Introduzione alla valutazione delle risposte in un'app di chat in JavaScript
Questo articolo illustra come valutare le risposte di un'app di chat rispetto a un set di risposte corrette o ideali (note come verità di base). Ogni volta che si modifica l'applicazione di chat in modo che influisca sulle risposte, eseguire una valutazione per confrontare le modifiche. Questa applicazione demo offre strumenti che è possibile usare oggi per semplificare l'esecuzione delle valutazioni.
Seguendo le istruzioni riportate in questo articolo, potrai:
- Usare richieste di esempio fornite personalizzate per il dominio soggetto. Queste richieste sono già presenti nel repository.
- Generare domande utente di esempio e risposte sulla verità dai propri documenti.
- Eseguire valutazioni usando una richiesta di esempio con le domande dell'utente generate.
- Esaminare l'analisi delle risposte.
Nota
Questo articolo usa uno o più modelli di app di intelligenza artificiale come base per gli esempi e le linee guida nell’articolo. I modelli di app di intelligenza artificiale offrono implementazioni di riferimento ben gestite e facili da distribuire per garantire un punto di partenza di alta qualità per le app di intelligenza artificiale.
Panoramica dell'architettura
I componenti chiave dell'architettura includono:
- App chat ospitata in Azure: l'app di chat viene eseguita nel servizio app Azure.
- Microsoft AI Chat Protocol offre contratti API standardizzati tra soluzioni e linguaggi di intelligenza artificiale. L'app chat è conforme al protocollo Microsoft AI Chat Protocol, che consente l'esecuzione dell'app di valutazione su qualsiasi app di chat conforme al protocollo.
- Ricerca di intelligenza artificiale di Azure: l'app di chat usa Ricerca intelligenza artificiale di Azure per archiviare i dati dai propri documenti.
- Generatore di domande di esempio: può generare molte domande per ogni documento insieme alla risposta alla verità di base. Più domande, più lunga è la valutazione.
- L'analizzatore esegue domande e richieste di esempio sull'app di chat e restituisce i risultati.
- Lo strumento di revisione consente di esaminare i risultati delle valutazioni.
- Lo strumento Diff consente di confrontare le risposte tra valutazioni.
Quando si distribuisce questa valutazione in Azure, viene creato l'endpoint OpenAI di Azure per il GPT-4 modello con la propria capacità. Quando si valutano le applicazioni di chat, è importante che l'analizzatore abbia una propria risorsa OpenAI usando GPT-4 con la propria capacità.
Prerequisiti
Abbonamento di Azure. Crearne uno gratuito
Distribuire un'app di chat.
Queste app di chat caricano i dati nella risorsa ricerca di intelligenza artificiale di Azure. Questa risorsa è necessaria per il funzionamento dell'app di valutazione. Non completare la sezione Pulire le risorse della procedura precedente.
Per questa distribuzione, sono necessarie le seguenti informazioni sulle risorse di Azure, riferite come app di chat in questo articolo:
- URI DELL'API Chat: l'endpoint back-end del servizio visualizzato alla fine del
azd upprocesso. - Azure AI Search. Sono necessari i valori seguenti:
- Nome risorsa: nome della risorsa di Ricerca di intelligenza artificiale di Azure, indicato come
Search servicedurante ilazd upprocesso. - Nome indice: nome dell'indice di Ricerca di intelligenza artificiale di Azure in cui sono archiviati i documenti. Questo è disponibile nella portale di Azure per il servizio di ricerca.
- Nome risorsa: nome della risorsa di Ricerca di intelligenza artificiale di Azure, indicato come
L'URL dell'API Chat consente alle valutazioni di effettuare richieste tramite l'applicazione back-end. Le informazioni di Ricerca intelligenza artificiale di Azure consentono agli script di valutazione di usare la stessa distribuzione del back-end, caricata con i documenti.
Dopo aver raccolto queste informazioni, non è necessario usare di nuovo l'ambiente di sviluppo di app di chat. Più avanti in questo articolo viene fatto riferimento più volte per indicare come l'app di chat viene usata dall'appValutazioni. Non eliminare le risorse dell'app chat fino a quando non si completa l'intera procedura in questo articolo.
- URI DELL'API Chat: l'endpoint back-end del servizio visualizzato alla fine del
Per completare questo articolo è disponibile un ambiente contenitore di sviluppo con tutte le dipendenze necessarie. Puoi eseguire il contenitore di sviluppo in GitHub Codespaces (in un browser) o in locale usando Visual Studio Code.
- Account GitHub
Ambiente di sviluppo aperto
Inizia ora con un ambiente di sviluppo che ha tutte le dipendenze installate per completare questo articolo. È consigliabile disporre l'area di lavoro di monitoraggio in modo da poter visualizzare sia questa documentazione che l'ambiente di sviluppo contemporaneamente.
Questo articolo è stato testato con l'area per la switzerlandnorth distribuzione di valutazione.
GitHub Codespaces esegue un contenitore di sviluppo gestito da GitHub con Visual Studio Code per il Web come interfaccia utente. Per l'ambiente di sviluppo più semplice, usa GitHub Codespaces per avere gli strumenti di sviluppo e le dipendenze corretti preinstallati per completare questo articolo.
Importante
Tutti gli account GitHub possono usare Codespaces per un massimo di 60 ore gratuite ogni mese con 2 istanze di core. Per altre informazioni, vedere Spazio di archiviazione e ore core mensili inclusi in GitHub Codespaces.
Avviare il processo per creare un nuovo codespace GitHub nel ramo
maindel repository GitHubAzure-Samples/ai-rag-chat-evaluator.Per visualizzare l'ambiente di sviluppo e la documentazione disponibile contemporaneamente, fare clic con il pulsante destro del mouse sul pulsante seguente e scegliere Apri collegamento in una nuova finestra.

Nella pagina Crea spazio codici esaminare le impostazioni di configurazione dello spazio di codice e quindi selezionare Crea nuovo spazio di codice
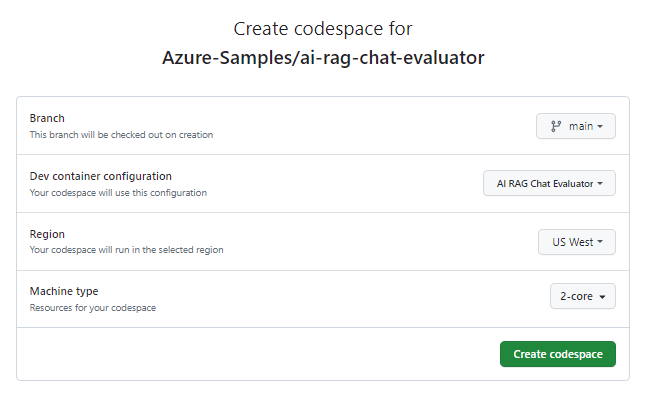
Attendere l'avvio del codespace. Questo processo di avvio può richiedere alcuni minuti.
Nel terminale nella parte inferiore della schermata accedere ad Azure con l'interfaccia della riga di comando per sviluppatori di Azure.
azd auth login --use-device-codeCopia il codice dal terminale e incollalo in un browser. Segui le istruzioni per eseguire l'autenticazione con l'account Azure.
Effettuare il provisioning della risorsa di Azure necessaria, Azure OpenAI, per l'app di valutazione.
azd upQuesta
AZD commandoperazione non distribuisce l'app di valutazione, ma crea la risorsa OpenAI di Azure con una distribuzione necessariaGPT-4per eseguire le valutazioni nell'ambiente di sviluppo locale.Le attività rimanenti in questo articolo vengono eseguite nel contesto di questo contenitore di sviluppo.
Il nome del repository GitHub viene visualizzato nella barra di ricerca. Questo indicatore visivo consente di distinguere l'app di valutazione dall'app di chat. Questo
ai-rag-chat-evaluatorrepository viene definito app Valutazioni in questo articolo.

Preparare i valori e le informazioni di configurazione dell'ambiente
Aggiornare i valori dell'ambiente e le informazioni di configurazione con le informazioni raccolte durante i prerequisiti per l'app di valutazione.
Creare un
.envfile basato su.env.sample:cp .env.sample .envEseguire questi comandi per ottenere i valori necessari per
AZURE_OPENAI_EVAL_DEPLOYMENTeAZURE_OPENAI_SERVICEdal gruppo di risorse distribuito e incollare tali valori nel.envfile:azd env get-value AZURE_OPENAI_EVAL_DEPLOYMENT azd env get-value AZURE_OPENAI_SERVICEAggiungere i valori seguenti dall'app di chat per l'istanzadi Ricerca di intelligenza artificiale di Azure all'oggetto
.env, raccolto nella sezione prerequisiti:AZURE_SEARCH_SERVICE="<service-name>" AZURE_SEARCH_INDEX="<index-name>"
Usare il protocollo Microsoft AI Chat per informazioni di configurazione
L'app Microsoft AI Chat Protocol specification di intelligenza artificiale open source, cloud e linguaggio usato per l'utilizzo e la valutazione. Quando gli endpoint client e di livello intermedio rispettano questa specifica di API, è possibile usare ed eseguire costantemente valutazioni nei back-end di intelligenza artificiale.
Creare un nuovo file denominato
my_config.jsone copiarne il contenuto seguente:{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/experiment<TIMESTAMP>", "target_url": "http://localhost:50505/chat", "target_parameters": { "overrides": { "top": 3, "temperature": 0.3, "retrieval_mode": "hybrid", "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_refined.txt", "seed": 1 } } }Lo script di valutazione crea la
my_resultscartella .L'oggetto
overridescontiene le impostazioni di configurazione necessarie per l'applicazione. Ogni applicazione definisce il proprio set di proprietà delle impostazioni.Usare la tabella seguente per comprendere il significato delle proprietà delle impostazioni inviate all'app di chat:
Settings, proprietà Descrizione semantic_ranker Se usare il ranker semantico, un modello che classifica i risultati della ricerca in base alla somiglianza semantica con la query dell'utente. Questa esercitazione viene disabilitata per ridurre i costi. retrieval_mode Modalità di recupero da utilizzare. Il valore predefinito è hybrid.temperatura Impostazione della temperatura per il modello. Il valore predefinito è 0.3.top Numero di risultati di ricerca da restituire. Il valore predefinito è 3.prompt_template Override della richiesta usata per generare la risposta in base ai risultati della domanda e della ricerca. seed Valore di inizializzazione per tutte le chiamate ai modelli GPT. L'impostazione di un valore di inizializzazione comporta risultati più coerenti tra le valutazioni. Passare al
target_urlvalore URI dell'app di chat, raccolto nella sezione prerequisiti. L'app di chat deve essere conforme al protocollo di chat. L'URI ha il formatohttps://CHAT-APP-URL/chatseguente. Assicurarsi che il protocollo e lachatroute facciano parte dell'URI.
Generare dati di esempio
Per valutare nuove risposte, devono essere confrontate con una risposta "verità di terra", che è la risposta ideale per una domanda specifica. Generare domande e risposte dai documenti archiviati in Ricerca di intelligenza artificiale di Azure per l'app di chat.
Copiare la
example_inputcartella in una nuova cartella denominatamy_input.In un terminale eseguire il comando seguente per generare i dati di esempio:
python -m evaltools generate --output=my_input/qa.jsonl --persource=2 --numquestions=14
Le coppie di domande/risposte vengono generate e archiviate in my_input/qa.jsonl (in formato JSONL) come input per l'analizzatore usato nel passaggio successivo. Per una valutazione di produzione, si genererebbero più coppie di controllo di qualità, più di 200 per questo set di dati.
Nota
Il numero limitato di domande e risposte per ogni origine consente di completare rapidamente questa procedura. Non è concepito per essere una valutazione di produzione che dovrebbe avere più domande e risposte per ogni origine.
Eseguire la prima valutazione con un prompt perfezionato
Modificare le proprietà del
my_config.jsonfile di configurazione:Proprietà Nuovo valore results_dir my_results/experiment_refinedprompt_template <READFILE>my_input/prompt_refined.txtIl prompt perfezionato è specifico sul dominio soggetto.
If there isn't enough information below, say you don't know. Do not generate answers that don't use the sources below. If asking a clarifying question to the user would help, ask the question. Use clear and concise language and write in a confident yet friendly tone. In your answers ensure the employee understands how your response connects to the information in the sources and include all citations necessary to help the employee validate the answer provided. For tabular information return it as an html table. Do not return markdown format. If the question is not in English, answer in the language used in the question. Each source has a name followed by colon and the actual information, always include the source name for each fact you use in the response. Use square brackets to reference the source, e.g. [info1.txt]. Don't combine sources, list each source separately, e.g. [info1.txt][info2.pdf].In un terminale eseguire il comando seguente per eseguire la valutazione:
python -m evaltools evaluate --config=my_config.json --numquestions=14Questo script ha creato una nuova cartella dell'esperimento in
my_results/con la valutazione. La cartella contiene i risultati della valutazione, tra cui:Nome del file Descrizione config.jsonCopia del file di configurazione usato per la valutazione. evaluate_parameters.jsonParametri utilizzati per la valutazione. Molto simile a config.jsonma include metadati aggiuntivi come timestamp.eval_results.jsonlOgni domanda e risposta, insieme alle metriche GPT per ogni coppia di controllo di qualità. summary.jsonRisultati complessivi, ad esempio le metriche GPT medie.
Eseguire la seconda valutazione con un prompt debole
Modificare le proprietà del
my_config.jsonfile di configurazione:Proprietà Nuovo valore results_dir my_results/experiment_weakprompt_template <READFILE>my_input/prompt_weak.txtTale prompt debole non ha alcun contesto sul dominio soggetto:
You are a helpful assistant.In un terminale eseguire il comando seguente per eseguire la valutazione:
python -m evaltools evaluate --config=my_config.json --numquestions=14
Eseguire la terza valutazione con una temperatura specifica
Usa una richiesta che consenta una maggiore creatività.
Modificare le proprietà del
my_config.jsonfile di configurazione:Esistente Proprietà Nuovo valore Esistente results_dir my_results/experiment_ignoresources_temp09Esistente prompt_template <READFILE>my_input/prompt_ignoresources.txtNuovo temperatura 0.9Il valore predefinito
temperatureè 0,7. Maggiore è la temperatura, più creative sono le risposte.Il
ignoreprompt è breve:Your job is to answer questions to the best of your ability. You will be given sources but you should IGNORE them. Be creative!L'oggetto config dovrebbe essere simile al seguente, tranne sostituire
results_dircon il percorso:{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/prompt_ignoresources_temp09", "target_url": "https://YOUR-CHAT-APP/chat", "target_parameters": { "overrides": { "temperature": 0.9, "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_ignoresources.txt" } } }In un terminale eseguire il comando seguente per eseguire la valutazione:
python -m evaltools evaluate --config=my_config.json --numquestions=14
Esaminare i risultati della valutazione
Sono state eseguite tre valutazioni in base a richieste e impostazioni dell'app diverse. I risultati vengono archiviati nella my_results cartella . Esaminare le differenze dei risultati in base alle impostazioni.
Usare lo strumento di revisione per visualizzare i risultati delle valutazioni:
python -m evaltools summary my_resultsI risultati hanno un aspetto simile al seguente:

Ogni valore viene restituito come numero e percentuale.
Usare la tabella seguente per comprendere il significato dei valori.
valore Descrizione Allineamento Questo si riferisce a quanto bene le risposte del modello si basano su informazioni effettive e verificabili. Una risposta viene considerata a terra se è effettivamente accurata e riflette la realtà. Pertinenza In questo modo viene misurata la modalità di allineamento delle risposte del modello al contesto o al prompt. Una risposta pertinente risolve direttamente la query o l'istruzione dell'utente. Coerenza Questo si riferisce alla coerenza logica delle risposte del modello. Una risposta coerente mantiene un flusso logico e non si contraddice. Citazione Indica se la risposta è stata restituita nel formato richiesto nel prompt. Durata In questo modo viene misurata la lunghezza della risposta. I risultati dovrebbero indicare che tutte e tre le valutazioni hanno avuto una rilevanza elevata, mentre la
experiment_ignoresources_temp09rilevanza più bassa è stata elevata.Selezionare la cartella per visualizzare la configurazione per la valutazione.
Premere CTRL + C per uscire dall'app e tornare al terminale.
Confrontare le risposte
Confrontare le risposte restituite dalle valutazioni.
Selezionare due delle valutazioni da confrontare, quindi usare lo stesso strumento di revisione per confrontare le risposte:
python -m evaltools diff my_results/experiment_refined my_results/experiment_ignoresources_temp09Esaminare i risultati. I risultati potrebbero variare.

Premere CTRL + C per uscire dall'app e tornare al terminale.
Suggerimenti per ulteriori valutazioni
- Modificare le richieste in
my_inputper personalizzare le risposte, ad esempio dominio soggetto, lunghezza e altri fattori. - Modificare il
my_config.jsonfile per modificare i parametri, adtemperatureesempio , edsemantic_rankereseguire di nuovo gli esperimenti. - Confrontare risposte diverse per comprendere come la richiesta e la domanda influiscono sulla qualità della risposta.
- Generare un set separato di domande e risposte reali per ogni documento nell'indice di Ricerca di intelligenza artificiale di Azure. Eseguire quindi di nuovo le valutazioni per vedere in che modo le risposte differiscono.
- Modificare le richieste per indicare risposte più brevi o più lunghe aggiungendo il requisito alla fine del prompt. Ad esempio:
Please answer in about 3 sentences..
Pulire risorse e dipendenze
Pulire le risorse di Azure
Le risorse di Azure create in questo articolo vengono fatturate alla sottoscrizione di Azure. Se prevedi che queste risorse non ti servano in futuro, eliminale per evitare di incorrere in costi aggiuntivi.
Per eliminare le risorse di Azure e rimuovere il codice sorgente, eseguire il comando seguente dell'interfaccia della riga di comando per sviluppatori di Azure:
azd down --purge
Pulire GitHub Codespaces
L'eliminazione dell'ambiente GitHub Codespaces offre la possibilità di aumentare le ore gratuite per core a cui si ha diritto per l'account.
Importante
Per altre informazioni sui diritti dell'account GitHub, vedere Ore di archiviazione e di core mensili incluse in GitHub Codespaces.
Accedere al dashboard di GitHub Codespaces (https://github.com/codespaces).
Individuare i codespace attualmente in esecuzione provenienti dal repository GitHub
Azure-Samples/ai-rag-chat-evaluator.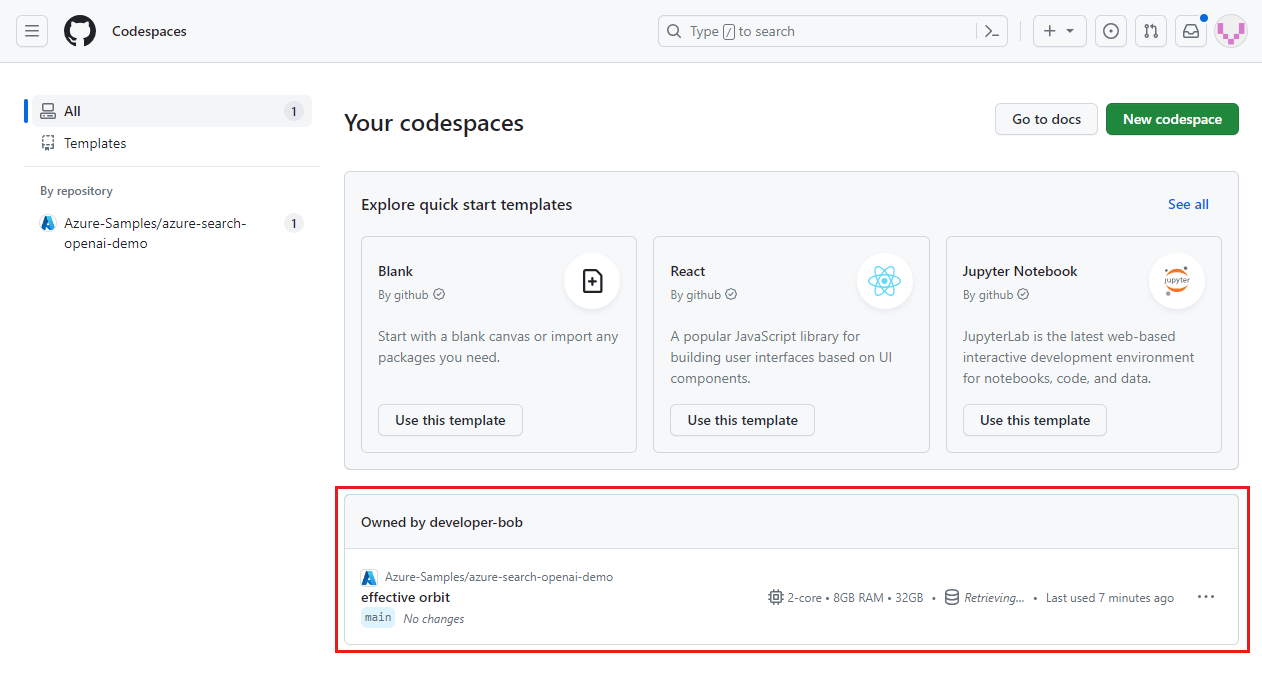
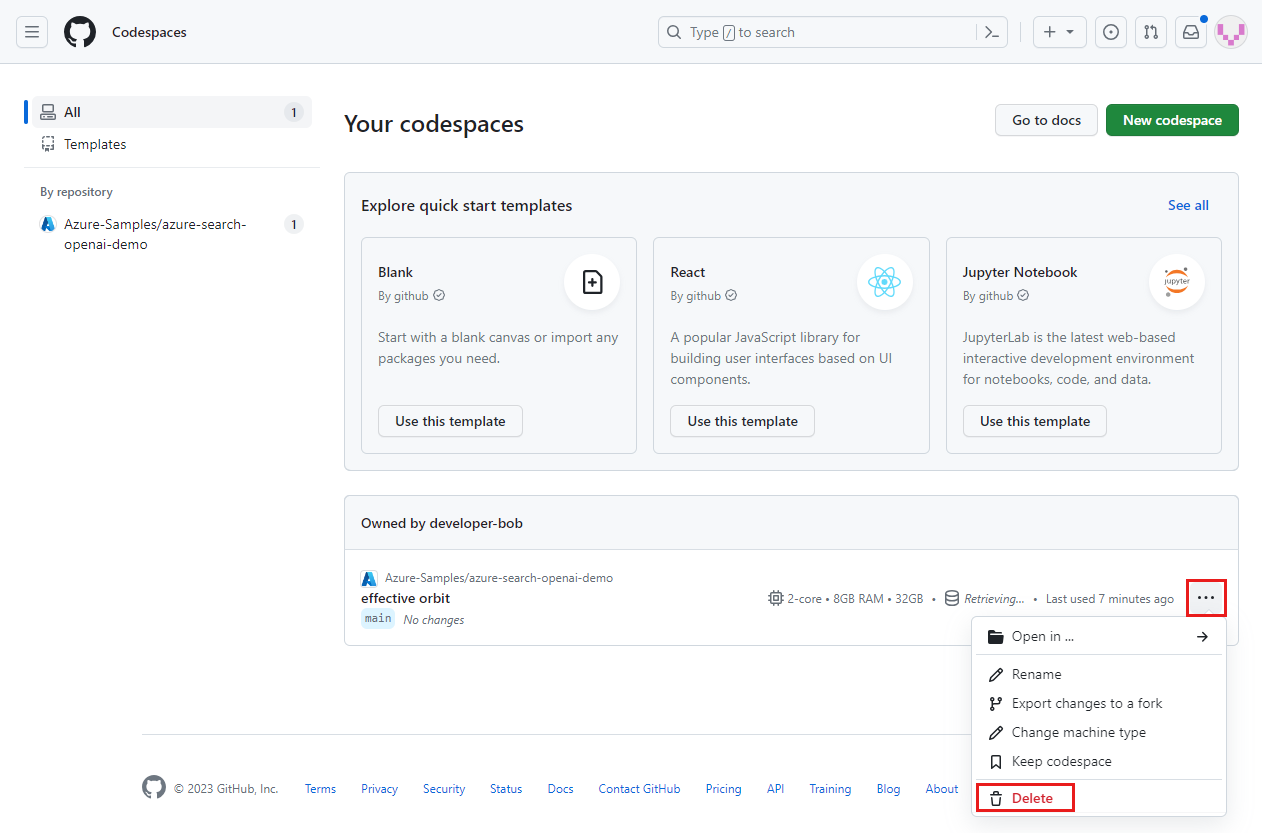
Aprire il menu di scelta rapida per il codespace e selezionare Elimina.
Tornare all'articolo sull'app di chat per pulire tali risorse.
Passaggi successivi
- Repository valutazioni
- Repository GitHub dell'app di chat Enterprise
- Creare un'app di chat con OpenAI di Azure: procedura consigliata per l’architettura della soluzione
- Controllo di accesso nelle app per intelligenza artificiale generative con Ricerca di intelligenza artificiale di Azure
- Creare una soluzione OpenAI Enterprise pronta con Gestione API di Azure
- Prestazioni della ricerca vettoriale con funzionalità di recupero e classificazione ibride