenziali di Servizi di ripristino e quindi selezionare Insiemi di credenziali di Servizi di ripristino nei risultati della ricerca.
- Selezionare il nome dell'insieme di credenziali di Servizi di ripristino,
recovery-service-vault-westus-mjg022624ad esempio . - In Gestione selezionare Piani di ripristino (Site Recovery). Selezionare il piano di ripristino creato,
recovery-plan-mjg022624ad esempio . - Usare gli stessi passaggi nella sezione Disabilitare la replica per rimuovere i blocchi sugli elementi replicati.
- Ripetere i passaggi da 1 a 4 per il gruppo di risorse del cluster WebSphere primario,
was-cluster-westus-mjg022624ad esempio . - Ripetere i passaggi da 1 a 4 per il gruppo di risorse del cluster WebSphere secondario,
was-cluster-eastus-mjg022624ad esempio .
Passaggi successivi
In questa esercitazione è stata configurata una soluzione di disponibilità elevata/ripristino di emergenza costituita da un livello di infrastruttura di applicazione attivo-passivo con un livello di database attivo-passivo e in cui entrambi i livelli si estendono su due siti geograficamente diversi. Nel primo sito, sia il livello di infrastruttura dell'applicazione che il livello di database sono attivi. Nel secondo sito il dominio secondario viene ripristinato con il servizio Azure Site Recovery e il database secondario è in standby.
Continuare a esplorare i riferimenti seguenti per altre opzioni per creare soluzioni di disponibilità elevata/ripristino di emergenza ed eseguire WebSphere in Azure: